Redis——详解五种数据结构
Redis——详解五种数据结构
文章目录
- Redis——详解五种数据结构
-
- 一、String
-
- 1、字符串类型
- 2、数值类型
- 3、bitmap
- 二、list
- 三、hash
- 四、set
- 五、sorted_set
在上一篇文章中我们已经大致了解了 Redis 在并发场景下的工作流程,下面我们就来学习一下 Redis 的应用层面的东西
前面我们讲了 Redis 与 memcache 的最本质的区别就是 Redis 键值对数据 key–value 中的 value 有五种数据类型,基于这五种数据类型及 Redis 提供的对五种数据结构操作的 API 方法,我们能够很方便的对指定的属性进行查询,返回给用户请求指定的属性值,而不必返回全量的数据组成的 JSON 对象
如果使用 memcache 返回全部的数据组成的 JSON,还需要在 client 端编写代码解析,才能够获取指定的字段值;而使用 Redis 中的五种数据类型,就能够使服务器返回指定的字段值。
核心思想就是使计算向数据移动。memcache 计算流程在客户端完成,客户端要处理大量的逻辑,server 端只返回大量的数据;而 Redis 的计算发生在 Server 端,根据客户端请求返回指定的数据,客户端相对比较轻盈

Redis 中 value 值有五种数据类型,每种数据类型都有各自的方法,每种方法是和各自类型绑定的
除了 key-value 键值对中 value 有五种数据结构,在 key 中其实也有优化。key 中有一个 type 属性,会登记注册对应的 value 的类型,如果你非要用一个对 int 类型的方法来操作 string 类型的数据,就会直接报错——类型不匹配。除了 type 属性,key 中还有 encoding 类型,使用 object 命令可以观察 value 的 encoding 是 string 还是 int
Redis 开发者通过在 key 中内置的 type 和 encoding 两个小细节优化,大大减少了后续的数据类型判断,提高了 Redis 的响应能力。众所周知,Redis 最显著的特点就是快,其实 Redis 的快就是通过许多这样小小的细节优化,慢慢的把优势积累出来的。
一、String
Redis 进程里面是分为了 16 个独立的区域,即 16 个库,key 创建在不同的区域,其他的区域是看不到的、是隔离的
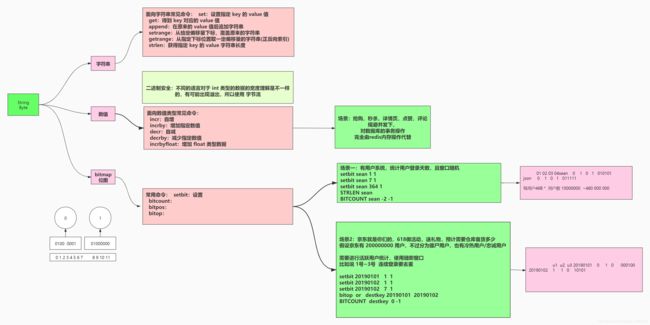
String 类型又分为字符串、数值、bitmap(位图)三种数据类型,面向每一种数据类型,都有各自的操作命令
1、字符串类型
面向字符串常见命令:
- set:设置指定 key 的 value 值
- get:得到 key 对应的 value 值
- append:在原来的 value 值后追加字符串
- setrange:从给定偏移量下标,覆盖原来的字符串
- getrange:从指定下标位置取一定偏移量的字符串(正反向索引)
- strlen:获得指定 key 的 value 字符串长度
2、数值类型
面向 string 类型数据,除了有针对字符串的指令之外,还有一些针对数值的操作:
- INCR:int 类型自增 1
- INCRBY:int 类型增加指定数值
- DECR:int 类型自减 1
- DECRBY:int 类型自减指定数值
- INCRBYFLOAT:int 类型加上 float 类型数据
我们通过这些命令可以像操作 int 类型数据一样,直接对 string 类型数据进行数值运算,它的底层实现可以归纳为二进制安全
应用场景:
- 抢购、秒杀、详情页、点赞数、评论数等等需要对数值进行增减操作的地方
二进制安全?
Redis 是支持多种语言连接的核心的中间件,不同的语言对于数据类型的理解是不一样的。有的语言认为 int 占两个字节,有的认为 int 占四个字节,如果用 int 存放一个占用 4 个字节的大整数,另外一种准备用 2 个字节接收的时候就会发现空间不够用,出现溢出错误
所以 Redis 在存放数据的时候,并不是使用字符流,而是使用字节流,一个字符占用一个字节,所以 9999 占用 4 个字节
说白了就是 Redis 底层存放数据的时候就是按照字节存放的,key 中的 encoding 只是在上层做了一些优化,如果没有 encoding 的话,每次进行运算的时候都要先进行类型判断,判断数据类型是否能够转换;而 key 中使用 encoding ,如果上次使用 int 类型做运算,解析成功了,那么这次的运算就不需要再进行判断,只需要直接进行运算即可
总结一下:所有使用 Redis 的用户,需要在用户端沟通好数据的编码和解码,Redis 里面是没有数据类型概念的
3、bitmap
bitmap 即位图,是 Redis 中最值钱的,也是最难理解的,精力不够,暂时略过
二进制位的数据在操作系统中,CPU 的运算速度是最快的,所以 bitmap 应用于快速运算有很大的优势
面向 bitmap 常见命令:
- set:设置位图
- bitpos:寻找第一个二进制位
- bitcount:统计 1 出现的次数
- bitop:
位图的应用场景:
- 用于滑动窗口
- 等等
二、list
Redis 中 key-value 键值对中的 value 也可以是 list 结构,是双向队列
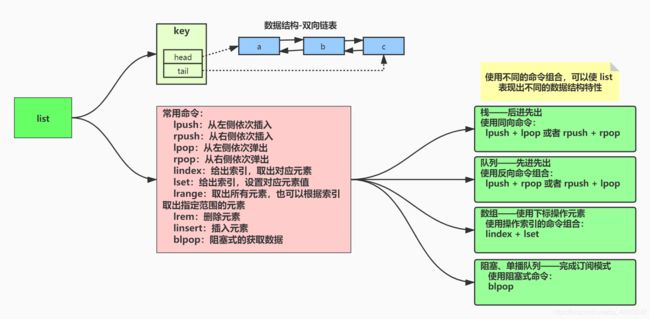
面向 list 结构常用命令:
- lpush:从左侧依次插入
- rpush:从右侧依次插入
- lpop:从左侧依次弹出
- rpop:从右侧依次弹出
- lindex:给出索引,取出对应元素
- lset:给出索引,设置对应元素值
- lrange:取出所有元素,也可以根据索引取出指定范围的元素
- lrem:删除元素
- linsert:插入元素
- blpop:阻塞式的获取数据
使用不同的命令组合,可以使 list 结构表现出不同的数据结构的特性
- 栈:栈的特点是先进后出,使用同向命令组合 lpush + lpop 或者 rpush + rpop
- 队列:队列的特点是先进先出,使用反向命令组合lpush + rpop 或者 rpush + lpop
- 数组:数组是有序的,使用索引来操作元素,使用命令 lindex + lset
- 阻塞队列(单播队列):使用阻塞式的命令,使队列一段阻塞,表现为单播对列,可用于发布——订阅模式。使用命令 blpop
三、hash
Redis 中 key-value 键值对中的 value 也可以是 hash 键值对结构,相当于 hashmap 里面又放了一层 hashmap,这其实也是我们见到过的用法
面向 Set 的命令:
HDEL key field [field ...]
summary: Delete one or more hash fields
since: 2.0.0
HEXISTS key field
summary: Determine if a hash field exists
since: 2.0.0
HGET key field
summary: Get the value of a hash field
since: 2.0.0
HGETALL key
summary: Get all the fields and values in a hash
since: 2.0.0
HINCRBY key field increment
summary: Increment the integer value of a hash field by the given number
since: 2.0.0
HINCRBYFLOAT key field increment
summary: Increment the float value of a hash field by the given amount
since: 2.6.0
HKEYS key
summary: Get all the fields in a hash
since: 2.0.0
HLEN key
summary: Get the number of fields in a hash
since: 2.0.0
HMGET key field [field ...]
summary: Get the values of all the given hash fields
since: 2.0.0
HMSET key field value [field value ...]
summary: Set multiple hash fields to multiple values
since: 2.0.0
HSCAN key cursor [MATCH pattern] [COUNT count]
summary: Incrementally iterate hash fields and associated values
since: 2.8.0
HSET key field value
summary: Set the string value of a hash field
since: 2.0.0
HSETNX key field value
summary: Set the value of a hash field, only if the field does not exist
since: 2.0.0
HSTRLEN key field
summary: Get the length of the value of a hash field
since: 3.2.0
HVALS key
summary: Get all the values in a hash
since: 2.0.0
以上解释在 redis 进程中使用命令行 help @hash 获得,由于不会设置高亮,感觉不是很简洁明了,所以后面还是不使用了
如果不支持 hash 这种 key-value 键值对的存储格式,存储键值对格式的数据将会很麻烦,使用 hash 进行设置的话就会很方便:
//设置单个 kev-value:对 key 为 5170203 的人的 value 进行设置姓名
hset 5170203 name mjt
//设置多个key-value:对 key 为 5170203 的人的 value 进行设置姓名、年龄、性别
hmset 5170203 name mjt age 18 gender man
此时可以使用 hgetall 命令,得到一个 key 的所有 key-value 属性,类似于面向对象的操作,减少请求的 IO 次数
四、set
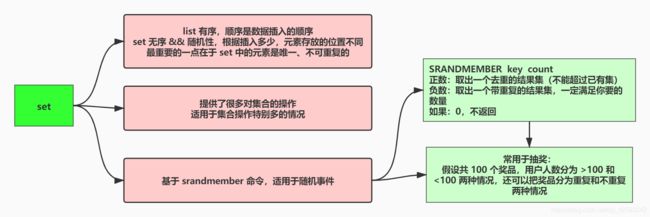
set 最需要记住的特点是元素唯一、适于集合操作、适合随机操作
面向 set 的命令:
SADD key member [member ...]
summary: Add one or more members to a set
since: 1.0.0
SCARD key
summary: Get the number of members in a set
since: 1.0.0
SDIFF key [key ...]
summary: Subtract multiple sets
since: 1.0.0
SDIFFSTORE destination key [key ...]
summary: Subtract multiple sets and store the resulting set in a key
since: 1.0.0
SINTER key [key ...]
summary: Intersect multiple sets
since: 1.0.0
SINTERSTORE destination key [key ...]
summary: Intersect multiple sets and store the resulting set in a key
since: 1.0.0
SISMEMBER key member
summary: Determine if a given value is a member of a set
since: 1.0.0
SMEMBERS key
summary: Get all the members in a set
since: 1.0.0
SMOVE source destination member
summary: Move a member from one set to another
since: 1.0.0
SPOP key [count]
summary: Remove and return one or multiple random members from a set
since: 1.0.0
SRANDMEMBER key [count]
summary: Get one or multiple random members from a set
since: 1.0.0
SREM key member [member ...]
summary: Remove one or more members from a set
since: 1.0.0
SSCAN key cursor [MATCH pattern] [COUNT count]
summary: Incrementally iterate Set elements
since: 2.8.0
SUNION key [key ...]
summary: Add multiple sets
since: 1.0.0
SUNIONSTORE destination key [key ...]
summary: Add multiple sets and store the resulting set in a key
since: 1.0.0
使用 set 的优势在于 set 中的元素唯一、不可重复
set 的另一个优势在于提供了许多对于集合的操作,支持集合的交集、并集和差集
同时基于 srandmember 命令,set 相当适合基于随机事件的场景
五、sorted_set
我们说 set 有很多好处,唯一不可重复,适用于集合操作和随机事件,不过 set 的缺点就是无序,有些需要顺序的情况下,就很难使用 set 结构。此时就可以使用 sorted_set
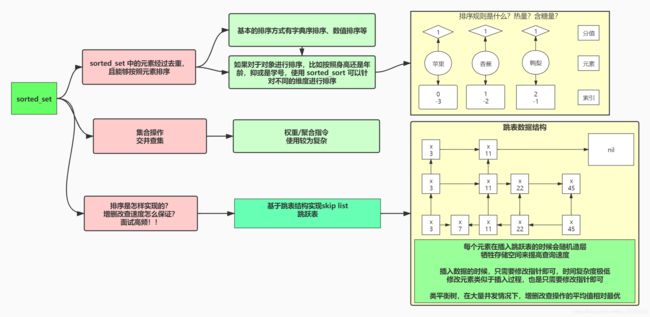
sorted_set 结构又称为有序集,是对 set 的优化,可以对数据去重还支持数据有序,这个顺序是对元素的排序
sorted_set 也是 Redis 中常用的东西,由排序可以引出如下概念:
- 元素:使用 sorted_sort 的时候有些命令是关注于元素,根据参数可以给出元素排名、分值
- 分值 score:给出分值区间,可以取出哪些元素
- 索引 index:给出索引,可以取出哪些元素
sorted_set 也是 set,同样适合于集合的操作,不过关于 sorted_set 的操作要注意权重问题,交并差集的指令稍微复杂一点,所以要多熟悉相关指令的使用细节
关于 sorted_set 面试也会常问其排序是怎样实现的?增删改查的速度是怎样保证的?——其核心点就是基于跳跃表的实现
总结:五种数据结构总结
关联文章:
Redis入门–万字长文详解epoll