sheng的学习笔记-Zookeeper框架原理
目录
ZK介绍和搭建
zk基础知识
znode-常用命令
znode-数据结构
zk中znode的结构:
zk中节点znode类型-持久节点和持久序号节点
临时节点用于服务发现原理图
ZK客户端Curator:
Curator介绍:
maven配置pom.xml文件
ZK持久化机制
快照数据
事务日志
数据相关过程
初始化
数据同步
小结:
ZK权限
权限设置:
ZK锁
zk锁的类型:
ZooKeeper分布式锁的原理
(一) ZooKeeper的每一个节点,都是一个天然的顺序发号器。
(二) ZooKeeper节点的递增有序性,可以确保锁的公平
(三)ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效
(四)ZooKeeper的节点监听机制,能避免羊群效应
图解:分布式锁的抢占过程
客户端A发起一个加锁请求
客户端B过来排队
客户端B开启监听客户端A
客户端B抢锁成功
分布式锁的基本思路
curator代码
对比ZooKeeper分布式锁和redis锁:
ZK的watch机制
ZK集群
ZK集群搭建
创建myid文件
修改zoo.cfg文件
启动服务
客户端连接
ZK集群原理
ZK服务器节点(非znode)分为3种角色:
ZBA协议
选举leader过程:
选票数据格式:
选举流程简介:
选举规则:
运行过程中检测主节点宕机
选举流程代码解析
ZK中NIO和BIO应用:
-
ZK介绍和搭建
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。
ZK官网:
Welcome to The Apache Software Foundation!
下载后可以看到bin和conf目录,下载目录如下(注意,要下bin文件,如果下载源码,运行会报错):

在conf中有zoo_sample.cfg,这是示例配置,拷贝出一个zoo.cfg(程序默认的配置文件),文件和内容如下:

# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper #此处改为自己的路径
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
配置文件简单解析
1.tickTime:这个时间是作为 zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2.dataDir:顾名思义就是 zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
3.clientPort:这个端口就是客户端连接 zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
然后运行bin/zkServer.cmd (这是windows的,如果是linux,运行zkServer.sh),双击或者在bash中运行都行


服务和端口都起来了,用客户端连接一下

zk基础知识
znode-常用命令
[zk: localhost:2181(CONNECTED) 0] ls / //查看节点
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /test1 // 创建节点
Created /test1
[zk: localhost:2181(CONNECTED) 2] ls /
[test1, zookeeper]
[zk: localhost:2181(CONNECTED) 3] create /test1/sub1 // 创建子节点
Created /test1/sub1
[zk: localhost:2181(CONNECTED) 4] ls /
[test1, zookeeper]
[zk: localhost:2181(CONNECTED) 5] create /test2 abc // 创建节点,并放入数据
Created /test2
[zk: localhost:2181(CONNECTED) 6] get /test2 // 获取节点数据
abc[zk: localhost:2181(CONNECTED) 29] create /test1/sub1/sub2
Created /test1/sub1/sub2
[zk: localhost:2181(CONNECTED) 30] ls -R /test1 //-R参数递归查询,看到所有子节点
/test1
/test1/sub1
/test1/sub1/sub2[zk: localhost:2181(CONNECTED) 33] delete /test1 //删除节点,但节点内有子节点,删除失败
Node not empty: /test1
[zk: localhost:2181(CONNECTED) 34] deleteall /test1 // 删除节点和其内子节点
[zk: localhost:2181(CONNECTED) 35] ls /test2
[]
[zk: localhost:2181(CONNECTED) 36] delete -v 1 /test2 //根据版本号删除节点,版本号错误删除失败,目前版本号是0,乐观锁删除,用于高并发
version No is not valid : /test2
[zk: localhost:2181(CONNECTED) 37] get -s /test2
abc
cZxid = 0x12
ctime = Thu Jan 27 18:13:11 CST 2022
mZxid = 0x12
mtime = Thu Jan 27 18:13:11 CST 2022
pZxid = 0x12
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0[zk: localhost:2181(CONNECTED) 38] set /test2 aaa //设置节点数据为aaa
[zk: localhost:2181(CONNECTED) 42] get -s /test2
aaa
cZxid = 0x12
ctime = Thu Jan 27 18:13:11 CST 2022
mZxid = 0x1f
mtime = Thu Jan 27 20:54:39 CST 2022
pZxid = 0x12
cversion = 0
dataVersion = 1 //此处版本号变为1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0
[zk: localhost:2181(CONNECTED) 7] get -s /test2 // 获取节点详细信息
abc
cZxid = 0x12 //节点创建时的zxid.
ctime = Thu Jan 27 18:13:11 CST 2022 //节点创建时的时间戳
mZxid = 0x12 //节点最新一次更新发生时的zxid
mtime = Thu Jan 27 18:13:11 CST 2022 //节点最新一次更新发生时的时间戳
pZxid = 0x12
cversion = 0 // 其子节点的更新次数
dataVersion = 0 //节点数据的更新次数
aclVersion = 0 // 节点ACL(授权信息)的更新次数
ephemeralOwner = 0x0 // 如果该节点为ephemeral节点, ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是ephemeral节点, ephemeralOwner值为0
dataLength = 3 // 节点数据的字节数
numChildren = 0 //子节点个数
znode-数据结构
ZK中数据是保存在节点中,节点是znode,多个znode组成一个树的目录结构,如下图
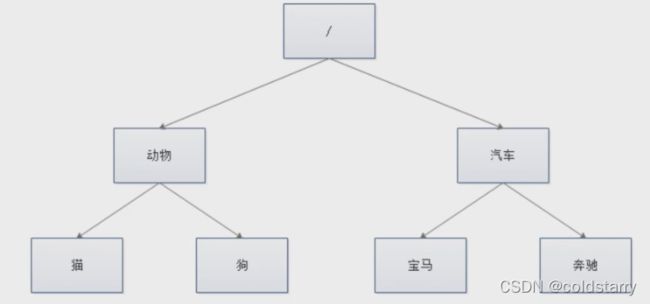
不同于树的节点,znode的饮用方式是路径引用,类似文件路径:
/动物/猫
/汽车/宝马
zk中znode的结构:
data:保存数据
acl:权限,定义了什么样的用户能够操作这个节点,且能够进行怎样的操作
- CREATE(r):创建子节点的权限
- DELETE(d):删除节点的权限
- READ(r):读取节点数据的权限
- WRITE(w):修改节点数据的权限
- ADMIN(a):设置子节点权限的权限
stat:描述当前znode的元数据
child:当前节点的子节点
具体实现:

- DataTree 中 nodes 是 Map,表示所有的 ZK 节点,那其内部 key 是:ZNode 的唯一标识
path作为 key - ephemerals 是Map,用于存储临时节点,临时节点是跟 Session 绑定的,sessionId 作为 key
zk中节点znode类型-持久节点和持久序号节点
[zk: localhost:2181(CONNECTED) 8] create /test3 // 默认是持久节点
Created /test3
[zk: localhost:2181(CONNECTED) 9] create /test3 //创建同名持久节点报错
Node already exists: /test3
[zk: localhost:2181(CONNECTED) 10] create -s /test3 //持久顺序节点
Created /test30000000003
[zk: localhost:2181(CONNECTED) 11] ls /
[test1, test2, test3, test30000000003, zookeeper]
[zk: localhost:2181(CONNECTED) 12] create -s /test3
Created /test30000000004
[zk: localhost:2181(CONNECTED) 13] ls /
[test1, test2, test3, test30000000003, test30000000004, zookeeper]
[zk: localhost:2181(CONNECTED) 14] create -e /test5 //创建临时节点,关闭当前会话,重新开个会话,节点就没了
Created /test5
[zk: localhost:2181(CONNECTED) 15] ls /
[test1, test2, test3, test30000000003, test30000000004, test5, zookeeper][zk: localhost:2181(CONNECTED) 26] create -e -s /test6 //创建临时序号节点
Created /test60000000006
[zk: localhost:2181(CONNECTED) 27] ls /
[test1, test2, test3, test30000000003, test30000000004, test60000000006, zookeep
er]


- 持久节点(PERSISTENT):session断联、服务端重启还在;可以创建子节点,子节点可以临时也可以持久;不能同名
- 持久顺序节点(PERSISTENT_SEQUENTIAL):session断联、服务端重启还在;可以创建子节点,子节点可以临时也可以持久;同名节点会在后面添加上序号,根据先后顺序,会在节点后带一个数值,越后执行数值越大,适用于分布式的应用场景,单调递增
- 临时节点(EPHEMERAL) :session链接断开后自动删除,通过这个特性,zk可以实现服务注册和发现的效果;不能创建子节点;不能同名
- 临时顺序节点(EPHEMERAL_SEQUENTIAL) :session链接断开就没了;不能创建子节点;同名节点会在后面添加上序号,适用于临时的分布式锁
- Container节点(3.5.3版本后增加):容器节点,当容器没有任何子节点,会被zk定期删除(默认60s),容器节点用于存放子节点
- TTL节点:可以指定节点到期时间,到期后被zk定时删除
临时节点用于服务发现原理图
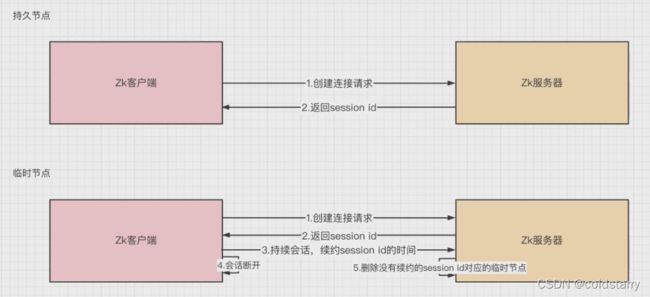
如果是临时节点,zk服务器的session id在持续会话时,会延迟消亡时间,在一段时间没有会话后,会自动删除session id对应的临时节点
ZK客户端Curator:
Curator介绍:
Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。
官网:Apache Curator – https://curator.apache.org/
https://curator.apache.org/
maven配置pom.xml文件
4.0.0 org.example zookeeper-app 1.0-SNAPSHOT 16 16 2.12.0 org.apache.curator curator-client ${curator.version} org.apache.curator curator-framework ${curator.version} org.apache.curator curator-recipes ${curator.version} org.apache.curator curator-test ${curator.version} org.apache.curator curator-x-discovery ${curator.version} org.apache.curator curator-x-discovery-server ${curator.version} org.apache.zookeeper zookeeper 3.4.6 com.sun.jmx jmxri com.sun.jdmk jmxtools javax.jms jms junit junit org.slf4j slf4j-log4j12 org.slf4j slf4j-api 1.7.6 org.slf4j slf4j-simple 1.7.25 compile
curator示例代码
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.junit.Before;
import org.junit.Test;
import java.nio.charset.StandardCharsets;
public class ZKClientCuratorTest {
CuratorFramework client;
@Before
public void init(){
System.out.println("call init function");
// 重试策略:重试之间等待的初始时间,最大的重试次数
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// 通过工厂建造出连接实例:client
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("localhost:2181")
.sessionTimeoutMs(5000) // 会话超时时间
.connectionTimeoutMs(5000) // 连接超时时间
.retryPolicy(retryPolicy)
.namespace("base") // 包含隔离名称
.build();
client = curatorFramework;
// 客户端必须开始
curatorFramework.start();
}
// 创建节点
@Test
public void testCreateMode() throws Exception {
client.create().creatingParentContainersIfNeeded() // 递归创建所需父节点
.withMode(CreateMode.PERSISTENT_SEQUENTIAL) // 创建类型为持久序号节点,避免重复运行时报错
.forPath("/nodeA/sub1", "init".getBytes()); // 目录及内容
//添加持久节点
String path = client.create().forPath("/create-for-path-curator-node");
// 添加持久序号节点
String path1 = client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/create-EPHEMERAL_SEQUENTIAL-curator-node",
"some-data".getBytes(StandardCharsets.UTF_8));
System.out.println("持久节点:" + path);
System.out.println("添加持久序号节点:" + path1);
}
//查询节点
@Test
public void testSetAndGetData() throws Exception {
// 设置数据
client.setData().forPath("/create-for-path-curator-node","changed".getBytes(StandardCharsets.UTF_8));
//查询数据
byte[] bytes = client.getData().forPath("/create-for-path-curator-node");
System.out.println("获取/create-for-path-curator-node节点信息:" + new String(bytes));
}
@Test
public void testDeleteData() throws Exception {
// 如果有子节点,一并删除
client.delete().guaranteed().deletingChildrenIfNeeded().forPath("/nodeA");
}
}
上述每运行一个方法就去zk的客户端看下数据

ZK持久化机制
zk的数据是运行在内存中,提供两种持久化机制:
事务日志:zk把执行的命令以日志形式保存在dataLogDir指定的路径中的文件
数据快照:zk会定时将一定时间间隔内做一次内存数据的快照,并将内存数据保存在快照文件中
快照数据
快照数据生成的基本过程:
关键点:
- 异步:异步线程生成快照文件
- Fuzzy 快照:
- 快照文件生成过程中,仍然有新的事务提交,
- 因此,快照文件不是精确到某一时刻的快照文件,而是
模糊的, - 这就要求
事务操作是幂等的,否则产生不一致。
事务日志
关键点:
- 事务日志频繁 flush 到磁盘,消耗大量磁盘 IO
- 磁盘空间
预分配:事务日志剩余空间 < 4KB 时,将文件大小增加 64 MB 磁盘预分配的目标:减少磁盘 seek 次数

事务序列化:本质是生成一个字节数组
- 包含:事务头、事务体的序列化
- 事务体:会话创建事务、节点创建事务、节点删除事务、节点数据更新事务
日志截断:
- 现象:Learner 的机器上记录的 zxid 比 Leader 机器上的 zxid 大,这是非法状态;
- 原则:只要集群中存在 Leader,所有机器都必须与 Leader 的数据保持同步
- 处理细节:遇到非法状态,Leader 发送 TRUNC 命令给特定机器,要求进行日志截断,Learner 机器收到命令,会删除非法的事务日志
数据相关过程
初始化
ZK 服务器启动时,首先会进行数据初始化,将磁盘中数据,加载到内存中,恢复现场。
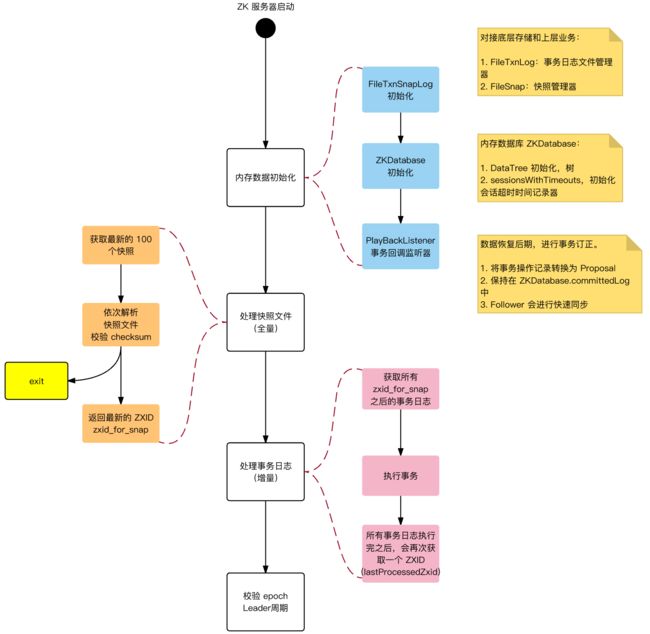
数据同步
ZK 集群服务器启动之后,会进行 2 个动作:
- 选举 Leader:分配角色
- Learner 向 Leader 服务器注册:数据同步
数据同步,本质:将没有在 Learner 上执行的事务,同步给 Learner

小结:
- 内存数据,是真正提供服务的数据
- 磁盘数据,作用:
- 恢复内存数据,恢复现场,先恢复快照文件中的数据到内存,再用日志文件中的数据做增量恢复,这样恢复速度更快
- 数据同步:集群内,不同节点间的数据同步(另,内存中的提议缓存队列 proposals)
- 磁盘数据,为什么同时包含:快照、事务日志?出于数据粒度的考虑
- 如果只包含快照,那恢复现场的时候,会有数据丢失,因为生成快照的时间间隔太大,即,快照的粒度太粗了
- 事务日志,针对每条提交的事务都会 flush 到磁盘,因此粒度很细,恢复现场时,能够恢复到事务粒度上
ZK权限
权限设置:
设置当前会话的账号和密码:
[zk: localhost:2181(CONNECTED) 45] addauth digest user:123456 //创建权限的用户名和密码,user是用户名,密码是123456
[zk: localhost:2181(CONNECTED) 46] create /test-node abcd auth:user:123456:cdwra //创建一个节点,必须是用户user好额密码123456的人,拥有权限:cdwra(权限值看上面znode节点介绍)Created /test-node
[zk: localhost:2181(CONNECTED) 47] ls /test-node
[]新开一个客户端,用以下命令测试
[zk: localhost:2181(CONNECTED) 0] ls /test-node //此处没有权限,报错
Insufficient permission : /test-node
[zk: localhost:2181(CONNECTED) 1] get /test-node //此处没有权限,报错
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth f
or /test-node
[zk: localhost:2181(CONNECTED) 2] addauth digest user:123456 //添加本会话权限
[zk: localhost:2181(CONNECTED) 3] get /test-node //拥有权限后操作成功
abcd
ZK锁
在单体的应用开发场景中,涉及并发同步的时候,大家往往采用synchronized或者Lock的方式来解决多线程间的同步问题。但在分布式集群工作的开发场景中,那么就需要一种更加高级的锁机制,来处理种跨JVM进程之间的数据同步问题,这就是分布式锁。
zk锁的类型:
读锁:大家都可以读,想要上读锁的前提:之前的锁没有写锁
写锁:只有得到写锁的才能写,想要上写锁的前提是:之前没有任何锁(不能有读锁或者写锁)
ZooKeeper分布式锁的原理
(一) ZooKeeper的每一个节点,都是一个天然的顺序发号器。
在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面,会加上一个次序编号,而这个生成的次序编号,是上一个生成的次序编号加一。
例如,有一个用于发号的节点“/test/lock”为父亲节点,可以在这个父节点下面创建相同前缀的临时顺序子节点,假定相同的前缀为“/test/lock/seq-”。第一个创建的子节点基本上应该为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推

Zookeeper临时顺序节点的天然的发号器作用
(二) ZooKeeper节点的递增有序性,可以确保锁的公平
一个ZooKeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程,都在这个节点下创建个临时顺序节点。由于ZK节点,是按照创建的次序,依次递增的。
为了确保公平,可以简单的规定:编号最小的那个节点,表示获得了锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
(三)ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效
每个线程抢占锁之前,先尝试创建自己的ZNode。同样,释放锁的时候,就需要删除创建的Znode。创建成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode
的通知就可以了。前一个Znode删除的时候,会触发Znode事件,当前节点能监听到删除事件,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
ZooKeeper的节点监听机制,能够非常完美地实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的Znode节点,只需要监听(linsten)或者监视(watch)排号在自己前面那个,而且紧挨在自己前面的那个节点,就能收到其删除事件了。
只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,自己就获得锁。
另外,ZooKeeper的内部优越的机制,能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用Znode锁的客户端与ZooKeeper集群服务器失去联系,这个临时Znode也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候,尽量创建临时znode
节点,
(四)ZooKeeper的节点监听机制,能避免羊群效应
ZooKeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
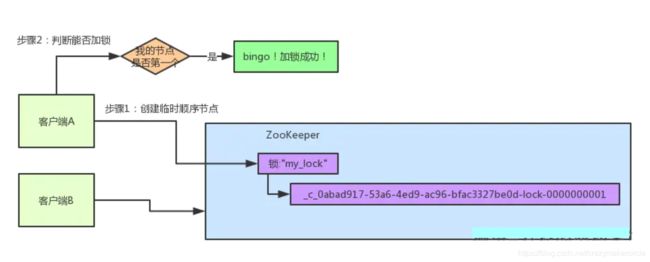
图解:分布式锁的抢占过程

咱们就假设客户端A抢先一步,对zk发起了加分布式锁的请求,这个加锁请求是用到了zk中的一个特殊的概念,叫做“临时顺序节点”。
简单来说,就是直接在"my_lock"这个锁节点下,创建一个顺序节点,这个顺序节点有zk内部自行维护的一个节点序号。
客户端A发起一个加锁请求
比如说,第一个客户端来搞一个顺序节点,zk内部会给起个名字叫做:xxx-000001。然后第二个客户端来搞一个顺序节点,zk可能会起个名字叫做:xxx-000002。大家注意一下,最后一个数字都是依次递增的,从1开始逐次递增。zk会维护这个顺序。
所以这个时候,假如说客户端A先发起请求,就会搞出来一个顺序节点,大家看下面的图,Curator框架大概会弄成如下的样子:

大家看,客户端A发起一个加锁请求,先会在你要加锁的node下搞一个临时顺序节点,这一大坨长长的名字都是Curator框架自己生成出来的。
然后,那个最后一个数字是"1"。大家注意一下,因为客户端A是第一个发起请求的,所以给他搞出来的顺序节点的序号是"1"。
接着客户端A创建完一个顺序节点。还没完,他会查一下"my_lock"这个锁节点下的所有子节点,并且这些子节点是按照序号排序的,这个时候他大概会拿到这么一个集合:

接着客户端A会走一个关键性的判断,就是说:唉!兄弟,这个集合里,我创建的那个顺序节点,是不是排在第一个啊?
如果是的话,那我就可以加锁了啊!因为明明我就是第一个来创建顺序节点的人,所以我就是第一个尝试加分布式锁的人啊!
bingo!加锁成功!大家看下面的图,再来直观的感受一下整个过程。
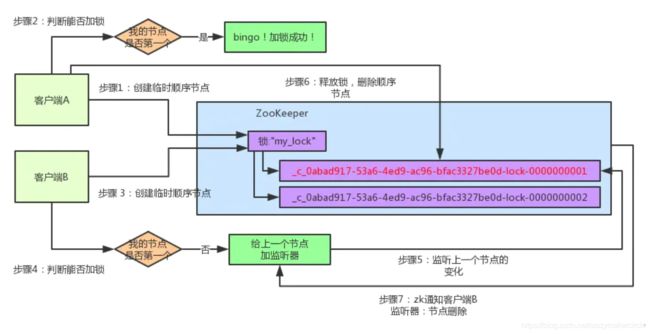
客户端B过来排队
接着假如说,客户端A都加完锁了,客户端B过来想要加锁了,这个时候他会干一样的事儿:先是在"my_lock"这个锁节点下创建一个临时顺序节点,此时名字会变成类似于:

 客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为"2"。
客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为"2"。
接着客户端B会走加锁判断逻辑,查询"my_lock"锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于:

同时检查自己创建的顺序节点,是不是集合中的第一个?
明显不是啊,此时第一个是客户端A创建的那个顺序节点,序号为"01"的那个。所以加锁失败!
客户端B开启监听客户端A
加锁失败了以后,客户端B就会通过ZK的API对他的顺序节点的上一个顺序节点加一个监听器。zk天然就可以实现对某个节点的监听。
如果大家还不知道zk的基本用法,可以百度查阅,非常的简单。客户端B的顺序节点是:
![]()
他的上一个顺序节点,不就是下面这个吗?
![]()
即客户端A创建的那个顺序节点!
所以,客户端B会对:
![]()
这个节点加一个监听器,监听这个节点是否被删除等变化!大家看下面的图。

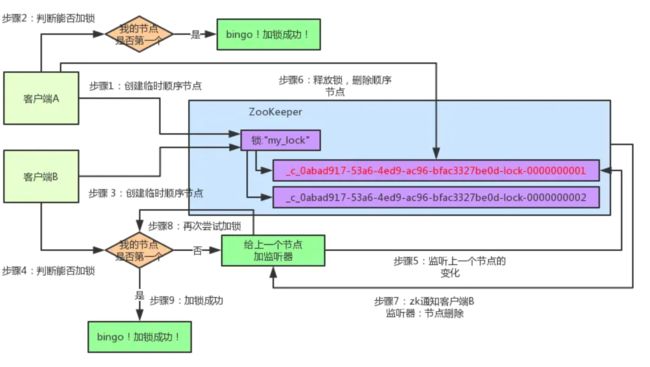
接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢?
其实很简单,就是把自己在zk里创建的那个顺序节点,也就是:

这个节点给删除。
删除了那个节点之后,zk会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。
此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。
客户端B抢锁成功
此时,就会通知客户端B重新尝试去获取锁,也就是获取"my_lock"节点下的子节点集合,此时为:

集合里此时只有客户端B创建的唯一的一个顺序节点了!
然后呢,客户端B判断自己居然是集合中的第一个顺序节点,bingo!可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。
分布式锁的基本思路
使用ZooKeeper实现分布式锁的算法,有以下几个要点:
- 一把分布式锁通常使用一个Znode节点表示;如果锁对应的Znode节点不存在,首先创建Znode节点。这里假设为“/test/lock”,代表了一把需要创建的分布式锁。
- 抢占锁的所有客户端,使用锁的Znode节点的子节点列表来表示;如果某个客户端需要占用锁,则在“/test/lock”下创建一个临时有序的子节点。这里,所有临时有序子节点,尽量共用一个有意义的子节点前缀。比如,如果子节点的前缀为“/test/lock/seq-”,则第一次抢锁对应的子节点为“/test/lock/seq-000000000”,第二次抢锁对应的子节点为“/test/lock/seq-000000001”,以此类推。再比如,如果子节点前缀为“/test/lock/”,则第一次抢锁对应的子节点为“/test/lock/000000000”,第二次抢锁对应的子节点为“/test/lock/000000001”,以此类推,也非常直观。
- 如果判定客户端是否占有锁呢?很简单,客户端创建子节点后,需要进行判断:自己创建的子节点,是否为当前子节点列表中序号最小的子节点。如果是,则认为加锁成功;如果不是,则监听前一个Znode子节点变更消息,等待前一个节点释放锁。
- 一旦队列中的后面的节点,获得前一个子节点变更通知,则开始进行判断,判断自己是否为当前子节点列表中序号最小的子节点,如果是,则认为加锁成功;如果不是,则持续监听,一直到获得锁。
- 获取锁后,开始处理业务流程。完成业务流程后,删除自己的对应的子节点,完成释放锁的工作,以方面后继节点能捕获到节点变更通知,获得分布式锁。
curator代码
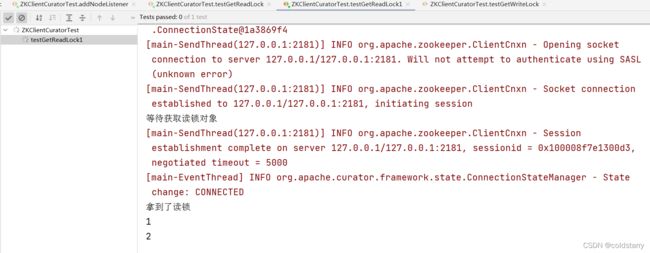
//读写锁
@Test
public void testGetReadLock() throws Exception{
//读写锁
InterProcessReadWriteLock interProcessReadWriteLock = new InterProcessReadWriteLock(client, "/lock1");
// 获取读锁对象
InterProcessLock interProcessLock = interProcessReadWriteLock.readLock();
System.out.println("等待获取读锁对象");
//获取锁
interProcessLock.acquire();
System.out.println("拿到了读锁");
for(int i = 1;i<=100;i++){
Thread.sleep(3000);
System.out.println(i);
}
interProcessLock.release();
System.out.println("等待释放锁");
}
@Test
public void testGetReadLock1() throws Exception{
testGetReadLock();
}
@Test
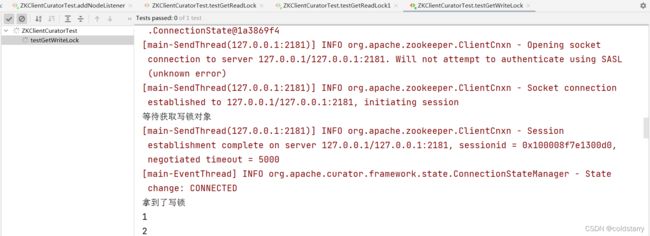
public void testGetWriteLock() throws Exception{
//读写锁
InterProcessReadWriteLock interProcessReadWriteLock = new InterProcessReadWriteLock(client, "/lock1");
// 获取读锁对象
InterProcessLock interProcessLock = interProcessReadWriteLock.writeLock();
System.out.println("等待获取写锁对象");
//获取锁
interProcessLock.acquire();
System.out.println("拿到了写锁");
for(int i = 1;i<=100;i++){
Thread.sleep(3000);
System.out.println(i);
}
interProcessLock.release();
System.out.println("等待释放锁");
}如果已经有读锁了,可以在别的方法获取读锁,但如果有读锁了不能获取写锁,先运行
testGetReadLock方法,获取读锁成功,再运行testGetReadLock1方法获取读锁成功,运行testGetWriteLock方法一直等待获取写锁,将两个读锁的进程关掉,才能获取到写锁

对比ZooKeeper分布式锁和redis锁:
- 优点:ZooKeeper分布式锁(如InterProcessMutex),能有效的解决分布式问题,不可重入问题,使用起来也较为简单。
- 缺点:ZooKeeper实现的分布式锁,性能并不太高。为啥呢?因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可用特性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。
在目前分布式锁实现方案中,比较成熟、主流的方案有两种:
(1)基于Redis的分布式锁
(2)基于ZooKeeper的分布式锁
两种锁,分别适用的场景为:
(1)基于ZooKeeper的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景;
(2)基于Redis的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。
ZK的watch机制
Watcher 监听机制是 Zookeeper 中非常重要的特性,我们基于 zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 zookeeper实现分布式锁、集群管理等功能。
watcher 特性:当数据发生变化的时候, zookeeper 会产生一个 watcher 事件,并且会发送到客户端。但是客户端只会收到一次通知。如果后续这个节点再次发生变化,那么之前设置 watcher 的客户端不会再次收到消息。(watcher 是一次性的操作)。 可以通过循环监听去达到永久监听效果。
通过下面命令,在获取数据时监听节点,但监听一次后节点再有变化将无法收到通知,只能在收到触发后再次监听,才可以达到循环监听的效果,数据修改和删除节点的类型不一样
get -w /test1
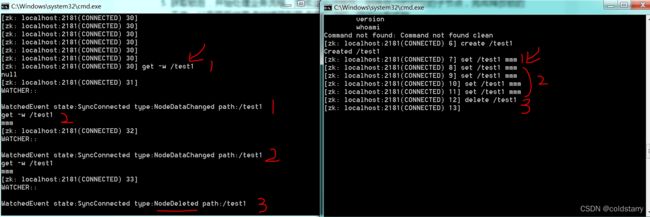
上图右边的图是修改节点,左边的图是监听,右边图尝试多次触发,单左边只收到了3次,在 一次监听回调后不再次监听就无法收到节点变化
curator代码如下
// watch监听器
@Test
public void addNodeListener() throws Exception {
NodeCache nodeCache = new NodeCache(client, "/curator-node");
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("node has been changed:" + "/curator-node");
byte[] bytes = client.getData().forPath("/curator-node");
System.out.println("node has been changed:" + new String(bytes));
}
});
nodeCache.start();
System.in.read();
}ZK集群
ZK集群搭建
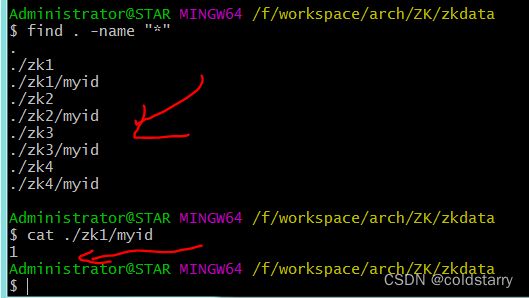
创建myid文件
在zookeeper的目录下创建4个目录

每个文件夹下创建一个myid文件,每个文件内容对应1个数字(应该有4个文件,内容分别是1,2,3,4不能重复)
修改zoo.cfg文件
将zoo.cfg复制为zoo1.cfg,并修改为下面红色字体部分
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=F:/workspace/arch/ZK/zkdata/zk1
# the port at which the clients will connect 给客户端连接用的端口,每个集群的服务节点应该不一样
clientPort=2182
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true#集群配置信息,数字要和上面的myid一致,2001那一列的端口是节点同步数据用的(主服务节点向从服务节点同步数据),3001那一列的端口用于选举leader
server.1=127.0.0.1:2001:3001
server.2=127.0.0.1:2002:3002
server.3=127.0.0.1:2003:3003
server.4=127.0.0.1:2004:3004:observer
按照上面的再复制和修改3个配置文件

启动服务
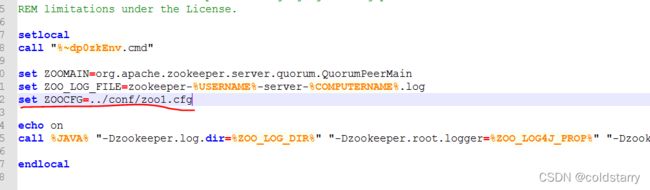
windows复制zkServer.cmd的文件,复制成4个开始命令文件,新增:set ZOOCFG=../conf/zoo1.cfg,每个命令文件对应一个配置,然后分别启动
cmd下启动多个zkServer都启动,四个zkServer没全启动的时候会报错误,这是zookeeper的Leader选举算法的异常信息,当节点没有启动完毕的时候,Leader无法正常进行工作,这种错误信息是可以忽略的,等其他节点启动之后就正常了。

linux用命令:./zkServer.sh start ../conf/zoo1.cfg后台启动(windows可以通过bash启动)
用命令:./zkServer.sh status ../conf/zoo1.cfg 看下状态,可以看到,1主2从1个observer
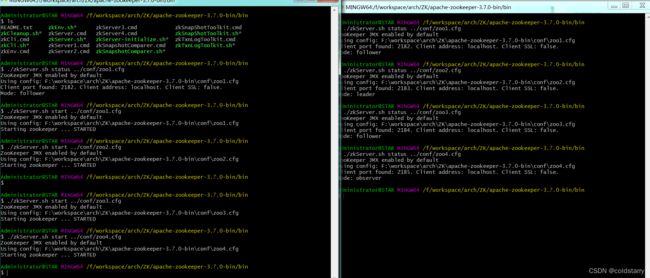
客户端连接
windows兄弟要么写代码连接吧,没找到cli.cmd的修改方法,脚本使用的是默认2181端口,如果在bash中用sh的方式连接服务端,客户端能启动成功,但无法执行命令,会卡死

linux的命令:
./zkcli.sh -server localhost:2182,localhost:2183,localhost:2184,localhost:2185
将集群服务器IP和端口都写上,这样在服务端一个机器挂了的话客户端会尝试连接另外一台
客户端代码连接集群服务器和测试代码如下:
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.NodeCache;
import org.apache.curator.framework.recipes.cache.NodeCacheListener;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.junit.Before;
import org.junit.Test;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class ZKClusterClientCuratorTest {
CuratorFramework client;
public void init() {
System.out.println("call init function");
// 重试策略:重试之间等待的初始时间,最大的重试次数
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// 通过工厂建造出连接实例:client
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("localhost:2182,localhost:2183,localhost:2184,localhost:2185")
.sessionTimeoutMs(5000) // 会话超时时间
.connectionTimeoutMs(5000) // 连接超时时间
.retryPolicy(retryPolicy)
.build();
client = curatorFramework;
// 客户端必须开始
curatorFramework.start();
}
public void test() {
while (true) {
try {
System.out.println("输入命令:");
Scanner input = new Scanner(System.in);
String str = input.nextLine();
System.out.println("输入命令:" + str);
String command = null;
if (str.startsWith("create")) {
command = str.substring("create".length()).trim();
System.out.println("创建命令:" + command);
client.create().creatingParentContainersIfNeeded()
.withMode(CreateMode.PERSISTENT_SEQUENTIAL)
.forPath(command);
} else if (str.startsWith("ls")) {
command = str.substring("ls".length()).trim();
System.out.println("ls命令:" + command);
System.out.println(client.getChildren().forPath(command));
}
} catch (Exception e) {
System.out.println("报错了," + e);
}
}
}
public static void main(String[] args) {
ZKClusterClientCuratorTest zk = new ZKClusterClientCuratorTest();
zk.init();
zk.test();
}
}
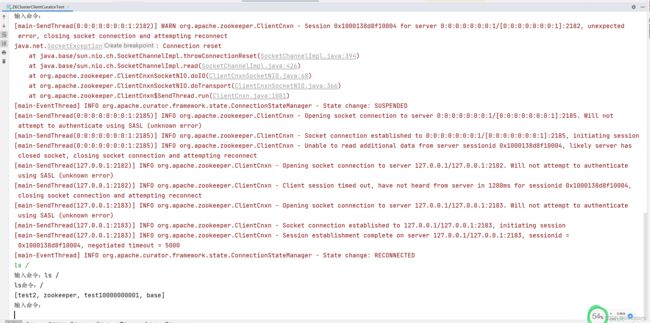
干掉了leader,客户端可以自动重新连接,正常查询节点信息

ZK集群原理
ZK服务器节点(非znode)分为3种角色:
- leader:处理集群的所有事务请求,集群中只有一个leader
- follow:只能处理读请求,参与leader选举
- observer:只能处理读请求,提升集群读性能,但不参与leader选举

ZBA协议
ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议),Zookeeper 是一个为分布式应用提供高效且可靠的分布式协调服务,ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持保证数据一致性的协议,主要解决了 崩溃恢复 和主从数据同步的问题
Zab 节点有三种状态:
- Following:当前节点是跟随者,服从 Leader 节点的命令。
- Leading:当前节点是 Leader,负责协调事务。
- Election/Looking:节点处于选举状态,正在寻找 Leader。
- Observing:观察者节点所在的状态
流程:
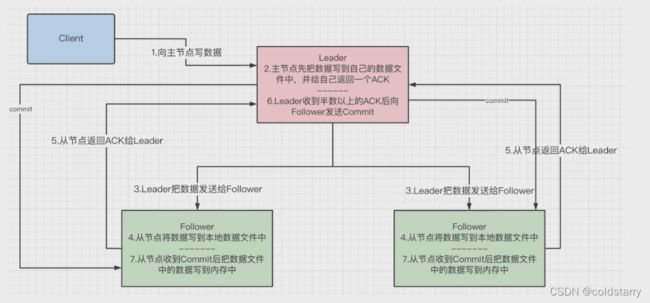
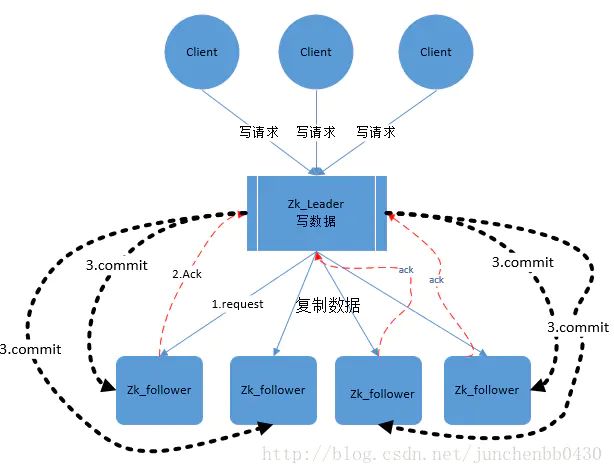
Zookeeper 客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交。
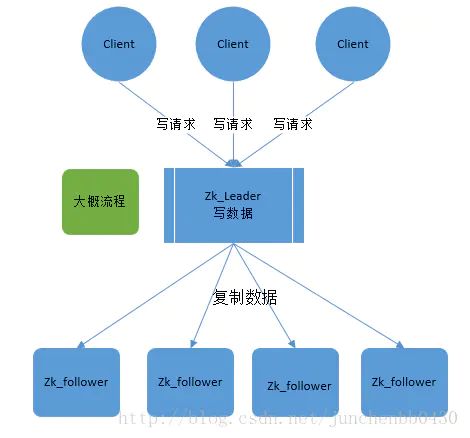
- 客户端发起一个写操作请求。
- Leader 服务器将客户端的请求转化为事务 Proposal 提案,同时为每个 Proposal 分配一个全局的ID,即zxid,写入leader的数据文件中,并给自己返回一个ack。
- Leader 服务器为每个 Follower 服务器分配一个单独的队列,然后将需要广播的 Proposal 依次放到队列中取,并且根据 FIFO 策略进行消息发送。
- Follower 接收到 Proposal 后,会首先将其以事务日志的方式写入本地磁盘中(此时没有加载到follower的内存中,如果客户端来查询,是无法查到数据的)
- 写入成功后向 Leader 反馈一个 Ack 响应消息。
- Leader 接收到超过半数以上 Follower 的 Ack 响应消息后(此处的半数算leader,比如1主2从,如果leader和一个follower成功后就认为成功,如果不算leader就需要两个follower都成功后才可以发送commit),即认为消息发送成功,可以发送 commit 消息。
- Leader 向所有 Follower 广播 commit 消息,同时自身也会完成事务提交。Follower 接收到 commit 消息后,会将上一条事务提交,从数据文件加载到内存中,此时客户端可以在follower中查到数据。
zookeeper 采用 Zab 协议的核心,就是只要有一台服务器提交了 Proposal,就要确保所有的服务器最终都能正确提交 Proposal。这也是 CAP/BASE 实现最终一致性的一个体现。
Leader 服务器与每一个 Follower 服务器之间都维护了一个单独的 FIFO 消息队列进行收发消息,使用队列消息可以做到异步解耦。 Leader 和 Follower 之间只需要往队列中发消息即可。如果使用同步的方式会引起阻塞,性能要下降很多。

选举leader过程:
选票数据格式:
服务器ID(myid):比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大。
数据ID(zxid):服务器中存放的最大数据ID,只要在ZK中做了节点的增删改(没有查),事务ID就会增加。值越大说明数据越新,在选举算法中数据越新权重越大。zxid是一个64位的数字。其中低32位可以看成一个简单的单增计数器,针对客户端每一个事务请求,Leader 在产生新的 Proposal 事务时,都会对该计数器加1。而高32位则代表了 Leader 周期的 epoch 编号。
epoch 编号可以理解为当前集群所处的年代,或者周期。每次Leader变更之后都会在 epoch 的基础上加1,这样旧的 Leader 崩溃恢复之后,其他Follower 也不会听它的了,因为 Follower 只服从epoch最高的 Leader 命令。
每当选举产生一个新的 Leader ,就会从这个 Leader 服务器上取出本地事务日志充最大编号 Proposal 的 zxid,并从 zxid 中解析得到对应的 epoch 编号,然后再对其加1,之后该编号就作为新的 epoch 值,并将低32位数字归零,由0开始重新生成zxid。
Zab 协议通过 epoch 编号来区分 Leader 变化周期,能够有效避免不同的 Leader 错误的使用了相同的 zxid 编号提出了不一样的 Proposal 的异常情况。
选举流程简介:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING,进行了下图的第二轮投票。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
最终Leader是服务器3,状态为LEADING;其余服务器是Follower,状态为FOLLOWING。

每个节点的选举流程图

选举规则:
- 选举原则:比较每个节点的(zxid,myid),在当选节点的票数>总节点数/2(该原则可以避免zk集群的脑裂问题),zxid大者当选,若zxid相同再比较myid,myid大者当选;若当前已发生投票节点数未过半,则继续等待投票
- zk保证CAP中的CP,不保证可用性(A):因为在zk集群选举过程中不对外提供服务
- zk可以保证数据不丢失:因为在选举过程中zxid较大的节点会当选leader,zxid越大代表数据越新(但这种保证是不严格的:启动阶段zxid相同,但运行阶段zxid相对较大的位于中间的节点会当选,zxid最大但位于最后的节点反而不当选)
- 选举需满足【当选节点的票数>总节点数/2】,故这种情况选举不出leader:整个集群中过半的节点挂掉了,此时永远不满足【当选节点的票数>总节点数/2】
- 集群总节点数一般设为基数【2N+1】,目的有两个:
- 出于成本考虑。当集群有5个节点时,最多挂掉2个节点,此时剩下3台,最大的当选节点票数为3>总节点数/2=5/2=2.5;当集群有6个节点,最多挂掉2个节点,此时剩下4台,最大当选票数为4>总节点数/2=6/2=3。所以5个节点和6个节点服务器的容错数都是一样的,但明显5台服务器成本更少。
- 防止脑裂。脑裂=一个集群由于网络故障分为两个集群,这两个集群又各自选选举出了自己的主节点,这样就有两个主节点了,原本只有一个主节点现在有了两个,类似于大脑裂开了两半;当考虑过半机制时,不管节点裂开成多少个集群,每个集群都需要超过总节点数的一半才能选主成功,这样自始至终都只有一个裂开后形成的集群能正常选主,其他裂开后形成的集群不能选主而不能正常工作
运行过程中检测主节点宕机
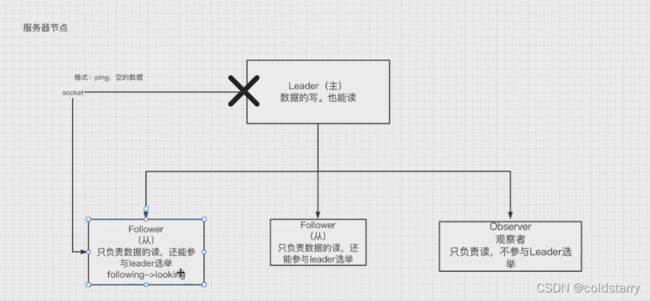
- 在运行过程中,leader会发socket连接到从节点,格式是ping的空数据,从节点周期获取ping信息
- 在leader挂了,socket的连接断开,从节点无法获取ping数据,报错
- 从节点从following状态编程looking状态,重新开始进行选举
- 在从节点选出leader后,原有的leader即便重新上线也只能做从节点,根据 zxid的epoch 编号机制达到目的
选举流程代码解析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap recvset = new HashMap();
HashMap outofelection = new HashMap();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
} ZK中NIO和BIO应用:
NIO:
- 用于被客户端连接的2181端口,使用的NIO模式与客户端建立连接
- 客户端开启watch时,使用NIO等待ZK的服务器回调
BIO
- 集群在选举时,多个节点之间的投票通信端口,使用BIO进行通讯
参考文章:
千锋最新Zookeeper集群教程-全网最全Zookeeper应用及原理分析课程_哔哩哔哩_bilibili
ZooKeeper 技术内幕:数据的存储(持久化机制)_varyall的专栏-CSDN博客_zookeeper持久化
Zookeeper 分布式锁 (图解+秒懂+史上最全) - 疯狂创客圈 - 博客园
Zookeeper leader选举机制_程序员-CSDN博客_zookeeper选举机制
Zab协议详解_脑壳疼-CSDN博客_zab协议
理解zookeeper选举机制 - min.jiang - 博客园