滴滴Ceph分布式存储系统优化之锁优化
摘自:https://mp.weixin.qq.com/s/oWujGOLLGItu1Bv5AuO0-A
2020-09-02 21:45
0.引言
Ceph是国际知名的开源分布式存储系统,在工业界和学术界都有着重要的影响。Ceph的架构和算法设计发表在国际系统领域顶级会议OSDI、SOSP、SC等上。Ceph社区得到Red Hat、SUSE、Intel等大公司的大力支持。Ceph是国际云计算领域应用最广泛的开源分布式存储系统,此外,Ceph也广泛应用在文件、对象等存储领域。Ceph在滴滴也支撑了很多关键业务的运行。在Ceph的大规模部署和使用过程中,我们发现了Ceph的一些性能问题。围绕Ceph的性能优化,我们做了很多深入细致的工作。这篇文章主要介绍我们通过调试分析发现的Ceph在锁方面存在的问题和我们的优化方法。
1. 背景
在支撑一些延迟敏感的在线应用过程中,我们发现Ceph的尾延迟较差,当应用并发负载较高时,Ceph很容易出现延迟的毛刺,对延迟敏感的应用造成超时甚至崩溃。我们对Ceph的尾延迟问题进行了深入细致的分析和优化。造成尾延迟的一个重要原因就是代码中锁的使用问题,下面根据锁问题的类型分别介绍我们的优化工作。本文假设读者已熟悉Ceph的基本读写代码流程,代码的版本为Luminous。
2. 持锁时间过长
▍2.1 异步读优化
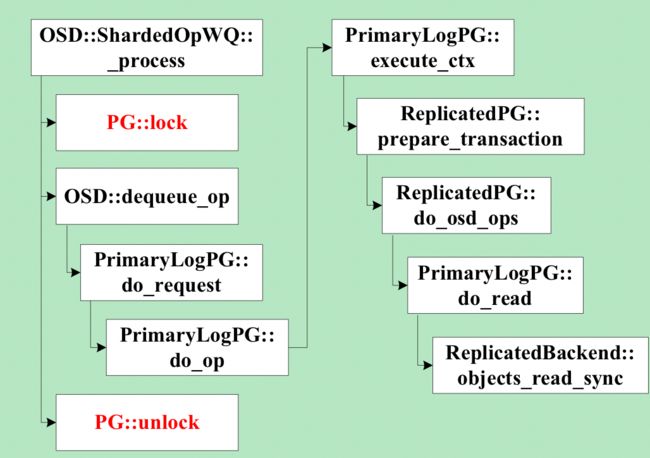
Ceph的osd处理客户端请求的线程池为osd_op_tp,在处理操作请求的时候,线程会先锁住操作对应pg的lock。其中,处理对象读请求的代码如下图所示,在锁住对象所属pg的lock后,对于最常用的多副本存储方式,线程会同步进行读操作,直到给客户端发送返回的数据后,才会释放pg lock。
在进行读操作时,如果数据没有命中page cache而需要从磁盘读,是一个耗时的操作,并且pg lock是一个相对粗粒度的锁,在pg lock持有期间,其它同属一个pg的对象的读写操作都会在加锁上等待,增大了读写延迟,降低了吞吐率。同步读的另一个缺点是读操作没有参与流量控制。
我们对线上集群日志的分析也验证了上述问题,例如,一个日志片段如下图所示,图中列举了两个op的详细耗时信息,这两个op均为同一个osd的线程所执行,且操作的是同一个pg的对象。根据时间顺序,第一个op为read,总耗时为56ms。第二个op为write,总耗时为69ms。图中信息显示,第二个op处理的一个中间过程,即副本写的完成消息在处理之前,在osd请求队列中等待了36ms。结合上图的代码可以知道,这36ms都是耗在等待pg lock上,因为前一个read操作持有pg lock,而两个对象属于相同pg。

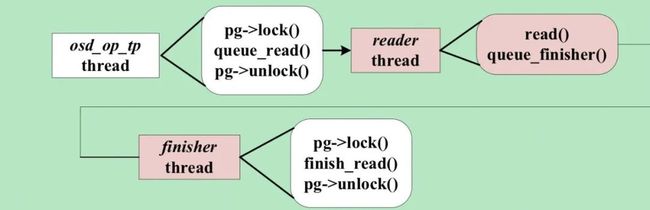
我们的优化如下图所示,我们创建了独立的读线程,负责处理读请求,osd_op_tp线程只需将读请求提交到读线程的队列即可返回解锁,大大减少了pg lock的持有时间。读线程完成磁盘读之后,将结果放到finisher线程的队列,finisher线程重新申请pg lock后负责后续处理,这样将耗时的磁盘访问放在了不持有pg lock的流程中,结合我们在流量控制所做的优化,读写操作可以在统一的框架下进行流量控制,从而精准控制磁盘的利用率,以免磁盘访问拥塞造成尾延迟。
我们用fio进行了异步读优化效果的测试,测试方法:对同一个pool的两个rbd,一个做随机读,另一个同时做随机写操作,将pg number配置为1,这样所有对象读写会落到同一个osd的同一个pg。异步读优化后,随机写平均延迟下降了53%。下图为某业务的filestore集群异步读上线前后读吞吐率的数据,箭头所指为上线时间,可见上线之后,集群承载的读操作的吞吐率增加了120%。

上述优化在使用filestore存储后端时取得了明显的效果,但在使用bluestore存储后端时,bluestore代码中还存在持有pg粒度锁同步读的问题,具体见BlueStore::read的代码。我们对bluestore的读也进行了异步的优化,这里就不详细介绍了。
3. 锁粒度过粗
▍3.1 object cache lock优化
Ceph在客户端实现了一个基于内存的object cache,供rbd和cephfs使用。但cache只有一把大的互斥锁,任何cache中对象的读写都需要先获得这把锁。在使用写回模式时,cache flusher线程在写回脏数据之前,也会锁住这个锁。这时对cache中缓存对象的读写都会因为获取锁而卡住,使读写延迟增加,限制了吞吐率。
我们实现了细粒度的对象粒度的锁,在进行对象的读写操作时,只需获取对应的对象锁,无需获取全局锁。只有访问全局数据结构时,才需要获取全局锁,大大增加了对象间操作的并行。并且对象锁采用读写锁,增加了同一对象上读的并行。测试表明,高并发下rbd的吞吐率增加了超过20%。
4. 不必要的锁竞争
▍4.1减少pg lock竞争
Ceph的osd对客户端请求的处理流程为,messenger线程收到请求后,将请求放入osd_op_tp线程池的缓存队列。osd_op_tp线程池的线程从请求缓存队列中出队一个请求,然后根据该请求操作的对象对应的pg将请求放入一个与pg一一对应的pg slot队列的尾部。然后获取该pg的pg lock,从pg slot队列首部出队一个元素处理。
可见,如果osd_op_tp线程池的请求缓存队列中连续两个请求操作的对象属于相同的pg,则一个osd_op_tp线程出队前一个请求加入pg slot队列后,获取pg lock,从pg slot队列首部出队一个请求开始处理。另一个osd_op_tp线程从请求缓存队列出队第二个请求,因为两个请求是对应相同的pg,则它会加入相同的pg slot队列,然后,第二个线程在获取pg lock时会阻塞。这降低了osd_op_tp线程池的吞吐率,增加了请求的延迟。
我们的优化方式是保证任意时刻每个pg slot队列只有一个线程处理。因为在处理pg slot队列中的请求之前需要获取pg lock,因此同一个pg slot队列的请求是无法并行处理的。我们在每个pg slot队列增加一个标记,记录当前正在处理该pg slot的请求的线程。当有线程正在处理一个pg slot的请求时,别的线程会跳过处理该pg slot,继续从osd_op_tp线程池的请求缓存队列出队请求。
▍4.2 log lock优化
Ceph的日志系统实现是有一个全局的日志缓存队列,由一个全局锁保护,由专门的日志线程从日志缓存队列中取日志打印。工作线程提交日志时,需要获取全局锁。日志线程在获取日志打印之前,也需要获取全局锁,然后做一个交换将队列中的日志交换到一个临时队列。另外,当日志缓存队列长度超过阈值时,提交日志的工作线程需要睡眠等待日志线程打印一些日志后,再提交。锁的争抢和等待都增加了工作线程的延迟。
我们为每个日志提交线程引入一个线程局部日志缓存队列,该队列为经典的单生产者单消费者无锁队列。线程提交日志直接提交到自己的局部日志缓存队列,该过程是无锁的。只有队列中的日志数超过阈值后,才会通知日志线程。日志线程也会定期轮询各个日志提交线程的局部日志缓存队列,打印一些日志,该过程也是无锁的。通过上述优化,基本避免了日志提交过程中因为锁竞争造成的等待,降低了日志的提交延迟。测试在高并发日志提交时,日志的提交延迟可降低接近90%。
▍4.3 filestore apply lock优化
对于Ceph filestore存储引擎,同一个pg的op需要串行apply。每个pg有一个OpSequencer(简称osr),用于控制apply顺序,每个osr有一个apply lock以及一个op队列。对于每个待apply的op,首先加入对应pg的osr的队列,然后把osr加到filestore的负责apply的线程池op_tp的队列,简称为apply队列。op_tp线程从apply队列中取出一个osr,加上它的apply lock,再从osr的队列里取出一个op apply,逻辑代码如下图左所示。可见,每个op都会把其对应的osr加入到apply队列一次。如果多个op是针对同一个pg的对象,则这个pg的osr可能多次加入到apply队列。如果apply队列中连续两个osr是同一个pg的,也就是同一个osr,则前一个op被一个线程进行apply时,osr的apply lock已经加锁,另一个线程会在该osr的apply lock上阻塞等待,降低了并发度。

这个问题也体现在日志中。一个线上集群日志片段如下图,有两个op_tp线程6700和5700,apply队列里三个对象依次来自pg: 1.1833, 1.1833. 1.5f2。线程6700先拿到第一个对象进行apply, 线程5700拿第二个对象进行apply时卡在apply lock上,因为两个对象都来自pg 1.1833,直到6700做完才开始apply。而6700拿到第三个对象,即1.5f2的对象进行apply即写page cache只用了不到1ms,但实际apply延迟234ms,可见第三个对象在队列里等待了233ms。如果5700不用等待apply lock,则第二和第三个对象的apply延迟可以大大缩短。

我们优化后的逻辑代码如上图右所示,同一个osr只加入apply队列一次,取消apply lock,利用原子操作实现无锁算法。上面的算法可以进一步优化,在将一个osr出队之后,可以一次从它的队列中取m(m>1)个op进行apply,在op apply完成阶段,改为如果atomic::fetch_sub(osr->queue_length, m) > m,则将osr重新入队以提高吞吐率。
我们用fio进行了apply lock优化效果测试,方法为建两个pool,每个pool的pg number为1,每个pool一个rbd, 对两个rbd同时进行随机写的操作,一个pool写入数据的量为31k*10k,另一个pool写入数据的量为4k*100k, 衡量所有请求apply的总耗时。优化前总耗时434ks, 优化后总耗时45ks,减少89.6%。
团队介绍
滴滴云平台事业群滴滴云存储团队原隶属于滴滴基础平台部,现隶属于新成立的滴滴云事业部。团队承担着公司在线非结构化存储服务的研发,并参与运维工作。具体来说,团队承担了公司内外部业务的绝大部分的对象、块、文件存储需求,数据存储量数十PB。团队技术氛围浓厚,同时具备良好的用户服务意识,立足于用技术创造客户价值,业务上追求极致。团队对于分布式存储、互联网服务架构、Linux存储栈有着深入的理解。
作者介绍

负责滴滴在线非结构化存储研发,曾任国防科技大学计算机学院副研究员,教研室主任,天河云存储负责人