大数据_SLA,SLO,SLI 名词解读
参考 : SLI、SLO和SLA,一文彻底搞懂!!!_木给哇啦丶的博客-CSDN博客
前言
SLO和SLA是大家常见的两个名词:服务等级目标和服务等级协议。
云计算时代,各大云服务提供商都发布有自己服务的 SLA 条款,比如 Amazon 的 EC2 和 S3 服务都有相应的 SLA 条款。这些大公司的SLA看上去如此的高大上,一般是怎么定义出来的呢?本文就尝试从技术角度解剖一下 SLA 的制定过程。
说 SLA 不能不提SLO,这个是众所周知的,但是还有一个概念知道的人就不多了,那就是 SLI(Service Level Indicator),定义一个可执行的 SLA,好的 SLO 和 SLI 是必不可少的。
再有就是 SLI/SLO/SLA 都是和服务联系在一起的,脱离了服务这三个概念就没有什么意义了。
术语清单
SLA = Service Level Agreement = 服务质量/水平协议(对外承诺)
SLO = Service Level Objective = 服务质量/水平目标(对内产品目标)
SLI = Services Level Indicator = 服务质量/水平指标(对内产品服务质量评价指标)
Service 什么是服务?
简单说就是一切提供给客户的有用功能都可以称为服务。
服务一般会由服务提供者提供,提供这个有用功能的组织被称为服务提供者,通常是人加上软件,软件的运行需要计算资源,为了能对外提供有用的功能软件可能会有对其他软件系统的依赖。
客户是使用服务提供者提供的服务的人或公司。
SLI
SLI是经过仔细定义的测量指标,它根据不同系统特点确定要测量什么,SLI的确定是一个非常复杂的过程。
SLI的确定需要回答以下几个问题:
要测量的指标是什么?
测量时的系统状态?
如何汇总处理测量的指标?
测量指标能否准确描述服务质量?
测量指标的可靠度(trustworthy)?
1. 常见的测量指标有以下几个方面:
性能
- 响应时间(latency)
- 吞吐量(throughput)
- 请求量(qps)
- 实效性(freshness)
- 可用性
- 运行时间(uptime)
- 故障时间/频率
- 可靠性
质量
- 准确性(accuracy)
- 正确性(correctness)
- 完整性(completeness)
- 覆盖率(coverage)
- 相关性(relevance)
内部指标
- 队列长度(queue length)
- 内存占用(RAM usage)
因素人
- 响应时间(time to response)
- 修复时间(time to fix)
- 修复率(fraction fixed)
下面通过一个例子来说明一下:
hotmail 的 downtime SLI
错误率(error rate)计算的是服务返回给用户的error总数
如果错误率大于X%,就算是服务down了,开始计算downtime
如果错误率持续超过Y分钟,这个downtime就会被计算在内
间断性的小于Y分钟的downtime是不被计算在内的。
2. 测量时的系统状态,在什么情况下测量会严重影响测量的结果
测量异常(badly-formed)请求,还是失败(fail)请求还是超时请求(timeout)
测量时的系统负载(是否最大负载)
测量的发起位置,服务器端还是客户端
测量的时间窗口(仅工作日、还是一周7天、是否包括计划内的维护时间段)
3. 如何汇总处理测量的指标?
计算的时间区间是什么:是一个滚动时间窗口,还是简单的按照月份计算
使用平均值还是百分位值,比如:某服务X的ticket处理响应时间SLI的
测量指标:统计所有成功解决请求,从用户创建ticket到问题被解决的时间
怎么测量:用ticket自带的时间戳,统计所有用户创建的ticket
什么情况下的测量:只包括工作时间,不包含法定假日
用于SLI的数据指标:以一周为滑动窗口,95%分位的解决时间
4. 测量指标能否准确描述服务质量?
性能:时效性、是否有偏差
准确性:精度、覆盖率、数据稳定性
完整性:数据丢失、无效数据、异常(outlier)数据
5. 测量指标的可靠度
是否服务提供者和客户都认可
是否可被独立验证,比如三方机构
客户端还是服务器端测量,取样间隔
错误请求是如何计算的
SLO
SLO(服务等级目标)指定了服务所提供功能的一种期望状态。SLO里面应该包含什么呢?所有能够描述服务应该提供什么样功能的信息。
服务提供者用它来指定系统的预期状态;开发人员编写代码来实现;客户依赖于SLO进行商业判断。SLO里没有提到,如果目标达不到会怎么样。
SLO是用SLI来描述的,一般描述为:
比如以下SLO:
每分钟平均qps > 100k/s
99% 访问延迟 < 500ms
99% 每分钟带宽 > 200MB/s
设置SLO时的几个最佳实践:
指定计算的时间窗口
使用一致的时间窗口(XX小时滚动窗口、季度滚动窗口)
要有一个免责条款,比如:95%的时间要能够达到SLO
如果Service是第一次设置SLO,可以遵循以下原则
测量系统当前状态
设置预期(expectations),而不是保证(guarantees)
初期的SLO不适合作为服务质量的强化工具
改进SLO
设置更低的响应时间、更改的吞吐量等
保持一定的安全缓冲
内部用的SLO要高于对外宣称的SLO
不要超额完成
定期的downtime来使SLO不超额完成
设置SLO时的目标依赖于系统的不同状态(conditions),根据不同状态设置不同的SLO:总SLO = service1.SLO1 weight1 service2.SLO2 weight2 …
为什么要有SLO,设置SLO的好处是什么呢?
对于客户而言,是可预期的服务质量,可以简化客户端的系统设计
对于服务提供者而言
可预期的服务质量
更好的取舍成本/收益
更好的风险控制(当资源受限的时候)
故障时更快的反应,采取正确措施
SLO设好了,怎么保证能够达到目标呢?
需要一个控制系统来:
监控/测量SLIs
对比检测到的SLIs值是否达到目标
如果需要,修正目标或者修正系统以满足目标需要
实施目标的修改或者系统的修改
该控制系统需要重复的执行以上动作,以形成一个标准的反馈环路,不断的衡量和改进SLO/服务本身。
我们讨论了目标以及目标是怎么测量的,还讨论了控制机制来达到设置的目标,但是如果因为某些原因,设置的目标达不到该怎么办呢?
也许是因为大量的新增负载;也许是因为底层依赖不能达到标称的SLO而影响上次服务的SLO。这就需要SLA出场了。
SLA
SLA是一个涉及2方的合约,双方必须都要同意并遵守这个合约。当需要对外提供服务时,SLA是非常重要的一个服务质量信号,需要产品和法务部门的同时介入。
SLA用一个简单的公式来描述就是: SLA = SLO 后果
SLO不能满足的一系列动作,可以是部分不能达到
比如:达到响应时间SLO 未达到可用性SLO
对动作的具体实施
需要一个通用的货币来奖励/惩罚,比如:钱
SLA是一个很好的工具,可以用来帮助合理配置资源。一个有明确SLA的服务最理想的运行状态是:增加额外资源来改进系统所带来的收益小于把该资源投给其他服务所带来的收益。
一个简单的例子就是某服务可用性从99.9%提高到99.99%所需要的资源和带来的收益之比,是决定该服务是否应该提供4个9的重要依据。
案例:
首先,SLI 和 SLO 是 SRE 工程实践里非常核心的概念,但是在同时提到这些概念的时候,经常容易混淆。
说明一下,下图假设所讨论的 SLA 个数为 1,使用了软件工程中 ER 图的表达方式,但也有所变化。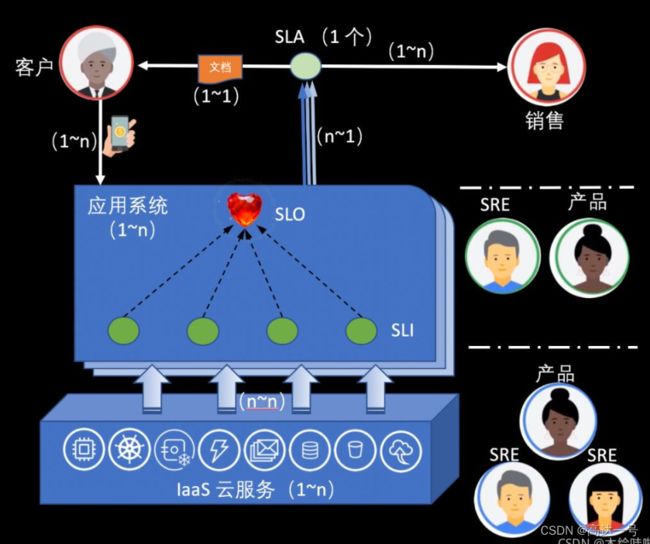
术语清单
SLA = Service Level Agreement = 服务质量/水平协议(对外承诺)
SLO = Service Level Objective = 服务质量/水平目标(对内产品目标)
SLI = Services Level Indicator = 服务质量/水平指标(对内产品服务质量评价指标)
人(用从上到下,从左到右的顺序)
客户 - 每 1 个客户在使用产品服务时,都显性或隐性的基于某 1 个 SLA,SLA 和客户之间是一种 1 对 1 的文档关系,这份协议文档就显性或者隐性的存在于系统中。客户使用 1 种,或者 n 种连接方式访问产品服务的 1 个或者 n 个应用系统。
销售 - SLA 本身是所销售产品服务的一部分,它规定了承诺给客户的产品功用和质量。基于 SLA,客户可以选择用付费或者免费的方式使用产品。1 个/份 SLA 的销售工作可以由 1 到 n 位销售完成。销售和客户都幻想着几乎完美的 SLA,这样代表企业利益的销售,以及产品的客户就都可以达到双赢的局面,皆大欢喜。
产品 - 通过与销售的间接互动,或者直接的客户调研,产品经理能够确定应用系统所应该具有的功能和发展方向。
SRE - SRE 和产品共同制定了每个 SLA 相关应用系统的 SLO,SLO 定量的定义了每 1 个应用系统所应该具备的服务质量,1 个应用系统的 SLO 被该产品服务的 SLO 文档定义,在该文档中 SLO 被映射到 1 个或者 n 个 SLI,每个 SLI 都需要用监控工具持续采集数据,通常它们的数值单位各不相同。所有 SLO 都是用百分比数值形式表达的,例如:99.99% 的成功率,90% 的请求延迟 < 400 毫秒等。SRE 和产品经理/专家还应该共同关注运行应用系统的基础设施层,确保基础设施的可用性和容量足以满足目标数量的用户访问,而且还要考虑和设计底层资源的容灾和跨区多活等复杂场景。
开发/运维 - 重要但暂不做讨论。
事(用从下往上的顺序)
IaaS 云服务 - 也可以是其它类型的可以供应用系统运行的环境。这里存在着 1 到 n 种子服务。它和上层的 n 个应用系统通常是 n 对 n 的关系。
应用系统 - 1 个到 n 个应用系统构成了 1 个产品服务(内含SLA),在和客户的互动中实现着产品服务的业务价值。
文档 - 以网页或者纸张的形式向用户描述了某个应用服务所提供的服务内容和质量信息。向用户提供这个文档并不是强制、显性和必须的。
结束语
结合你的实际工作场景,想象并描绘一下 SLA 、SLO 和 SLI 在你周围的人事物中关系网。在SRE 的工作实践中,定义 SLO,并梳理 SLI,将量化以后的目标和说明文档化,并让各个干系人认同并签署,是一项基础的起步工作。