负载均衡的实现算法
前言
负载均衡这个概念,几乎在所有支持高可用的技术栈中都存在,例如微服务、分库分表、各大中间件(MQ、Redis、MyCat、Nginx、ES)等,也包括云计算、云调度、大数据中也是炙手可热的词汇。
负载均衡策略主要分为静态与动态两大类:
- 静态调度算法:指配置后只会依据配置好的策略进行请求分发的算法。
- 动态调度算法:指配置后会根据线上情况(网络/CPU 负载/磁盘 IO 等)来分发请求。
但负载均衡算法数量并不少,本篇主要对于一些常用且高效的负载策略进行剖析。
静态调度算法
轮询算法
轮询算法是最为简单、也最为常见的算法,也是大多数集群情况下的默认调度算法,这种算法会按照配置的服务器列表,按照顺序依次分发请求,所有服务器都分发一遍后,又会回到第一台服务器循环该步骤。
实现方案一般通过一个原子计数器记录当前请求的序列号,然后直接通过 % 集群中的服务器节点总数,最终得到一个具体的下标值,再通过这个下标值,从服务器 IP 列表中获取一个具体的 IP 地址。
轮询算法的优势:
- 算法实现简单,请求分发效率够高。
- 能够将所有请求均摊到集群中的每个节点上。
- 易于后期弹性伸缩,业务增长时可以拓展节点,业务萎靡时可以缩减节点。
轮询算法的劣势:
- 对于不同配置的服务器无法合理照顾,无法将高配置的服务器性能发挥出来。
- 由于请求分发时,是基于请求序列号来实现的,所以无法保证同一客户端的请求都是由同一节点处理的,因此需要通过 session 记录状态时,无法确保其一致性。
轮询算法的应用场景:
- 集群中所有节点硬件配置都相同的情况。
- 只读不写,无需保持状态的情景。
随机算法
随机算法的实现也非常简单,也就是当客户端请求到来时,每次都会从已配置的服务器列表中随机抽取一个节点处理。
实现方案一般做一个随机数产生器,从服务器列表中随机抽取一个节点处理请求,该算法的结果也不测试了,大家估计一眼就能看明白。
随机算法的优势:个人看来该算法单独使用的意义并不大,一般会配合下面要讲的权重策略协同使用。
随机算法的劣势:
- 无法合理的将请求均摊到每台服务器节点。
- 由于处理请求的目标服务器不明确,因此也无法满足需要记录状态的请求。
- 能够在一定程度上发挥出高配置的机器性能,但充满不确定因素。
权重算法
权重算法是建立在其他基础算法之上推出的一种概念,权重算法并不能单独配置,因为权重算法无法做到请求分发的调度,所以一般权重会配合其他基础算法结合使用,如:轮询权重算法、随机权重算法等,这样可以让之前的两种基础调度算法更为“人性化”一些。
权重算法是指对于集群中的每个节点分配一个权重值,权重值越高,该节点被分发的请求数也会越多,反之同理。
这样做的好处十分明显,也就是能够充分考虑机器的硬件配置,从而分配不同权重值,做到“能者多劳”。
先看随机权重算法:
- 设置每个节点一个权重值,算出所有节点的权重值总和。
- 当请求进来时随机一个总和范围内的数,然后遍历节点。
- 当随机数小于节点权重则直接选择该节点。
- 当随机数大于节点权重,则随机数取它减去当前节点的权重值,然后继续遍历节点,直到找到合适的节点。
接着再来看看轮询权重算法的实现:
- 设置每个节点一个权重值,算出所有节点的权重值总和,然后每个节点维护一个代表它的动态权重值,初始为其权重值。
- 每次的请求都是从第一个节点开始计算,当动态权重值不为零时,就选择该节点,然后该动态权重值递减。
- 当动态权重值为零时,就到下一个节点,一直这么循环。
- 直到最后一个节点的动态权重值为0,则又全部初始化,重新来一遍。
轮询权重算法的弊端就是在一定时间内请求都是打到一个节点的,于是后来人们提出更好的平滑加权轮询算法。
平滑轮询加权算法的本质就是为了解决之前实现方式中所存在的问题,能够将请求均匀的按照权重值分发到每台机器。它的证明公式以及实现步骤都比较拗口,这里直接举例子说明:
- 现在有三个节点,节点分配的权重依次是5、1、1,我们称之为基数权重组,然后还求他们的和5+1+1=7,称之为权重和。最终设定一个动态权重组,初始化为基数权重组的值5、1、1。
- 选择动态权重组中最大权重的节点,然后动态权重组中该节点的权重减去权重和,也就是动态权重组变成了5-7=-2、1、1,最后动态权重组=动态权重组+基数权重组,也就是5、1、1加-2、1、1等于3、2、2。
- 不断重复第二个步骤。
| 动态权重组 | 选择的节点 | 改变后的动态权重组 |
|---|---|---|
| 5、1、1 | 1 | -2、1、1 |
| 3、2、2 | 1 | -4、2、2 |
| 1、3、3 | 2 | 1、-4、3 |
| 6、-3、4 | 1 | 4、-2、5 |
| 4、-2、5 | 3 | 9、-1、-1 |
| 9、-1、-1 | 1 | 2、-1、-1 |
| 7、0、0 | 1 | 0、0、0 |
上表中列出了7次请求的处理过程,整个过程到最后,动态权重值又会回归初始值:0,0,0,然后开启新的一轮计算,周而复始之,格外的神奇。
平滑加权轮询算法也是应用最为广泛的轮询算法,在 Dubbo、Robbin、Nginx、Zookeeper 等一些集群环境中,当你配置了权重时,默认采用的就是该算法作为请求分发的策略。
一致性哈希算法
其实平滑加权轮询算法对于请求分发而言,是一种比较优秀的策略了,不过前面分析的所有策略,都存在一个致命问题:不能确保同一客户端的所有请求都分发在同一台服务器处理,因此无法实现有状态的请求。
好比最简单的登录功能,客户端发送请求登录成功,然后将其登录的状态保存在 session 中,结果客户端的第二次请求被分发到了另外一台机器,由于第二台服务器 session 中没有相关的登录信息,因此会要求客户端重新登录,这显然造成的用户体验感是极差的。当然我们可以用一些打补丁的方式解决:
- 采用外部中间件存储 session,例如 Redis,然后从 Redis 中获取登录状态。
- 采用特殊的请求分发策略,确保同一客户端的所有请求都会去到同一台机器上处理。
一致性哈希算法就是一种能够能够确保同一客户端的所有请求都会被分发到同一台机器的策略,不过一致性哈希算法依旧会存在问题,就是当集群中某个节点下线,或者集群出现拓展时,那么也会影响最终分发的目标机器。
实现一致性哈希算法的核心结构在于哈希环,一致性哈希是基于 2^32 做取模,那么首先可以将二的三十二次方想象成一个圆,这个圆总共由 2^32 个点组成,如下:
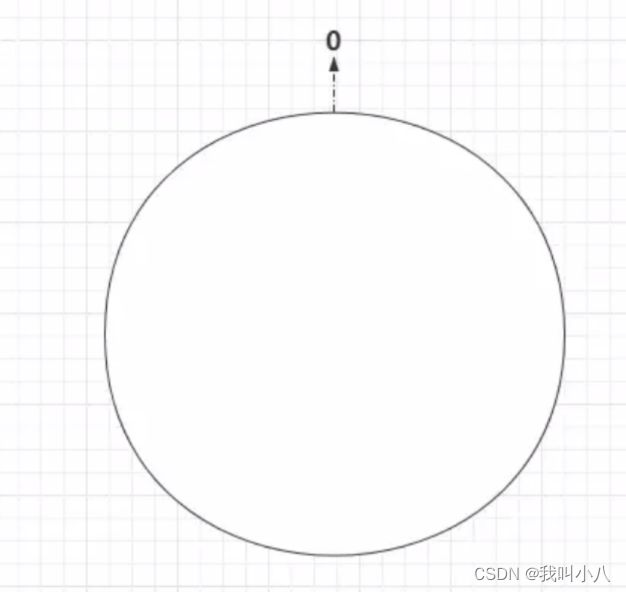
圆环的正上方第一个点代表 0,0 右侧的点按照 1、2、3、4…的顺序依此类推,直到 2^32-1,也就是说 0 左侧的第一个点代表着 2^32-1。最终这个在逻辑上由 2^32 个点组成的圆,被称为哈希环。
假设有四台服务器 A、B、C、D,然后再通过每台服务器的 IP 哈希值取模 2^32,最终必然会得到一个 2^32 范围之内的整数,这个数在哈希环上定然也对应着一个点。那么每台服务器的 IP 就可以映射到哈希环上,如下:

当有客户端访问时,通过下面2步进行寻址:
- 将客户端IP通过哈希取模计算哈希值,并确定它在环上的位置。
- 从这个位置沿着哈希环顺时针行走,遇到的第一个节点就是对应的节点。
- 上图的箭头就是指这个区域的哈希值都是访问该节点。
因为是拿客户端 IP 作为哈希取模的条件,这样就能确保同一个客户端的所有请求都会被分发到同一台服务器,这样就能很好的解决上述说的session问题了。
但哈希环在使用过程中还会有一个问题,就是每台服务器经过哈希取模后,得到的哈希值非常接近就像下图,这样的话所有的请求大概率都会落到服务器A中,最终导致 A 服务器承载了 90% 以上的访问压力。

如果服务器 IP 映射在哈希环上出现偏移,在大流量的冲击下,这种情况很容易导致整个集群崩塌,首先是A扛不住并发冲击,宕机下线,紧接着流量交给 B,B 也扛不住,接着宕机,然后 C…
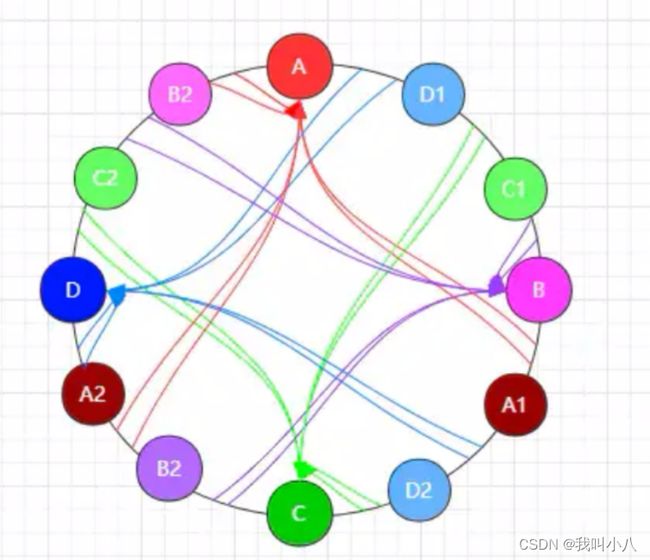
因此哈希环映射偏移问题可能会造成的一系列连锁反应,所以在一致性哈希算法中,为了确保整个集群的健壮性,提出了一种虚拟节点的概念来解决此问题。
虚拟节点其实本质上就是真实服务器节点的复制品,虚拟节点映射的 IP 都是指向于真实服务器的。看看下图所示,分别给ABCD做个虚拟节点,那这样的话就解决了流量都在服务器A上的问题了。

在一致性哈希算法的实际应用场景中,绝非只映射一个虚拟节点,往往会为一个真实节点映射数十个虚拟节点,以便于减小哈希环偏移所带来的影响。
同时,虚拟节点的数量越多,请求在分发时也能更均匀的分布,哈希环最终结构如下:
动态调度算法
上述分析的算法都属于静态算法,也就是说这些算法配置后,并不会根据线上的实际运行情况进行调整,只会根据已配置的规则进行请求分发。
那有时候分配流量是要根据实际情况的话,那就得用一些动态调度算法了。
最小活跃数算法
最小活跃数算法则会根据线上的实际情况进行分发,能够灵活的检测出集群中各个节点的状态,能够自动寻找并调用活跃度最低的节点处理请求。
现在每个服务都有对应的活跃数,初始情况下,所有服务的活跃数均为0。每进来一个请求,都把它分发给活跃数最低的服务,服务每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务能够优先获取到新的请求、这就是最小活跃数负载均衡算法的基本思想。
一般情况下此算法都会结合权重算法来做,当活跃数一致时就用权重来分配,显著的例子就是Dubbo的处理:
- 先从注册中心中拉取所有的服务实例,然后找出活跃数最小的节点。
- 如果只有一个,那么则直接返回对应的实例节点处理本次请求。
- 如果存在多个,则根据每个节点配置的权重值来决定本次处理请求的具体节点。
- 如果权重值不同,优先选取权重值最大的实例,作为处理本次请求的节点。
- 如果存在相同的最大权重值,那么则通过随机的方式选择一个节点提供服务。
从最小活跃数算法特性不难得知,该算法带来的优势极为明显,永远都能选取节点列表中最空闲的那台服务器处理请求,从而避免某些负载过高的节点,还依旧承担需要承担新的流量访问,造成更大的压力。
最优响应算法
与前面分析的最小活跃数算法一样,最优响应算法也是一种动态算法,但它比最小活跃数算法更加智能,因为最小活跃数算法中,如果一台节点存在故障,导致它自身处理的请求数比较少,那么它会遭受最大的访问压力,这显然是并不合理的。
最小活跃数算法就类似于平时的搬砖工作,谁事情做的最少谁留下来加班,在正常情况下,这种算法都能够找到“摸鱼”最厉害的员工留下来加班。
但如果有一天,某个员工由于身体出问题了,导致自己做的工作量比较少,但按照这种算法的逻辑,依旧会判定为该员工今天最闲,所以留下来加班。
从上述这个案例中,大家略微能够感受出来最小活跃数算法的不合理性。而最优响应算法则更加智能,该算法在开始前,会对服务列表中的各节点发出一个探测请求(例如 Ping 或心跳包检测),然后根据各节点的响应时间来决定由哪台服务器处理客户端请求,该算法能较好根据节点列表中每台机器的当前运行状态分发请求。
总结
在本文中,对于比较常用的负载均衡的算法进行了剖析,可以看到越智能的调度算法,进行节点选择时的开销会更大,所以并非越智能的算法越好,越是并发高、流量大的场景下,反而选用最基本的算法更合适,例如微信的红包业务,就是采用最基本的轮询算法进行集群调度。
因此在面临巨大访问压力的情景中,选择最简单的算法反而带来的收益更高,但前提是需要集群中所有的节点硬件配置都一致,所有节点分配的资源都相同,轮询算法则是最佳的调度算法。