1. 登陆
迅雷离线下载的第一步需要使用账号登陆,网页的登陆页面是:
http://lixian.xunlei.com/login.html
首先,迅雷服务器验证账号和密码的地址为:
https://login.xunlei.com/sec2login
https://login2.xunlei.com/sec2login
https://login3.xunlei.com/sec2login
以上任意一个地址(服务器)都可以验证,迅雷离线页面采取某种算法随机选择一个。
然后,向服务器提交的数据,包括以下几个:
| 参数名 |
含义 |
说明 |
| p |
加密后的密码 |
|
| u |
账号 |
|
| n, e |
n和e组成了加密算法的公钥 |
|
| verifycode |
验证码 |
|
| login_enable |
是否自动登陆 |
|
| business_type |
值为108 |
未明 |
| v |
值为100 |
未明 |
| cachetime |
客户端当前时间(毫秒数) |
|
在向服务器提交数据的时候,唯一需要注意的就是这个请求的Cookie字段,因为n,e,verifycode这几个重要的参数都是通过Cookie传递的,而获取这几个参数的地址为:
https://login.xunlei.com/check/
发送这个请求需要携带以下几个参数:
| 参数名 |
含义 |
说明 |
| u |
账号 |
|
| business_type |
值为108 |
未明 |
| cachetime |
客户端当前时间(毫秒数) |
|
服务器返回的参数都是放在了Cookie里面,主要有以下几项:
| 参数名 |
含义 |
备注 |
| check_result |
是否需要验证码 |
|
| check_n, check_e |
加密算法公钥,base64编码 |
|
| verify_type |
验证类型 |
|
| VERIFY_KEY |
没用到 |
未明 |
其中,check_result 有两部分组成,格式为:
数值 : 验证码
如果冒号前面的数值为0,那么表示该账号登陆无需额外输入验证码,直接使用冒号后面的验证码(感叹号开头,后面跟3位字母或数字);如果冒号前面的数值为1,表示该账号需要额外输入验证码。
一个示例请求,如下图所示(无需验证码的情况):
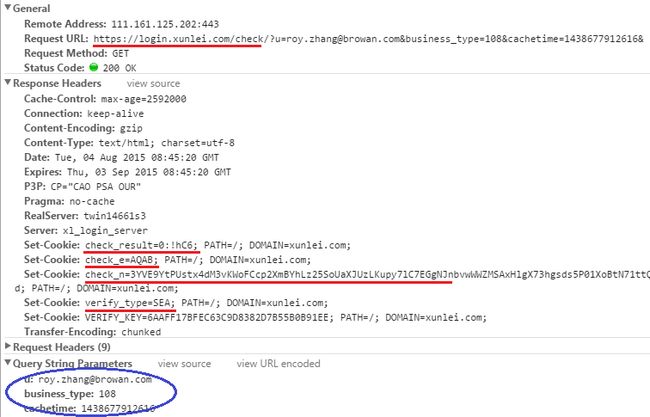
成功登陆后,服务器返回的Cookie:

所以登陆的过程为:
第一步:向 https://login.xunlei.com/check 发起请求,获取Cookie信息供第二步使用;
第二步:向 https://login.xunlei.com/sec2login 发起请求,登陆成功,获取Cookie以及Session ID。
1.1 密码
登陆过程最关键的难点就在于密码的加密算法,迅雷采用的是安全性很高的RSA加密算法。RSA加密算法介绍参见维基百科:https://en.wikipedia.org/wiki/RSA
客户端(浏览器)只需获取公钥完成对密码加密,迅雷服务器根据私钥进行解密并验证密码。所以客户端和第三方基本无法破解原始密码。
迅雷使用的RSA算法的JS代码(只有加密):
http://i.xunlei.com/login/lib/rsa.js
下面简单介绍一下密码加密的过程。加密的过程是在
http://i.xunlei.com/login/2.5/xlQuickLogin.min.js
里面的request() 函数内,case "login"分支。
var kn = Util.getCookie("check_n"); var ke = Util.getCookie("check_e"); var rsa = new RSAKey(); rsa.setPublic(b64tohex(kn), b64tohex(ke)); var code = data.captcha.toUpperCase(); var pwd = hex2b64(rsa.encrypt(md5(data.password) + code));
(1) 从Cookie获取check_n和check_e,用base64解码之后,作为RSA的公钥;
(2) 先计算密码的MD5值(十六进制小写),然后和验证码(全部转大写)共同组成字符串,使用RSA计算密文;
(3) 将RSA密文使用base64编码。
在这里我们可以根据check_n的值,看到RSA的公钥长度为1024位,安全系数很高。
RSA加密的过程,有一步是需要填充字符串,填充方法有两种:PCKS #1和OAEP。PCKS #1的方法是:
00 02 Padding-String 00 Message
可以看到,原始的文本放到最后,Padding-String 的长度为总长度减去原始文本长度再减去3,这个序列的总长度为公钥的长度,单位是字节,所以这里是128. Padding-String就是一串随机数。由于Message是由一个MD5值和验证码组成的,MD5值长度为32,验证码长度为4,因此可以得知Padding-String的长度为 89. 同时,Padding-String 里面不能包含 00. 详细的说明可参考:
RFC 3447 : Public-Key Cryptography Standards (PKCS) #1: RSA Cryptography Specifications Version 2.1 https://tools.ietf.org/html/rfc3447
OAEP 的方法是:
Message 00 Padding-String
即原始文本在最前面,然后填充 00,然后是填充字符串,填充字串不能包含00. 详细的说明可参考维基百科:
https://en.wikipedia.org/wiki/Optimal_asymmetric_encryption_padding
可以看到,由于填充算法不同,即使使用相同的RSA公钥,其生成的密文也不一样,在解密时也会有区别。迅雷使用的是第二种。在这个地方微小的差别,浪费了我很多的时间。
1.2 验证码
请求验证码的URL为:
http://verify1.xunlei.com/image
http://verify2.xunlei.com/image
http://verify3.xunlei.com/image
使用任何一个地址都可以,这个请求需要携带的参数:
| 参数名 |
含义 |
说明 |
| t |
验证类型,即上面提到的verify_type |
|
| cachetime |
客户端当前时间(毫秒数) |
|
验证码为4个字符,每个字符都是字母或数字。此时,使用验证码输入框内的字符代替 check_result 这个 Cookie携带的验证码。
2. 查看当前任务
通过登陆验证之后,就可以访问
http://dynamic.cloud.vip.xunlei.com/user_task
来获取用户离线下载的任务了。这个请求需要携带的参数:
| 参数名 |
含义 |
说明 |
| userid |
用户ID |
不是用户名 |
| st |
值为4 |
未明 |
| p |
第几页 |
可以没有 |
在 http://lixian.xunlei.com/login.html 的 enter() 函数里面有这么一行代码:
window.location.href = 'http://dynamic.cloud.vip.xunlei.com/user_task?userid=' + matches[1] + '&st=4';
所以不明st为4的含义。
迅雷默认每页显示25(?)个任务,如果任务有多页,可以在请求的地址上加上 p= 参数。通过分析页面的HTML,可以看到每个任务有几个属性:
| 属性名 |
含义 |
说明 |
| dflag |
未明 |
|
| durl |
未明 |
|
| dcid |
未明 |
|
| dl_url |
离线下载地址 |
只有VIP账号才会有这个属性,普通用户没有 |
| bt_down_url |
BT下载地址 |
|
| bt_movie |
未明 |
|
| f_url |
原始URL |
|
| d_status |
未明 |
|
| d_tasktype |
未明 |
|
| taskname |
任务名称 |
|
| ref_url |
原始下载页面 |
|
| ysfilesize |
原始文件大小 |
单位:字节 |
| verify |
校验码 |
算法未知,一般用MD5 |
| ifvod |
是否可以视频点播 |
|
| vodurl |
视频点播地址 |
|
|
开放格式 |
movie, bt, image, rar, music等 |
进度是放在了 标签之间。
3. 添加任务
3.1 普通URL
向迅雷添加普通的下载地址,有两个步骤:
(1) 检查地址
向 http://dynamic.cloud.vip.xunlei.com/interface/task_check 发送一个请求,携带的参数如下:
| 参数名 |
含义 |
说明 |
| callback |
回调函数 |
填入queryCid,可忽略 |
| url |
下载链接 |
|
| interfrom |
|
值task |
| random |
随机数 |
|
| tcache |
防止缓存 |
|
参数random的算法,网页中是这样的:
TrimPath.parseTemplate_etc.modifierDef.random=function(){ return new Date().getTime().toString() + (Math.random()*(2000000-10)+10).toString(); }
即在当前时间(毫秒数)后面加一个[10, 2000000)之间的随机数(浮点数)。tcache是为了浏览器从缓存中获取数据。
取得的响应如下:
queryCid('38BEAB6CA218557CA5B57E85712F8954ECEC2206', '4D69C4E3DABB7C578CBDB94A133CA53FA2710EE7', '688914432','3377655951167334',
'archlinux-2015.08.01-dual.iso', '0','0', 0,'1438844515342488243.8073119521','','0')
queryCid的原型如下:
function queryCid(cid,gcid,file_size,avail_space,tname,goldbean_need,silverbean_need,is_full,random,type,rtcode){ ... }
红色标出的几个在第二步中需要使用。
(2) 提交新任务
真正新建任务时,在网页上点击按钮“开始下载”,会向下面地址发送请求:
http://dynamic.cloud.vip.xunlei.com/interface/task_commit
携带的参数如下:
| 参数名 |
含义 |
说明 |
| callback |
网页回调函数 |
ret_task |
| uid |
用户ID |
|
| cid |
|
check_task获取 |
| gcid |
|
check_task获取 |
| size |
|
check_task获取 |
| goldbean |
|
check_task获取 |
| silverbean |
|
check_task获取 |
| t |
文件名称 |
check_task获取tname |
| url |
原始下载地址 |
|
| type |
下载类型 |
check_task获取 |
|
|
填history |
|
|
填0 |
| class_id |
分类信息 |
0,全部任务 |
| database |
|
undefined |
| interfrom |
|
填task |
| verify_code |
验证码 |
如果没有就留空 |
| time |
当前时间 |
|
| noCacheIE |
防止缓存 |
|
下载类型有如下定义:
| 下载类型 |
type值 |
检验方法 |
| 磁力链 |
4 |
包含“magnet:” |
| 迅雷链接 |
3 |
包含“thunder://” |
| 电驴链接 |
2 |
包含“ed2k://” |
| BT种子 |
1 |
包含“.torrent”或者“get_torrent?userid=” |
| 其他 |
0 |
|
请求的响应如下:
ret_task(1,'1038026251769089','0.42461609840393')
这个函数的原型如下:
function ret_task(ret_num,taskid,time){ ... }
第一个参数表示是否成功,0表示失败,1表示成功;如果成功了,第二个参数就是新添加的任务的ID。
迅雷在这个步骤中分了两种情况:
(a) 如果是BT文件,那么就会向
http://dynamic.cloud.vip.xunlei.com/interface/url_query
发送一个请求,该请求携带的参数和task_check相同,除了将url替换为u
这个请求的回调函数是queryUrl,服务器会返回该BT文件所包含的每个文件的名称、类型、图标、大小等信息,网页端收到后进行显示;
(b) 其他文件,执行相同的流程。
下载任务添加成功后,网页会发起一个showtask_unfresh的请求,请求携带的page/p/tasknum都为1。该请求的详细说明参见下节“任务进度”。
3.2 BT文件
前面提到的BT文件是以链接的形式提供,本小节所说的BT文件是通过直接上传来提交到迅雷服务器。
上传文件,是浏览器向服务器POST一个请求,这个请求的地址为:
http://dynamic.cloud.vip.xunlei.com/interface/torrent_upload
请求携带的 Content-Type 这个头必须为 multipart/form-data。详细说明可参考这个页面:http://www.w3.org/Protocols/rfc1341/7_2_Multipart.html
这个请求携带的参数:
| 参数名 |
含义 |
说明 |
| random |
随机数 |
见上小节“普通URL”部分random描述 |
| interfrom |
task |
|
| filepath |
文件名 |
|
请求的响应是一段包含在 之间的代码,上传的结果用变量 btResult 来表示:
var btResult ={ "ret_value":1, "infoid":"828E86180150213C10677495565BAEF6B232DBDD", "ftitle":"archlinux-2015.08.01-dual.iso", "btsize":688953422, "is_full":"0", "filelist":[ { "id":"0", "subsize":"688914432", "subformatsize":"657M", "file_icon":"RAR", "valid":1, "findex":"0", "subtitle":"archlinux-2015.08.01-dual.iso", "ext":"iso", "is_blocked":0 } ], "random":"1438864263456261213.74925996875" };
如下图所示:
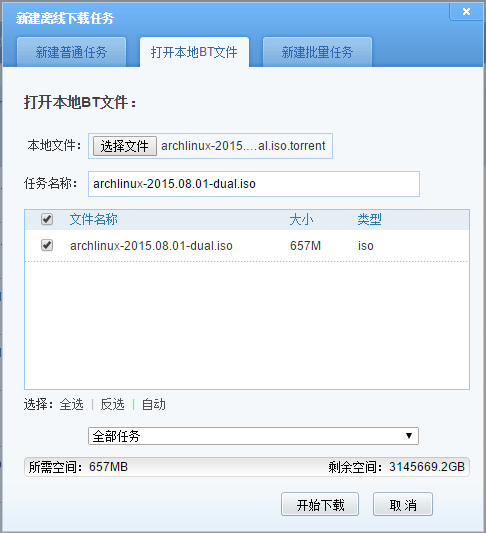
btResult 中的属性和值都很明确,这里不作说明。点击开始下载后,向
http://dynamic.cloud.vip.xunlei.com/interface/bt_task_commit
提交一个请求,这个请求携带的参数:
| 参数名 |
含义 |
说明 |
| callback |
网页回调函数 |
|
| t |
当前时间 |
|
| uid |
用户ID |
|
| btname |
BT名称 |
将来会在任务列表中用该名字显示 |
| cid |
|
BtResult中的infoid |
| goldbean |
|
|
| silverbean |
|
|
| tsize |
BT包含文件的总大小 |
|
| findex |
要下载的每个文件的索引 |
如果有多个,用下划线“_”分隔 |
| size |
要下载的每个文件的大小 |
如果有多个,用下划线“_”分隔 |
|
|
0 |
|
上面的interfrom属性 |
task |
| class_id |
分类目录 |
0,全部任务 |
| interfrom |
|
task |
| verify_code |
验证码 |
如果没有则留空 |
这个请求的响应如下:
jsonp1438863023246({"id":"1038213134292225","avail_space":"3377512162541400","time":0.55812907218933,"progress":1})
响应的参数是一个JSON对象,id表示任务ID,avail_space表示剩余空间,progress的含义:
| 值 |
含义 |
| 1 |
提交成功 |
| 2 |
任务无法提交 |
| -11,-12 |
需要验证码 |
同样的,添加任务后,网页会向showtask_unfresh发送一个请求,获取最新添加的任务的信息。这个请求请参见下节“任务进度”。
4. 任务进度
在显示了用户任务之后,向
http://dynamic.cloud.vip.xunlei.com/interface/showtask_unfresh
发起一个请求,携带的参数:
| 参数名 |
含义 |
说明 |
| callback |
网页回调函数,可以忽略 |
|
| t |
当前时间 |
Wed Aug 05 2015 14:36:40 GMT+0800 (中国标准时间) |
| type_id |
未明 |
|
| page |
第几页 |
|
| tasknum |
每页任务数 |
|
| p |
第几页,和page重复 |
|
| interfrom |
值为task |
|
l 关于t的时间格式,多做一点说明:在网页Javascript代码中,t就是一个Date对象,在转换成字符串时,默认的格式每种浏览器的格式不尽相同:
| 浏览器 |
Date 格式 |
| Internet Explorer 11 |
Wed Aug 05 2015 14:36:40 GMT+0800 (中国标准时间) |
| Mozilla Firefox 39 |
Wed Aug 05 2015 14:36:40 GMT+0800 |
| Google Chrome 44 |
Wed Aug 05 2015 14:36:40 GMT+0800 (中国标准时间) |
可以通过这个页面进行测试:http://www.w3school.com.cn/tiy/t.asp?f=jseg_tostring
Python 的 time 模块的 strftime 可以使用自定义的格式来输出时间,但是strftime的实现依赖于操作系统,尤其对于时区,z和Z来说:
(1) Windows平台,MSDN上查到的说明如下:
%z, %Z Either the time-zone name or time zone abbreviation, depending on registry settings; no characters if time zone is unknown
https://msdn.microsoft.com/en-us/library/fe06s4ak.aspx
(2) Linux 平台,glibc上查到的说明如下:
%z RFC 822/ISO 8601:1988 style numeric time zone (e.g., -0600 or +0100), or nothing if no time zone is determinable. This format was first standardized by ISO C99 and by POSIX.1-2001 but was previously available as a GNU extension. In the POSIX locale, a full RFC 822 timestamp is generated by the format ‘"%a, %d %b %Y %H:%M:%S %z"’ (or the equivalent ‘"%a, %d %b %Y %T %z"’). %Z The time zone abbreviation (empty if the time zone can’t be determined).
http://www.gnu.org/software/libc/manual/html_mono/libc.html
http://www.cplusplus.com/reference/ctime/strftime/?kw=strftime
也就是说,MSC和GLIBC对zZ的处理不同,Javascript至少需要获取RFC 822/ISO 8601:1988 定义的数字格式的时区(numeric time zone),但是MSC无法提供,Python的time模块在Windows平台又依赖于MSC,因此Windows的Python的time.strftime无法输出数字时区格式。
这个请求的响应,是一个Javascript 函数调用,格式如:
jsonp1438756475786(...);
中间的参数,就是一个JSON字符串。在这里,我们只关心JSON里面的global_new字段,这个字段的值如下:
{ "speed": 0, "page": "...", // HTML "download_all_task_ids": "", "download_task_ids": "1037042946479361,", "download_nm_task_ids": "1037042946479361,", "download_bt_task_ids": "" }
在这里,我们又只关心到红色标注的几个字段。收到响应后,调用jsonp的一个处理函数,根据这几个字段,会向
http://dynamic.cloud.vip.xunlei.com/interface/task_process
发起请求,携带的参数如下:
| 参数名 |
含义 |
说明 |
| callback |
网页回调函数,可以忽略 |
|
| t |
当前时间 |
Wed Aug 05 2015 14:36:40 GMT+0800 (中国标准时间) |
| list |
|
上面的download_task_ids |
| nm_list |
|
上面的download_nm_task_ids |
| bt_list |
|
上面的download_bt_task_ids |
| uid |
User id,数字格式 |
|
| interfrom |
值为task |
|
这个请求的响应就是一个JSON 表(table),里面包含要查询的每个任务,其数据如下(只取一个):
{ "tid":"1035366520591617", "tcid":"", "openformat":"movie", "url":"http:\/\/v.weipai.cn\/video\/\/201403\/21\/07\/7102A11F-B86F-4AF2-8322-0BC2B30C67A.mov", "speed":"0", "fpercent":0, "leave_time":"-", "percent":0, "fsize":"0B", "download_status":"1", "res_count1":0, "res_count0":0, "res_count_degree":0, "progress_class":"rwicdown", "lixian_url":"", "cid":"", "left_live_time":"365\u5929", "tasktype":"1", "taskname":"7102A11F-B86F-4AF2-8322-0BC2B30C67A.mov", "filesize":"0" }
小结:在获取任务进度的过程中,网页中使用了两个步骤:
(1) 通过 showtask_unfresh 获取需要刷新的任务;
(2) 通过 task_process 获取任务的详细信息。
5. 删除任务
向 http://dynamic.cloud.vip.xunlei.com/interface/task_delete 发送一个请求,这个请求携带的参数:
| 参数名 |
含义 |
说明 |
| callback |
网页回调函数 |
|
| type |
删除类型 |
0 普通任务 1 已删除任务 4 全部任务中的过期任务 |
| t |
当前时间 |
|
| taskids |
要删除的任务ID |
如果有多个,用逗号分隔 |
| old_idlist |
过期任务ID |
如果有多个,用逗号分隔 |
| databases |
|
默认为0,个数和要删除的任务一样 |
| old_databaselist |
|
个数要和过期任务ID个数一样 |
| interfrom |
task |
|
返回的格式如:
jsonp1438862421221({"result":1,"type":2})
result 为1表示删除成功,如果为7,则会转到 http://lixian.vip.xunlei.com/aq/ ,目前不清楚这个页面的作用。
6. 演示代码
#!/usr/bin/env python3 #-*- encoding: utf-8 -*- import os import re import sys import time import json import random import base64 import pickle import hashlib import threading import urllib.parse import urllib.request import rsa class NotImplemented(Exception): pass class MultiPart(object): # HTTP multipart/form-data wrapper def __init__(self, file): if isinstance(file, str): self.pathname = file with open(file, "rb") as f: self.content = f.read() self.content = self.content.decode('latin-1') elif hasattr(file, 'read'): self.pathname = 'file' self.content = file.read() else: raise TypeError("str or objects that have ``read`` attribute needed, but got a {}.".format(type(file))) def _gen_boundary(self): if not self.content: return ### FIXME should we raise an exception? nrand = int(random.random() * 50 + 50) brand = os.urandom(nrand) boundary = hashlib.md5(brand).hexdigest() return boundary def post(self, url, extra={}): boundary = self._gen_boundary() boundary = '--' + boundary headers = { 'Content-Type': 'multipart/form-data; boundary={}'.format(boundary) } if 'Cookie' in extra: headers['Cookie'] = extra.pop('Cookie') multiparts = [] # first extra data for k,v in extra.items(): multiparts.append('--' + boundary) multiparts.append('Content-Disposition: form-data; name="{}"'.format(k)) multiparts.append('') multiparts.append(v) # last pathname multiparts.append('--' + boundary) multiparts.append('Content-Disposition: form-data; name="filepath"; filename="{}"'.format(self.pathname)) multiparts.append('Content-Type: application/octet-stream') multiparts.append('') multiparts.append(self.content) multiparts.append('--' + boundary + '--') # end multiparts.append('') data = '\r\n'.join(multiparts).encode('latin-1') req = urllib.request.Request(url, data=data, headers=headers) resp = urllib.request.urlopen(req) return resp class SimpleCookie(object): ### FIXME: we should subclass http.cookiejar.Cookie instead def __init__(self, name='', value='', path='', domain=''): self.name = name self.value = value self.path = path self.domain = domain self.extra = [] @staticmethod def fromstring(cookie_str): cookie = SimpleCookie() cookie._parse(cookie_str) return cookie def _parse(self, cookie_str): for what in cookie_str.split(';'): what = what.strip() try: what.index('=') except ValueError: self.extra.append(what) continue k,v = what.strip().split('=', 1) if k.lower() == 'path': self.path = v elif k.lower() == 'domain': self.domain = v else: self.name = k self.value = v def __str__(self): return '{}={};'.format(self.name, self.value) class XLTask(object): ### TODO: fulfill all task attributes as list in the documentation def __init__(self, tid, name, dl_url, fsize, loadnum): self.tid = tid self.name = name self.dlurl = dl_url self.fsize = fsize self.loadn = loadnum class Thunder(object): LIXIAN_HOME = 'http://lixian.xunlei.com' INTERFACE_URL = 'http://dynamic.cloud.vip.xunlei.com/interface/' # All these actions below are from INTERFACE_URL TASK_PROCESS = INTERFACE_URL + 'task_process' SHOW_UNFRESH = INTERFACE_URL + 'showtask_unfresh' TASK_CHECK = INTERFACE_URL + 'task_check' TASK_COMMIT = INTERFACE_URL + 'task_commit' TASK_DELETE = INTERFACE_URL + 'task_delete' URL_QUERY = INTERFACE_URL + 'url_query' # for bt TORRENT_UPLOAD = INTERFACE_URL + 'torrent_upload' BT_TASK_COMMIT = INTERFACE_URL + 'bt_task_commit' def __init__(self, uname, password): self.uname = uname self.password = password self.unfinished = [] self.eyeon = [] def _getcookie(self): # get cookie from check user action business_type = 108 url = 'https://login.xunlei.com/check/?u={}&business_type={}&cachetime={:.0f}&' resp = urllib.request.urlopen(url.format(urllib.parse.quote(self.uname), business_type, time.time() *1000)) cookies = resp.headers.get_all('Set-Cookie') cookies_dict = {} # FIXME: should we use OrderedDict? for cookie in cookies: cook_obj = SimpleCookie.fromstring(urllib.parse.unquote(cookie)) cookies_dict[cook_obj.name] = cook_obj self.cookies = cookies_dict self._save_cookies() return self.cookies def _build_cookie_str(self): cookies_all = [] for _,cook in self.cookies.items(): cookies_all.append('{}={};'.format(urllib.parse.quote_plus(cook.name), urllib.parse.quote_plus(cook.value))) return ' '.join(cookies_all) def _refresh_captcha(self, verify_type, cookie=None): captcha_url = "http://verify1.xunlei.com/image?t={}&cachetime={:.0f}".format(verify_type, time.time()*1000) headers = {} if cookie: headers['Cookie'] = cookie req = urllib.request.Request(captcha_url, headers=headers) resp = urllib.request.urlopen(req) self._update_cookies(resp.headers.get_all('Set-Cookie')) with open("captcha.jpg", 'wb') as f: f.write(resp.read()) def login(self): # login to get cookie self._getcookie() # login method, request, blabla while True: lr, result = self._login_internal() if result != 'Captcha error': break return lr, result def _get_verifycode(self): # check result: R : V # where R indicates if we would get a captcha and # V tells the verify code cr = self.cookies['check_result'].value try: if_captcha, verify_code = cr.split(':') except ValueError: # need captcha if_captcha = cr verify_code = '' if_captcha = int(if_captcha) # verify type vt = self.cookies.get('verify_type') vt = vt.value if vt else 'SEA' if if_captcha: # get a captcha from self._refresh_captcha(vt) while True: ucode = input("Please open captcha.jpg and input what you see. Or \nPRESS ENTER ONLY to refresh captcha image:\n") ucode = ucode.strip() if len(ucode) == 0: # refresh captcha self._refresh_captcha(vt) continue # user has input a code break verify_code = ucode return verify_code def _login_internal(self): # self._d_print("User:", self.uname) # get verify code verify_code = self._get_verifycode() # prepare cookie string for further request cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://i.xunlei.com/login/2.5/?r_d=1', 'Cookie': cookies_all_str } # User can login now kn = self.cookies['check_n'].value ke = self.cookies['check_e'].value N = int.from_bytes(base64.b64decode(kn.encode()), byteorder='big') E = int.from_bytes(base64.b64decode(ke.encode()), byteorder='big') pubkey = rsa.key.PublicKey(N, E) message = hashlib.md5(self.password.encode()).hexdigest() + verify_code.upper() rsapwd = rsa.encrypt(message.encode(), pubkey, padding='oaep') newpwd = base64.b64encode(rsapwd) newpwd = newpwd.decode() # Thunder randomly selects a login server from these: # "https://login" # "https://login2" # "https://login3" login_url = 'https://login.{}/sec2login'.format(self.cookies['check_n'].domain) login_params = { 'p': newpwd, 'u': self.uname, 'n': kn, 'e': ke, 'verifycode': verify_code, 'login_enable': 0, ### TODO: what dose this parameter mean? 'business_type': 108, ### TODO: what dose this parameter mean? 'v': 100, 'cachetime': int(time.time() * 1000) } data = urllib.parse.urlencode(login_params).encode() #self._d_print("Data", data.decode()) req = urllib.request.Request(login_url, data, headers) resp = urllib.request.urlopen(req) self._update_cookies(resp.headers.get_all('Set-Cookie')) self._d_write_response(resp) lr,reason = self._check_login_response() self._d_print("Login Result:", lr, reason) return lr,reason def _update_cookies(self, new_cookies, log=False): for cookie in new_cookies: if log: self._d_print("Add cookie:", cookie) cook_obj = SimpleCookie.fromstring(cookie) self.cookies[cook_obj.name] = cook_obj self._save_cookies() return self.cookies def _save_cookies(self): with open('cookies.cache', 'wb') as f: pickle.dump(self.cookies, f) def _check_login_response(self): # case -1:code=1;msg="连接超时,请重试";break; # case 0:msg="登录成功";break; # case 1:case 9:case 10:case 11:code=2;msg="验证码错误,请重新输入验证码";break; # case 2:case 4:code=3;msg="帐号或密码错误,请重新输入";break; # case 3:case 7:case 8:case 16:code=4;msg="服务器内部错误,请重试";break; # case 12:case 13:case 14:case 15:code=5;msg="登录页面失效";break; # case 6:msg="帐号被锁定,请换帐号登录";break; # default:code=-1;msg="内部错误,请重试";break result_str = { -1: 'Connection Timeout', 0: 'Succeed', 1: 'Captcha error', 2: 'Account or Password error', 3: 'Server Internal error', 4: 'Account or Password error', 6: 'Account is locked', 7: 'Server Internal error', 8: 'Server Internal error', 9: 'Captcha error', 10: 'Captcha error', 11: 'Captcha error', 12: 'Login page failure', 13: 'Login page failure', 14: 'Login page failure', 15: 'Login page failure', 16: 'Server Internal error', } lr = self.cookies.get('blogresult') lr = int(lr.value) if lr else -1 if lr not in result_str: return lr, 'Internal Error' return lr, result_str[lr] def _d_write_response(self, resp): pr = urllib.parse.urlparse(resp.url) name = '{}-{}'.format(pr.path.strip('/'), pr.query.replace('&', '_')) with open(name, 'wb') as f: f.write(resp.read()) def _d_print(self, *args): print(*args) def gettasks(self, page=1): # get user tasks # this function simply aquire # http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4 # where userid is responsd from login cookie if page < 1: page = 1 try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") cookies_all_str = self._build_cookie_str() task_url = 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4&p={}&stype='.format(userid, page) headers = { 'Referer': 'http://lixian.xunlei.com/login.html', 'Cookie': cookies_all_str } req = urllib.request.Request(task_url, headers=headers) resp = urllib.request.urlopen(req) # update cookies self._update_cookies(resp.headers.get_all('Set-Cookie')) # The page is utf-8 encoded, so just go content = resp.read().decode() with open("tasks.resp.html", "w", encoding="utf-8") as f: f.write(content) self.tasklist = self._parse_tasks(content) self._d_print_tasks() def _parse_tasks(self, content, tasklist=None): # for me, only dl_url, taskname, ysfilesize and loadnum of tasks are cared pat_attr = '' pat_load = '(\\d+)%' L1 = re.findall(pat_attr, content) L2 = re.findall(pat_load, content) # len(L2) == len(L1)//3 + 1 # self._d_print("len(tasks):", len(L1)) # self._d_print("len(loadnum):", len(L2)) # self._d_print("Loadnum:", L2) # dl_url, name, fsize assert len(L1) % 3 == 0 # assert len(L2) == len(L1)//3 + 1 if not tasklist: tasklist = list() # XLTask for i in range(0, len(L1), 3): # their id must be unique #assert L1[i][1] == L1[i+1][1] == L1[i+2][1] tid = L1[i][1] # usually, # L[i] is dl_url # L[i+1] is tname # L[i+1] is fsize # but just usually. I cannot guarantee the order. So let us just use this ugly style. if L1[i][0] == "dl_url": dl_url = L1[i][2] elif L1[i][0] == "taskname": tname = L1[i][2] elif L1[i][0] == "ysfilesize": fsize = L1[i][2] if L1[i+1][0] == "dl_url": dl_url = L1[i+1][2] elif L1[i+1][0] == "taskname": tname = L1[i+1][2] elif L1[i+1][0] == "ysfilesize": fsize = L1[i+1][2] if L1[i+2][0] == "dl_url": dl_url = L1[i+2][2] elif L1[i+2][0] == "taskname": tname = L1[i+2][2] elif L1[i+2][0] == "ysfilesize": fsize = L1[i+2][2] try: # and here too loadnum = L2[i//3] except IndexError: loadnum = '--' #self._d_print(ntype, tname, fsize) tasklist.append(XLTask(tid, tname, dl_url, fsize, loadnum)) return tasklist def _d_print_tasks(self, count=-1): if count < 0: count = len(self.tasklist) if count == 0: return print("loadnum\tsize(M)\tname") for i in range(count): print("{}\t{}\t{}".format(self.tasklist[i].loadn, int(self.tasklist[i].fsize)//(2**20), self.tasklist[i].name)) def addurl(self, url): self._d_print("add url: {}".format(url)) args = self._check_task(url) while True: taskid = self._commit_task(*args) if taskid == -11 or taskid == -12: # need verify code cookie_str = self._build_cookie_str() while True: self._refresh_captcha('MVA', cookie_str) ucode = input("Please open captcha.jpg and input what you see. Or \nPRESS ENTER ONLY to refresh captcha image:\n") ucode = ucode.strip() if len(ucode) != 0: break else: break return taskid def process(self, tasks, nm_tasks=None, bt_tasks=None): # get processes of specified tasks # this function simply aquire # http://dynamic.cloud.vip.xunlei.com/interface/task_process # with query string: # callback=jsonp1438754682737&t=Wed%20Aug%2005%202015%2014:05:43%20GMT+0800%20(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4) try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") process_url = self.TASK_PROCESS cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } _params = { 'uid': userid, 'callback': 'jsonp{:.0f}'.format(time.time()), 't': time.strftime('%a %b %d %Y %H:%M:%S GMT%z (%Z)'), 'list': ','.join(tasks), 'nm_list': ','.join(nm_tasks) if nm_tasks else '', 'bt_list': ','.join(bt_tasks) if bt_tasks else '', 'interfrom': 'task' } data = urllib.parse.urlencode(_params).encode() req = urllib.request.Request(process_url, data=data, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # error? with open("process.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') json_str = con[lcolon:rcolon] # self._d_print(json_str) # to process results = [] try: tasks_resp = json.loads(json_str) except ValueError: return results for task in tasks_resp["Process"]["Record"]: should_print = False tid = task["tid"] if tid in tasks: should_print = True if nm_tasks and tid in nm_tasks: should_print = True if bt_tasks and tid in bt_tasks: should_print = True if not should_print: continue results.append(task) return results def task_unfresh(self, page=1): # get user unfinished tasks # this function simply aquire # http://dynamic.cloud.vip.xunlei.com/interface/showtask_unfresh # with query string: # callback=jsonp1438756475786&t=Wed%20Aug%2005%202015%2014:36:40%20GMT+0800%20(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&type_id=4&page=1&tasknum=30&p=1&interfrom=task # where userid is responsd from login cookie if page < 1: page = 1 try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") task_url = self.SHOW_UNFRESH + "?" cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } _params = { 'callback': 'jsonp{:.0f}'.format(time.time()), 't': time.strftime('%a %b %d %Y %H:%M:%S GMT+0800 (%Z)'), 'type_id': 4, ### TODO: What does it mean? 'page': page, 'p': page, 'tasknum': 30, 'interfrom': 'task' } query = urllib.parse.urlencode(_params) req = urllib.request.Request(task_url+query, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # cache it with open("unfresh.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') json_str = con[lcolon:rcolon] # self._d_print(json_str) # to process unfinished_json = json_str unfinished = json.loads(unfinished_json) if unfinished["rtcode"] == -11 or unfinished["rtcode"] == -1: print("System busy. Please retry later.") return None, None, None elif unfinished["rtcode"] != 0: print("Unknown error. Please retry later.") return None, None, None ta_ids = unfinished["global_new"]["download_task_ids"].split(',') nm_ids = unfinished["global_new"]["download_nm_task_ids"].split(',') bt_ids = unfinished["global_new"]["download_bt_task_ids"].split(',') self.unfinished.extend(unfinished) return ta_ids, nm_ids, bt_ids def showtasks(self): while True: ta_ids, nm_ids, bt_ids = self.task_unfresh() if ta_ids is None: time.sleep(10) # sleep 10 seconds and try again continue # tasks are grabbed break tasks = self.process(ta_ids, nm_ids, bt_ids) self._d_print_process(tasks) def _d_print_process(self, tasks): msgfmt = "{0[fsize]:<8s}{0[fpercent]:>6.2f}% {0[leave_time]:<11s}{1}" self._d_print("{:<8s}{:<8s}{:<11s}{}".format("size", "percent", "leave-time", "tid")) for t in tasks: name = t['taskname'] if 'taskname' in t else t['tid'] self._d_print(msgfmt.format(t, name)) def _gen_rand(self): _randf = '{:.0f}{}'.format(time.time() * 1000, random.random()*(2000000-10)+10) return _randf def _check_task(self, url): # check a url to add a task check_url = self.TASK_CHECK + '?' # userid try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } # random _randf = self._gen_rand() _params = { 'callback': 'queryCid', 'url': url, 'interfrom': 'task', 'random': _randf, 'tcache': int(time.time()*1000) } query = urllib.parse.urlencode(_params) req = urllib.request.Request(check_url+query, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # cache it with open("check.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') parameters_str = con[lcolon:rcolon] # function queryCid(cid,gcid,file_size,avail_space,tname,goldbean_need,silverbean_need,is_full,random,type,rtcode) l = parameters_str.split(',') if len(l) < 11: return None try: cid = eval(l[0]) gcid = eval(l[1]) fsize = eval(l[2]) fname = eval(l[4]) goldbean = eval(l[5]) silverbean = eval(l[6]) ttype = eval(l[9]) except IndexError: return None # task type # magnet: : 4 # thunder:// : 3 # ed2k:// : 2 # .torrent : 1 # all other : 0 ### FIXME shall we check random? Xunlei's queryCid does. # check if it is bit-torrent if fname.endswith('.torrent'): # goto # INTERFACE_URL+"/url_query?callback=queryUrl&u="+encodeURIComponent(u)+"&random="+$('#query_random').val()+"&interfrom="+G_PAGE; # to check bt task return self.checkbturltask(url) ### TODO we SHOULD check if golden or silver bean is needed return [cid, gcid, fsize, fname, goldbean, silverbean, ttype] def checkbturltask(self, url): # check a url to add a task check_url = self.URL_QUERY + '?' # userid try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } # random _randf = self._gen_rand() _params = { 'callback': 'queryUrl', 'u': url, 'interfrom': 'task', 'random': _randf, 'tcache': int(time.time()*1000) } query = urllib.parse.urlencode(_params) req = urllib.request.Request(check_url+query, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # cache it with open("check.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') parameters_str = con[lcolon:rcolon] # queryUrl(flag,infohash,fsize,bt_title,is_full,subtitle,subformatsize,size_list,valid_list,file_icon,findex,is_blocked,random,rtcode) l = parameters_str.split(',') if len(l) < 13: return None try: flag = l[0].strip() infohash = l[1].strip() fsize = l[2].strip() bt_title = l[3].strip() subtitle = l[5].strip() subformatsize = l[6].strip() size_list = l[7].strip() rtcode = l[-1].strip() except IndexError: return None if not bt_title: return None flag = int(flag) if flag == 0: self._d_print("Get bit-torrent failed. Please check if the url is correct.") return None elif flag == -1: self._d_print("You have uploaded this torrent before.") ### TODO we should let the user select files OR just begin download # goto # INTERFACE_URL+"/fill_bt_list?callback=edit_bt_list&tid="+fsize+"&infoid="+infohash+"&uid="+G_USERID+"&ed=1&random="+random+"&interfrom="+G_PAGE; # to get bt list? return None ### TODO find a url that directs to a BT file and see what happened raise NotImplemented('BT download through a url is not implemented yet. \n' 'If you see this message, please send the url to [email protected]') def _commit_task(self, *args): # commit a task commit_url = self.TASK_COMMIT + '?' # if len(args) < 7: # raise ValueError("committask need 7 parameters, but only {} passed".format(len(args))) #self._d_print("commit task args:", *args) try: cid, gcid, fsize, fname, goldbean, silverbean, ttype = args except TypeError: return -1 if cid is None: return -1 # userid try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") # cookie cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } _params = { 'callback': 'ret_task', 'uid': userid, 'cid': cid, 'gcid': gcid, 'size': fsize, 'goldbean': goldbean, 'silverbean': silverbean, 't': fname, # file name 'url': url, # source url 'type': ttype, # task type 'o_page': 'history', 'o_taskid': 0, ### FIXME 'class_id': 0, # classify/group 'database': 'undefined', 'interfrom': 'task', 'verify_code': '', 'time': time.strftime('%a %b %d %Y %H:%M:%S GMT+0800 (%Z)'), 'noCacheIE': int(time.time()*1000) } query = urllib.parse.urlencode(_params) req = urllib.request.Request(commit_url+query, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # cache it with open("commit.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') parameters_str = con[lcolon:rcolon] # function ret_task(ret_num,taskid,time) l = parameters_str.split(',') retnum = int(eval(l[0].strip())) taskid = eval(l[1].strip()) # tatime = l[2].strip() self._d_print("retnum:", retnum) if retnum != 1: # failed: -1, 75, 76 return retnum return taskid def deletetask(self, tasks): # delete tasks delete_url = self.TASK_DELETE + '?' # userid try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") # cookie cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } if isinstance(tasks, str) or not hasattr(tasks, '__iter__'): tasks = [tasks, ] tasks_str = ','.join(tasks) + ',' databases = ','.join('0'*len(tasks)) + ',' self._d_print("delete task: ", ",".join(tasks)) _params1 = { # for url 'callback': 'jsonp{:.0f}'.format(time.time()*1000), 'type': 0, 't': time.strftime('%a %b %d %Y %H:%M:%S GMT+0800 (%Z)'), } _params2 = { # for data 'taskids': tasks_str, 'databases': databases, 'old_idlist': '', 'old_databaselist': '', 'interfrom': 'task', } query = urllib.parse.urlencode(_params1) data = urllib.parse.urlencode(_params2) data = data.encode() req = urllib.request.Request(delete_url+query, data=data, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # cache it with open("delete.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') json_str = con[lcolon:rcolon] try: dr = json.loads(json_str) return dr['result'] == 1 except (ValueError, KeyError): return False def addbt(self, btfile): # upload bt try: title, btcid, fsize, files = self._upload_btfile(btfile) except ValueError as e: print("Error:", e) return -1 # commit bt task while True: tid = self._commit_bttask(title, btcid, fsize, files) if tid == -11 or tid == -12: # need verify code cookie_str = self._build_cookie_str() while True: self._refresh_captcha('MVA', cookie_str) ucode = input("Please open captcha.jpg and input what you see. Or \nPRESS ENTER ONLY to refresh captcha image:\n") ucode = ucode.strip() if len(ucode) != 0: break else: break return tid def _upload_btfile(self, btfile): ### TODO upload_url = self.TORRENT_UPLOAD # cookie cookies_all_str = self._build_cookie_str() headers = { 'Cookie': cookies_all_str, 'random': self._gen_rand(), 'interfrom': 'task' } mp = MultiPart(btfile) resp = mp.post(upload_url, headers) con = resp.read() con = con.decode() with open("upload.resp", "w", encoding="utf-8") as f: f.write(con) # find the value of btResult try: _start = con.find('btResult') _start1 = con.find('{', _start) # `}` # `{` _end = con.rfind('}') json_str = con[_start1:_end+1] except ValueError: raise ValueError('upload response is not expected.') try: br = json.loads(json_str) except ValueError: raise ValueError('btResult is not a valid JS object.') if br["ret_value"] != 1: raise ValueError('file upload return {}.'.format(br["ret_value"])) title = br["ftitle"] btcid = br["infoid"] fsize = br["btsize"] files = br["filelist"] self._d_print("upload result: title: {}, cid: {}, fsize: {}, files:{}".format(title, btcid, fsize, files)) return title, btcid, fsize, files def _commit_bttask(self, title, btcid, fsize, files): commit_url = self.BT_TASK_COMMIT + '?' # userid try: userid = self.cookies['userid'].value except KeyError: raise ValueError("Cookies does not contain 'userid'") # cookie cookies_all_str = self._build_cookie_str() headers = { 'Referer': 'http://dynamic.cloud.vip.xunlei.com/user_task?userid={}&st=4'.format(userid), 'Cookie': cookies_all_str } # for now, we select to download all. and someday in the future ### TODO select user interested files automatically like QQ-Download findex = '_'.join(f['id'] for f in files) + "_" ssize = '_'.join(f['subsize'] for f in files) + "_" _params1 = { 'callback': 'jsonp{:.0f}'.format(time.time()*1000), 't': time.strftime('%a %b %d %Y %H:%M:%S GMT+0800 (%Z)'), } _params2 = { 'uid': userid, 'btname': title, 'cid': btcid, 'goldbean': 0, 'silverbean': 0, 'tsize': fsize, 'findex': findex, 'size': ssize, 'o_taskid': 0, 'o_page': 'task', 'class_id': 0, # category: all files 'interfrom': 'task', 'verify_code': '' } query = urllib.parse.urlencode(_params1) data = urllib.parse.urlencode(_params2) data = data.encode() # self._d_print("commit bt task query: ", query) # self._d_print("commit bt task query: ", data.decode()) req = urllib.request.Request(commit_url+query, data=data, headers=headers) resp = urllib.request.urlopen(req) # ascii characters con = resp.read().decode() # self._d_print("commit bt task response: ", con) # cache it with open("commit_bttask.resp", "w", encoding="utf-8") as f: f.write(con) lcolon = con.find('(') + 1 # `)` # `(` rcolon = con.rfind(')') json_str = con[lcolon:rcolon] try: dr = json.loads(json_str) except (ValueError, KeyError): return False progress = { 1: 'Success', 2: 'Fail', -11: 'Need verify code (-11)', -12: 'Need verify code (-12)' } tid = dr.get('id') if tid is None: # dr['progress'] must exist return dr['progress'] # self._d_print('commit bt task result:', progress[dr['progress']]) return dr['id'] def openeye(self, tasks): if not hasattr(tasks, '__iter__'): tasks = [tasks,] self.eyeon.extend(tasks) ### TODO Threads in python will slow down your execution sharply ### but do we have another way to take a glance now and then wihout ### interrupting other tasks? raise NotImplemented("Eyes are closed currently....") if __name__ == '__main__': # get thunder vip account: http://521xunlei.com/portal.php url = 'http://mirrors.163.com/archlinux/iso/2015.08.01/archlinux-2015.08.01-dual.iso' my = Thunder('793040110:1', '1575933') print("************************ login ************************") lr, reason = my.login() if lr != 0: sys.exit(0) print("************************ tasks (page 1) ************************") my.gettasks() print("************************ process ************************") my.showtasks() # print("************************ add url ************************") # tid = my.addurl(url) # if isinstance(tid, int): # print("Add task failed.") # else: # print("Add task succeed, task id:", tid) # #print("************************ eyeon ************************") # #my.start_eyeon(tid) # print("************************ delete ************************") # r = my.deletetask(tid) # print("delete result:", r) print("************************ add bt file ************************") tid = my.addbt('archlinux-2015.08.01-dual.iso.torrent') if isinstance(tid, int): print("Add bt task failed.") else: print("Add task succeed, task id:", tid) #print("************************ eyeon ************************") #my.start_eyeon(tid) print("************************ delete ************************") my.deletetask(tid)