Java爬取酷狗音乐歌单

AHA
目录
前言
一、分析
二、构想实现
三、代码实现
1.引入jar包(使用工具来简化开发)
2.写入代码
3.完成
总结
前言
最近表姐想让我帮她U盘下载几首车载音乐,感觉挺简单的,直接打开谷歌浏览器搜索酷狗音乐(表姐要的歌单是酷狗),播放一首歌页面跳转到播放器,然后老规矩F12+Ctrl+F,搜索audio标签得到src链接,点进去就能下载了,可是她要的可不止一首啊,要整个歌单,那只能采用爬虫来获取我们想要的东西了。
一、分析
爬虫之前我们需要熟悉爬虫的基本流程:
1.发起请求:通过url向服务器发起request请求,请求可以包含额外的header信息。
2.获取响应内容:如果服务器正常响应,那我们将会收到一个response,response即为我们所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。
3.解析内容:如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件进行进一步处理。
4.保存数据:可以保存到本地文件,也可以保存到数据库
附上歌单链接:https://www.kugou.com/yy/special/single/3337103.html
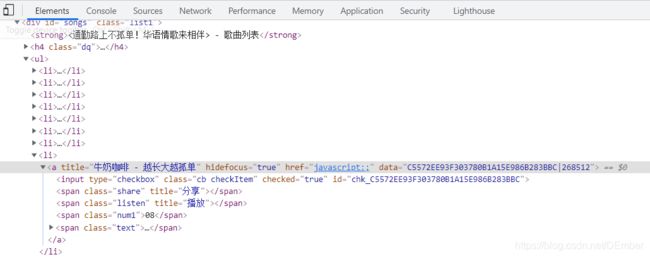
首先我们要的是歌单里面的每一首歌曲,从上面可以发现每一首歌都有一个a标签,而且这个a标签都有一个data值,而href指向的不是一个具体的地址,所以可以判定的采用JS代码控制来跳转的,再看看下面的图片是新跳转的播放器页面的URL,可知每一首歌对应的hash的值和歌单页面的歌曲a标签的data值一致,这就可以知道hash了,但是这个album_id是怎么来的呢?
![]() 我们再点开一首歌曲,可以看出变化的只是hash和album_id
我们再点开一首歌曲,可以看出变化的只是hash和album_id
![]()
也就是说这个hash和album_id是从歌单页面跳转到播放页面的,那要找这个album_id也得从歌单页面找,作者在歌单页面里的JS文件找到了album_id的出处,其实在页面加载时就已经从后端接口请求这个歌单的所有歌曲信息,后来找到了这个data变量藏在了head标签里
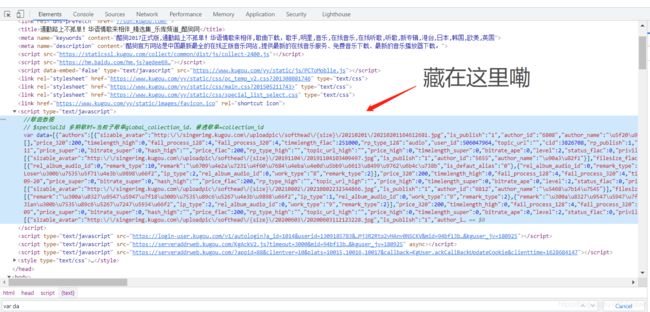
光有这些参数其实还不行,还得找到对应的后端请求接口,就像水管漏水了,空有一身修水管的功夫但是找不到哪个地方漏水也是虚劳的。因为我们的点击音乐会跳到播放页面,所以可以断定获取歌曲的请求是在播放页面上的,我们简单地抓一下包,打开F12,点击Network,Ctrl+R键刷新一下(因为页面在我们调试器打开之前就已经加载好了),一堆数据包我们只要其中的JS或者PHP文件,最终我们找到了我们的请求接口。
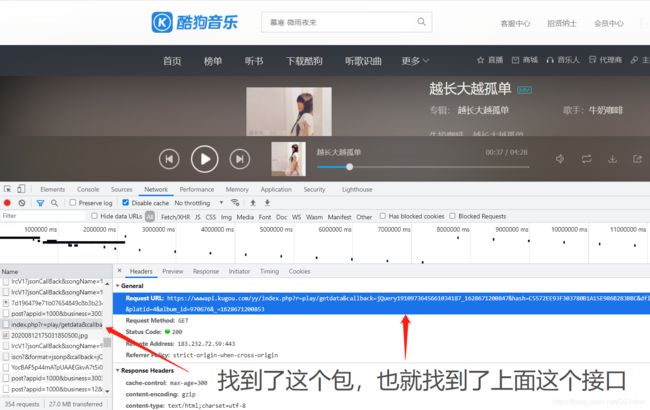
而这个接口里面变化的只有hash和album_id,所以我们可以拿取歌单的data变量里的hash和album_id去请求这个接口获取我们要的数据了
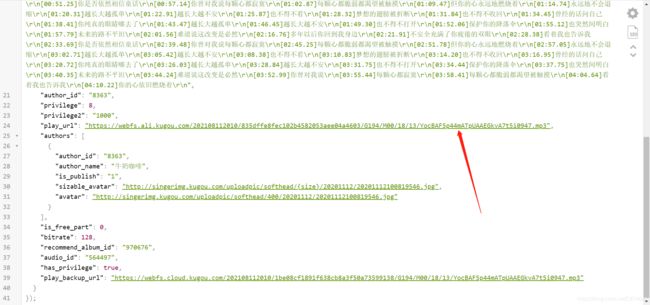
打开这个接口,往下翻可以找到这个资源就是我们要下载的东西
二、构想实现
每一个程序的功能的诞生离不开程序猿(媛)们的奇妙构想,所以我们也得先把总的实现思路构建起来才来进行下一步。
1.获取歌单所有的hash和album_id值。 既然我们要的是歌单所有的歌曲,而歌曲的获取唯一判别他们的可不是歌名,就像你的名字叫张三,他的名字也叫张三,那要是他犯法了抓不到,抓到了你这个张三那肯定不行,所以歌曲也一样,不能以歌名区分,只能用album_id来区分,和身份证号是一个道理,那我们就可以先获取歌单页的data变量,再把他们储存起来,匹配的话我们统一采用正则表达式。
2.接口地址拼接hash和album_id。 我们将获取到的歌曲请求接口按照我们匹配出来的hash和album_id拼接起来再去请求就能得到我们所要的数据。
3.下载到本地。 到了这一步已经是完成了,借助JavaIO流把数据传输到本地文件或者数据库上。(这边是准备上传到U盘里面所以就没必要放入数据库了)
三、代码实现
1.引入jar包(使用工具来简化开发)
org.jsoup
jsoup
1.13.1
org.apache.httpcomponents
httpclient
4.5.13
commons-io
commons-io
2.9.0
com.fasterxml.jackson.core
jackson-databind
2.11.4
Jsoup:一款Java 的HTML解析器,它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
HttpComponents:是专门设计来简化HTTP客户端与服务器进行各种通讯编程,主要是提供对http服务器的访问功能。
Commons-io:使用Java原生的IO流操作比较繁琐,可以利用IO工具库来简化。
Jackson:用来解析序列化和反序列化Json数据。
关于上面的工具库不再赘述了,有兴趣的小伙伴可以自行了解
2.写入代码
/**
* @author Ember
*/
public class SpiderKugou {
/**
* 1.歌曲的hash值 [正则匹配]
* 2.歌曲的album_id [正则匹配]
* 3.歌名 [正则匹配]
* 4.歌曲下载地址 [正则匹配]
* 5.unicode转中文 [正则匹配]
*/
private static final String hashRegex = ",\"hash\":\"(.*?)\",\"brief\":";
private static final String albumIdRegex = "\"album_id\":(.*?),\"hash\"";
private static final String audioNameRegex = "\"audio_name\":\"(.*?)\",\"have_album\"";
private static final String playUrlRegex = "\"play_url\":\"(.*?)\",\"authors\":";
private static final String unicodeRegex = "(\\\\u(\\p{XDigit}{4}))";
private static String baseUrl = "https://www.kugou.com/yy/special/single/3953033.html";
private static String downloadSrc = "E:/2021-8-8酷狗歌曲/download/";
public static void main(String[] args) throws Exception {
System.out.println("下载中...");
parameter(baseUrl);
System.out.println("歌单下载已完成!");
}
/**
* 爬取歌单的每一首歌曲
* @param baseUrl 酷狗歌单链接地址
* @throws Exception
*/
public static void parameter(String baseUrl) throws Exception {
//JSON工具
ObjectMapper mapper = new ObjectMapper();
//获取歌单的Document
Document musicList = Jsoup.connect(baseUrl).get();
//正则表达式匹配出歌单所有hash和album_id对应的值
List musicHash = myRegexpList(musicList.toString(), hashRegex);
List musicId = myRegexpList(musicList.toString(), albumIdRegex);
for (int i = 0;i < musicId.size();i++) {
//调出歌单每首歌的接口
String mp3 = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191043744424319789976_1628418579111" +
"&hash="+musicHash.get(i)+"&dfid=08yAMj3R2Rtq2vHAnv0NSCKV&mid=94bf13b027c6ce8289bdfa422f5e783e&platid=4" +
"&album_id="+musicId.get(i)+"&_=1628418579112";
//获取歌曲的doc
Document musicPlayer = parsUrl(mp3);
//获取歌曲的歌名
String unicodeName = myRegexpOne(musicPlayer.toString(), audioNameRegex);
//将unicode编码的歌名转换为中文
String musicName= unicodeToString(unicodeName);
//将接口的数据转为JSON对象
String mp3Doc = mapper.writeValueAsString(musicPlayer.body().text());
//转JSON有反斜杠,将反斜杠替换掉即可
mp3Doc = mp3Doc.replaceAll("\\\\", "");
//得到歌曲下载地址
String playUrl = myRegexpOne(mp3Doc, playUrlRegex);
//下载
downLoadMusic(playUrl,musicName);
System.out.println((i+1) + "--->【" + musicName + "】 >ω< 下载完成");
Thread.sleep(1000);
}
} public static void downLoadMusic(String musicUrl,String musicName){
try {
System.out.println("\n" + musicName + "源地址->" + musicUrl);
Connection.Response response = Jsoup.connect(musicUrl)
//忽略ContentType
.ignoreContentType(true)
//解除最大字节限制
.maxBodySize(0)
//模拟浏览器用户代理
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
//执行
.execute();
ByteArrayInputStream stream = new ByteArrayInputStream(response.bodyAsBytes());
FileUtils.copyInputStreamToFile(stream,new File(downloadSrc + musicName + ".mp3"));
} catch (Exception e) {
System.out.println("链接->"+musicUrl+" >﹏< 下载失败");
e.printStackTrace();
}
}
/**
* 获取Doc工具类
* @param url
* @return
* @throws Exception
*/
public static Document parsUrl(String url) throws Exception {
try {
Document document = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
.timeout(2000)
.get();
return document;
}catch (Exception e){
e.printStackTrace();
return null;
}
}
/**
* 正则匹配字符串集合工具类
* @param str
* @param keyWords
* @return
*/
public static List myRegexpList(String str,String keyWords){
List list = new ArrayList<>();
Pattern compile = compile(keyWords);
Matcher matcher = compile.matcher(str);
while (matcher.find()) {
list.add(matcher.group(1));
}
return list;
}
/**
* 正则匹配单个字符串工具类
* @param str
* @param keyWords
* @return
*/
public static String myRegexpOne(String str,String keyWords){
String result = "";
Pattern compile = compile(keyWords);
Matcher matcher = compile.matcher(str);
while (matcher.find()) {
result = matcher.group(1);
}
return result;
}
/**
* unicode转码中文字符
* @param str
* @return
*/
public static String unicodeToString(String str) {
Pattern pattern = compile(unicodeRegex);
Matcher matcher = pattern.matcher(str);
char ch;
while (matcher.find()) {
ch = (char) Integer.parseInt(matcher.group(2), 16);
str = str.replace(matcher.group(1), ch+"" );
}
return str;
}
} 3.完成
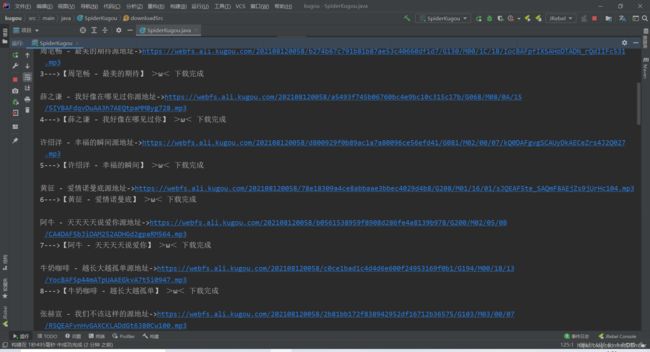

可以看到我们下载成功了
总结
为什么使用Java爬虫来抓取酷狗资源呢,一个是目前大多都是Python教程,Java爬取酷狗比较少,也有一些小伙伴可能只接触到Java这门编程语言或者就没接触Python的,想要了解了解如何使用Java进行抓取。二是作者也是刚接触到Java爬虫,Python并没了解过,但Java和Python都能做到相同的东西,只是工程量的事,还有表姐突如其来的要求也让我萌生了使用Java练手一下。
以上就是今天要讲的内容,本文仅仅简单介绍了Java如何爬取网页数据的使用,还有如何使用第三方类库更加方便地进行开发。有需要的小伙伴可供参考,如果觉得本文对你有一定的帮助的话不妨帮我点个赞,收藏一下~感谢!