《软件架构设计--大型网站技术架构与业务架构融合之道》读书笔记
1、缓冲IO和直接IO
应用程序内存:通常写代码malloc/free、new/delete等分配出来的内存
用户缓冲区:C语言FILE结构体里面的buffer
内核缓冲区:Linux操作系统的Page Cache。为了加快磁盘IO,Linux系统会把磁盘上的数据以Page(即内存页)为单位缓存在操作系统中的内存中,一个Page大小一般为4KB。
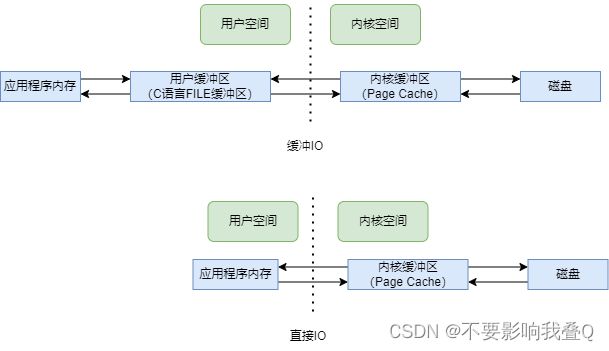
对于缓冲IO(C语言的库函数,如fopen、fread等),一个读操作会有3次数据拷贝,一个写操作会有反向的3次数据拷贝:
读:磁盘-->内核缓冲区-->用户缓冲区-->应用程序内存
写:应用程序内存-->用户缓冲区-->内核缓冲区-->磁盘
对于直接IO(Linux系统API,如open、read、write、pread等),一个读操作会有2次数据拷贝,一个写操作会有2次反向的数据拷贝
· 读:磁盘-->内核缓冲区-->应用程序内存
写:应用程序内存-->内核缓冲区-->磁盘
所谓的直接IO,其中直接的意思是指没有用户级的缓冲,但是操作系统本身的缓冲区还是有的。二者的对比如下图所示:
关于缓冲IO和直接IO,需要注意以下几点:
1)fflush和fsync的区别:fflush是缓冲IO的一个API,他只是把数据从用户缓冲区刷到内核缓冲区而已,fsync则是把数据从内核缓冲区刷到磁盘中。
这意味无论缓冲IO还是直接IO,如果在写数据之后不及时调用fsync,若系统断电,则最新的部分数据会丢失。
2、内存映射文件与零拷贝
相比较于直接IO,内存映射文件更进了一步。如下图所示,当用户空间不再有内存,直接拿应用程序的逻辑内存地址映射到Linux操作系统的内核缓冲区,应用程序虽然读写的是自己的内存(虚拟地址),但实际上读写的是内核缓冲区

数据拷贝次数从缓冲IO的3次,到直接IO的2次,再到内存映射文件,变成了1次 。
读:磁盘 ----> 内核缓冲区
写:内核缓冲区--->磁盘
零拷贝又是提升IO效率的另一个神器。当用户需要把文件中的数据发送到网络时,各个方案的实现手段如下:
实现方法1:利用直接IO,伪代码如下:
fd1 = 打开的文件描述符
fd2 = 打开的socket文件描述符
buffer = 应用程序内存
read(fd1,buffer....); //先把数据从文件中读取出来
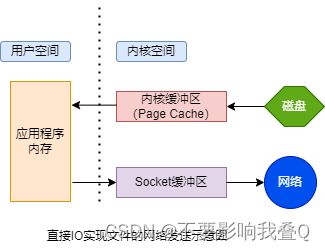
write(fd2,buffer...); //再通过网络发送出去如下图所示,整个过程有4次数据拷贝,读进来2次,写回去又是2次。
磁盘 --> 内核缓冲区 --> 应用程序内存 --> socket缓冲区 --> 网络
实现方法2:利用内存文件映射,伪代码如下:
fd1 = 打开的文件描述符
fd2 = 打开的socket文件描述符
buffer = 应用程序内存
mmap(fd1,buffer....); //先把磁盘数据映射到buffer上
write(fd2,buffer...); //再通过网络发送出去如下图所示,整个过程会有3次数据拷贝,不再经过应用程序内存,直接在内核空间中从内核缓冲区拷贝到socket缓冲区。

注意:这里要分清楚“映射”和“拷贝” 的区别。拷贝是把数据从一块内存拷贝到另一块内存中(即内存拷贝);映射只是持有了数据的一个引用(或者叫地址),数据本身只有一份。
实现方法3:利用零拷贝实现
但是如果使用零拷贝,可能连内核缓冲区到Socket缓冲区的拷贝也省略了。如下图所示,内核缓冲区和Socket缓冲区之间并没有做数据拷贝,只是一个地址的映射。底层网卡驱动程序要读取数据并发送到网络时,看似是从Socket缓冲区中读取数据,但实际上直接读的是内核缓冲区中的数据。
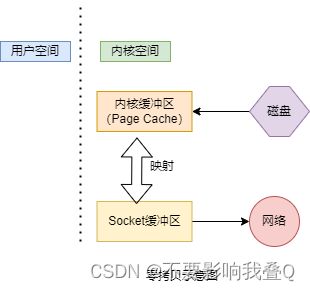
在此处,虽然叫零拷贝,实际上是2次数据拷贝:1次是从磁盘拷贝到内核缓冲区,1次是从内核缓冲区拷贝到网络,之所以叫零拷贝,是从内存的角度来看的:数据没有在内存之间发生拷贝,只在内存和IO之间进行传输。
最后总结一些,对于把文件数据发送到网络的这个场景,直接IO、内存映射文件、零拷贝对应的数据拷贝次数分别是4次、3次、2次,内存拷贝次数分别是2次、1次、0次。
在Linux系统中,零拷贝对应的系统API为sendFile。
2、网络IO模型
下面的同步和异步主要是在操作系统层面的,但实际上还有应用框架和业务层面的同步和异步,将会在后面补充说明
异步:读写由底层(操作系统或者框架)完成,读写完成之后,以某种方式通知应用程序。
阻塞和非阻塞是从函数调用角度来说的,而同步和异步则是从“读写是谁完成的”角度来区分的。
阻塞:如果读写没有完成或者读写没有就绪,则该函数需要一直等待。
非阻塞:函数立即返回,然后让应用程序去轮询。
同步:读写操作由应用程序去完成。
异步:读写由操作系统完成,完成之后,通过回调或者事件通知应用程序。
注意:IO多路复用(select、poll、epoll)都是同步IO,因为read、write函数操作都是由应用程序完成的,同时也是阻塞IO,因为select、read、write的调用都是阻塞的。
Reactor模式:主动模式,所谓主动,是指应用程序不断轮询,询问操作系统或者应用框架,IO是否就绪(如Linux下的select、poll、epoll就属于主动模式),需要应用程序中有一个循环一直轮询。在这种模式下,实际的IO操作还是由应用程序自己完成。
Proactor模式:被动模式,应用程序把read和write函数全部交给操作系统或者网络框架,实际的IO操作由网络或者框架完成,之后再回调应用程序提供的回调函数。如asio库就是典型的proactor模式。
悲观锁:认为数据发生并发冲突的概率很大,读之前就上锁
悲观锁:认为数据发生并发冲突的概率很小,所以读之前不上锁,等到写回去的时候再判断数据是否被其他事物修改了,即多线程里面的常讲的CAS比较并交换操作。
CAS的核心思想是:数据读出来的时候有一个版本V1,然后在内存里面修改。当写回去的时候,如果发现数据库种的版本不是V1(比V1大),说明在修改的期间内别的事物也在修改。则放弃更新,把数据读出来,重新计算逻辑,再重新写回去,如此不断地重试。
3、异步详解
“异步”一词在计算机世界里几乎无处不在。在操作系统和上层应用的语境中,异步IO的含义是有差异的。操作系统中的异步IO是一个狭义的概念(特指某些技术),上层应用中异步的指代则更为宽泛。
接口层面的异步:当客户端在调用的时候,是通过传入一个回调函数或者返回一个future对象来实现异步的。接口的异步有两种实现方式:
1)假异步:在接口内做一个线程池,把异步接口调用转化为同步接口调用;
2)真异步:在接口内部通过NIO(Java JDK层面的一个异步机制)实现真的异步,不需要开很多线程;
业务层面的异步:客户端通过HTPP、RPC或者消息中间件把请求传递给服务器。服务器收到请求后不立即处理,而是先落盘(存到数据库或者消息中间件或者磁盘),然后使用后台任务定时处理,让客户端通过另一个HTTP或者RPC接口轮询结果,或者服务器通过接口或消息主动通知客户端。
在接口层面、业务层面的异步可以通过同步接口,也可以通过异步接口;在底层IO的实现处,接口层的异步可能是通过同步方式实现的,也可能是异步方式实现的。
最后总结一下:站在客户端的角度来看异步,是请求服务器做一件事情,客户端不用等待结果返回就去做其他的事情,回头再进行轮询,或者让服务器调用回调函数进行通知;站在服务器的角度来看异步,是接收到一个客户的请求之后并不立即处理,也不立马返回结果,而是在“后台慢慢地处理”,稍后返回结果。因为客户端不等待上一个请求返回结果就可以发送下一个请求,从而源源不断地发送请求,就形成了异步。
需要说明的是,应用服务器和消息队列(又叫消息中间件)是内网通信,不会被阻塞。即使客户端并发量很大,最多导致消息堆积在消息队列里面。
4、隔离、熔断、限流和降级(微服务常提的概念)
隔离:是指将系统或者资源分隔开,在系统发生故障时能限定传播范围和影响范围,即发生故障后不会出现滚雪球效应,从而把故障的影响限定在一个范围内。隔离的手段有很多,不同业务场景下的做法多变,主要有以下几个手段。
1、数据隔离:从数据的重要性程度来说,一个公司的数据肯定有非常重要、次重要、不重要之分,在数据库的存储中,把这些数据所在的物理库彻底隔开。当然这也对应着业务的拆分和分库。从这个角度来看,业务的拆分和数据的隔离,其实是从不同角度说的同一个事情。
2、机器隔离(调用者隔离):对一个服务来说,有很多调用者,这些调用者也有一个重要性登机排序。对于那些最核心的几个调用者,可以为其专门准备一组机器,这样其他的调用者不会影响核心调用者的服务。成熟的RPC框架往往有隔离功能,根据调用方的标识(ID),把来自某个调用放的请求发送到一组固定的机器中,无需业务人员编写代码,用一个简单的饿配置即可搞定
3、线程池隔离:为每个RPC服务单独准备一个线程池(一般2到10个线程),而不是在一个大的线程池中让所有的RPC服务一起运行。当线程池重活没有空闲线程切线程池内部的队列已经满了的情况下,线程池直接抛出异常,拒绝新的请求,从而保证线程调用不会被阻塞。
4、信号量隔离:信号量在本质上是一个数字,它记录了当前访问某个资源的并发线程数。线程访问资源前获取该信号量,当访问结束,释放该信号量。一单信号量达到最大阈值,后发出请求的线程获取不到该信号量,会丢弃请求而不是则色等待信号量。信号量隔离比线程池隔离要轻一些。
限流:分为技术层面的限流和业务层面的限流。
1、技术层面的限流:一种是限制并发数,也就是根据系统的最大资源量进行限制,比如数据库连接池、线程池等;另一种是限制速度(QPS),如Nginx的limit_req模块。限制速率的这种方式对于服务的接口调用非常有用。即使有大量的请求进来,但超过QPS的请求接口会直接拒绝提供服务。虽然部分请求被拒绝了,但是不会影响其他服务的请求可以被正常处理,保证接口所在服务不会被压垮。
技术层面的限流比较通用,各种业务场景都能用得到;业务层面的限流需要根据具体的业务场景做开发。限流算法分为限制并发数的算法和限制速率的算法。限制并发数的计算原理很简单,系统只需要维护正在使用的资源数量或空闲数,如数据库的连接数,线程池的连接数。限制速率的算法稍微复杂,常用的有漏桶算法和令牌算法。令牌桶限制的是平均流入速率。;漏桶算法平滑了流入速率,起到了削峰的作用,有点类似与消息队列。
熔断:熔断有两种策略,根据请求失败率熔断和根据请求响应时间熔断。
1、根据请求失败率做熔断:对于客户端调用的某个服务,如果服务在短时间内大量超时或者抛错,则客户端直接开启熔断,也就是不再调用此服务。在经过一段时间后,再把熔断打开,如果还是不行,则继续开启熔断。这也是常提到的“快速失败”原则。
2、根据请求响应时间做熔断:当资源的平均响应时间超过阈值后,资源进入准降级状态。接下来如果持续进入5个请求且他们的RT持续超过阈值,那么接下来的时间窗口内,对该接口的调用都会自动地返回。
与限流对比可以发现:限流是服务端根据自己的能力上限设置一个过载保护,而熔断是调用端对自己做的一个保护,防止自己被其他响应速度慢的服务拖垮。能熔断的服务肯定不能是核心链路上的必选服务(如果是的话,服务超时或者宕机,前端应该是处于不能用的状态而不是熔断),所以说,熔断其实也是降级的一种方式。
降级:降级是一种兜底方案,是系统在出现故障之后尽力而为的一个措施。相比较于熔断、限流两更加偏向技术性的词汇,降级则是一个更加偏向业务的词汇。在现实中,虽然一个业务或者系统都有很多功能,但并不要求这些功能一定100%可用,或者完全不可用,其中存在着一个灰度空间。降级的设计思路是:尽最大的努力提供服务,哪怕是有损服务也要强于完全不服务。
降级不是一个纯粹技术手段,而是要根据具体业务场景具体分析,看看哪些功能可以降级,降级到什么程度,哪些宁愿不可用也不能降级。·
边界思维:“优雅的接口,龌龊的实现”可以说是边界思维最好的诠释。在技术领域,“封装”、“面向接口的编程”等技术也都是边界思维的体现。只要一个系统对外的接口是简洁的、优雅的,即使系统内部混乱,也不会影响到外界其他系统,相当于把混乱的逻辑约束到一个小范围,而不会扩散到所有系统。边界思维在不同层面的体现如下:
对象层面:单一职责原则
接口层面:首先考虑的不应该是如何实现,而是把系统当做一个黑盒,看系统对外提供的接口是什么。接口就是系统的边界,接口定义了系统可以支持什么、不可以支持什么。所以接口的设计往往比实现更重要!
产品层面:对于产品,常说的一句话就是内部实现很复杂,用户界面很简单。把复杂留给自己,把简单留给用户。