clickhouse原理解析与应用实践
一、ClickHouse基础介绍
1.1 介绍
Click Stream,Data Warehouse 点击流数据仓库
在采集数据过程中,一次页面click,会产生一个event。 ----》 基于页面点击事件流,面向数据仓库进行OLAP分析
Clickhouse 是一个开源的,完全列式存储的,关系型数据库管理系统。面向数据仓库,主要用于联机分析处理(OLAP,Online Analytical Processing)。
1.2 优点
关系型联机分析处理 ROLAP, On-Line Analytical Processing
在线实时查询 https://clickhouse.tech/benchmark/dbms/
完整的DBMS
DDL:可以动态的创建、修改或者删除数据库、表和视图,而无须重启服务;
DML:可以动态的查询、插入、修改、或者删除数据;
权限控制:可以按照用户粒度设置数据库或者表的操作权限,保证数据的安全性;
数据备份与恢复:提高数据备份导出与导入恢复机制;
分布式管理:提供集群模式,能够自动管理多个数据库节点。
完全列式存储(减少数据扫描范围,数据传输时大小) ----》 数据高效压缩
假设一张数据表A中字段A1~A50,100行数据。
按列查找:SELECT A1,A2,A3,A4,A5 FROM A; 有效的减少了查询时所需扫描的数据量;
按行查找:数据库首先追行扫描,并且获取每行数据的所有50个字段,再从每一行的数据中返回A1~A5这五个字段.
压缩前:abcdefghi_bcdefghi;
压缩后:abcdefghi_(9,8)。
压缩本质:按照一定步长对数据进行匹配扫描,当发现重复部分的时候进行编码转化。重复值越多,压缩比越高。
数据压缩:上述(9,8)表示如果从下划线开始向前移动9个字节,会匹配到8个字节长度的重复项,即bcdefghi
向量化执行引擎
消除程序中循环的优化
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
SQL查询
多样化的数据库引擎和表引擎
不同的引擎,不同的数据存储位置和特点
数据库引擎:
Ordinary 默认引擎
Dictionary 字典引擎 此类数据库会自动为所有数据字典创建他们的数据表。
Memory 内存引擎 用于存放临时数据,此类数据库下的数据表只会停留在内存,重启数据丢失。
Lazy 日志引擎 此类数据库下只能使用log系列的表引擎。
Mysql Mysql引擎 此类数据库会自动拉取远端Mysql中的数据,并创建Mysql表引擎的数据表。
表引擎:
Memory、MergeTree
多线程与分布式
多主架构
采用Multi-Master主从架构,节点角色对等,客户端访问任意节点得到效果相同,规避了单点故障
1.3 缺点
不支持事务。
不支持二级索引。
元数据管理需要人工干预维护。
尽量做批量的insert操作。
支持有限操作系统。
不支持典型K/V存储
并发查询资源控制不好处理
1.4 适用场景
适用于商业智能领域(BI),应用于广告流量、web、APP流量、物联网等其他领域。
多主架构模式(Multi-Master),适用于多数据中心,异地多活的场景
1.5 不适用场景
不支持事务 ----》 OLTP事务性操作场景
不擅长根据主键按行粒度进行查询(支持) ----》 不应该把CK当作Key-Value数据库使用
不擅长按行删除数据(支持)
二、ClickHouse架构设计
cloumn和field是ClickHouse数据最基本的映射单元。
为什么ClickHouse如此之快?
0.c++,c语言和硬件交互优势
1.采用列式存储,
4.方便实时的数据结构 MergeTree
2.使用了向量化引擎
3.软件架构设计采用自底向上方式。 追求自底向上、追求极致的设计思路
硬件---》算法---》特殊优化---》版本发布
硬件:

ClickHouse会在内存中GROUP BY,并且使用HashTable装载数据。
在意CPU L3级别缓存,因为一次L3级别缓存失效会带来70~100ns的延迟。意味着单核CPU上,浪费4000万次/秒的运算;32线程的CPU上,浪费5亿次/秒的运算。ClickHouse在基准查询中能做到1.75亿次/秒的数据扫描性能。
算法:
对于常量,使用了Volnitsky算法;对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2和hyperscan算法。
特殊优化:
针对同一场景不同状况,选择使用不同的实现方式。
例如去重计数uniqCombined函数,会根据数据量的不同选择不同的算法:
当数据量较小的时候,会选择Array保存;
当数据量中等的时候,会选择HashSet;
当数据量很大的时候,会使用HyperLogLog算法
对于数据结构比较清晰的场景,会通过代码生成技术实现循环展开,以减少循环次数。
版本发布:
基本每个月都能发布一个版本,意味着拥有一个持续验证,持续改进的机制。
三、客户端访问接口
3.1 ClickHouse的底层访问接口
支持TCP和HTTP两种协议。
TCP协议拥有更好的性能,其端口为9000,主要用于集群间内部通信及CLI(Command Line Interface,命令行接口)客户端;
CLI两种执行模式:
1.交互式执行 clickhouse-client -h clickhouse-11 --port 9000
2.非交互式执行 clickhouse-client --query
标准输入:cat /root/test.tsv |clickhouse-client --query "INSERT INTO test FORMAT TSV"
标准输出:clickhouse-client --query="select * from test" > /root/test.csv
默认情况下,clickhouse-client后面只能运行一条SQL语句,执行多条情况下:
clickhouse-client -h clickhouse-1 --port 9000 --multiquery --query="select1;select 2;select 3;"
HTTP协议拥有更好的兼容性,其端口为8123,可以通过REST服务的形式被广泛用于JAVA,Python等编程语言的客户端。
更推荐通过CLI或者JDBC这些封装接口连接,更加简单易用。
clickhouse-client参数
--host / -h :服务器地址 config.xml中::1
127.0.0.1
--port :服务器TCP端口,默认9000 config.xml中9000
--user/ - u :登录的用户名,默认default
--password :登录的密码,默认为空 users.xml中default
--query / -q :只能非交互查询时使用,指定SQL语句
--multiquery / -n :在非交互式查询中,允许一次运行多个SQL语句
--time / -t :在非交互式执行中,会打印每条SQL执行时间
clickhouse-client -t -n -q “select RequestNum,RequestTry from test.hit limit 1000000,10;select count(*) from test.hit;select RequestNum,RequestTry from test.hit limit 100000,10;”
非交互式导入导出数据:
https://clickhouse.tech/docs/zh/getting-started/example-datasets/metrica/
导入数据:
unxz hits_v1.tsv.xz
clickhouse-client --query "create database if not exists test"
clickhouse-client --query "create table test.hit ( WatchID UInt64, JavaEnable UInt8, Title String, GoodEvent Int16, EventTime DateTime, EventDate Date, CounterID UInt32, ClientIP UInt32, ClientIP6 FixedString(16), RegionID UInt32, UserID UInt64, CounterClass Int8, OS UInt8, UserAgent UInt8, URL String, Referer String, URLDomain String, RefererDomain String, Refresh UInt8, IsRobot UInt8, RefererCategories Array(UInt16), URLCategories Array(UInt16), URLRegions Array(UInt32), RefererRegions Array(UInt32), ResolutionWidth UInt16, ResolutionHeight UInt16, ResolutionDepth UInt8, FlashMajor UInt8, FlashMinor UInt8, FlashMinor2 String, NetMajor UInt8, NetMinor UInt8, UserAgentMajor UInt16, UserAgentMinor FixedString(2), CookieEnable UInt8, JavascriptEnable UInt8, IsMobile UInt8, MobilePhone UInt8, MobilePhoneModel String, Params String, IPNetworkID UInt32, TraficSourceID Int8, SearchEngineID UInt16, SearchPhrase String, AdvEngineID UInt8, IsArtifical UInt8, WindowClientWidth UInt16, WindowClientHeight UInt16, ClientTimeZone Int16, ClientEventTime DateTime, SilverlightVersion1 UInt8, SilverlightVersion2 UInt8, SilverlightVersion3 UInt32, SilverlightVersion4 UInt16, PageCharset String, CodeVersion UInt32, IsLink UInt8, IsDownload UInt8, IsNotBounce UInt8, FUniqID UInt64, HID UInt32, IsOldCounter UInt8, IsEvent UInt8, IsParameter UInt8, DontCountHits UInt8, WithHash UInt8, HitColor FixedString(1), UTCEventTime DateTime, Age UInt8, Sex UInt8, Income UInt8, Interests UInt16, Robotness UInt8, GeneralInterests Array(UInt16), RemoteIP UInt32, RemoteIP6 FixedString(16), WindowName Int32, OpenerName Int32, HistoryLength Int16, BrowserLanguage FixedString(2), BrowserCountry FixedString(2), SocialNetwork String, SocialAction String, HTTPError UInt16, SendTiming Int32, DNSTiming Int32, ConnectTiming Int32, ResponseStartTiming Int32, ResponseEndTiming Int32, FetchTiming Int32, RedirectTiming Int32, DOMInteractiveTiming Int32, DOMContentLoadedTiming Int32, DOMCompleteTiming Int32, LoadEventStartTiming Int32, LoadEventEndTiming Int32, NSToDOMContentLoadedTiming Int32, FirstPaintTiming Int32, RedirectCount Int8, SocialSourceNetworkID UInt8, SocialSourcePage String, ParamPrice Int64, ParamOrderID String, ParamCurrency FixedString(3), ParamCurrencyID UInt16, GoalsReached Array(UInt32), OpenstatServiceName String, OpenstatCampaignID String, OpenstatAdID String, OpenstatSourceID String, UTMSource String, UTMMedium String, UTMCampaign String, UTMContent String, UTMTerm String, FromTag String, HasGCLID UInt8, RefererHash UInt64, URLHash UInt64, CLID UInt32, YCLID UInt64, ShareService String, ShareURL String, ShareTitle String, ParsedParams Nested(Key1 String, Key2 String, Key3 String, Key4 String, Key5 String, ValueDouble Float64), IslandID FixedString(16), RequestNum UInt32, RequestTry UInt8) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) SETTINGS index_granularity = 8192"
cat hits_v1.tsv | clickhouse-client --query "insert into test.hit FORMAT TSV " --max_insert_block_size=100000
clickhouse-client --query "optimize table test.hit final"
clickhouse-client --query "select count(*) from test.hit"
导出数据:
clickhouse-client --query "select * from test.hit" >> /root/hit.tsv
速度之快:
SELECT count(*) FROM test.hit
┌─count()─┐
│ 8873898 │
└─────────┘
1 rows in set. Elapsed: 0.002 sec.
SELECT
RequestNum,
RequestTry
FROM test.hit
LIMIT 1000000, 10
┌─RequestNum─┬─RequestTry─┐
│ 240 │ 1 │
│ 5 │ 0 │
│ 4 │ 1 │
│ 1188 │ 0 │
│ 1829 │ 0 │
│ 1229 │ 0 │
│ 1508 │ 0 │
│ 1348 │ 0 │
│ 1418 │ 2 │
│ 1988 │ 0 │
└────────────┴────────────┘
10 rows in set. Elapsed: 0.007 sec. Processed 1.57 million rows, 7.86 MB (223.91 million rows/s., 1.12 GB/s.)
3.2 内置实用工具
clickhouse-local 单机版 需要指定数据源+stdin标准输入+非交互式执行+只能使用File表引擎
clickhouse-benchmark SQL语句性能测试 自动运行SQL查询,并生成相应运行指标报告
clickhouse-benchmark参数:
-i / --iterations SQL语句查询执行的次数,默认值为0
-c / --concurrency 同时执行查询的并发数,默认值是1
-r / --randomize 再执行多条SQL语句的时候,按照随机顺序执行,
-h / --host 服务端地址,默认值localhost;对比测试时,需要指定两个服务端
SQL语句性能测试
echo "select * from test.hit limit 1000000,10" |clickhouse-benchmark -i 5
Loaded 1 queries.
Queries executed: 1.
localhost:9000, queries 1, QPS: 1.121, RPS: 1203315.971, MiB/s: 1131.422, result RPS: 11.213, result MiB/s: 0.011.
0.000% 0.892 sec.
10.000% 0.892 sec.
20.000% 0.892 sec.
30.000% 0.892 sec.
40.000% 0.892 sec.
50.000% 0.892 sec.
60.000% 0.892 sec.
70.000% 0.892 sec.
80.000% 0.892 sec.
90.000% 0.892 sec.
95.000% 0.892 sec.
99.000% 0.892 sec.
99.900% 0.892 sec.
99.990% 0.892 sec.
Queries executed: 2.
localhost:9000, queries 1, QPS: 1.651, RPS: 1772268.853, MiB/s: 1673.131, result RPS: 16.515, result MiB/s: 0.015.
0.000% 0.606 sec.
10.000% 0.606 sec.
20.000% 0.606 sec.
30.000% 0.606 sec.
40.000% 0.606 sec.
50.000% 0.606 sec.
60.000% 0.606 sec.
70.000% 0.606 sec.
80.000% 0.606 sec.
90.000% 0.606 sec.
95.000% 0.606 sec.
99.000% 0.606 sec.
99.900% 0.606 sec.
99.990% 0.606 sec.
Queries executed: 5.
localhost:9000, queries 5, QPS: 1.183, RPS: 1257808.054, MiB/s: 1184.972, result RPS: 11.829, result MiB/s: 0.012.
0.000% 0.606 sec.
10.000% 0.651 sec.
20.000% 0.696 sec.
30.000% 0.753 sec.
40.000% 0.823 sec.
50.000% 0.892 sec.
60.000% 0.894 sec.
70.000% 0.897 sec.
80.000% 0.941 sec.
90.000% 1.027 sec.
95.000% 1.070 sec.
99.000% 1.104 sec.
99.900% 1.112 sec.
99.990% 1.113 sec.
四、数据类型
数据类型划分:
基础类型、复合类型,特殊类型
4.1 基础类型
4.1.1 数值类型
Int 整型 (有符号)
| 名称 | 大小(字节) | 范围 | Mysql普通观念 |
|---|---|---|---|
| Int8 | 1 | -128到127 | Tinyint |
| Int16 | 2 | -32768到32767 | Smallint |
| Int32 | 4 | -2147483648到2147483647 | int |
| Int64 | 8 | -9223372036854775808到9223372036854775807 | bigint |
Int 整型(无符号)
| 名称 | 大小(字节) | 范围 | Mysql普通观念 |
|---|---|---|---|
| UInt8 | 1 | 0到255 | Tinyint Unsigned |
| UInt16 | 2 | 0到65535 | Smallint Unsigned |
| UInt32 | 4 | 0到4294967295 | int Unsigned |
| UInt64 | 8 | 0到18446744073709551615 | bigint Unsigned |
浮点型 Float
| 名称 | 大小(字节) | 有效精度 | Mysql普通观念 | 起始点 |
|---|---|---|---|---|
| Float32(单精度) | 4 | 7 | Float | 小数点后第8位 |
| Float64(双精度) | 8 | 16 | Double | 小数点后第17位起 |
Decimal 定点数
| 名称 | 等效声明 | 范围 |
|---|---|---|
| Decimal32(S) | Decimal(1~9,S) | -1*10(9~S)到1*10(9~S) |
| Decimal64(S) | Decimal(10~18,S) | -1*10(18~S)到1*10(18~S) |
| Decimal128(S) | Decimal(19~38,S) | -1*10(38~S)到1*10(38~S) |
4.1.2 字符串类型
| 名称 | 长度 | 备注 |
|---|---|---|
| String | 长度不限 | 使用统一编码即可(utf-8) |
| FixedString | 固定长度字符串 | 不够用null字节末尾填充 |
| UUID | 32位(8-4-4-4-12) | 常用主键;未赋值使用0填充 |
String类型演示:
select toFixedString('abc',5) , LENGTH (toFixedString('abc',5)) as LENGTH
SELECT
toFixedString('abc', 5),
LENGTH(toFixedString('abc', 5)) AS LENGTH
┌─toFixedString('abc', 5)─┬─LENGTH─┐
│ abc │ 5 │
└─────────────────────────┴────────┘
1 rows in set. Elapsed: 0.003 sec.
UUID类型演示:
create table uuid_test (c1 UUID, c2 String) ENGINE = Memory
CREATE TABLE uuid_test
(
`c1` UUID,
`c2` String
)
ENGINE = Memory
0 rows in set. Elapsed: 0.015 sec.
:) insert into uuid_test select generateUUIDv4(),'t1'
INSERT INTO uuid_test SELECT
generateUUIDv4(),
't1'
Ok.
0 rows in set. Elapsed: 0.002 sec.
:)
:) insert into uuid_test(c2) values('t2')
INSERT INTO uuid_test (c2) VALUES
Ok.
1 rows in set. Elapsed: 0.002 sec.
:)
:) select * from uuid_test;
SELECT *
FROM uuid_test
┌───────────────────────────────────c1─┬─c2─┐
│ 33509345-71c0-499f-be3c-37fdc09f818f │ t1 │
└──────────────────────────────────────┴────┘
┌───────────────────────────────────c1─┬─c2─┐
│ 00000000-0000-0000-0000-000000000000 │ t2 │
└──────────────────────────────────────┴────┘
2 rows in set. Elapsed: 0.002 sec.
4.1.3 时间类型
| 名称 | 格式 | 备注 |
|---|---|---|
| DateTime | 2020-12-03 13:33:32 | 日时分秒,精确到秒 |
| DateTime64 | 2020-12-03 13:33:32.00 | 日时分秒亚秒,精确到亚秒 |
| Date | 2020-12-03 | 日,精确到天 |
4.2 复合类型
4.2.1 Array
数组有两种定义方式:
1.常规方式array(T)
select array(1,2) as a, toTypeName(a)
SELECT
[1, 2] AS a,
toTypeName(a)
┌─a─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
2.简写方式[T]
select [1,2] as a,toTypeName(a)
SELECT
[1, 2] AS a,
toTypeName(a)
┌─a─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
注:同一数组内可以包含多种数据类型,但是各类型之间必须兼容。
select array(1,2,null) as a, toTypeName(a)
SELECT
[1, 2, NULL] AS a,
toTypeName(a)
┌─a──────────┬─toTypeName([1, 2, NULL])─┐
│ [1,2,NULL] │ Array(Nullable(UInt8)) │
└────────────┴──────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
注:在定义表字段时,数组需要制定明确的元素类型
create table array_test_1 (c1 Array(String)) engine = Memory
4.2.2 Tuple
元组由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。
元组有两种定义方式:
1.常规方式tuple(T)
select tuple(1,'a',now()) AS x,toTypeName(x)
SELECT
(1, 'a', now()) AS x,
toTypeName(x)
┌─x─────────────────────────────┬─toTypeName(tuple(1, 'a', now()))─┐
│ (1,'a','2020-12-04 16:25:01') │ Tuple(UInt8, String, DateTime) │
└───────────────────────────────┴──────────────────────────────────┘
1 rows in set. Elapsed: 0.005 sec.
2.简写方式(T)
select (1,2,0,null) as a, toTypeName(a)
SELECT
(1, 2, 0, NULL) AS a,
toTypeName(a)
┌─a────────────┬─toTypeName(tuple(1, 2, 0, NULL))──────────────┐
│ (1,2,0,NULL) │ Tuple(UInt8, UInt8, UInt8, Nullable(Nothing)) │
└──────────────┴───────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
注:在定义表字段时,元组需要制定明确的元素类型
create table tuple_test (c1 Tuple(String,Int8)) engine = Memory
4.2.3 Enum
枚举固定使用(String:Int)key/Value键值对的形式定义数据,所以Enum8和Enum16分别对应(String:Int8)和(String:Int16
create table enum_test ( c1 Enum8('ready' = 1,'start' = 2,'success' = 3,'error' = 4)) engine = Memory;
CREATE TABLE enum_test
(
`c1` Enum8('ready' = 1, 'start' = 2, 'success' = 3, 'error' = 4)
)
ENGINE = Memory
0 rows in set. Elapsed: 0.001 sec.
:)
:) insert into enum_test values ('ready');
INSERT INTO enum_test VALUES
Ok.
1 rows in set. Elapsed: 0.002 sec.
:)
:) insert into enum_test values ('start');
INSERT INTO enum_test VALUES
Ok.
1 rows in set. Elapsed: 0.002 sec.
:)
:) select * from enum_test;
SELECT *
FROM enum_test
┌─c1────┐
│ ready │
└───────┘
┌─c1────┐
│ start │
└───────┘
2 rows in set. Elapsed: 0.002 sec.
# 不在范围抛出异常
insert into enum_test values ('stop');
4.2.4 Nested
嵌套表结构,一张数据表,可以定义任意多个嵌套类型字段,但是每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。
create table nested_test (name String,age UInt8,dept Nested (id UInt8,name String)) engine = Memory;
CREATE TABLE nested_test
(
`name` String,
`age` UInt8,
`dept` Nested(
id UInt8,
name String)
)
ENGINE = Memory
:)
:) into nested_test values ('zhang' , 18 , [10000],['测试部']);
0 rows in set. Elapsed: 0.001 sec.
:)
:) insert into nested_test values ('zhang',18,[10000,10001,10002],['研发部','技术部','技术支持']);
INSERT INTO nested_test VALUES
Ok.
1 rows in set. Elapsed: 0.002 sec.
:)
:) insert into nested_test values ('zhang' ,18, [10000,10001],['研发部','测试部']);
INSERT INTO nested_test VALUES
Ok.
1 rows in set. Elapsed: 0.001 sec.
:)
:) select * from nested_test;
SELECT *
FROM nested_test
┌─name──┬─age─┬─dept.id────┬─dept.name──────────────────────┐
│ zhang │ 18 │ [16,17,18] │ ['研发部','技术部','技术支持'] │
└───────┴─────┴────────────┴────────────────────────────────┘
┌─name──┬─age─┬─dept.id─┬─dept.name───────────┐
│ zhang │ 18 │ [16,17] │ ['研发部','测试部'] │
└───────┴─────┴─────────┴─────────────────────┘
┌─name──┬─age─┬─dept.id─┬─dept.name──┐
│ zhang │ 18 │ [16] │ ['测试部'] │
└───────┴─────┴─────────┴────────────┘
3 rows in set. Elapsed: 0.005 sec.
4.3 特殊类型
| 名称 | 备注 |
|---|---|
| Nullable | 辅助修饰符,,表示某个基础数据类型可以为Null |
| Domain | 存储IPv4(UInt32)和IPv6 |
create table ipv4 (url String,ip IPv4) engine = Memory;
CREATE TABLE ipv4
(
`url` String,
`ip` IPv4
)
ENGINE = Memory
0 rows in set. Elapsed: 0.001 sec.
:)
:) insert into ipv4 values ('www.oldba.cn','10.0.0.30')
INSERT INTO ipv4 VALUES
Ok.
1 rows in set. Elapsed: 0.001 sec.
:)
:) select url,ip,toTypeName(url),toTypeName(ip) from ipv4;
SELECT
url,
ip,
toTypeName(url),
toTypeName(ip)
FROM ipv4
┌─url──────────┬─────ip────┬─toTypeName(url)─┬─toTypeName(ip)─┐
│ www.oldba.cn │ 10.0.0.30 │ String │ IPv4 │
└──────────────┴───────────┴─────────────────┴────────────────┘
1 rows in set. Elapsed: 0.003 sec.
五、定义数据表
5.1 数据库
数据库目前支持五种引擎:
Ordinary 默认引擎
Dictionary 字典引擎 此类数据库会自动为所有数据字典创建他们的数据表。
Memory 内存引擎 用于存放临时数据,此类数据库下的数据表只会停留在内存,重启数据丢失。
Lazy 日志引擎 此类数据库下只能使用log系列的表引擎。
Mysql Mysql引擎 此类数据库会自动拉取远端Mysql中的数据,并创建Mysql表引擎的数据表。
创建数据库:
create database if not exists testdb
数据路径下会有testdb文件夹;
metadata路径下会有testdb.sql文件。
查看数据库:
show databases
删除数据库:
drop database testdb
5.2 数据表
建表完整语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
数据表相关操作
建表举例
create table content (title String,url String,enenttime Datetime) engine = Memory;
复制同contnet一样的表结构为content_v1表
create table content_v1 as content engine = TinyLog 只有表结构
create table content_v1 engine = TinyLog as select ... 只有表结构
create table content_v1 engine = TinyLog as select * from content 表结构+数据
查看表定义结构:
show create table content 原样输出
desc test 表格显示
删除表:
drop table content 物理删除,立即释放空间;删除表数据+表空间
truncate table content 物理删除,立即释放空间;删除表数据,保留表结构
delete table content [FROM] 逻辑删除,删除的数据做标记;逐行删除表数据,保留表空间
5.3 默认值表达式
表字段支持三种默认值表达式:
DEFAULT
MATERIALIZED
ALIAS
三者区别:
数据写入时,只有default类型的字段可以出现在INSERT语句中。
数据查询时,只有default类型的字段可以通过在SELECT*返回。
数据存储时,只有default和materialized类型的字段才支持持久化。
表字段被定义了默认值,不再强制要求定义数据类型,CK根据默认值类型推断;
如果同时对表字段定义了默认值表达是和数据类型,则按照定义的数据类型为主。
示例演示:
CREATE TABLE test ( id String, c1 DEFAULT 1000, c2 String DEFAULT c1) ENGINE = TinyLog
INSERT INTO test(id) values('A000')
SELECT
c1,
c2,
toTypeName(c1),
toTypeName(c2)
FROM test
┌───c1─┬─c2───┬─toTypeName(c1)─┬─toTypeName(c2)─┐
│ 1000 │ 1000 │ UInt16 │ String │
└──────┴──────┴────────────────┴────────────────┘
c1根据字段默认值推断为无符号的整数
c2根据定义的类型判断为字符型
5.4 数据表的基本操作
追加新字段
ALTER TABLE xxx add column item String DEFAULT 'mac' 默认最后一行加
ALTER TABLE xxx add column app String AFTER ID 在ID列后面加新字段
修改数据类型
ALTER TABLE content MODIFY COLUMN ip IPv4
修改备注
ALTER TABLE content comment column ID '主键列'
删除已有字段
ALTER TABLE content DROP COLUMN [IF EXISTS] name
移动数据表
RENAME TABLE default.content TO test.test
清空数据表
drop table content 物理删除,立即释放空间;删除表数据+表空间
truncate table content 物理删除,立即释放空间;删除表数据,保留表结构
delete table content [FROM] 逻辑删除,删除的数据做标记;逐行删除表数据,保留表空间
5.5 数据分区的基本操作
5.5.1 查询分区表
SELECT
table,
partition_id,
name,
path
FROM system.parts
WHERE table = 'test'
┌─table─┬─partition_id─┬─name─────────┬─path───────────────────────────────────────────────┐
│ test │ 202012 │ 202012_1_3_1 │ /data/clickhouse/data/data/test/test/202012_1_3_1/ │
│ test │ 210506 │ 210506_4_4_0 │ /data/clickhouse/data/data/test/test/210506_4_4_0/ │
└───────┴──────────────┴──────────────┴────────────────────────────────────────────────────┘
5.5.2 删除指定分区
语法:
alter table tb_name drop partition partition_id
alter table test drop partition 201905
5.5.3 复制分区数据
ClickHosue支持将A表的分区数据复制到B表,这项特性可以用于快速写入、多表间数据同步和备份等场景。
语法:
ALTER TABLE B REPALCE PARTITION partition_expr FROM A
满足条件才可相互复制:
两张表需要拥有相同的分区键;
它们的表结构完全相同。
假设test_v1和test_v2表分区键和表结构完全相同
CREATE TABLE test.test_v1 (`id` String,url String,EventTime Date) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventTime) ORDER BY id
insert into test_v1 values ('A006-V1','www.v1.com','2019-08-05'),('A007-v1','www.v1.con','2019-08-20')
select * from test_v1
┌─id──────┬─url────────┬──EventTime─┐
│ A006-V1 │ www.v1.com │ 2019-08-05 │
│ A007-v1 │ www.v1.con │ 2019-08-20 │
└─────────┴────────────┴────────────┘
ALTER TABLE test_v2 REPLACE PARTITION 201908 FROM test_v1
SELECT * FROM test_v2 ORDER BY EventTime ASC
┌─id──────┬─url────────┬──EventTime─┐
│ A006-V1 │ www.v1.com │ 2019-08-05 │
│ A007-v1 │ www.v1.con │ 2019-08-20 │
└─────────┴────────────┴────────────┘
5.5.4 重置分区数据
如果数据表的某一列数据不正确,需要将其初始化。
语法:
ALTER TABLE tb_name CLEAR COLUMN cloumn_name IN PARTITION partition_expr
示例演示:
ALTER TABLE test_v2 CLEAR COLUMN url IN PARTITION 201908
SELECT * FROM test_v2 ORDER BY EventTime ASC
┌─id──────┬─url─┬──EventTime─┐
│ A006-V1 │ │ 2019-08-05 │
│ A007-v1 │ │ 2019-08-20 │
└─────────┴─────┴────────────┘
5.5.5 卸载与装载分区
表分区可以通过DETACH语句卸载,分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的detached子目录下。装载是卸载的反过程。常用于分区数据的迁移和备份场景。
卸载语法:
ALTER TABLE tb_name DETACH PARTITION partition_expr
示例演示:
ALTER TABLE test_v2 DETACH PARTITION 201908
SELECT * FROM test_v2 ORDER BY EventTime ASC
# ll /data/clickhouse/data/data/test/test_v2/
drwxr-x--- 3 clickhouse clickhouse 26 Dec 8 14:23 detached
-rw-r----- 1 clickhouse clickhouse 1 Dec 7 17:15 format_version.txt
# ll /data/clickhouse/data/data/test/test_v2/detached/
drwxr-x--- 2 clickhouse clickhouse 203 Dec 8 14:23 201908_2_2_0
# 此时一旦分区被移动到detached的目录下,就代表已经脱离了ClickHouse的管理。ClickHouse并不会主动清理这些文件。
装载语法:
ALTER TABLE tb_name ATTACH PARTITION partition_expr
示例演示:
ALTER TABLE test_v2 ATTACH PARTITION 201908
SELECT * FROM test_v2 ORDER BY EventTime ASC
┌─id──────┬─url─┬──EventTime─┐
│ A006-V1 │ │ 2019-08-05 │
│ A007-v1 │ │ 2019-08-20 │
└─────────┴─────┴────────────┘
# ll /data/clickhouse/data/data/test/test_v2/detached/
total 0
# ll /data/clickhouse/data/data/test/test_v2/
total 4
drwxr-x--- 2 clickhouse clickhouse 203 Dec 8 14:33 201908_3_3_0
drwxr-x--- 2 clickhouse clickhouse 6 Dec 8 14:33 detached
-rw-r----- 1 clickhouse clickhouse 1 Dec 7 17:15 format_version.txt
5.6 分布式DDL执行
DDL:数据定义语言。
CREATE、ALTER、DROP、RENAME、及TRUNCATE等DDL语句都支持分布式。
DDL语法:
CREATE TABLE tb_name ON CLUSTER ck_cluster (
id String,
url String,
eventtime Date
) ENGINE = MergeTree ()
PARTITION BY toYYYYMM(eventtime)
ORDER BY id
5.7 数据的写入
INSERT支持三种范式写入。
第一种使用VALUES格式的常规语法:
INSERT INTO table [(c1,c2,c3...)] VALUES (V11,V12,V13...),(V21,V22,V23)
示例演示:
INSERT INTO test_v2 VALUES ('A0011','www.xxx.com','2020-12-08'),('A0012','www.nnn.com','2020-11-08'),('A0013','www.qqq.com','2020-12-09')
第二种使用指定格式语法:
INSERT INTO table [(c1,c2,c3...)] FORMAT format_name data_set
示例演示:
INSERT INTO test_v2 FORMAT CSV \
'A0011','www.xxx.com','2020-12-08'\
'A0012','www.nnn.com','2020-11-08'\
'A0013','www.qqq.com','2020-12-09'
第三种使用SELECT子句形式的语法:
INSERT INTO table [(c1,c2,c3...)] SELECT ...
示例演示:
INSERT INTO test_v2 SELECT 'A0020','www.ooo.com','now()'
5.8 数据的删除与修改
ClickHouse提供了DELETE和UPDATE的能力,这类操作称Mutation查询。(是ALTER语句的变种)
适用于批量数据的修改和删除
不支持事务,一旦提交被执行,无法回滚;
Mutation语句的执行是一个异步的后台过程,语句被提交之后就会立即返回,但是具体逻辑并不一定执行完毕,需要通过system.mutations系统表查询。
DELETE语句完整语法:
ALTER TABLE table DELETE WHERE filter_expr
示例演示:
ALTER TABLE test_v2 DELETE WHERE id = 'A006-V1' 异步重操作。
进入目录发现,再执行了DETELE操作之后数据目录发生了变化,每个原有的目录后末尾都加了_6的后缀,此外,目录下还多了Mmutation_6.txt的文件夹。
# ll /data/clickhouse/data/data/test/test_v2/
total 8
drwxr-x--- 2 clickhouse clickhouse 234 Dec 8 15:27 201908_3_3_0_6
drwxr-x--- 2 clickhouse clickhouse 234 Dec 8 15:27 202011_5_5_0_6
drwxr-x--- 2 clickhouse clickhouse 234 Dec 8 15:27 202012_4_4_0_6
drwxr-x--- 2 clickhouse clickhouse 6 Dec 8 14:33 detached
-rw-r----- 1 clickhouse clickhouse 1 Dec 7 17:15 format_version.txt
-rw-r----- 1 clickhouse clickhouse 92 Dec 8 15:27 mutation_6.txt
# cat mutation_6.txt
format version: 1
create time: 2020-12-08 15:27:39
commands: DELETE WHERE id = \'A006-V1\'
SELECT database,table,mutation_id,block_numbers.number AS num, is_done FROM system.mutations
┌─database─┬─table───┬─mutation_id────┬─num─┬─is_done─┐
│ test │ test_v2 │ mutation_6.txt │ [6] │ 1 │
└──────────┴─────────┴────────────────┴─────┴─────────┘
每执行一条ALTER TABLE xxx DELETE FROM 语句,都会在mutation系统表中生成一条对应的执行计划,当is_done为1时,代表执行完毕。同时也会在数据目录下会以mutation_id为名生成与之对应的日志文件用于记录相关信息。
删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,新目录的命名规则在原有名称之上加上system.mutations.block_numbers.number,数据在重写的过程中会将需要删除的数据去掉。就数据不会立即删除,标记为非激活状态(active 0)。等到MergeTree引擎的下一次合并动作触发时,这些非激活目录才会被真正从物理上删除。
六、MergeTree原理解析
6.1 MergeTree创建方式
MergeTree在写入数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段较多,clickhouse通过后台进程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。
MergeTree支持主键索引,数据分区,数据副本和数据采用,支持ALTER操作。
创建方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
PARTITION BY
分区键:表示表数据会以何种标准进行分区;默认all分区。
分区方式:单列、元组形式使用多列或者使用列表达式。
合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
ORDER BY
排序键:用于指定在一个数据片段内,数据以何种标准排序;默认情况和主键相同。
排序方式:单列、元组形式使用多列。ORDER BY (counterID,EventDate)为例,在单个数据片段中,数据首先以counterID排序,相同的counterID,在按照EventDate排序。
PAIMARY KEY
主键:会按照主键字段生成一级索引,用于加速表查询;默认情况下,主键个ORDER BY相同。
SAMPLE BY
抽样表达式:用于声明数据以何种标砖进行采样。
SETTINGS:index_granularity
index_granularity对于MergeTree表示索引粒度,默认值8192.(每隔8192行数据生成一条索引)
SETTINGS:index_granularity_bytes
19.11前:clickhouse只支持固定大小的索引间隔,由index_granularity控制,默认8192。
在新版本:自适应间隔大小。根据每一批次写入数据体量大小,动态划分间隔大小。数据体量由index_granularity_bytes控制,默认10M(10*1024*1024),设置为0不启动自适应功能。
SETTINGS:enable_mixed_granularity_parts
是否开启自适应索引间隔,默认开启
SETTINGS:merge_with_ttl_timeout 数据TTL功能
SETTINGS:storage_policy 多路径存储策略
```
CREATE TABLE test20(ID String,Price Int32,Val Float64,EventTime Date) engine = MergeTree() PARTITION BY toYYYYMM(EventTime) ORDER BY ID
create table test (id UInt8,name String,age UInt8,shijian Date) engine = MergeTree() partition by toYYYYMM(shijian) order by id
6.2 MergeTree存储结构
MergeTree表引擎中数据拥有物理存储,数据会按分区目录的形式保存到磁盘中
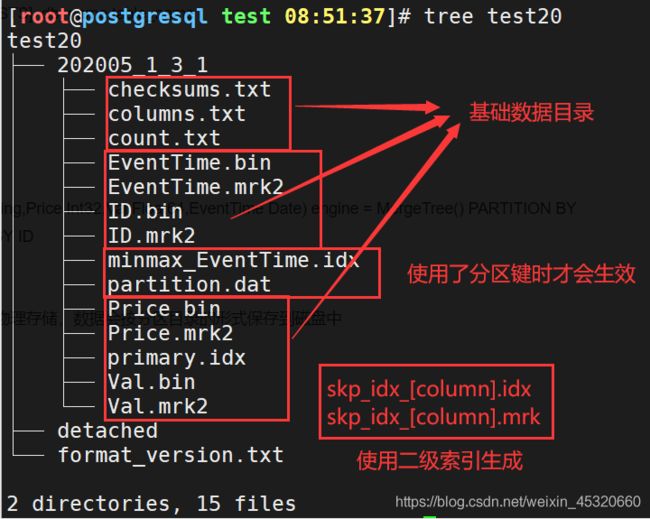
[root@postgresql test 08:51:37]# tree test20
test20
├── 202005_1_3_1 分区目录
│ ├── checksums.txt 校验文件,保存余下各类文件的size大小及size的哈希值,校验数据完整性
│ ├── columns.txt 列信息文件。明文格式存储列字段名称和数据类型。
│ ├── count.txt 计数文件。明文记录当前数据分区目录下的数据总行数
│ ├── EventTime.bin
│ ├── EventTime.mrk2
│ ├── ID.bin 数据文件。使用压缩格式存储(默认LZ4),存储某一列数据
│ ├── ID.mrk2
│ ├── minmax_EventTime.idx 分区键的索引文件,记录当前分区下分区字段对应原始数据的最小和最大值
│ ├── partition.dat 分区键(使用了PARTITION BY),保存前分区下分区表达式最终生成的值
│ ├── Price.bin
│ ├── Price.mrk2 使用了自适应大小索引间隔的列标记文件,二进制存储,保存.bin文件中数据的偏移量信息
│ ├── primary.idx 一级索引文件,二进制格式存储。一张MergeTree()表只能声明一次一级索引(primary key或者order by)
│ ├── Val.bin
│ └── Val.mrk2
├── detached
└── format_version.txt
2 directories, 15 files
6.3 数据分区
数据分区:针对本地数据,对数据一种纵向切分
数据分片:针对CK集群,以横向切割数据。
6.3.1 数据分区规则
MergeTree数据分区的规则由ID决定,而具体到每个数据分区所对应的ID,则是由分区键的取值决定的。
分区ID生成逻辑四种规则:
1.不指定分区键 分区ID默认为all
2.使用整型 直接按照该整形的字符形式输出作为分区ID的取值
3.使用日期类型 按照YYYYMMDD格式化后字符形式输出作为分区ID取值
4.使用其他类型 分区键取值不属于整型,也不属于日期,例如String、Float则会通过128位Hash算法取其Hash值作为分区ID
PartitionID在不同规则下示例
| 类型 | 样例数据 | 分区表达式 | 分区ID |
|---|---|---|---|
| 无分区键 | 无 | all | |
| 整型 | 18,19,20 | PARTITION BY Age | 分区1:18;分区2:19;分区3:20 |
| 整型 | ‘A0’,‘A1’,‘A3’ | PARTITION BY length(Code) | 分区1:2 |
| 日期 | 2019-02-01,019-06-11 | PARTITION BY EventTime | 分区1:20190201;分区2:20190611 |
| 日期 | 2019-05-01,2019-06-11 | PARTITION BY toYYYYMM(EventTime) | 分区1:201905;分区2:201906 |
| 其他 | ‘www.oldba.cn’ | PARTITION BY URL | 分区1:15r515rs15gr15615wg5e5h5548h3045h |
6.3.2 数据分区目录命名规则
举例说明:
202005_1_3_1 此目录直观来看,采用时间年月作为分区ID,分三次插入到同一分区,并且三次插入完成之后的某个时刻进行了一次数据合并。
202005 PartitionID 分区目录ID
1 MinBlockNum 最小数据块编号 (默认和MaxBlockNum从1开始)
3 MaxBlockNum 最大数据块编号 (发生合并时取合并时的最大数据块编号)
1 Level 合并的层级,某个分区被合并过的次数或者这个分区的年龄。(每次合并自增+1)
6.3.3 数据分区合并过程
MergeTree分区目录创建:数据写入的过程中创建;创建之后在写入数据或者合并,目录也会变化。
也就是说:一张表没有任何数据,那不会有任何分区目录存在。
MergeTree分区目录合并过程:
伴随每次写入数据(insert),MergeTree都会生成一批新的分区目录(即使不同批次写入的数据属于相同分区,也会生成不同的分区目录)。在写入后的某个时刻,ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新目录。已经存在的旧分区并不会立即删除,而是在之后的某个时刻通过后台任务删除(默认8分钟)。
新目录名称的合并规则:
MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。
MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。
Level:取同一分区内最大Level值并加1。
create table test(id UInt32,name String,age UInt8,shijian DateTime) engine = MergeTree() PARTITION BY toYYYYMM(shijian) ORDER BY id
insert into test values (1,'张三',18,'2020-12-08') t1时刻
insert into test values (2,'李四',19,'2020-12-08') t2时刻
insert into test values (3,'王五',22,'2021-01-03') t3时刻
insert into test values (2,'李四',19,now()) t4时刻
SELECT now()
┌───────────────now()─┐
│ 2020-12-08 11:36:42 │
└─────────────────────┘
按照上述规则未合并时的目录:
PARTITIONID 202012
MinBlockNum 1
MaxBlockNmu 1
对于新建分区,它们的值一样(来源表内全局自增的BlockNum),初始值为1,每次新建目录累计加1。
level 0
202012_1_1_0 t1时刻的目录
202012_2_2_0 t2时刻的目录
202101_3_3_0 t3时刻的目录
202012_4_4_0 t4时刻的目录
按照上述规则合并时的目录:
假设在t2~t3时刻之间发生了合并,那么此时只有一个目录:202012_1_2_1
假设在t3~t4时刻之间发生了合并,那么此时肯有两个目录:202012_1_2_1,202101_3_3_0
假设在t4时刻之后发生了合并,那么此时也肯定有两个目录:202012_1_4_2,202101_3_3_0
注意:
在创建完成之后的某个时刻进行合并,必须是相同分区才会合并,生成新的分区,同时将旧分区目录状态设置为非激活,然后在默认8分钟之后,删除非激活状态的分区目录。
6.4 一级索引
MergerTree 指定主键方式:
1.PRIMARY KEY MergerTree会根据index_granularity间隔(默认8192行)为数据表生成一级索引保存在primary.idx文件中,根据主键排序
2.ORDER BY .bin 文件按完全相同PRIMARY KEY的规则排序
6.4.1 稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现
稠密索引:每一行索引标记对应一行具体的数据记录
稀疏索引:每一行索引标记对应一段具体的数据记录
两者比较:
a 稀疏索引占用的索引存储空间比较小,但是查找时间较长; 数据量大场景,利用primary.idx内的索引数据常驻内存
b 稠密索引查找时间较短,索引存储空间较大。 数据量小场景

6.4.2 索引粒度(index_granularity)
数据以index_granularity的粒度(默认固定索引粒度8192)被标记成多个小空间,其中每个空间最多8192行数据。这段空间的具体区间就是MarkRange,并且通过start和end表示具体的范围。

6.4.3 索引查询过程
MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成多个小的间隔数据段,一个具体的数段就是MarkRange。
MarkRange与索引编号对应,使用start和end表示具体的范围。
通过start及end对应的索引编号取值,即能得到它所对应的数值区间。
索引查询其实就是两个数值区间的交集判断:
1.一个区间是由基于主键的查询条件转换而来的条件区间;
2.一个区间是MarkRange对应的数值区间。
索引查询过程:
1.生成查询条件区间:将查询条件转换为条件区间
where ID = 'A003' ['A003','A003']
where ID > 'A000' ('A000','+inf')
where ID LIKE 'A006%' ['A006','A007')
2.递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。
如果不存在交集,则直接通过剪枝算法优化此整段MarkRange
如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间(由merge_tree_coarse_index_granularity指定,默认为8),并重复此规则,继续做递归交集判断
如果存在交集,且MarkRange不可再分割(步长小于8),则记录MarkRange并返回
3.合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围
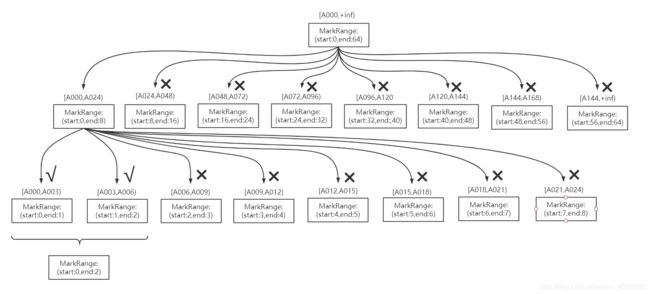
索引查询完整过程图示
6.4.4 二级索引(跳数索引)
由数据的聚合信息构建而成。不同的索引类型,聚合信息内容也不同。
MergeTree支持跳数索引类型:minmax、set、ngrambf_v1和tokenbf_v1。一张表同时支持声明多个跳数索引。
跳数索引默认情况是关闭的,需要设置set allow_experimental_data_skipping_indiced = 1
对于跳数索引,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度。
granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
6.4.5 数据存储
各列独立存储
MergeTree中,数据按列存储。具体到每个列字段,每个列字段都拥有一个与之对应的.bin数据文件(物理存储)。
.bin文件只会保存当前分区片段内的这一部分数据。
首先,数据是经过压缩,(目前支持:LZ4,ZSTD、Multiple和Delta几种算法);
其次,数据会事先按照ORDER BY 的声明排序;
最后,数据以多个压缩数据块的形式被组织并写入.bin文件中的。
压缩数据块
一个压缩数据块由头信息和压缩数据两部分组成。
头信息固定使用9位字节表示:
一个UInt8 1字节整型 使用压缩算法类型
一个UInt32 4字节整型 压缩后的数据大小
一个UInt32 4字节整型 压缩前的数据大小
MergeTree在数据具体写入过程中,会按照索引粒度,按批次获取数据并进行处理。
多对一 1.单个批次数据SIZE < 64KB;如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到SIZE>=64KB时,生成下一个压缩数据块;
一对一 2.单个批次数据64KB<=SIZE<=1MB:如果单个批次数据大小恰好在64KB与1MB之间,则直接生成下一个压缩数据块
一对多 3.单个批次数据SIZE>1MB;如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个数据块。剩余数据继续按照大小判断执行。
总结:一个.bin文件由1至多个压缩数据块组成,每个压缩块大小在64KB~1MB之间。
多个压缩块之间,按顺序写入首尾相接。
.bin文件引入压缩块的目的:
1.数据被压缩后能有效减少数据大小,降低存储空间,加速数据传输效率;但是压缩、解压效率也会影响性能。
2.再具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存中解压读取。那就是通过压缩块(64KB~1MB)可以不读取整个.bin文件的情况下将读取粒度降低到压缩块级别。
6.5 数据标记
6.5.1 数据标记生成规则
primary.idx 一级索引
.bin 数据文件
.mrk为一级索引和数据文件之间建立关联。主要记录两个信息:
1.一级索引对应的页码信息;
2.一段文字在某一页中的起始位置。

数据标记特征:1.数据标记文件和索引区间是对齐的。都是按照index_granularity的粒度间隔划分。
2.数据标记文件和.bin文件也是一一对应。每一个列字段[column].bin文件都有一个对应的[column].mrk数据标记文件,用于记录数据在.bin文件中偏移量信息。
一行标记数据使用元组表示,包含两个整型数据的偏移信息(压缩文件中偏移量,解压缩块中的偏移量)
每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息
标记数据与一级索引不同,它不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取用速度。
6.5.2 数据标记的工作方式
在MergeTree读取数据时,必须通过标记数据的位置信息找到所需要的数据。
查找过程大致分为读取压缩数据块和读取数据两个步骤。

JavaEnable字段的数据类型为UInt8,所以每行数据占用1字节。
数据表的index_granularity粒度为8192,所以每一个索引片段大小正是8192B。
按照数据压缩块规则,8192B<64KB,当等于64KB压缩为下一个数据块。(64KB/8192B=8,也就是8行数据为一个数据压缩块)
MergeTree如何定位压缩数据块并读取数据:
1.读取压缩数据块:在查询某一列数据MergeTree无须一次性加载整个.bin文件。借住标记文件中的压缩文件偏移量加载指定的数据压缩块。
2.读取数据:解压后的数据,MergeTree并不需要一次性扫描整段解压数据,借住标记文件中保存的数据块中偏移量以index_granularity的粒度加载特定一小段
6.6 对于分区、索引、标记和压缩数据的协同总结
6.6.1 写入过程
1.生成分区目录(伴随每一次insert操作,生成一个新的分区目录);
2.在后续的某个时刻,合并相同分区的目录;
3.按照index_granularity索引粒度,分别生成primary.idx索引文件、二级索引、每一列字段的.mrk数据标记和.bin压缩数据文件。
索引和标记区间对应,标记区间与压缩块区间不同,生成一对一,一对多,多对一的三种关系。
根据分区目录:201403_1_34_3得知:
该分区的N行数据,34次分批写入,合并3次。
6.6.2 查询过程
1.minmax.idx (分区索引)
2.primary.idx (一级索引)
3.skp_idx.idx (二级索引)
4…mrk (标记文件)
5…bin (数据压缩文件)
查询语句中没有where条件,1,2,3步骤不走;先扫描所有分区目录,及目录内索引段的最大区间,MergeTree借住数据标记,多线程的形式读取多个压缩块。
6.6.3 数据标记与压缩数据块的对应关系
压缩块的划分:
索引粒度(index_granularity)的大小,及压缩块的三种规则决定数据块的大小在64KB~1MB。
而一个索引间隔的数据,产生一行数据标记。
多对一:多个数据标记对应一个数据压缩块。一个index_granularity的未压缩SIZE<64KB
假设JavaEnable字段的数据类型为UInt8,所以每行数据占用1字节。数据表的index_granularity粒度为8192,所以每一个索引片段大小正是8192B。按照数据压缩块规则,8192B<64KB,当等于64KB压缩为下一个数据块。(64KB/8192B=8,也就是8行数据为一个数据压缩块)
一对一:一个数据标记对应一个数据压缩块。一个index_granularity的未压缩64KB<= SIZE <= 1MB
假设URLHash字段数据类型UInt64,大小为8B,则一个默认间隔的数据大小为8*8192=65536B,正好是64KB。此时的标记数据和压缩数据是一对一的关系。
一对多:一个数据标记对应多个数据压缩块。一个index_granularity的未压缩SIZE> 1MB
假设URL字段类型为String,内容正好4.8MB,那么一个数据标记文件对应5个数据压缩块。
七、数据字典
数据字典是clickhouse提供的存储媒介,用键值和属性映射的形式定义数据。
数据字典常驻内存,适合保存常量或者经常使用的维度表数据(减少json查询)
数据字典分类:内置字典和扩展字典
7.1 内置字典
内置字典clickhouse默认自带的字典,目前只有一种:Yandex.Metrica字典,快速读取geo地理数据。
默认内置字典禁用状态。
开启方式config.xml
<path_to_regions_hierarchy_file>/opt/geo/regions_hierarchy.txtpath_to_regions_hierarchy_file>
<path_to_regions_names_files>/opt/geo/path_to_regions_names_files>
惰性加载,只有当字典首次被查询的时候才会触发加载动作。
填充Yandex.Metrica字典的geo地理数据由以上两种模型组成。
1.path_to_regions_hierarchy_file
path_to_regions_hierarchy_file等同于区域数据的主表,由1个regions_hierarchy.txt和多个regions_hierarchy_[name].txt区域层次的数据文件共同组成。[name]表示区域标识符,与i18n类似。
| 名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| Region ID | UInt32 | 是 | 区域ID |
| Parent Region ID | UInt32 | 是 | 上级区域ID |
| Region Type | UInt8 | 是 | 区域类型:1.continect 3.country 4.federal district 5.region 6.city |
| Population | UInt32 | 否 | 入口 |
2.path_to_regions_names_files
path_to_regions_names_files等同于区域数据的维度,记录了与区域ID对应的区域名称。维度使用6个regions_names_[name].txt文件保存,其中[name]表示区域标识符与regions_hierarchy__[name].txt对应,包括ru,en,ua,by,kz,tr,必须全部定义,首次加载会一次性加载6个区域标识的数据文件。缺一导致内置字典抛出异常初始化失败。
| 名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| Region ID | UInt32 | 是 | 区域ID |
| parent Name | String | 是 | 区域名称 |
7.2 扩展字典
扩展字典是用户自定义配置以插件形式实现的字典。目前扩展字典支持7种类型的内存布局和4类数据来源。
7.2.1 准备字典数据
获取数据源:
organization.csv
企业组织数据,用于flat,hashed,cache,complex_key_hashed和complex_key_cache
1,2016-01-01,2017-01-10,100
2,2016-05-01,2017-07-01,200
3,2014-03-05,2018-01-20,300
4,2018-08-01,2019-10-01,400
5,2017-03-01,2017-06-01,500
6,2017-04-09,2018-05-30,600
7,2018-06-01,2019-01-25,700
8,2019-08-01,2019-12-12,800
asn.csv
asn数据,用于演示ip_trie字典的场景
"82.118.230.0/24","AS42831","GB"
"148.163.0.0/17","AS53755","US"
"178.93.0.0/18","AS6849","UA"
"200.69.95.0/24","AS262186","CO"
"154.9.160.0/20","AS174","US"
sales.csv
销售数据,用于演示range_hashed字典的演示
1,"a0001","研发部"
2,"a0002","产品部"
3,"a0003","数据部"
4,"a0004","测试部"
5,"a0005","运维部"
6,"a0006","规划部"
7.2.2 扩展字典配置文件的元素组成
扩展字典有配置文件config.xml中dictionaries_config配置向指定:
<dictionaries_config>*_dictionary.xmldictionaries_config>
vim /etc/clickhouse-server/test_dictionary.xml
<dictionaries>
<dictionary>
<name>testname>
<source>
<odbc>
<connection_string>DSN=pg;UID=;PWD=;HOST=;PORT=5432;DATABASE=connection_string>
<table>producttable>
odbc>
source>
<lifetime>
<min>300min>
<max>360max>
lifetime>
<layout>
<hashed/>
layout>
<structure>
<id>
<name>idname>
id>
<attribute>
<name>del_flagname>
<type>UInt64type>
<null_value>0null_value>
attribute>
structure>
dictionary>
dictionaries>
dictionary元素定义分为5个子元素:
1.name:字典的名称,用于确定字典的唯一标识,必须全局唯一。多个字点之间不允许重复。
2.structure:字典的数据结构
3.layout:字典的类型。
4.source:字典的数据源。
5.lifetime:字典的更新时间。
7.2.3 扩展字典的数据结构
扩展字典的数据结构,由structure元素定义,由键值Key(描述字典的数据标识)和属性attribute(字段属性)两部分组成。
<structure>
<id>
<name>idname> id或者key相关的属性
id>
<attribute> 字段属性
<name>del_flagname>
<type>UInt64type>
<null_value>0null_value>
attribute>
structure>
1.key
用于定义字典的键值,每个字典必须包含一个键值key字段,用于定义数据,类似数据库表的主键。
键值key分为数值型和复合型。
数值型:数值型key有UInt64整型定义,支持flat,hashed,range_hashed和cache类型的字典。
复合型:复合型key使用Tuple元组定义,可以由1到多个字段组成,类似数据库的符合主键,仅支持complex_key_hashed,complex_key_cache和ip_trie类型的字典。
2.attribute
用于定义字典的属性字段,字典可以拥有1到多个属性字段。
| 配置名称 | 是否必填 | 默认值 | 说明 |
|---|---|---|---|
| name | 是 | - | 字段名称 |
| type | 是 | - | 字段类型 |
| null_value | 是 | - | 在查询时,条件key没有对应元素时默认值 |
| expression | 否 | 无表达式 | 表达式,可以调用函数或者使用运算符 |
| hierarchical | 否 | false | 是否支持层次结构 |
| injective | 否 | false | 是否支持集合单射优化 |
| is_object_id | 否 | false | 是否开启MongoDB优化 |
7.2.4 扩展字典的类型
扩展字典的类型使用layout元素定义,目前支持7种类型。一个字段类型,决定了其数据在内存中的存储结构和字典支持的key键类型。
根据key键类型划分:
一类是单数值的key类型,包括flat、hashed、range_hashed和cache;
另一类是复合key类型,包括complex_key_hashed、complex_key_cache和ip_trie。
7.2.4.1 flat
flat字典是性能最高的字典类型,只能以UInt64数值型key,使用数组结构存储,初始大小为1024,上限为500000(存储500000行数据)。在创建字典时数据量超出其上限,那么字典会创建失败。
cat /etc/clickhouse-server/test_dictionary.xml
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_flat_dict</name>
<!--数据源-->
<source>
<file>
<path>/home/clickhouse/organization.csv</path>
<format>CSV</format>
</file>
</source>
<!--字典类型-->
<layout>
<flat/>
</layout>
<!--与数据结构对应-->
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value></null_value>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value></null_value>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
select * from system.dictionaries\G
Row 1:
──────
database:
name: test_flat_dict
uuid: 00000000-0000-0000-0000-000000000000
status: NOT_LOADED
origin: /etc/clickhouse-server/test_dictionary.xml
type:
key:
attribute.names: []
attribute.types: []
bytes_allocated: 0
query_count: 0
hit_rate: 0
element_count: 0
load_factor: 0
source:
lifetime_min: 0
lifetime_max: 0
loading_start_time: 1970-01-01 08:00:00
last_successful_update_time: 1970-01-01 08:00:00
loading_duration: 0
last_exception:
1 rows in set. Elapsed: 0.005 sec.
SELECT dictGet('test_flat_dict', 'name', toUInt64(1));
┌─dictGet('test_flat_dict', 'name', toUInt64(1))─┐
│ 研发部 │
└────────────────────────────────────────────────┘
select * from system.dictionaries\G
Row 1:
──────
database:
name: test_flat_dict
uuid: 00000000-0000-0000-0000-000000000000
status: LOADED
origin: /etc/clickhouse-server/test_dictionary.xml
type: Flat
key: UInt64
attribute.names: ['code','name']
attribute.types: ['String','String']
bytes_allocated: 41328
query_count: 2
hit_rate: 1
element_count: 6
load_factor: 0.005859375
source: File: /home/clickhouse/organization.csv CSV
lifetime_min: 300
lifetime_max: 360
loading_start_time: 2020-12-24 13:58:29
last_successful_update_time: 2020-12-24 13:58:29
loading_duration: 0.001
last_exception:
1 rows in set. Elapsed: 0.007 sec.
7.2.4.2 hashed
hashed字典与flat不同的是,flat是以数组的方式存储,hashed则是散列结构,没有上限制约。
以下是hashed字典的配置示例:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_hashed_dict</name>
<!--数据源-->
<source>
<file>
<path>/home/clickhouse/organization.csv</path>
<format>CSV</format>
</file>
</source>
<!--字典类型 只有这个地方不一样-->
<layout>
<hashed/>
</layout>
<!--与数据结构对应-->
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value></null_value>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value></null_value>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
SELECT dictGet('test_flat_dict', 'name', toUInt64(1));
┌─dictGet('test_flat_dict', 'name', toUInt64(1))─┐
│ 研发部 │
└────────────────────────────────────────────────┘
select * from system.dictionaries\G
Row 1:
──────
database:
name: test_flat_dict
uuid: 00000000-0000-0000-0000-000000000000
status: LOADED
origin: /etc/clickhouse-server/test_dictionary.xml
type: Hashed
key: UInt64
attribute.names: ['code','name']
attribute.types: ['String','String']
bytes_allocated: 20880
query_count: 1
hit_rate: 1
element_count: 12
load_factor: 0.046875
source: File: /home/clickhouse/organization.csv CSV
lifetime_min: 300
lifetime_max: 360
loading_start_time: 2020-12-24 14:05:29
last_successful_update_time: 2020-12-24 14:05:29
loading_duration: 0
last_exception:
1 rows in set. Elapsed: 0.005 sec.
7.2.4.3 range_hashed
在hashed字典的基础上增加了指定时间区间的特性,数据会以散列结构存储并按照时间排序。时间的区间通过range_min和range_max元素指定,所指定的字段必须是Date或者DateTime类型。
<dictionaries>
<dictionary>
<name>test_range_hashed_dictname>
<source>
<file>
<path>/home/clickhouse/sales.csvpath>
<format>CSVformat>
file>
source>
<layout>
<range_hashed/>
layout>
<structure>
<id>
<name>idname>
id>
<range_min>
<name>startname>
range_min>
<range_max>
<name>endname>
range_max>
<attribute>
<name>pricename>
<type>Float32type>
<null_value>null_value>
attribute>
structure>
<lifetime>
<min>300min>
<max>360max>
lifetime>
dictionary>
dictionaries>
select name,type,key,attribute.names,attribute.types from system.dictionaries;
┌─name───────────────────┬─type────────┬─key────┬─attribute.names─┬─attribute.types─┐
│ test_range_hashed_dict │ RangeHashed │ UInt64 │ ['price'] │ ['Float32'] │
└────────────────────────┴─────────────┴────────┴─────────────────┴─────────────────┘
SELECT *
FROM system.dictionaries
Row 1:
──────
database:
name: test_range_hashed_dict
uuid: 00000000-0000-0000-0000-000000000000
status: LOADED
origin: /etc/clickhouse-server/test_dictionary.xml
type: RangeHashed
key: UInt64
attribute.names: ['price']
attribute.types: ['Float32']
bytes_allocated: 8352
query_count: 0
hit_rate: 1
element_count: 8
load_factor: 0.03125
source: File: /home/clickhouse/sales.csv CSV
lifetime_min: 300
lifetime_max: 360
loading_start_time: 2020-12-24 15:12:42
last_successful_update_time: 2020-12-24 15:12:42
loading_duration: 0
last_exception:
1 rows in set. Elapsed: 0.006 sec.
7.2.4.4 cache
在内存中会通过固定长度的向量数组保存,长度为2 的整数倍并会自动向上取整,并不会像其他字典查询一次后一次性全部直接加载到内存,而是命中一次加载一次,所以性能最不稳定,完全取决于命中率(缓存命中率=命中次数/查询次数)
7.2.4.5 complex_key_hashed
该类型的字典在功能上与hashed字典完全相同,只是将单个的数值的key替换成了复合型
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_complex_hashed_dict</name>
<!--数据源-->
<source>
<file>
<path>/home/clickhouse/organization.csv</path>
<format>CSV</format>
</file>
</source>
<!--字典类型 只有这个地方不一样-->
<layout>
<complex_key_hashed/>
</layout>
<!--与数据结构对应-->
<structure>
<key>
<attribute>
<name>id</name>
<type>UInt64</type>
</attribute>
<attribute>
<name>code</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>name</name>
<type>String</type>
<null_value></null_value>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
SELECT dictGet('test_complex_hashed_dict', 'name', (toUInt64(1), 'a0001'))
┌─dictGet('test_complex_hashed_dict', 'name', tuple(toUInt64(1), 'a0001'))─┐
│ 研发部 │
└──────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.006 sec.
SELECT *
FROM system.dictionaries
Row 1:
──────
database:
name: test_complex_hashed_dict
uuid: 00000000-0000-0000-0000-000000000000
status: LOADED
origin: /etc/clickhouse-server/test_dictionary.xml
type: ComplexKeyHashed
key: (UInt64, String)
attribute.names: ['name']
attribute.types: ['String']
bytes_allocated: 18728
query_count: 1
hit_rate: 1
element_count: 6
load_factor: 0.0234375
source: File: /home/clickhouse/organization.csv CSV
lifetime_min: 300
lifetime_max: 360
loading_start_time: 2020-12-24 14:37:35
last_successful_update_time: 2020-12-24 14:37:35
loading_duration: 0.002
last_exception:
1 rows in set. Elapsed: 0.007 sec.
7.2.4.6 complex_key_cache
在cache字典的基础上,将单数值的key替换为复合型。
7.2.4.7 ip_trie
专门用于IP前缀查询的场景。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_ip_trie_dict</name>
<!--数据源-->
<source>
<file>
<path>/home/clickhouse/asn.csv</path>
<format>CSV</format>
</file>
</source>
<!--字典类型-->
<layout>
<ip_trie/>
</layout>
<!--与数据结构对应-->
<structure>
<key>
<attribute>
<name>prefix</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>asn</name>
<type>String</type>
<null_value></null_value>
</attribute>
<attribute>
<name>country</name>
<type>String</type>
<null_value></null_value>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
SELECT dictGet('test_ip_trie_dict', 'country', tuple(IPv4StringToNum('148.163.0.0')))
┌─dictGet('test_ip_trie_dict', 'country', tuple(IPv4StringToNum('148.163.0.0')))─┐
│ US │
└────────────────────────────────────────────────────────────────────────────────┘
-
总结
名称 存储结构 字典键类型 支持的数据源 flat 数组 UInt64 Local file、Executable file、HTTP、DBMS hashed 散列 UInt64 Local file、Executable file、HTTP、DBMS range_hashed 散列按时间排序 UInt64和时间 Local file、Executable file、HTTP、DBMS complex_key_hashed 散列 复合型key Local file、Executable file、HTTP、DBMS ip_trie 层次结构 复合型key(单个String) Local file、Executable file、HTTP、DBMS cache 固定大小数组 UInt64 Executable file、HTTP、ClickHouse、MySQL complex_key_cache 固定大小数组 复合型key Executable file、HTTP、ClickHouse、MySQL
7.2.5 扩展字典的数据源
-
文件类型
本地文件:采用file元素定义。path定义绝对路径,format定义数据格式(CSV或者TabSeparated)
可执行文件:采用executable元素定义。command定义绝对路径,format定义数据格式
远程文件:采用http元素定义。url定义数据访问路径,format定义数据格式
-
数据库类型
MySQL:数据源支持指定的数据库中提取数据,作为字典的数据来源。
ClickHouse:准备好数据源的测试数据编写配置文件即可。
MongoDB:执行语句后,会自动创建相应的schema并写入数据。
7.2.6 扩展字典的数据更新策略
扩展字典支持数据的在线更新,更新无须重启服务。字典数据的更新频率由配置文件中lifetime元素定义,单位秒。同时也代表缓存失效时间。
<lifetime>
<min>300min>
<max>360max>
lifetime>
min和max分别指定了更新间隔的上下限。ClickHouse会在这个时间区间内触发更新操作。
-
文件数据源
文件类型的数据源的previous值来自系统文件的修改时间。
stat test_dictionary.xml File: ‘test_dictionary.xml’ Size: 1077 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 202620427 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2020-12-24 15:26:21.089166098 +0800 Modify: 2020-12-24 15:26:16.121165975 +0800 Change: 2020-12-24 15:26:16.121165975 +0800当前后的previous的值不相同时,才会触发数据更新。
-
MySQL(InnoDB),clickhouse和ODBC
它的值previous值来源invalidate_query中定义的SQL语句。
-
MySQL(MyISAM)
通过SHOW TABLE STATUS命令查看修改时间,前后两次Update_time的值不同,则会判定源数据发生了变化。
7.2.7 扩展字典的基本操作
-
元数据查询
select name,type,key,attribute.names,attribute.types,source from system.dictionaries; Row 1: name: test_ip_trie_dict type: Trie key: (String) attribute.names: ['asn','country'] attribute.types: ['String','String'] source: File: /home/clickhouse/asn.csv CSV name: 字典名称 status: 字典状态 origin: 字典加载的配置文件 type: 字典所属类型 key: 字典的Key值,数据通过Key值定位 attribute.names: 属性名称 attribute.types: 属性类型 bytes_allocated: 已载入数据在内存中占用的字节数 query_count: 字典被查询的次数 hit_rate: 字典数据查询的命中率 element_count: 已载入数据的行数 load_factor: 数据的加载率 source: 数据源信息 last_exception: 异常信息,重点关注对象 -
数据查询
可以使用字典函数(dictGet)或者system.dictionaries查询。
八、MergeTree系列表引擎
8.1 MergeTree
两项能力:数据TTL和存储策略。
8.1.1 TTL
TTL即time To Live,数据的存活时间。
MergeTree中,可以为某个列字段,或者整张表设置TTL。当时间到达时,如果是列字段级别为TTL,则会删除这一列数据;如果是表级别为TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,会以先到时间的为准删除数据。
无论是列或者表级别的TTL,都依靠DateTime或Date类型字段,通过对这个时间字段的INTERVAL操作,来确定TTL过期时间:
示例:
TTL time_column + interval 3 DAY
表示数据存活的时间为time_column 时间的3天之后。
TTL time_column + interval 1 MONTH
表示数据存活的时间为time_column 时间的1月之后。
INTERVAL支持的操作:second,minute,hour,day,week,month,quarter,year。
8.1.1.1 列级别的TTL
若要设置列级别的TTL,则需要在定义表字段的时候,为他们声明TTL表达式,主键字段不能被声明TTL。
示例:
CREATE TABLE t_column_ttl
(
id UInt64 COMMENT 'Primary key',
create_time Datetime,
product_desc String TTL create_time + toIntervalSecond(10),
product_type UInt8 TTL create_time + toIntervalSecond(10)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
insert into table t_column_ttl values(1,now(),'Huawei',1),(2,now()+interval 1 minute,'Apple',2);
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:16:28 │ Huawei │ 1 │
│ 2 │ 2020-12-24 16:17:28 │ Apple │ 2 │
└────┴─────────────────────┴──────────────┴──────────────┘
select sleep(10);
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:18:51 │ │ 0 │
│ 2 │ 2020-12-24 16:19:51 │ Apple │ 2 │
└────┴─────────────────────┴──────────────┴──────────────┘
optimize table t_column_ttl final;
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:18:51 │ │ 0 │
│ 2 │ 2020-12-24 16:19:51 │ │ 0 │
└────┴─────────────────────┴──────────────┴──────────────┘
# 执行optimize命令会强制触发TTL清理,若再次查询可以看到满足TTL条件之后,定义了TTL操作的字段列会被还原为数据类型的默认值。
# 修改列字段的TTL或者修改已有字段的TTL:
alter table t_column_ttl MODIFY COLUMN product_desc String TTL create_time + INTERVAL 2 DAY;
# 添加字段的TTL:
alter table t_column_ttl add column product_name String comment '产品名称' ttl create_time + interval 3 month;
# 查看TTL的信息:
desc t_column_ttl\G
Row 1:
──────
name: id
type: UInt64
default_type:
default_expression:
comment: Primary key
codec_expression:
ttl_expression:
Row 2:
──────
name: create_time
type: DateTime
default_type:
default_expression:
comment:
codec_expression:
ttl_expression:
Row 3:
──────
name: product_desc
type: String
default_type:
default_expression:
comment:
codec_expression:
ttl_expression: create_time + toIntervalSecond(10)
Row 4:
──────
name: product_type
type: UInt8
default_type:
default_expression:
comment:
codec_expression:
ttl_expression: create_time + toIntervalSecond(10)
8.1.1.2 表级别的TTL
可以在MergeTree的表参数中增加TTL表达式 为整张表设置TTL。
设置之前需要查找配置的 disk和volume
SELECT * FROM system.disks
┌─name────┬─path──────────────────────┬───free_space─┬──total_space─┬─keep_free_space─┬─type──┐
│ default │ /var/lib/clickhouse/ │ 100418579456 │ 102818225152 │ 1024 │ local │
│ disk_1 │ /mnt/fast_ssd/clickhouse/ │ 49954570240 │ 52710309888 │ 0 │ local │
│ disk_2 │ /mnt/hdd1/clickhouse/ │ 39246221312 │ 42130964480 │ 10485760 │ local │
│ disk_3 │ /mnt/hdd2/clickhouse/ │ 39916331008 │ 42130964480 │ 10485760 │ local │
└─────────┴───────────────────────────┴──────────────┴──────────────┴─────────────────┴───────┘
select * from system.storage_policies\G
Row 1:
──────
policy_name: default
volume_name: default
volume_priority: 1
disks: ['default']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0
Row 2:
──────
policy_name: hdd_jbod
volume_name: jbod_volume
volume_priority: 1
disks: ['disk_2','disk_3']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 3:
──────
policy_name: policy_1_only
volume_name: volume_1
volume_priority: 1
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 4:
──────
policy_name: policy_hot_and_cold_data
volume_name: hot_volume
volume_priority: 1
disks: ['disk_1']
volume_type: JBOD
max_data_part_size: 1073741824
move_factor: 0.1
Row 5:
──────
policy_name: policy_hot_and_cold_data
volume_name: cold_volume
volume_priority: 2
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 6:
──────
policy_name: policy_hot_and_cold_data_movefactor99
volume_name: hot_volume
volume_priority: 1
disks: ['disk_1']
volume_type: JBOD
max_data_part_size: 1073741824
move_factor: 0.01
Row 7:
──────
policy_name: policy_hot_and_cold_data_movefactor99
volume_name: cold_volume
volume_priority: 2
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.01
7 rows in set. Elapsed: 0.005 sec.
# 表的定义:
CREATE TABLE t_table_ttl
(
`id` UInt64 COMMENT '主键',
`create_time` Datetime COMMENT '创建时间',
`product_desc` String COMMENT '产品描述' TTL create_time + toIntervalMinute(10),
`product_type` UInt8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
表级别的TTL修改:
alter table t_table_ttl modify ttl create_time + interval 2 month;
查看信息:
SELECT
database,
name,
engine,
data_paths,
metadata_path,
metadata_modification_time,
partition_key,
sorting_key
FROM system.tables
WHERE name = 't_table_ttl'
Row 1:
──────
database: default
name: t_table_ttl
engine: MergeTree
data_paths: ['/var/lib/clickhouse/data/default/t_table_ttl/']
metadata_path: /var/lib/clickhouse/metadata/default/t_table_ttl.sql
metadata_modification_time: 2020-12-24 16:34:47
partition_key: toYYYYMM(create_time)
sorting_key: create_time
# 查看表的结构:
DESCRIBE TABLE t_table_ttl
Row 1:
──────
name: id
type: UInt64
default_type:
default_expression:
comment: 主键
codec_expression:
ttl_expression:
Row 2:
──────
name: create_time
type: DateTime
default_type:
default_expression:
comment: 创建时间
codec_expression:
ttl_expression:
Row 3:
──────
name: product_desc
type: String
default_type:
default_expression:
comment: 产品描述
codec_expression:
ttl_expression: create_time + toIntervalMinute(10)
Row 4:
──────
name: product_type
type: UInt8
default_type:
default_expression:
comment:
codec_expression:
ttl_expression:
注意:列级别或者表级别的TTL 目前暂不支持取消操作。
8.1.1.3 TTL的运行机理
若一张MergeTree表被设置为TTL 则在写入数据时候会以数据分区为单位,在每个分区目录内生成一个ttl.txt的文件。
写入数据:
insert into t_table_ttl(id,create_time,product_desc,product_type)values(10,now(),'Huawei',1),(20,now()+ interval 10 minute,'Apple',2);
ll /var/lib/clickhouse/data/default/t_table_ttl/
total 4
drwxr-x--- 2 clickhouse clickhouse 322 Dec 24 17:14 202012_1_1_0
drwxr-x--- 2 clickhouse clickhouse 6 Dec 24 16:34 detached
-rw-r----- 1 clickhouse clickhouse 1 Dec 24 16:34 format_version.txt
ll /var/lib/clickhouse/data/default/t_table_ttl/202012_1_1_0/
total 60
-rw-r----- 1 clickhouse clickhouse 464 Dec 24 17:14 checksums.txt
-rw-r----- 1 clickhouse clickhouse 115 Dec 24 17:14 columns.txt
-rw-r----- 1 clickhouse clickhouse 1 Dec 24 17:14 count.txt
-rw-r----- 1 clickhouse clickhouse 34 Dec 24 17:14 create_time.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 create_time.mrk2
-rw-r----- 1 clickhouse clickhouse 39 Dec 24 17:14 id.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 id.mrk2
-rw-r----- 1 clickhouse clickhouse 8 Dec 24 17:14 minmax_create_time.idx
-rw-r----- 1 clickhouse clickhouse 4 Dec 24 17:14 partition.dat
-rw-r----- 1 clickhouse clickhouse 8 Dec 24 17:14 primary.idx
-rw-r----- 1 clickhouse clickhouse 39 Dec 24 17:14 product_desc.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 product_desc.mrk2
-rw-r----- 1 clickhouse clickhouse 28 Dec 24 17:14 product_type.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 product_type.mrk2
-rw-r----- 1 clickhouse clickhouse 93 Dec 24 17:14 ttl.txt
cat /var/lib/clickhouse/data/default/t_table_ttl/202012_1_1_0/ttl.txt
ttl format version: 1
{"columns":[{"name":"product_desc","min":1608801843,"max":1608802443}]}
cat /var/lib/clickhouse/data/default/t_column_ttl/202012_1_1_1/ttl.txt
ttl format version: 1
{"columns":[{"name":"product_desc","min":1608802649,"max":1608802649},{"name":"product_type","min":1608802649,"max":1608802649}]}
可以看到MergeTree是通过一串JSON配置保存了TTL的相关信息。
columns 用于保存列级别的TTL信息
tables 用于保存表级别的TTL信息
min和max则保存了当前数据分区内TTL指定的日期字段的最小值和最大值分别与INTERVAL表达式计算后的时间戳。
# 列
select toDateTime('1608801843') ttl_min,toDateTime('1608802443') ttl_max,ttl_min - min(create_time) expire_min,ttl_max - max(create_time) expire_max from t_table_ttl;
┌─────────────ttl_min─┬─────────────ttl_max─┬─expire_min─┬─expire_max─┐
│ 2020-12-24 17:24:03 │ 2020-12-24 17:34:03 │ 600 │ 600 │
└─────────────────────┴─────────────────────┴────────────┴────────────┘
# 表
select toDateTime('1608802649') ttl_min,toDateTime('1608802649') ttl_max,ttl_min - min(create_time) expire_min,ttl_max - max(create_time) expire_max from t_table_ttl;
┌─────────────ttl_min─┬─────────────ttl_max─┬─expire_min─┬─expire_max─┐
│ 2020-12-24 17:37:29 │ 2020-12-26 17:37:29 │ 86400 │ 86400 │
└─────────────────────┴─────────────────────┴────────────┴────────────┘
可以看ttl.txt 记录的极值区间恰好等于当前数据分区内create_time的最大值和最小值加1天(86400S ),和TTL的表达式的预期相符合。
通过TTL的信息记录方式 可以推断大体的处理逻辑:
1.MergeTree 是以分区目录为单位,通过ttl.txt 记录过期时间,并以此作为判断标准。
2.每当写入一批数据时候,都会基于interval 表达式的计算结果为这个分区生成ttl.txt 文件
3.只有在MergeTree合并分区才会触发TTL过期数据的逻辑
4.在删除分区的时候,选择使用了贪婪算法,算法规则即尽可能找到会最早过期,同时时间最早的分区。
5.若一个分区内某一列因为TTL到期则全部删除,在合并之后生成的新分区目录中将不会包含这个列字段的数据文件(.bin 和.mrk)
注意:
1.TTL默认的合并频率有MergeTree的参数merge_with_ttl_timeout 控制,默认周期为86400秒。它专门维护一个专有的TTL任务队列。有别于MergeTree的常规合并任务,若这个值设置的过小则可能会带来性能损耗。
此设置意味着仅在一个分区上或发生后台合并时,每24小时执行一次TTL删除。因此,在最坏的情况下,ClickHouse现在最多每24小时删除一个与TTL delete表达式匹配的分区。
此行为可能并不理想,因此,如果您希望TTL删除表达式更快地执行删除操作,则可以修改表的merge_with_ttl_timeout设置
设置为一个小时。
alter table t_table_ttl MODIFY SETTING merge_with_ttl_timeout = 3600;
2.除了触发TTL合并外,optimize 命令可以强制触发合并。
触发一个分区合并: optimize table t;
触发所有分区合并: optimize table t final;
3.目前没有删除ttl的声明方法,但是提供了全局控制TTL合并任务的启动和关停方法:
system stop/start TTL MERGES
8.1.2 多路径存储策略
在ClickHouse 19.15版本之前,MergeTree只支持半路径存储,所有的数据都会被写入到config.xml配置中path指定路径下。
在ClickHouse 19.15版本之后,MergeTree实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
8.2 ReplacingMergeTree
MergeTree拥有主键,但是主键没有唯一键约束(会出现主键相同)。
ReplacingMergeTree为了数据去重而设计,能够在合并分区时删除重复的数据。一定程度解决了重复数据的问题(同数据分区)。
# 建表语法
CREATE TABLE replace_table(
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY(id,code)
PRIMARY KEY id ;
insert into replace_table values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-11 17:00:00'),('A001','C100','2019-05-12 17:00:00'),('A001','C200','2019-05-13 17:00:00'),('A002','C2','2019-05-14 17:00:00'),('A003','C3','2019-05-15 17:00:00');
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
ORDER BY是去除重复数据的关键,排序键ORDER BY所声明的表达式是后续作为判断数据是否重复的依据。在这个例子中,数据会基于id和code两个字段去重。
执行optimize强制触发合并后,会按照id和code分组,保留分组内的最后一条(观察create_time日期字段):
optimize TABLE replace_table FINAL;
select * from replace_table;
┌─i───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
从执行的结果来看,ReplacingMergeTree在去除重复数据时,确实是以ORDERBY排序键为基准的,而不是PRIMARY KEY。因为在上面的例子中,ORDER BY是(id, code),而PRIMARY KEY是id,如果按照id值去除重复数据,则最终结果应该只剩下A001、A002和A003三行数据。
CREATE TABLE replace_table_v1(
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY(id)
PRIMARY KEY id ;
insert into replace_table_v1 values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-11 17:00:00'),('A001','C100','2019-05-12 17:00:00'),('A001','C200','2019-05-13 17:00:00'),('A002','C2','2019-05-14 17:00:00'),('A003','C3','2019-05-15 17:00:00');
select * from replace_table_v1 ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table_v1 FINAL;
select * from replace_table_v1 ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
写入之后,执行optimize强制分区合并,并查询数据:
insert into replace_table values ('A001','C1','2020-07-02 12:01:01');
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2020-07-02 12:01:01 │
└──────┴──────┴─────────────────────┘
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table FINAL;
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2020-07-02 12:01:01 │
└──────┴──────┴─────────────────────┘
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
观察返回的数据,可以看到A001:C1依然出现了重复。这是因为ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。这就是上面说ReplacingMergeTree只是在一定程度上解决了重复数据问题的原因。
ReplacingMergeTree版本号的用法。以下面的语句为例:
CREATE TABLE replace_table_v (
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMM(create_time)
ORDER BY id ;
replace_table_v基于id字段去重,并且使用create_time字段作为版本号
insert into replace_table_v values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-25 17:00:00'),('A001','C200','2019-05-13 17:00:00');
select * from replace_table_v
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-25 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table_v FINAL;
select * from replace_table_v ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-25 17:00:00 │
└──────┴──────┴─────────────────────┘
ReplacingMergeTree的处理逻辑。
(1)使用ORBER BY排序键作为判断重复数据的唯一键。
(2)只有在合并分区的时候才会触发删除重复数据的逻辑。
(3)以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
(4)在进行数据去重时,因为分区内的数据已经基于ORBER BY进行了排序,所以能够找到那些相邻的重复数据。
(5)数据去重策略有两种:
❑ 如果没有设置ver版本号,则保留同一组重复数据中的最后一行。
❑ 如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
十、副本与分片
副本和分片区分:
数据层面区分:
假设CK集群两个节点,host1,host2,两个节点都有结构相同的一张表table。
此时如果host1的table中的数据和host2的table中的数据不同,那就是分片;
此时如果host1的table中的数据和host2的table中的数据相同,那就是副本。
功能作用层面区分:
副本:防止数据丢失,增加数据存储的冗余;
分片:实现数据的水平切分,提高数据写入读取的性能。