使用MAT分析OOM问题
OOM和内存泄漏在我们的工作中,算是相对比较容易出现的问题,一旦出现了这个问题,我们就需要对堆进行分析。
一般情况下,我们生产应用都会设置这样的JVM参数,以便在出现OOM时,可以dump出堆内存文件,也就是保留案发现场,方便我们后续的研究。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=.
至于分析堆内存的工具可以使用Jvisualvm,但Jvisualvm只能查看类使用内存的直方图,无法有效的追踪内存的引用关系,因此更加推荐使用Eclipse 的 Memory Analyzer(也叫做 MAT)做堆转储的分析。可以通过这个链接,下载 MAT。
使用MAT分析OOM问题,一般可以按照以下的思路进行:
- 通过支配树功能或直方图功能查看消耗内存最大的类型,来分析内存泄露的大概原因;
- 查看那些消耗内存最大的类型、详细的对象明细列表,以及它们的引用链,来定位内存泄露的具体点;
- 配合查看对象属性的功能,可以脱离源码看到对象的各种属性的值和依赖关系,帮助我们理清程序逻辑和参数;
- 辅助使用查看线程栈来看 OOM 问题是否和过多线程有关,甚至可以在线程栈看到 OOM 最后一刻出现异常的线程。
接下来,我们有一个案例,通过这个案例可以得到一个OOM后的堆转储文件java_pid12300.hprof,然后我们通过MAT的直方图、支配树、线程栈、OQL 等功能来分析此次 OOM 的原因。
在文章的最后会有代码地址,运行代码一段时间发生OOM后,你就可以得到一个hprof文件。
1、查看堆概述信息
通过MAT打开java_pid12300.hprof文件后,首先进入的是概览信息界面。
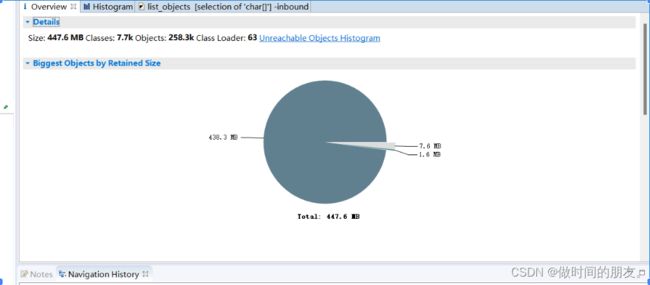
从这个概览图中,我们可以看出整个堆的大小是437.6MB。接下来我们可以通过直方图来看这437.6MB的对象都是哪些对象。
2、直方图观察对象分布
点击工具栏的第二个图标,进入到直方图视图

从直方图中,我们可以看到,char[]字节数组占用的内存最多,对象数量给也最多。排名第二的String对象也很多,可以推断程序可能是被String占满了(String底层使用的就是char[]作为实际存储,因此String多,char[]也会多)
3、分析char[]的引用关系
在 char[]上点击右键,选择 List objects->with incoming references,可以列出所有的char[]实例,以及每个 char[]的整个引用关系链:

随机展开一个 char[],如下图所示:

- 在①处看到,这些 char[]几乎都是 10000 个字符、占用 20000 字节左右(char 是 UTF-16,每一个字符占用 2 字节);
- 在②处看到,char[]被 String 的 value 字段引用,说明 char[]来自字符串;
- 在③处看到,String 被 ArrayList 的 elementData 字段引用,说明这些字符串加入了一个 ArrayList 中;
- 在④处看到,ArrayList 又被 FooService 的 data 字段引用,这个 ArrayList 整个 RetainedHeap 列的值是 431MB。
Retained Heap(深堆)代表对象本身和对象关联的对象占用的内存,Shallow Heap(浅堆)代表对象本身占用的内存。比如,我们的 FooService 中的 data 这个 ArrayList 对象本身只有 16 字节,但是其所有关联的对象占用了 431MB 内存。这些就可以说明,肯定有哪里在不断向这个 List 中添加 String 数据,导致了 OOM。
左侧的蓝色框可以查看每一个实例的内部属性,图中显示 FooService 有一个 data 属性,类型是 ArrayList。
如果我们希望看到字符串完整内容的话,可以右键选择 Copy->Value,把值复制到剪贴板或保存到文件中:
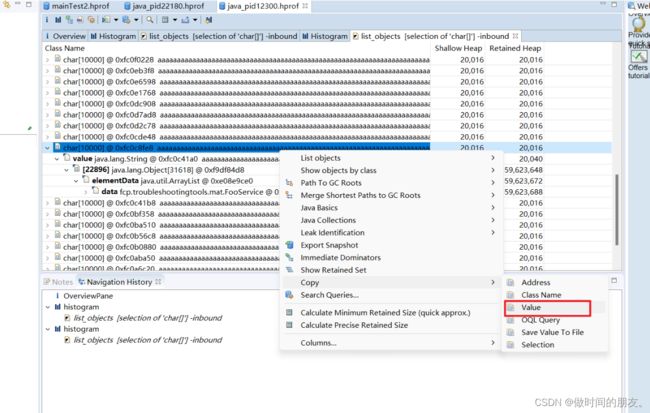
这里,我们复制出的是 10000 个字符 a(下图红色部分可以看到)。对于真实案例,查看大字符串、大数据的实际内容对于识别数据来源,有很大意义:

4、利用支配树查看内存中最大的对象
点击工具栏的第三个按钮可以进入到支配树界面,这个界面会根据Retained Heap 倒序直接列出占用内存最大的对象。
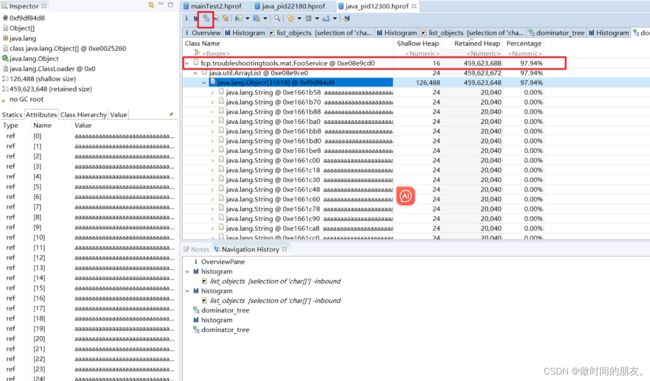
这样我们就可以很快速的定位到是哪个对象导致的OOM,接下来我们就要看一下OOM的时候,FooService在执行什么逻辑。
5、查看线程视图
点击工具栏的第五个按钮,打开线程视图,首先看到的是main线程。
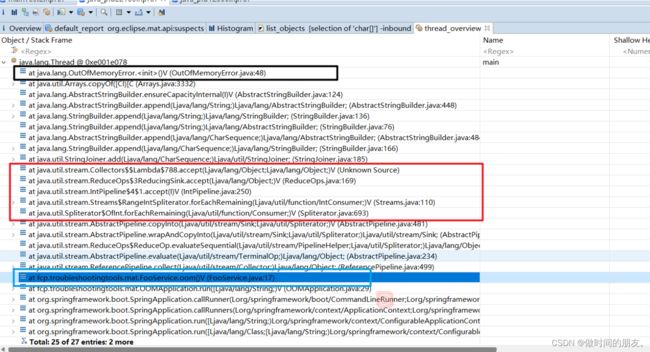
从黑色框来看,确实这里发生了OOM。紧接继续往下看,寻找我们可以的FooService,可以看到这个线程栈中FooSerice.oom()方法被调用。
在往下看的话,可看到参数中的 CommandLineRunner 你应该能想到,OOMApplication 其实是实现了 CommandLineRunner 接口,所以是 SpringBoot 应用程序启动后执行的。
在FooService.oom()往上看,红色框部分,我们可以猜测出这些字符串是由Stream操作产生的,以及在上面的StringBuilder 的 append是最终导致OOM的方法。
6、OQL查找类
最后我们还可以看一下FooService是不是Spring的Bean,又是不是单例?如果是的话,就更能确定是因为反复调用同一个 FooService 的 oom 方法,然后导致其内部的 ArrayList 不断增加数据的。
我们可以点击工具栏的第四个按钮,进入到OQL界面,然后在这里我们可以使用类似 SQL 的语法,在 dump 中搜索数据(你可以直接在 MAT 帮助菜单搜索 OQL Syntax,来查看 OQL 的详细语法)。
比如,输入如下语句搜索 FooService 的实例:
select * from fcp.troubleshootingtools.mat.FooService
可以看到只有一个实例,然后我们通过 List objects 功能搜索引用 FooService 的对象:
得到以下结果:
 可以看到,一共两处引用:
可以看到,一共两处引用:
- 第一处是,OOMApplication 使用了 FooService,这个我们已经知道了。
- 第二处是一个 ConcurrentHashMap。可以看到,这个 HashMap 是 DefaultListableBeanFactory 的 singletonObjects 字段,可以证实 FooService 是 Spring 容器管理的单例的 Bean。
我们甚至可以在HashMap 上点击右键,选择 Java Collections->Hash Entries 功能,来查看其内容:


我们还可以在Value列通过正则进一步对解决进行过滤筛选:

到现在为止,我们虽然没看程序代码,但是已经大概知道程序出现 OOM 的原因和大概的调用栈了。我们再贴出程序来对比一下,果然和我们看到得一模一样:
@SpringBootApplication
public class OOMApplication implements CommandLineRunner {
@Autowired
FooService fooService;
public static void main(String[] args) {
SpringApplication.run(OOMApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
//程序启动后,不断调用Fooservice.oom()方法
while (true) {
fooService.oom();
}
}
}
@Component
public class FooService {
List<String> data = new ArrayList<>();
public void oom() {
//往同一个ArrayList中不断加入大小为10KB的字符串
data.add(IntStream.rangeClosed(1, 10_000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")));
}
}
这边做个小总结
- 我们通过MAT可以通过直方图很方便的知道当前堆中哪个对象的数量较多且占据的堆内存较多。同时我们可以通过List objects查看引用链,最终定位到究竟是在哪个类中出现了大量对象导致OOM
- 除了直方图外,我们可以使用支配树在更快的时间发现导致OOM的对象
- 然后根据线程视图,定位到具体是在哪个地方发生了OOM
- 最后呢,我们可以通过OQL查看类,搜索类有几个实例,以及实例在哪几个地方有引用
最后呢,可以到代码地址中下载相关代码,然后本地实践一下。以及本篇文章的内容实际上是学习自极客时间的《Java业务开发常见错误100例》这是一个实战性比较强的专栏,推荐大家也可以去看看