去年在 re:Invent 上,我们推出了 Amazon Redshift Serverless 的预览版,这是 Amazon Redshift 的无服务器选项,可让您分析任何规模的数据,而无需管理数据仓库基础设施。您只需要加载和查询数据,并且只需为使用的内容付费。这使更多的公司能够制定现代数据策略,尤其适用于分析工作负载不全天候运行且数据仓库并非一直处于活动状态的使用案例。也适用于组织内数据使用量不断扩大、新部门的用户希望在不拥有数据仓库基础设施的情况下运行分析的公司。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
今天,我很高兴地与大家分享 Amazon Redshift Serverless 已正式推出,而且我们添加了许多新功能。与预览版相比,我们还降低了 Amazon Redshift Serverless 的计算成本。
现在,您可以使用命名空间和工作组为每个 Amazon 账户和区域创建多个无服务器端点:
- 命名空间是数据库对象和用户的集合,例如数据库名称和密码、权限和加密配置。这是管理数据的地方,在这里您可以看到使用了多少存储空间。
- 工作组是计算资源的集合,包括网络和安全设置。每个工作组都有一个无服务器端点,您可以将应用程序连接到该端点。配置工作组时,您可以设置私有或可公开访问的端点。
每个命名空间只能有一个与之关联的工作组。相反,每个工作组只能与一个命名空间关联。您可以拥有一个没有任何工作组与其关联的命名空间,例如,仅将其用于与同一或其他 Amazon 账户或区域中的其他命名空间共享数据。
在工作组配置中,您现在可以使用查询监控规则来帮助控制成本。此外,Amazon Redshift Serverless 自动扩展数据仓库容量的方式更加智能,能够快速为要求苛刻且不可预测的工作负载提供性能。
我们来通过一个快速演示了解下具体的工作原理。然后,我将向您展示如何使用命名空间和工作组。
使用 Amazon Redshift Serverless
在 Amazon Redshift 控制台中,我在导航窗格中选择了 Redshift serverless(Redshift 无服务器)。首先,我选择 Use default settings(使用默认设置)来配置命名空间和具有最常用选项的工作组。例如,我将能够使用我的默认 VPC 和默认安全组进行连接。

使用默认设置时,剩下的唯一配置选项是 Permissions(权限)。在这里,我可以指定 Amazon Redshift 如何与 S3、Amazon CloudWatch Logs、Amazon SageMaker 和 Amazon Glue 等其他服务进行交互。为了稍后加载数据,我授予 Amazon Redshift 访问 S3 存储桶的权限。我选择 Manage IAM roles(管理 IAM 角色),然后选择 Create IAM role(创建 IAM 角色)。
创建 IAM 角色时,我选择了授予 specific S3 buckets(特定 S3 存储桶)访问权限的选项,然后在同一 Amazon 区域中选择一个 S3 存储桶。 然后,我选择 Create IAM role as default(创建 IAM 角色作为默认角色)来完成角色的创建,并自动将其用作命名空间的默认角色。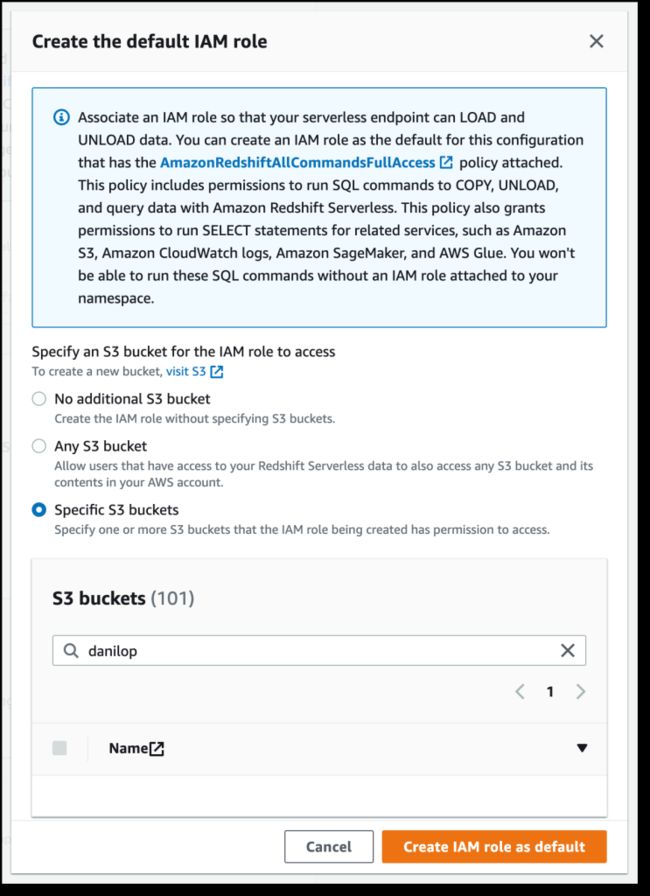
我选择 Save configuration(保存配置),几分钟后数据库就可以使用了。在 Serverless dashboard(无服务器控制面板)中,我选择 Query data(查询数据)来打开 Redshift query editor v2(Redshift 查询编辑器 v2)。然后,我按照 Amazon Redshift 数据库开发人员指南中的说明加载示例数据库。如果您想做一个快速测试,sample_data_dev 数据库中已经有几个示例数据库(包括我在这里使用的数据库)。另请注意,运行查询不需要将数据加载到 Amazon Redshift 中。通过创建外部架构和外部表,我可以在查询中使用来自 S3 数据湖的数据。
示例数据库由七个表组成,跟踪虚构的“TICKIT”网站的销售活动,用户在该网站上买卖体育赛事、表演和音乐会的门票。
为了配置数据库架构,我运行了几个 SQL 命令来创建 users、venue、category、date、 event、listing和 sales表。
然后,我下载了 tickitdb.zip 文件,其中包含数据库表的示例数据。我解压缩文件并将其加载到配置 IAM 角色时使用的同一 S3 存储桶中的 tickit文件夹。
现在,我可以使用 COPY 命令将 S3 存储桶中的数据加载到我的数据库中。例如,要将数据加载到 users表中,请执行以下操作:
SQL
https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html包含 sales表数据的文件使用制表符分隔的值:
SQL
copy sales from 's3://MYBUCKET/tickit/sales_tab.txt' iam_role default delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS';在所有表中加载数据后,我开始运行一些查询。例如,以下查询联接五个表,以查找加利福尼亚州活动的前五名卖家(请注意,示例数据为 2008 年的数据):
SQL
select sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold)
from sales, date, users, event, venue
where sales.sellerid = users.userid
and sales.dateid = date.dateid
and sales.eventid = event.eventid
and event.venueid = venue.venueid
and year = 2008
and venuestate = 'CA'
group by sellerid, username, sellername, venuestate
order by 5 desc
limit 5;
现在我的数据库已准备就绪,让我们看看通过配置 Amazon Redshift Serverless 命名空间和工作组可以做些什么。
**
使用和配置命名空间**
命名空间是数据库数据及其安全配置的集合。在 Amazon Redshift 控制台的导航窗格中,我选择 Namespace configuration(命名空间配置)。在列表中,我选择我刚刚创建的 default命名空间。
在 Data backup(数据备份)选项卡中,我可以创建或恢复快照或从其中一个恢复点恢复数据,这些恢复点每 30 分钟自动创建一次,保留 24 小时。这对于在意外写入或删除的情况下恢复数据非常有用。
在 Security and encryption(安全和加密)选项卡中,我可以更新权限和加密设置,包括用于加密和解密我的资源的 AWS Key Management Service(AWS KMS)密钥。在此选项卡中,我还可以启用审计日志记录并导出用户、连接和用户活动日志。[[日志要导出到哪里? CloudWatch 日志? 从控制台的角度不清楚]]

在 Datashares(数据共享)选项卡中,我可以创建一个数据共享,以便与相同或不同区域中的其他命名空间和 AWS 账户共享数据。在此选项卡中,我还可以使用从其他命名空间或 AWS 账户收到的共享创建数据库,并且可以看到由 AWS Data Exchange 管理的数据共享的订阅。
当我创建数据共享时,我可以选择要包含哪些对象。例如,现在我只想共享 date和 event表,因为它们不包含敏感数据。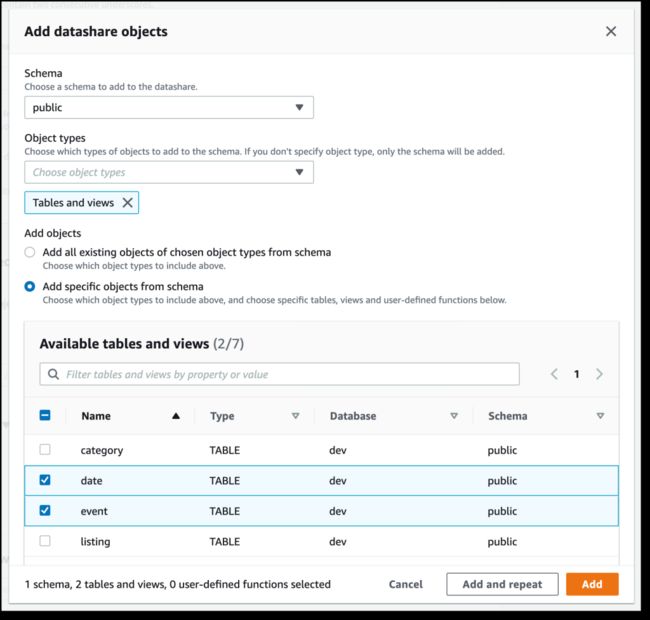
使用和配置工作组
工作组是计算资源及其网络和安全设置的集合。它们为其配置的命名空间提供无服务器端点。在 Amazon Redshift 控制台的导航窗格中,我选择 Workgroup configuration(工作组配置)。在列表中,我选择我刚刚创建的 default命名空间。
在 Data access(数据访问)选项卡中,我可以更新网络和安全设置(例如,更改 VPC、子网或安全组)或将端点设为可公开访问。在此选项卡中,我还可以启用 Enhanced VPC routing(增强型 VPC 路由),以便通过 VPC 而非互联网在我的无服务器数据库和我使用的数据存储库(例如,用于加载或卸载数据的 S3 存储桶)之间路由网络流量。要访问位于其他 VPC 或子网中的无服务器端点,我可以创建由 Amazon Redshift 管理的 VPC endpoint(VPC 端点)。

在 Limits(限制)选项卡中,我可以配置用于处理查询的基本容量(以 Redshift 处理单元或 RPU 表示)。Amazon Redshift Serverless 可扩展容量以应对更多用户的需求。在这里,我还可以选择增加基本容量以加快查询速度,或者减少基本容量以降低成本。
在此选项卡中,我还可以设置 Usage limits(使用限制),以配置每日、每周和每月阈值,以保持成本的可预测性。例如,我为计算资源配置了每日 200 RPU 小时的限制和每月 2,000 RPU 小时的限制。为了控制跨区域数据共享的数据传输成本,我将每日限制配置为 3 TB,每周限制配置为 10 TB。最后,为了限制每个查询使用的资源,我使用 Query limits(查询限制)将运行超过 60 秒的查询设为超时。

可用性和定价
Amazon Redshift Serverless 现已在以下 Amazon 区域正式推出:美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国东部(俄勒冈州)、欧洲地区(法兰克福)、欧洲地区(爱尔兰)、欧洲地区(伦敦)、欧洲地区(斯德哥尔摩)和亚太地区(首尔)、亚太地区(新加坡)、亚太地区(悉尼)和亚太地区(东京)。
您可以使用自己喜欢的客户端工具通过 JDBC/ODBC 或使用 Amazon Redshift 查询编辑器 v2(在 Amazon Redshift 控制台上提供的基于 Web 的 SQL 客户端应用程序)连接到工作组端点。使用基于 Web 服务的应用程序(例如 AWS Lambda 函数或 Amazon SageMaker 笔记本)时,您可以使用内置的 Amazon Redshift 数据 API 访问数据库并执行查询。
使用 Amazon Redshift Serverless,您只需为数据库处于活动状态时消耗的计算容量付费。计算容量会根据您的工作负载自动扩展或缩减,并在闲置期间关闭,以节省时间和成本。您的数据存储在托管存储中,您需要按每月 GB 的费率付费。
为了提高性价比并灵活地将 Amazon Redshift Serverless 用于更广泛的使用案例,我们正在将美国东部(弗吉尼亚州北部)区域的每 RPU 小时价格从 0.5 美元降至 0.375 美元。同样,我们也会将其他区域的价格从预览版价格平均降低 25%。有关更多信息,请参阅 Amazon Redshift 定价页面。
为了帮助您练习自己的使用案例,我们还提供 300 美元的 AWS 服务抵扣金,为期 90 天,用于试用 Amazon Redshift Serverless。这些服务抵扣金仅用于支付 Amazon Redshift Serverless 的计算、存储和快照使用费用。
使用 Amazon Redshift Serverless,在几秒钟内从数据中获取见解。
— Danilo
文章来源:https://dev.amazoncloud.cn/column/article/6309a617afd24c6ba21...