HCIP-OpenStack组件介绍
OpenStack排错思路:
OpenStack查询日志,所有日志都在/var/log/模块名称下面。
OpenStack修改配置,所有配置文件都在/etc/模块名称下面。
openstack把这些组件服务都集成到httpd服务中了,目的是为了提升性能。登入不了openstack在控制节点查下httpd服务,systemctl status httpd
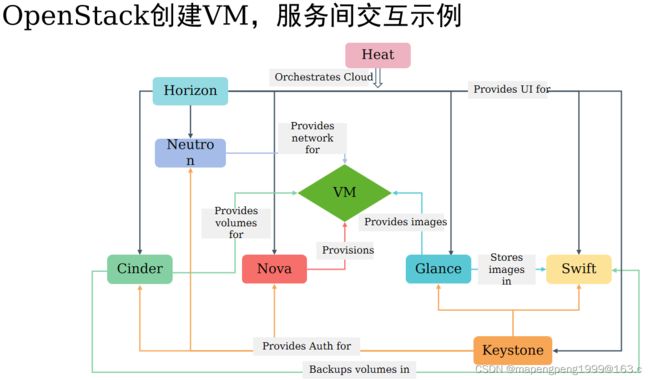
Dashboard horizon:提供webUI图形化界面的
Keystone:提供身份认证服务、授权、endpoint端点(类似于电话簿,给谁打哪个电话),所有的服务都要在keystone组件上注册的,不注册无法访问。
Nova:提供计算服务的,cpu,内存
Cinder:提供块存储服务的,提供磁盘的
Glance:提供镜像服务的,glance加载镜像但不保存镜像,glance后面一定会对接存储的,这里对接的是swift存储镜像(但实验环境是存在本地文件系统的)。
Swift:对象存储,后端可以对接nfs/ceph/glusterfs/aws等
neutron提供网络服务,网络/子网/子接口/dhcp等
每个组件(模块)对应有很多服务的,[root@controller ~]# systemctl list-unit-files |grep cinder
openstack-cinder-api.service enabled
openstack-cinder-backup.service enabled
openstack-cinder-scheduler.service enabled
openstack-cinder-volume.service enabled
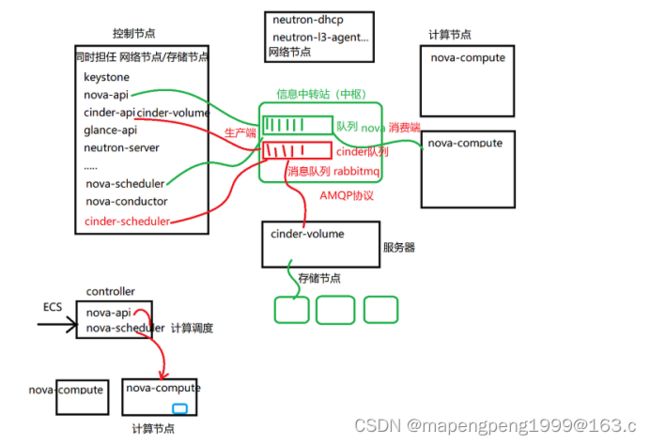
发放云主机,控制节点的nova-api接收请求,给nova-scheduler处理做完计算调度后,发放给某个计算节点的nova-compute处理。
创建云硬盘,控制节点的cinder-api接收请求,给cinder-scheduler处理做完计算调度后,发放给某个存储节点cinder-volume处理(生产环境有独立的存储节点的,实验环境是将存储部署在控制节点)。
rabbitmq
通过rabbitmq消息队列处理请求,按照规则排队处理互不影响,不会说因为cinder-scheduler调度慢而影响cinder-api接收请求性能,也不会因为cinder-volume处理慢而影响cinder-scheduler调度性能,把这些服务解耦了提升性能了。
rabbitmq基于AMQP协议,rabbitmq来处理消息队列的,每个组件都会生成自己组件的队列,在这个队列里面去消费就行,产生需求信息的叫生产端(如nova-api、cinder-api产生新需求的),把生产端的需求拿过来放到对应队列里面,再由相应组件去对应队列里面取用消费。用rabbitmq为了实现消息的传递互通,能解决并发问题、rabbitmq并发量是毫秒级的,性能很好,不管并发量多大直接扔给rabbitmq,再由其它组件进行消费就行,把这些组件服务充分进行解耦了。
rabbitmq默认部署在控制节点,rabbitmq掌握各个组件的互通,rabbitmq服务停了发放云主机会有问题的,不知哪有问题,就按照组件单个组件查日志,发放云主机先经过nova组件,就先查看nova组件日志,比如查看nova-api.log日志找到error发现rabbitmq连接不上。Systemctl status rabbitmq-server.service
控制节点上已经安装了rabbitmq,rabbitmq默认部署在控制节点
rabbitmq-plugins list 列出所有rabbitmq模块,能查看rabbitmq模块是否启用
rabbitmq-plugins enable rabbitmq_management 启用rabbitmq_management模块就能网页登录rabbitmq
默认只有25672端口给内部rabbitmq互通的,15672 端口是启用rabbitmq_management模块开通的,给用户网页登录rabbitmq用的。
# netstat -utlnp |grep 56
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 6681/beam.smp
tcp 0 0 0.0.0.0:25672 0.0.0.0:* LISTEN 6681/beam.smp
tcp6 0 0 :::5672 :::* LISTEN 6681/beam.smp
通过ip:15672 尝试网页登录rabbitmq有问题,telnet看15672端口是否通,如果无法登录,添加一条iptables规则,iptables -I INPUT 1 -p tcp --dport 15672 -j ACCEPT


Keystone
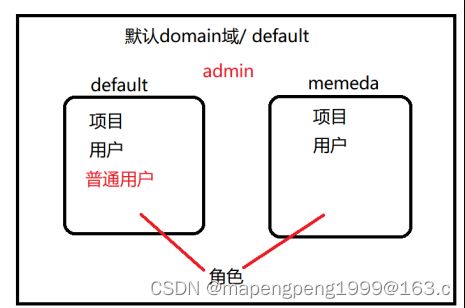
多域管理,通过domain(域)逻辑隔离不同的租户/项目以及用户,但角色是全局通用的。
如果是管理员角色权限,那么所有的域下面的资源都可以看到。如果是普通用户,只能看到当前所在域下面的资源。
查看域,[root@controller ~(admin)]# openstack domain list
创建域,[root@controller ~(admin)]# openstack domain create memeda
删除域,[root@controller ~(admin)]# openstack domain delete memeda
Failed to delete domain with name or ID 'memeda': Cannot delete a domain that is enabled, please disable it first. (HTTP 403) (Request-ID: req-2b24ee89-3200-4e07-bbb9-3265c131910a)
1 of 1 domains failed to delete.
删除域失败,得先禁用域disable再删除
查看域的详情信息,[root@controller ~(admin)]# openstack domain show memed
发现域是enabled启用的,得先禁用域disable再删除
禁用域,[root@controller ~(admin)]# openstack domain set --disable memeda
查看域的详情信息,[root@controller ~(admin)]# openstack domain show memeda
删除域,[root@controller ~(admin)]# openstack domain delete memeda
查看memeda域下面的项目[root@controller ~(admin)]# openstack project list --domain memeda
查看memeda域下面的用户,[root@controller ~(admin)]# openstack user list --domain memeda
在memeda域里面创建项目和用户再关联角色
在memeda域里面创建项目
[root@controller ~(admin)]# openstack project create memeda --domain memeda
在memeda域里面创建用户
[root@controller ~(admin)]# openstack user create --password redhat --domain memeda memeda
关联角色,给哪个域哪个项目哪个用户关联角色(项目和用户最好用id唯一的,防止多个域内用户项目名重复)这里给关联了admin角色权限
[root@controller ~(admin)]# openstack role add --project 333d5d01d0074b8c854d6c8e7de67bc5 --user f6e8c320a6e8482e8c967d5036bab143 admin
启用多域,修改配置文件,vim /etc/openstack-dashboard/local_settings
[root@controller openstack-dashboard(admin)]# vim local_settings
#OPENSTACK_KEYSTONE_MULTIDOMAIN_SUPPORT = False
OPENSTACK_KEYSTONE_MULTIDOMAIN_SUPPORT = True 启用多域 ,默认禁用多域
# Overrides the default domain used when running on single-domain model
# with Keystone V3. All entities will be created in the default domain.
#OPENSTACK_KEYSTONE_DEFAULT_DOMAIN = 'Default'
OPENSTACK_KEYSTONE_DEFAULT_DOMAIN = 'Default' 默认使用Default域
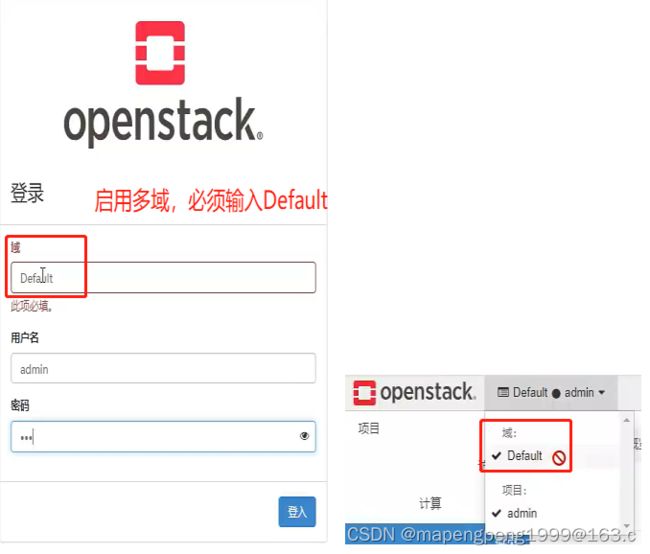
启用多域了,想使用默认的Default域登入时也必须手工输入Default
重启apache服务,[root@controller ~(admin)]# systemctl restart httpd
重新登录,输入对应的域,用户名和密码进行登录。

Cinder
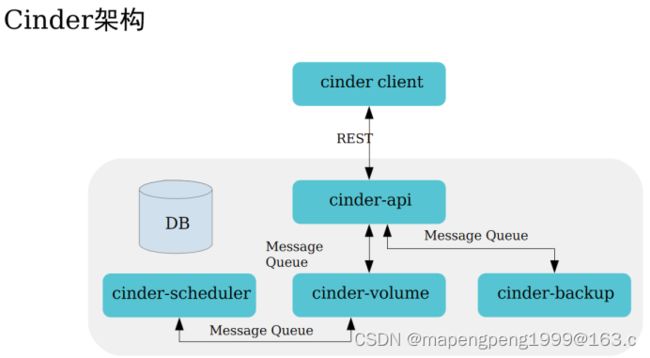
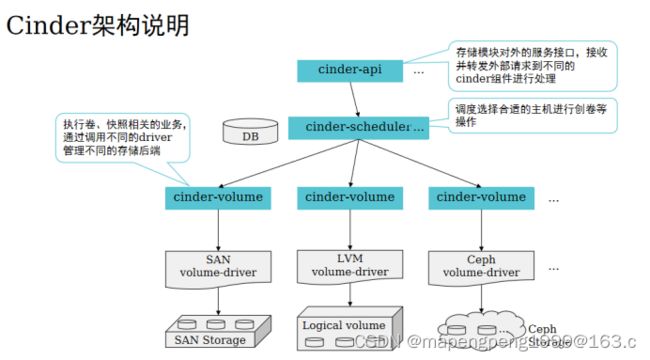

创建卷的流程,和挂载卷的流程是不一样的。从创建卷到挂载卷,它是两个动作,分别由不通的组件来执行。创建卷的时候,是由cinder组件来创建;而挂载卷的时候,是由nova组件来挂载。

创建云硬盘,控制节点的cinder-api接收请求,给cinder-scheduler处理做完计算调度后,发放给某个存储节点cinder-volume处理(生产环境有独立的存储节点的,实验环境是将存储部署在控制节点)。
/etc/libvirt/qemu目录下有个xml配置文件,将物理机的/dev/sda映射给虚拟机的/vda,先挂载到物理机再通过xml配置文件映射给虚拟机使用。

Cinder对接后端NFS存储
具体操作流程请大家参考视频及https://blog.51cto.com/cloudcs/5387939
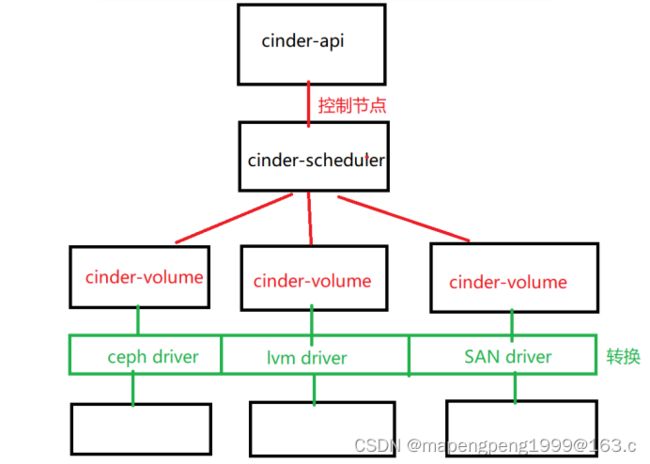
cinder-api接收外部请求,放到消息队列中由cinder-scheduler消费,cinder-api和cinder-scheduler服务位于控制节点,cinder-volume在存储节点(这里有3台linux主机存储节点,cinder-scheduler根据调度选择合适linux主机),在下面有驱动,不同的对接存储类型有不同的存储驱动driver,存储不同所执行的命令不同,通过驱动进行翻译在底层存储创建。
Glance

Glance提供镜像服务的,不是提供镜像存储的。现在实验环境镜像是存储在本地的文件系统中。
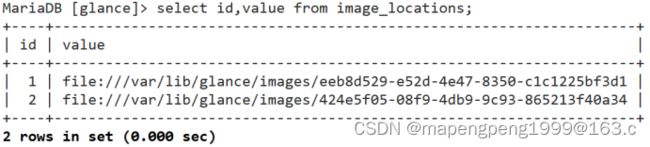
可以把glance对接到swift对象存储,现在实验环境swift对象存储对接的后端存储是在本地文件系统。

swift是个组件本身不存储,是要对接到后端存储的,后端存储对接默认也是在本地文件系统。
让glance对接到swift里面,修改配置文件,修改配置文件前先备份。
[root@controller glance(admin)]# cp glance-api.conf glance-api.conf.bak
[root@controller glance(admin)]# vim glance-api.conf
3057 stores=file,http,swift glance支持的选项
3111 default_store=swift glance默认使用的选项,默认是file对接的本地文件系统
3982 swift_store_region = RegionOne 默认存储的区域
4032 swift_store_endpoint_type = publicURL 端点类型public,走哪个endpoint去连接
4090 swift_store_container = glance 名字可以自定义,未来上传镜像后,会自动创建一个以glance开头的容器名。
4118 swift_store_large_object_size = 5120 限制最大单个上传的对象为5G大小。
4142 swift_store_large_object_chunk_size = 200 类似于条带化大小,不能超过200个chunk
4160 swift_store_create_container_on_put = true 要不要自动给你创建一个容器
4182 swift_store_multi_tenant = true 是否支持多租户/项目
4230 swift_store_admin_tenants = services swift对应的租户/项目名称
4382 swift_store_auth_version = 2 身份认证版本
4391 swift_store_auth_address = http://192.168.100.151:5000/v3 身份认证地址(keystonerc_admin环境变量文件里面的OS_AUTH_URL)
4399 swift_store_user = swift 对象存储使用的默认用户swift
4408 swift_store_key = 6424bb8bc0e04f6c swift用户的密码(去应答文件里面搜索SWIFT)
修改完配置文件后,重启glance服务。
[root@controller glance(admin)]# systemctl restart openstack-glance-*
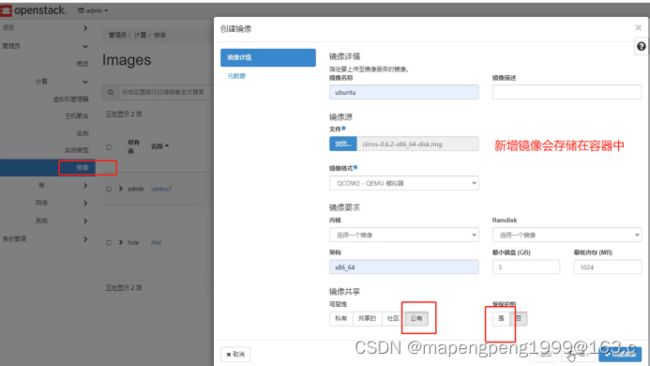
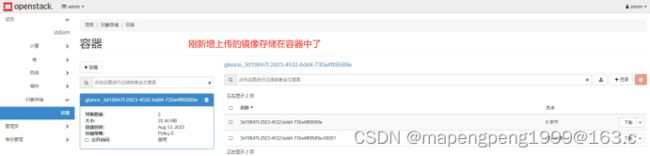
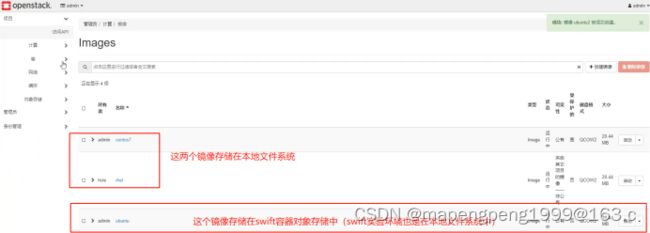
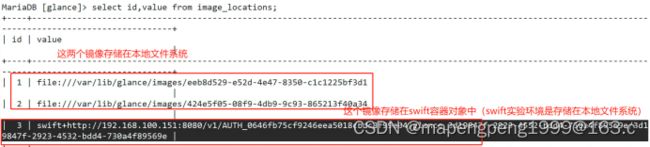

把镜像存在对象存储中,对象存储中存储的内容一般是不改动的数据,查询读取性能好,适合大量永久存储。