大数据面试(java)题库汇总
文章目录
- 大数据面试
-
- 1. HDFS读写流程?
-
- 1.1 HDFS写流程
- 1.2 HDFS读流程
- 2 HDFS HA 架构
- 3 小文件给hadoop带来的瓶劲问题
-
- 3.1 造成问题
- 3.2 IO问题,性能问题如何解决?
- 4 flink 组件,作业提交流程?
-
- 4.1 组件?
- 4.2 任务提交流程?
-
- 4.2.1 standalone提交流程?
- 4.2.1 YARN提交流程?
- 4.3 flink如何优化?
- java 篇
-
- 1 反射概念
-
- 1.1 如何获取反射?
- 1.2 反射的应用,手写ORMMapper 框架
- 2 多线程
-
- 2.1 创建线程的方式?共同点异同点?
- 2.2 主线程获取子线程的返回值?
- 2.3 synchronized
- 2.4 线程wati(),notifyAll().notify()
- 2.5 synchronized与可重入锁ReenTrantLock区别?
- 3 JVM(JDK1.8)
-
- 3.1 自定义classLoader
- 3.2 Class.forName 与 ClassLoader区别loadClass区别
- 3.3 JVM 内存结构
- 3.4 JVM 垃圾回收机制
- 3.5 谈谈你所了解的垃圾回收机制?
- 3.6 JVM 新生代->老年代需要几次GC?
- 3.7 JVM 垃圾收集器
- 4 其他
-
- 4.1 volatile作用
- 4.2 实现简单的线程池?
- 4.3 多线程 实现生产者与消费者?
- 4.4 分布式锁
-
- 4.4.1 分布式锁常见的应用场景
- 4.4.2 分布式锁的实现方式
- 4.5 动态代理是什么?如何实现?
- 4.6 java中有哪些集合?这些集合的差别是什么?List与LinkList区别?
- 4.7 hasMap什么时候生成数组链表?
- 4.8 SpringMvc的处理流程?
- 4.9 SpringBoot与Spring,SpringMvc区别?
- 4.10 SpringBoot新增了哪些新特性的注解?
- 4.11 SpringBoot 对象循环引用的问题?如何解决?
- 4.12 什么是反射?
- 4.13 什么是泛型?
- 4.14 对线程的理解
- 4.15 如何优化锁
- 5 剑指offer算法题
-
- 5.1 从尾到头打印链表
- 5.2 反转链表
- 5.3 合并两个排序的链表
- 5.4 两个链表的第一个公共结点
- 5.5 链表中倒数最后k个结点
- 5.6 链表中环的入口结点
- 5.7 复杂链表的复制
- 5.8 删除链表中重复的结点
- 5.9 二叉树的深度
- 5.10 按之字形顺序打印二叉树
- 5.11 动态规划-跳台阶问题
- 5.12 动态规划-跳台阶扩展问题
大数据面试
1. HDFS读写流程?
1.1 HDFS写流程

1.clinet上传200M文件,client根据HDFS配置信息对文件进行拆分block1,block2
2.client 通知NameNode block1,block2存储,副本三份
3-4. NameNode进行权限等校验,根据内部算法合理的计算出block存储的dataNode节点,并将存储信息返回给client
5. client根据NameNode返回的信息先后进行block1,block2文件上传,在上传的过程中,其他两个副本存储是同步进行的,dataNode存储成功会通知nameNode已存储成功,所有的dataNode存储成功之后,nameNode通知client整个写流程结束。
1.2 HDFS读流程

1.Client执行:hadoop fs -get /spark/file.txt 获取文件
2.Client 通知nameNode获取文件的行为,nameNode从原数据获取文件的存储信息block0,,block1信息
3.Client 获取到存储信息直接从dataNode获取,获取成功后自动合并block,下载完成结束。
2 HDFS HA 架构
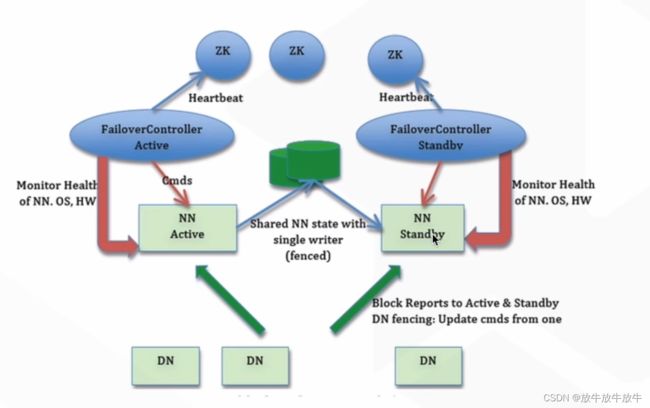
- 通过zookeeper组件,启动两个线程进行节点监控,存在宕机,自动切换
- nameNode主备之间数据,有同步机制
3 小文件给hadoop带来的瓶劲问题
3.1 造成问题
- 在处理批量文件,小文件太多,会造成多次的磁盘IO,大量的mapReduce,task资源的注册与销毁的开销(hadoop一个文件的处理正常对饮给一个mapReduce,task),造成文件读取时间远远大于数据消费处理的时间,从而导致这集群效率降低。
- 造成多个任务,作业处于等待,等待资源释放
- 小文件存储信息,都会以元数据的信息存储到nameNode。一方面,每条元数据信息会占用200字节左右存储空间,小文件过多,会提高内存的使用率。另一反面,集群启动,nameNode会从磁盘重新加载元数据,会大大的提高集群启动时间,重而导致在启动的过程当中无法提交或者处理任务。
3.2 IO问题,性能问题如何解决?
4 flink 组件,作业提交流程?
4.1 组件?
- dispatcher:它为应用提交提供了 REST 接口。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式。
- jobManager:JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的 JAR 包,而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
- resourcemanager:负责管理任务管理器(TaskManager)的插槽(slot),ResourceManager 还负责终止空闲的 TaskManager,释放计算资源。
- taskManager: 旗下有slots,作用是工作执行者。
4.2 任务提交流程?
4.2.1 standalone提交流程?

- app提交要执行的应用及参数。
- dispatcher启动并提到应用到jobManager
- jobManager对其提交的jar,参数分析生成作业图,逻辑数据流图及其需要的插槽资源等,将信息提交给resourceManager申请资源
4-6. resourceManager向taskmanager发出指令,启动申请相应的资源,无足够的资源则等待,等待超时job提交失败。 - taskManager提供足够的资源给jobManager,等待jobManage分配任务。
4.2.1 YARN提交流程?
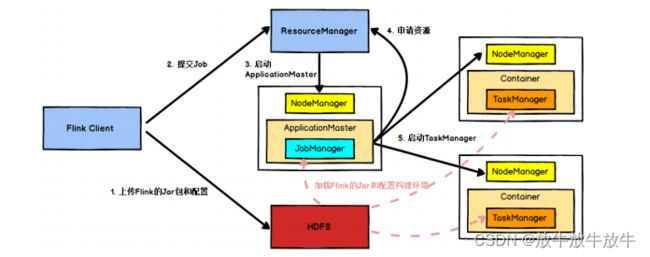
- client 向hdfs上传jar和配置信息
- 向Yaen 的ResourceManager申请启动JobManager资源,yarn通知NodeManager启动ApplicationMaster,启动jobManager并加载jar包和配置文件,jobManager分析生成作业图,数据流图和启动需要的资源。
- jobManager向Yanr的resourceManager申请资源
- resourceManager通知NodeManager创建container启动taskManager资源
- TaskManager启动后向 JobManager 发送心跳包,并等待 JobManager 向其分配任务。
4.3 flink如何优化?
- taskManager.numberOfTaskSlots 配置与服务器cpu一致,将cpu利用率提高到最高
- 提高核心任务job的并行度,提高服务器资源利用
- taskManager内存分配,根据实际的数据量,计算分析内存最高的使用率进行配置。
- 根据ExecutionGraph对任务链(算子链)做相关拆分优化
java 篇
1 反射概念
在程序运行时状态中,通过反射可以知道该类的所有属性和方法;对任意一个对象,通过反射可以调用其属性和方法;通过动态获取信息以及动态获取对象的方法功能称之为反射机制。
1.1 如何获取反射?
// 1 方式1
Class<?> clazz = Class.forName("类全路径")
// 2 方式2
Object obj = new Object();
Class<?> clazz = obj.getClass();
Class<?> clazz = Class.getClass();
1.2 反射的应用,手写ORMMapper 框架
略
2 多线程
2.1 创建线程的方式?共同点异同点?
// 1. 继承Thread
// 2. 实现Runnable
- 共同点:都要重写run方法,通过start启动
- 异同点:Thread本身就实现了Runnable,可以简单理解Thread是一个Runnable的加强类
2.2 主线程获取子线程的返回值?
- 主线程等待,直到获取到值。(不推荐)
- 使用线程的Thread.join()方法,阻塞等待线程使用在继续执行。(不推荐使用)
- Callbale接口,FetureTask机制
public static main(String[] args) throw Exception {
FetureTask<String> fetureTask = new FetureTask<String>(new Callable<String>() {
// 业务逻辑
return "字符串";
});
new Thread(fetureTask).start();
// fetureTask .get() 方法调用会阻塞,等待线程执行完成
System.out.println(fetureTask .get());
}
- Callbale接口,ExecutorServer线程池
2.3 synchronized
synchronized:可以解决线程处理共享数据(共享对象)造成的并发问题。synchronized锁的释放机制:当一个线程获取锁,需要等到线程抛出异常或者线程执行完毕才会释放锁,线程获取锁的期间,其他线程不能操作当前对象。
简单理解:synchronized修饰的方法是对对象加锁,修饰的static方法是对类加锁。
2.4 线程wati(),notifyAll().notify()
wati:线程等待
notifyAll:唤醒其他所有线程
notify:唤醒其他线程中的一个
注意:notify,notifyAll,notify需要在synchronized关键字中使用,防止异常现象产生
2.5 synchronized与可重入锁ReenTrantLock区别?
- 从实现的角度:Synchronized是依赖于JVM实现的,而ReenTrantLock是JDK实现的
- 性能发面:Synchronized与ReenTrantLock差不多;在两者均可用情况,官方建议使用Synchronized
- 功能上:Synchronized的使用比较方便简洁,并且由编译器去保证锁的加锁和释放;ReenTrantLock需要手动开启与释放
- 灵活度:ReenTrantLock比Synchronized灵活
3 JVM(JDK1.8)
3.1 自定义classLoader
3.2 Class.forName 与 ClassLoader区别loadClass区别
类的装载过程
- 加载:ClassLoader加载class字节码文件,生成class文件
- 链接:校验,准备,解析,分配指针
- 初始化:构造方法执行,初始化变量,静态代码块执行等
ClassLoader的loadClass:只完成了第一步,生成class
Class.forName:完成类装载的整个过程
3.3 JVM 内存结构
3.4 JVM 垃圾回收机制
- 判断对象是否是垃圾回收的标准
- 判断对象是否是垃圾回收的算法

3.5 谈谈你所了解的垃圾回收机制?
-
标记-清除算法
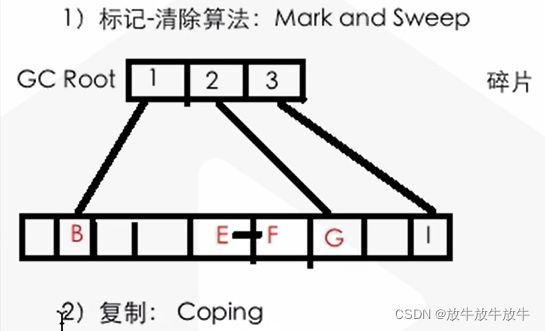
缺点:碎片化严重 -
复制算法

优点:无碎片化,简单高效
缺点:可使用的内存变少了(只剩50%),不适合用于老年代对象存储,原因:老年代数据过多,对象内存的重新复制分配排序低效 -
标记-整理算法
与标记-清除算法类似,不同点:标记-整理算法将被标记为垃圾的对象清除,将存活的对象进行整合顺序排序。此算法解决了:内存碎片化的问题,同时也解决了复制算法内存只能使用50%,但是缺点在处理耗时,适用于对象存活率高的场景:老生代。 -
分代收集算法
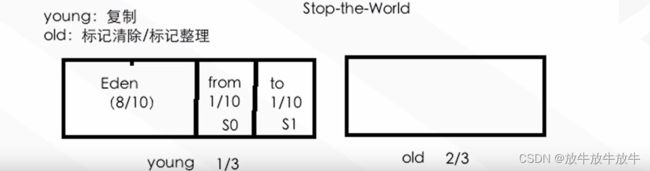
- 内存模型如上图,新创建的对象会添加到eden/from中的一个或者是eden/to中的一个。每经过一次GC,均会将eden及from的内存复制到to模块中。
- 新生代使用复制算法,老生代使用标记清楚/标记整理算法
- 当JVM在GC时,整个应用程序会停止工作stop the world),优化JVM主要目的是加快GC
3.6 JVM 新生代->老年代需要几次GC?
默认15次,新生代默认分配的内存占1/3,老年代默认分配的内存2/3。
内存分配模型如:

3.7 JVM 垃圾收集器
- 概念

jdk8 默认是G1。 - 垃圾回收器的搭配

4 其他
4.1 volatile作用
解决多线程中共享变量的可见性,以及指令防止指令重排序的问题。
https://blog.csdn.net/qq_45376284/article/details/113486716
4.2 实现简单的线程池?
import com.google.common.collect.Lists;
import org.springframework.util.CollectionUtils;
import java.util.*;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.atomic.AtomicInteger;
public class MyThreadPool {
private final AtomicInteger ctl = new AtomicInteger(0);
// 默认线程池大小
private static final int DEFAULT_THREAD_NUM = 5;
// 执行最大任务
private static final int DEFAULT_MAX_TASK = 20;
// 队列
private BlockingQueue<Runnable> queueRunnable;
// 当前线程池的线程数
private int current_thread_num;
// 当前线程池最大中任务数
private int current_max_task_num;
// 工作的线程
private Set<RunThread> workThread;
static MyThreadPool newFixThreadPool(Integer threadNum, Integer maxTask) {
return new MyThreadPool(threadNum, maxTask);
}
private MyThreadPool(Integer taskNum, Integer maxTask) {
if (Objects.isNull(taskNum) || taskNum <= 0) {
this.current_thread_num = DEFAULT_THREAD_NUM;
} else {
this.current_thread_num = taskNum;
}
if (Objects.isNull(maxTask) || maxTask <= 0) {
this.current_max_task_num = DEFAULT_MAX_TASK;
} else {
this.current_max_task_num = maxTask;
}
this.queueRunnable = new ArrayBlockingQueue<>(this.current_max_task_num);
this.workThread = new HashSet<>();
for (int i = 0; i < current_thread_num; i++) {
RunThread runThread = new RunThread("Thread pool-" + ctl.incrementAndGet());
runThread.start();
this.workThread.add(runThread);
}
}
public void submit(Runnable runnable) {
if (Objects.isNull(runnable)) {
return;
}
queueRunnable.add(runnable);
}
public void submit(List<Runnable> runnableList) {
if (CollectionUtils.isEmpty(runnableList)) {
return;
}
if(runnableList.size() > this.current_max_task_num) {
System.out.println("任务超标");
return;
}
queueRunnable.addAll(runnableList);
}
private final class RunThread extends Thread {
private String threadName;
public RunThread(String name) {
this.threadName = name;
}
@Override
public void run() {
try {
for (;;) {
Runnable runnable = queueRunnable.take();
if (Objects.nonNull(runnable)) {
System.out.println(threadName);
runnable.run();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* @describe 测试
* @param args
*/
public static void main(String[] args) {
int num = 20;
List<Runnable> runnableList = Lists.newArrayList();
MyThreadPool myThreadPool = MyThreadPool.newFixThreadPool(2, 20);
for (int i = 0; i < num; i++) {
runnableList.add(new TestThread(i));
}
myThreadPool.submit(runnableList);
}
public static class TestThread implements Runnable {
private int x;
public TestThread(int x) {
this.x = x;
}
@Override
public void run() {
System.out.println("TestThread:" + x);
}
}
}
4.3 多线程 实现生产者与消费者?
- TestThread
import org.springframework.util.CollectionUtils;
import java.util.Objects;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class TestThread {
public static void main(String[] args) {
QueueInfo queueInfo = new QueueInfo();
producer producer = new producer(queueInfo);
producer produce1 = new producer(queueInfo);
consumer consumer = new consumer(queueInfo);
consumer consumer1 = new consumer(queueInfo);
consumer consumer2 = new consumer(queueInfo);
producer.start();
consumer.start();
consumer1.start();
consumer2.start();
produce1.start();
}
public static class producer extends Thread {
private QueueInfo queueInfo;
public producer(QueueInfo queueInfo) {
this.queueInfo = queueInfo;
}
@Override
public void run() {
super.run();
ReentrantLock reentrantLock = this.queueInfo.getReentrantLock();
Condition condition = this.queueInfo.getCondition();
// 1. 获取锁 未获取 注释状态
while (true) {
reentrantLock.lock();
try {
// 如果队列满了,阻塞
while (Objects.equals(queueInfo.size(), queueInfo.getMAX())) {
System.out.println(super.getName() + ":队列已满:" + queueInfo.size() + ",等待消费");
Thread.sleep(2000);
condition.await();
}
this.queueInfo.addQueue(super.getName());
Thread.sleep(10);
// 唤醒其他线程
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
reentrantLock.unlock();
}
}
}
}
public static class consumer extends Thread {
private QueueInfo queueInfo;
public consumer(QueueInfo queueInfo) {
this.queueInfo = queueInfo;
}
@Override
public void run() {
super.run();
ReentrantLock reentrantLock = this.queueInfo.getReentrantLock();
Condition condition = this.queueInfo.getCondition();
// 消费逻辑
// 1. 获取锁 未获取 注释状态
while (true) {
// 加锁消费
reentrantLock.lock();
try {
// 如果队列无消息,通知生产数据
while(CollectionUtils.isEmpty(this.queueInfo)) {
System.out.println(super.getName() + ":已消费完成,等待生产者生产消息");
condition.await();
}
this.queueInfo.poolQueue(super.getName());
Thread.sleep(80);
// 消费完成 唤醒其他生产者或者消费者
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
reentrantLock.unlock();
}
}
}
}
}
- QueueInfo
import java.util.LinkedList;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class QueueInfo extends LinkedList<String> {
private final AtomicInteger atomicInteger = new AtomicInteger(0);
private Integer MAX = 20;
// 引入可重入锁
private final ReentrantLock reentrantLock = new ReentrantLock();
private final Condition condition = reentrantLock.newCondition();
public ReentrantLock getReentrantLock() {
return reentrantLock;
}
public Condition getCondition() {
return condition;
}
public void addQueue(String threadName) {
int i = atomicInteger.incrementAndGet();
super.add(i + "");
System.out.println(threadName + ": 生产了一条消息:" + i);
}
public void poolQueue(String threadName) {
String poll = super.poll();
System.out.println(threadName + ": 消费消息:" + poll);
}
public AtomicInteger getAtomicInteger() {
return atomicInteger;
}
public Integer getMAX() {
return MAX;
}
public void setMAX(Integer MAX) {
this.MAX = MAX;
}
}
4.4 分布式锁
4.4.1 分布式锁常见的应用场景
4.4.2 分布式锁的实现方式
redis,zookeeper
4.5 动态代理是什么?如何实现?
4.6 java中有哪些集合?这些集合的差别是什么?List与LinkList区别?
4.7 hasMap什么时候生成数组链表?
4.8 SpringMvc的处理流程?
4.9 SpringBoot与Spring,SpringMvc区别?
4.10 SpringBoot新增了哪些新特性的注解?
4.11 SpringBoot 对象循环引用的问题?如何解决?
4.12 什么是反射?
反射可以获取类的属性,方法,继承关系,可以动态的获取这些信息或者是执行操作。
4.13 什么是泛型?
泛型可以作为类或者是接口存储的对象或者是其描述的对象
4.14 对线程的理解
线程是一个程序执行过程中所需要的工作者。它由操作系统管理调度所有的线程,将线程分配到任何可用的cpu。线程初始化完成,通过调用run开始执行。当线程执行结束,会被回收。
4.15 如何优化锁
- 减少程序加锁的时间,只用在有现成安全的程序/代码块上。
- 减小所的颗粒度,比如tableMap(大锁)到concurrtHashMap锁使用差异(分段锁/颗粒锁)。
- 根据读写功能划分使用什么锁,写使用写锁,读使用读书。
5 剑指offer算法题
5.1 从尾到头打印链表

- 方式1:简易代码,耗时相对长,内存使用少
思路:递归将
/**
* public class ListNode {
* int val;
* ListNode next = null;
*
* ListNode(int val) {
* this.val = val;
* }
* }
*
*/
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
import java.util.Collections;
public class Solution {
List<Integer> list = new ArrayList<Integer>();
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
def(listNode);
Collections.reverse(list);
return (ArrayList<Integer>) list;
}
// 递归方法取值
private void def(ListNode listNode) {
if (Objects.nonNull(listNode)) {
list.add(listNode.val);
if(listNode.next != null) {
def(listNode.next);
}
}
}
}
结果:

5.2 反转链表

1, 思路:该提逻辑相对比较绕

/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode ReverseList(ListNode head) {
if(head==null)
return null;
ListNode pre = null;
ListNode next = null;
while(head!=null){
next = head.next;
head.next = pre;
pre = head;
head = next;
}
return pre;
}
}
5.3 合并两个排序的链表
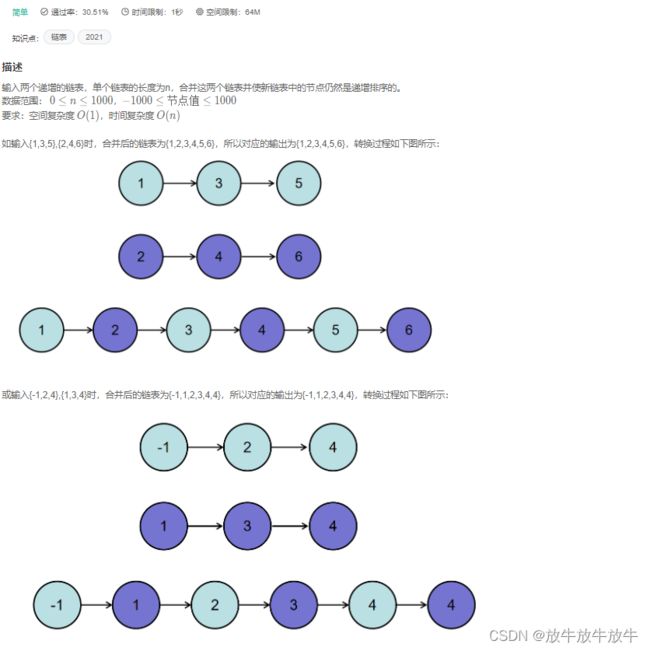

- 思路1:简单粗暴,将链表转成两个list,合并后通过stream升序排序,排序结束后循环创建链表关系,最后输出
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
public class Solution {
List<ListNode> mergeList = new ArrayList<>();
ListNode resultNode = null;
public ListNode Merge(ListNode list1, ListNode list2) {
List<ListNode> mergeList1 = anz(list1);
List<ListNode> mergeList2 = anz(list2);
mergeList1.addAll(mergeList2);
List<ListNode> mergeList = mergeList1.stream().map(node -> {
node.next = null;
return node;
})
.sorted((n, s) -> {
return n.val - s.val;
}).collect(Collectors.toList());
for (int i = 0; i < mergeList.size(); i++) {
ListNode listNode = mergeList.get(i);
if (i == 0) {
resultNode = listNode;
}
int nex = i + 1;
if (nex < mergeList.size()) {
listNode.next = mergeList.get(nex);
}
}
return resultNode;
}
public List<ListNode> anz(ListNode head) {
List<ListNode> resultList = new ArrayList<>();
if (Objects.isNull(head)) {
return resultList;
}
while (head != null) {
resultList.add(head);
if (head.next == null) {
break;
}
head = head.next;
}
return resultList;
}
}
- 思路2:同时不断遍历两个链表,取出小的追加到新的头节点后,直至两者其中一个为空
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode Merge(ListNode list1, ListNode list2) {
ListNode resultNode = new ListNode(0);
ListNode currNode = resultNode;
while (list1 != null || list2 != null) {
// 两个有序得链表,存在空直接返回另一个链表得剩余节点
if(list1 == null) {
currNode.next = list2;
break;
}
if(list2 == null) {
currNode.next = list1;
break;
}
if (list1.val <= list2.val) {
currNode.next = list1;
list1 = list1.next;
} else {
currNode.next = list2;
list2 = list2.next;
}
currNode = currNode.next;
}
return resultNode.next;
}
}
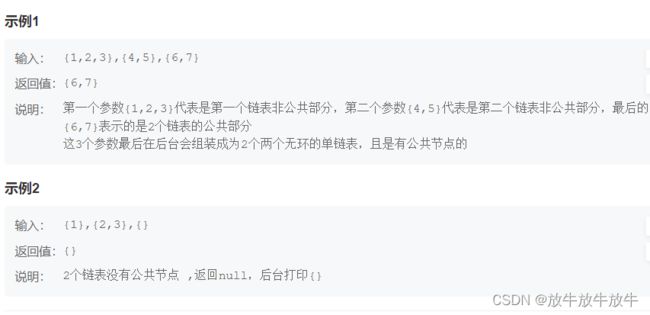
5.4 两个链表的第一个公共结点

/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if (pHead1 == null || pHead2 == null) {
return null;
}
ListNode currNode = null;
while (pHead1 != null) {
if (def(pHead1, pHead2)) {
currNode = pHead1;
break;
}
// 下一个
pHead1 = pHead1.next;
}
return currNode;
}
// 递归
private boolean def(ListNode pHead1, ListNode pHead2) {
while (pHead2 != null) {
if (compare(pHead1, pHead2)) {
return true;
}
pHead2 = pHead2.next;
}
return false;
}
public boolean compare(ListNode pHead1, ListNode pHead2) {
while (pHead1 != null && pHead2 != null) {
if (pHead1.val != pHead2.val) {
return false;
}
pHead1 = pHead1.next;
pHead2 = pHead2.next;
}
if (pHead1 == null && pHead2 == null) {
return true;
}
return false;
}
}
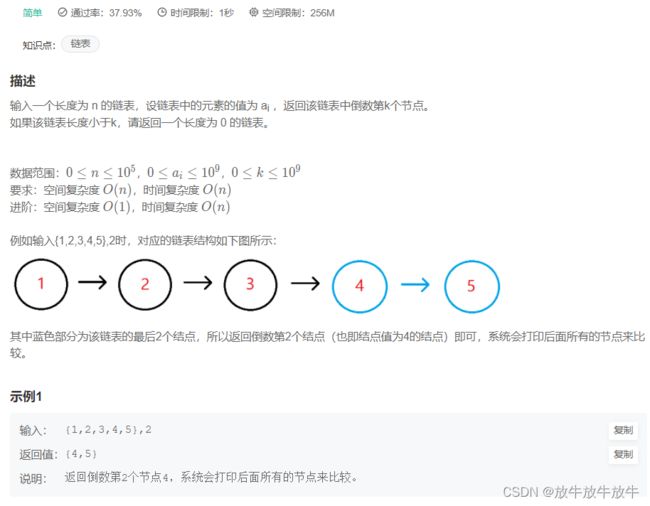
5.5 链表中倒数最后k个结点

- 思路1:list有序队列反转获取
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
import java.util.ArrayList;
import java.util.List;
public class Solution {
List<ListNode> list = new ArrayList<>();
public ListNode FindKthToTail (ListNode pHead, int k) {
while (pHead != null) {
list.add(pHead);
pHead = pHead.next;
}
// 获取倒数k个
if(k > list.size() || k == 0){
return null;
}
// 1 2 3 4 5 5
return list.get(list.size() - k);
}
}
- 思路2:压栈做法
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
import java.util.Stack;
// 压Stack
public class Solution {
Stack<ListNode> stack = new Stack<>();
public ListNode FindKthToTail(ListNode pHead, int k) {
if (k == 0) {
return null;
}
while (pHead != null) {
stack.add(pHead);
pHead = pHead.next;
}
// 获取倒数k个
if (k > stack.size() || k == 0) {
return null;
}
ListNode resNode = null;
while (k > 0) {
k--;
resNode = stack.pop();
}
return resNode;
}
}
5.6 链表中环的入口结点


- 思路:利用set的特性,存在第一个重复直接返回
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
import java.util.HashSet;
import java.util.Set;
public class Solution {
Set<Integer> set = new HashSet<>();
public ListNode EntryNodeOfLoop(ListNode pHead) {
while (pHead != null) {
if (!set.add(pHead.val)) {
return pHead;
}
pHead = pHead.next;
}
return null;
}
}
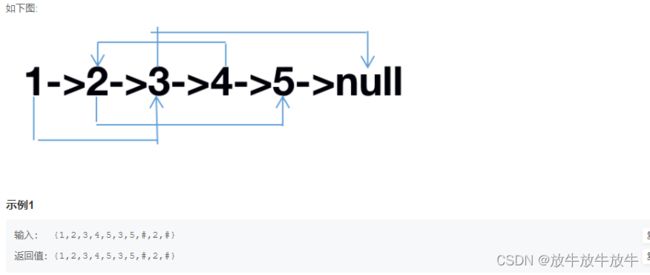
5.7 复杂链表的复制

- 思路:首先遍历主节点,将新节点存储到Map集合中。随机节点后续循环做映射
/*
public class RandomListNode {
int label;
RandomListNode next = null;
RandomListNode random = null;
RandomListNode(int label) {
this.label = label;
}
}
*/
import java.util.*;
public class Solution {
RandomListNode root = new RandomListNode(-1);
Map<RandomListNode, RandomListNode> map = new HashMap<>();
public RandomListNode Clone(RandomListNode pHead) {
if (pHead == null) {
return null;
}
RandomListNode currNode = root;
// 1. 先复制单节点
while (pHead != null) {
// 复制节点
RandomListNode newNode = new RandomListNode(pHead.label);
currNode.next = newNode;
currNode = currNode.next;
map.put(pHead, currNode);
pHead = pHead.next;
}
// 2. 节点映射
for (RandomListNode keyNode : map.keySet()) {
RandomListNode randomListNode = map.get(keyNode);
randomListNode.random = map.get(keyNode.random);
}
return root.next;
}
}
5.8 删除链表中重复的结点
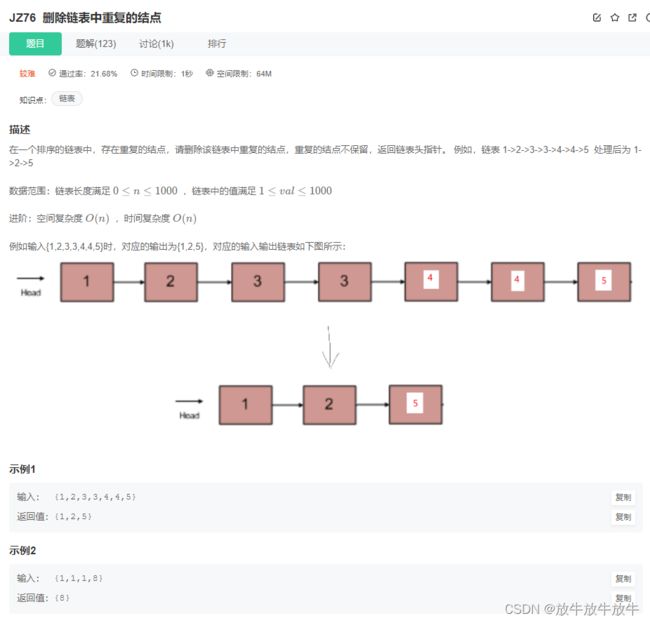
- 思路:通过set,queue,map结合循环处理
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
import java.util.*;
public class Solution {
Set<Integer> set = new HashSet();
// 存储所有节点 去重
Queue<ListNode> queue1 = new LinkedList<>();
// 存储重复节点
Map<Integer, Boolean> map = new HashMap<>();
public ListNode deleteDuplication(ListNode pHead) {
if (pHead == null) {
return null;
}
while (pHead != null) {
// success 没有重复
if (set.add(pHead.val)) {
queue1.add(pHead);
} else {
map.put(pHead.val, true);
}
pHead = pHead.next;
}
ListNode resultNode = new ListNode(0);
ListNode currNode = resultNode;
for (ListNode node: queue1) {
if(map.containsKey(node.val)) {
continue;
}
node.next = null;
currNode.next = node;
currNode = currNode.next;
}
return resultNode.next;
}
}
5.9 二叉树的深度

- 思路:递归算出左右节点的最大深度,返回最大值
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public int TreeDepth(TreeNode root) {
if (root == null) {
return 0;
}
return def(root, 1);
}
private int def(TreeNode node, int i) {
// 当前节点为null 或者 左右节点均为null 表示到达最深度
if (node == null|| (node.right == null && node.left == null)) {
return i;
}
i++;
int lef = def(node.left, i);
int rig = def(node.right, i);
return lef > rig ? lef : rig;
}
}
5.10 按之字形顺序打印二叉树

- 思路:将树的每一层看作队列,从左开始输出,偶数倒序
import java.util.ArrayList;
/*
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Queue;
public class Solution {
public ArrayList<ArrayList<Integer>> Print(TreeNode pRoot) {
if(pRoot == null) {
return new ArrayList<>();
}
Queue<TreeNode> q = new LinkedList<>();
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
// 奇数左=>右 偶从右=>左
int index = 1;
q.add(pRoot);
while (!q.isEmpty()) {
// 当前有几个节点
ArrayList<Integer> lineList = new ArrayList<>();
int max = q.size();
for (int i = 0; i < max; i++) {
TreeNode currNode = q.poll();
lineList.add(currNode.val);
// 左到右设置节点
if (currNode.left != null) {
q.add(currNode.left);
}
if (currNode.right != null) {
q.add(currNode.right);
}
}
res.add(lineList);
if (index % 2 == 0) {
Collections.reverse(lineList);
}
index++;
}
return res;
}
}
5.11 动态规划-跳台阶问题
- 思路:公式法
f(n)=f(n-1)+f(n-2) n > 2
f(1) = 1
f(2)=2
public class Solution {
public int jumpFloor(int n) {
if(n == 1) {
return 1;
}
if(n == 2) {
return 2;
}
return jumpFloor(n - 1) + jumpFloor(n-2);
}
}
5.12 动态规划-跳台阶扩展问题

- 思路; 公式法
f(n)=2*f(n-1) n>2
f(1)=1
public class Solution {
public int jumpFloorII(int n) {
if(n == 1) {
return 1;
}
return 2*jumpFloorII(n - 1);
}
}