YOLOv5基础知识入门(3)— 目标检测相关知识点

前言:Hello大家好,我是小哥谈。YOLO算法发展历程和YOLOv5核心基础知识学习完成之后,接下来我们就需要学习目标检测相关知识了。为了让大家后面可以顺利地用YOLOv5进行目标检测实战,本节课就带领大家学习一下目标检测的基础知识点,希望大家学习之后有所收获!
 前期回顾:
前期回顾:
YOLOv5基础知识入门(1)— YOLO算法的发展历程
YOLOv5基础知识入门(2)— YOLOv5核心基础知识讲解
目录
1.目标检测
2.目标检测数据集
2.1 PASCAL VOC数据集
2.2 MS COCO数据集
3.目标检测性能指标
3.1 检测精度指标
3.2 检测速度指标

1.目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小,是机器视觉领域的核心问题之一。由于各类物体有不同的外观、形状、姿态,再加上成像时的光照、遮挡等因素的干扰,目标检测一直是机器视觉领域最具有挑战性的问题。
计算机视觉中关于图像识别有四大类任务:
- 分类(Classification):解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位(Location):解决“在哪里?”的问题,即定位出这个目标的的位置。
- 检测(Detection):解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物体是什么。
- 分割(Segmentation):分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
说明:
百科定义:♨️♨️♨️
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割。它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。尤其是在复杂场景中,需要对多个目标进行实时处理时,目标自动提取和识别就显得特别重要。随着计算机技术的发展和计算机视觉原理的广泛应用,利用计算机图像处理技术对目标进行实时跟踪研究越来越热门,对目标进行动态实时跟踪定位在智能化交通系统、智能监控系统、军事目标检测及医学导航手术中手术器械定位等方面具有广泛的应用价值。
关于目标检测,具体如下图所示:
用YOLOv5进行目标检测,我们需要解决所检测目标的定位和识别问题。
定位(Localization):解决的是目标“在哪里?”的问题,即需要获知目标位置(最小外接矩形,Bounding box)。
识别(Recognition):解决的是目标“是什么?”的问题,即需要获知目标的类别标签(Category label)和置信度得分(Confidence score)。
说明:
置信度:♨️♨️♨️
置信度是介于0-1(或100%)之间的数字,它描述模型认为此预测边界框包含某类别目标的概率。通俗来说,即有多大概率确定所检测的物体是某物体。
同时,除了目标检测,还有分类、定位、实例分割等任务。
定位是找到检测图像中带有一个给定标签的单个目标 。
检测是找到图像中带有给定标签的所有目标。
2.目标检测数据集
目标检测需要使用到数据集,本节课就给大家介绍一下目标检测领域常用的PASCAL VOC和MS COCO数据集。
2.1 PASCAL VOC数据集
PASCAL VOC挑战赛在2005年至2012年间展开。PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。很多优秀的计算机视觉模型比如分类、定位、检测、分割、动作识别等模型都是基于PASCAL VOC挑战赛及其数据集上推出的,尤其是一些目标检测模型(比如大名鼎鼎的R-CNN系列,以及后面的YOLO、SSD等)。
PASCAL VOC从2005年开始举办挑战赛,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测、分割、人体布局、动作识别(Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification)等内容,数据集的容量以及种类也在不断的增加和改善。该项挑战赛催生出了一大批优秀的计算机视觉模型(尤其是以深度学习技术为主的)。
PASCAL VOC 2007: 9963张图像,24640个标注。
PASCAL VOC 2012: 11530 张图像,27450个标注。
该数据集有20个分类:
- Person: person
- Animal: bird、cat、cow、dog、horse、sheep
- Vehicle: aeroplane、bicycle、boat、bus、car、motorbike、train
- Indoor: bottle、chair、dining table、potted plant、sofa、tv/monitor

说明:
链接: The PASCAL Visual Object Classes Challenge 2012 (VOC2012)
2.2 MS COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于 2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、 Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
COCO(Common Objects in Context)数据集包含20万个图像:11.5万多张训练集图像, 5千张验证集图像,2万多张测试集图像。80个类别中有超过50万个目标标注,平均每个图像的目标数为7.2。
说明:
链接:COCO - Common Objects in Context (cocodataset.org)
3.目标检测性能指标
目标检测的性能指标包括检测精度(检测效果是否足够好)和检测速度(检测速度是否足够快)。
检测精度指标:
- Precision, Recall, F1 score
- IoU (Intersection over Union)
- P-R curve (Precison-Recall curve)
- AP (Average Precision)
- mAP (mean Average Precision)
检测速度指标:
- 前传耗时
- 每秒帧数 FPS (Frames Per Second)
- 浮点运算量(FLOPS)
3.1 检测精度指标
(1)混淆矩阵(confusion matrix)
混淆矩阵(confusion matrix),是对分类问题预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,显示了分类模型进行预测时会对哪一部分产生混淆。通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了(即把一个类错认成了另一个)。
混淆矩阵不仅可以让我们直观的了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生,正是这种对结果的分解克服了仅使用分类准确率带来的局限性(总体到细分)。❤️

总结:
精度Precision(查准率)是评估预测的准不准(看预测列)
召回率Recall(查全率)是评估找的全不全(看实际行)
(2)IoU (Intersection over Union )
IoU(Intersection over Union,IoU),即两个边界框相交面积与相并面积的比值,边界框的准确度可以用IoU进行表示;一般约定,在检测中,IOU>0.5,则认为检测正确,IOU<0.5,则认为检测错误。一般阈值设为0.5(需要根据实际情况进行设定)。
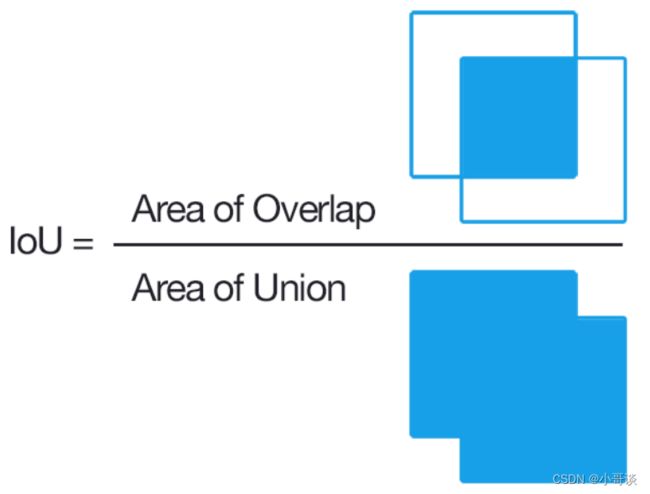
说明:
IoU与混淆矩阵的关系:♨️♨️♨️
如果阈值设为0.5,那么
如果IOU ≥ 0.5,则认为检测正确,归类为TP。
如果IOU<0.5,则认为检测错误,归类为FP。
当图像中存在一个真实目标,而未能检测到目标时,将其归类为FN。
当没有检测某图像的物体时(即没有对该图像进行检测,该图像其实没有用处),将其归类为TN。
(3)P-R curve
P-R curve (Precison-Recall curve)曲线体现的是精确率和召回率的关系。在准确率很高的前提下,尽可能的检测到全部的类别。因此希望我们的曲线接近(1,1),即希望曲线的面积尽可能接近1。

(4)AP和mAP
AP (Average Precision),衡量的是学习出来的模型在每个类别上的好坏。
mAP (mean Average Precision),衡量的是学习出来的模型在所有类别上的好坏。mAP就是取所有类别上AP的平均值。

用一个简单的例子来演示平均精度(AP)的计算。 假设数据集中总共有5个苹果。 我们收集模型为苹果作的所有预测(以10次预测举例),并根据预测的置信水平(从最高到最低)对其进行排名。 第二列表示预测是否正确。 如果它与 ground truth匹配并且IoU≥0.5,则是正确的。
由下图可以看到,Recall随着包含更多预测而增加,但Precision会上下波动。

3.2 检测速度指标
前传耗时(ms):从输入一张图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)。
说明:
关于非极大值抑制,请参考我的另外一篇文章:♨️♨️♨️
目标检测中NMS(非极大值抑制)原理解析
每秒帧数 FPS(Frames Per Second):每秒钟能处理的图像数量 。
FPS是图像领域中的定义,是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的动作就会愈流畅。通常,要避免动作不流畅的最低是30。
浮点运算量(FLOPS):处理一张图像所需要的浮点运算数量,跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速度。