
- 傻瓜式临床预测模型软件 LogisticApp
- 无需复杂冗长的代码
- 只需要鼠标点点,
- 即可轻松完成 3 分 SCI
- 支持 Windows32 位、64 位,Mac intel 芯片、M1/M2 芯片
视频教程见 B 站 up 主:R 语言临床预测模型
1 LogisticApp 简介
- 傻瓜式零代码 Logistic 临床预测模型构建、评价、验证。
- 涉及批量缺失值的多重插补、倾向性匹配得分 PSM、基线资料分析、批量单因素 Logistic 回归、多因素 Logistic 回归、森林图自动绘制、逐步回归、最优子集、Lasso 回归及 Score 计算、随机森林、机器学习(SVM、GBM、ANN、treebag、pls、nnet、bayyes)、列线图 Nomogram 绘制、Nomogram 评分计算、留一法交叉验证、K 折交叉验证、自助抽样 boot、内外部验证(ROC 曲线、AUC、PR 曲线、校准曲线、C 指数、拟合优度、DCA 曲线、CIC 曲线、NRI、IDI 计算)、多模型比较(ROC 曲线、AUC、校准曲线、C 指数、DCA 曲线)、相加交互、相乘交互、Logistic Curve、亚组分析、限制性立方样条图 RCS 等。下面逐一介绍。
- LogisticApp2.2.1 版本 下载链接:
https://pan.baidu.com/s/1vgnvqTfTxIrhCKb37scSWw?pwd=m919 提取码:m919 - 关注微信公众号 spss1949 回复
LogApp获得 LogisticApp 最新版下载链接。
2 软件登录
- 双击应用程序,打开软件。

- 弹出登录界面。输入用户名、密码,点击登录 Login 即可。

- 登录成功界面

3 样本量计算
- 切换到样本量计算菜单。
- 弹出样本量计算界面。
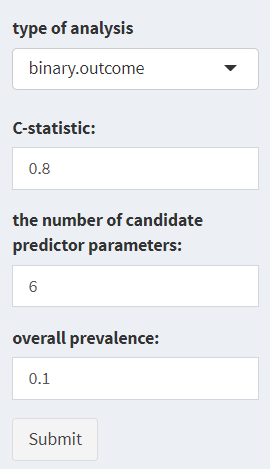
- 输入 4 个指标快速计算临床预测模型研究所需要的最小样本量,点击 submit,计算样本量,输出结果如下:

样本量计算的详细操作步骤及结果解读参照B站视频教程,篇幅原因,不再过多罗列。
4 上传数据
- 切换到上传数据菜单
Upload。
- 弹出上传数据界面。

- 点击
Upload CSV File中的Browse,导入电脑中的 csv 数据文件,可导入最大不超过100M的数据。需要注意数据并不会上传到云端,不存在数据泄露风险。
- 数据上传之后,需要设置分类自变量。在
Categroy X的选择框中通过鼠标选择分类自变量。选择完成之后,点击 submit。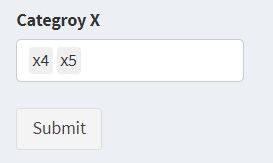
需要注意的是,即使你的数据中不存在分类自变量,也要点击此处的 submit,这样软件才知道你的数据中不存在分类自变量。另外对于因变量虽然其也是分类变量,但此处不要选择进来。此处是针对自变量的。 - 之后,我们可以分别切换到
View、Names、Summary、Structure界面。查看数据的基本信息。4 个界面结果截图如下: - View 窗口浏览全部数据。

- Names 窗口浏览全部变量名,切记变量名不能有空格或其他特殊符号。变量名称只支持 26 个英文字母或者.与\_

- Summary 窗口浏览全部变量摘要信息。分类变量提供频数信息,连续性变量提供最基本的 5 个描述统计量信息。

- Structure 窗口浏览全部变量结构信息。再次核对数据以及变量的类型,相当重要!!!

5 拆分数据
- 数据的拆分有两种方法,一种是随机拆分,另外一种是按照数据中的某个二分类资料直接进行拆分。

- 在数据拆分的
Split data选择框中,Split.Random 表示随机拆分,此时我们需要通过Set Seed设置种子数,以保证结果的重现性,种子数不同,拆分的数据就不同,这里种子数我设置成了859929351,然后是通过Number:%来设置按照什么比例拆分,一般是按照 70%作为训练集,30%作为测试集,设置完成之后点击submit。如果样本量低,可将拆分比例拉到100%,所有数据都将是建模集,而没有测试集。这样就只有建模集自身的内部验证,而无测试集验证。
- 在数据拆分的
Split data选择框中,Split.by.Variable 表示按照数据中的某个二分类资料直接进行拆分,默认样本量大的是训练集,样本量小的是测试集。比如截图中选择了变量Sex,那就会按照性别的不同拆分成两个数据集。设置完成之后点击submit。
在数据拆分完成之后,在哪里找到拆分后的数据集呢?在下方的截图中,我们可以切换到Trainset界面即显示训练集,共有 196 个样本。可以通过图中的CSV将数据导出成 CSV 格式的本地数据,也可以通过图中的Excel导出成 Excel 格式的本地数据。具体步骤不再赘述。针对测试集,只要切换到Testset即可。

6 多重插补 Mice
若数据存在缺失值,可通过多重插补对缺失值进行填补,针对连续性变量、二分类变量、多分类变量试用不同的算法填补。需要注意的是,多重插补是针对整个数据集进行填补,和训练集、测试集无关。
- 在菜单界面点击
Mice,切换到多重插补界面。
- 自动完成缺失值填补,完整的数据见下。可通过
CSV按键或者Excel将插之后的数据集保存本地。
7 倾向性匹配得分 PSM
为什么要进行 PSM,可能的原因是你的原始数据基线不平衡,需要对不平衡的数据进行 PSM,从而得到均衡性的目的。具体原理观看我B站视频。需要注意的是,PSM 也是针对整个数据集进行匹配,和训练集、测试集无关。
- 在菜单界面点击
PSM-Table,切换到 PSM 界面。
- 在
PSM界面,通过Y选择因变量,必须是二分类,比如病例组和对照组,或者试验组和对照组。通过X选择匹配的协变量。通过1:N Matched:q 确定是 1 比几匹配,指定1个病例匹配几个对照。通过caliper:确定卡钳值是 0.1。点击Submit开始匹配。
- TabUnmatched窗口:显示未匹配前,病例组、对照组的变量分布情况,建议用SMD来衡量均衡性,而非P值。表格可导出本地。结果略。
- 匹配之后的数据见下,可通过
CSV按键或者Excel将插之后的数据集保存本地。在数据里有一个 match.id 表示哪些研究对象配在一起组成了对子。match.id相同的表示属于1个对子。表格可导出本地。
- 匹配之后的数据,共有 2183 对。两组间的协变量比较,可通过 P 值或SMD值来判断是否均衡。

- 在菜单界面点击
PSM-Plot,可查看 PSM 得到的图形。每一幅图形都可以通过右侧的菜单进行细节调整。图形确定无误后可导出成PDF。 - 显示未匹配前,病例组、对照组的密度曲线情况,右侧参数可进行图形的颜色、坐标轴等个性化设置。图形可导出本地。

- 显示匹配后,病例组、对照组的密度曲线情况,右侧参数可进行图形的颜色、坐标轴等个性化设置。图形可导出本地。

- 显示匹配后,病例组、对照组的love plot,右侧参数可进行图形的颜色、坐标轴等个性化设置。图形可导出本地。

8 基线资料比较
可以批量进行基线资料的分析,自动化导出训练集、验证集基线信息,以及训练集、验证集比较的表格。
- 在菜单界面点击
Baseline,切换到基线分析界面。
- 在基线分析界面,通过
Y选择二分类因变量,通过Select Method设置选择自变量的方法,提供两种方法,一种是按照变量名选择,一种是按照列选择。这里面我们按照变量名称来选择,通过X多选框来选择变量名称。点击Submit。
- 通过
Nonparametric来选择针对连续性自变量究竟是进行秩和检验还是 T 检验。Significant P Value来设置 alpha=0.05。
- 输出结果见下,包含整个数据集的基线信息,训练集的基线信息,验证集的基线信息,训练集和验证集比较的信息。表格中包含描述性统计结果以及差异性比较的 P 值。可以导出为三线表。_需要注意的是_,如果选择 T 检验,罗列的是均数和标准差;如果选择秩和检验,罗列是的中位数、四分位数。
- All data Analysis窗口:对全部数据进行结局分析,按照是否发生结局分析两组间差异,支持批量卡方检验(罗列百分位数)、t检验(罗列均数、标准差)、秩和检验(罗列中位数、四分位数),自动汇报P


- Trainset Analysis,对建模集数据进行结局分析,按照是否发生结局分析两组间差异,支持批量卡方检验(罗列百分位数)、t检验(罗列均数、标准差)、秩和检验(罗列中位数、四分位数),自动汇报P


- Testset Analysis,对测试集数据进行结局分析,按照是否发生结局分析两组间差异,支持批量卡方检验(罗列百分位数)、t检验(罗列均数、标准差)、秩和检验(罗列中位数、四分位数),自动汇报P


- Trainset & Testset,对全部数据进行拆分均衡性检验,按照建模集 vs 测试集比较变量在两个数据间是否存在差异,理论上应该不存在差异,支持批量卡方检验(罗列百分位数)、t检验(罗列均数、标准差)、秩和检验(罗列中位数、四分位数),自动汇报P


9 批量单因素 Logistic
可以批量进行单因素 Logistic 回归分析,自动对单因素 P<0.05 的变量进行多因素 Logistic 回归分析,结果可导出为三线表。_注意_,针对的是训练集进行分析。
- 在菜单界面点击
Uni-Logistic,切换到 Logistic 回归分析界面。
- 在 Logistic 回归分析界面,通过
Decimal Digits:指定保留 3 位小数,通过Significant P Value:设置 P<0.05 的单因素进行多因素分析。_需要注意的是_,若 Significant P Value:设置为 1,将对所有变量进行多因素分析。
- Uniivariate Analysis窗口:对建模集数据进行分析结局的影响因素,批量进行单因素logistic回归,返回偏回归系数、标准误、统计量Z值、P值、OR值及其可信区间,自动汇报P

- Multivariate Analysis,自动对上一步P

- Uni-Multi Analysis,将单因素logistic结果与多因素logistic结果合并,包括Crude OR及其可信区间、P值,以及Adj OR及其可信区间、P值。结果可以表格形式下载本地。

- 除此之外还可以针对上述的单因素 Logistic、多因素 Logistic 自动绘制森林图,每一幅森林图的颜色、线条、坐标轴等细节均可以调整。共有 5 幅森林图。
- Uni--Forest Plots1窗口,单因素结果自动绘制森林图。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Uni--Forest Plots2窗口,单因素结果自动绘制森林图。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Multi-Forest Plots1,多多因素结果自动绘制森林图。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Multi-Forest Plots2,多多因素结果自动绘制森林图。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Multi-Forest Plots3,多因素结果自动绘制森林图。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

10 逐步回归
可以进行向前法逐步回归,向后法逐步回归。_注意_,针对的是训练集进行分析。
- 在菜单界面点击
Stepwise,切换到逐步回归界面。
- 针对建模集数据进行向前法逐步回归,省略迭代过程,只显示最终结果。结果可以表格形式下载本地。

- Backward,针对建模集数据进行向后法逐步回归,省略迭代过程,只显示最终结果。结果可以表格形式下载本地。

11 最优子集回归
可以进行枚举法的最优子集回归。_注意_,针对的是训练集进行分析。
- 在菜单界面点击
Optimal subset,切换到最优子集回归界面。
- AIC窗口,针对建模集数据,将候选自变量的所有组合均进行分析,提供其AIC,AIC最小是为最优模型。假设自变量个数是10,将有1023种组合。假设自变量个数是20,将有无穷大种组合。此种方法谨慎使用。。

- BIC窗口,针对建模集数据,将候选自变量的所有组合均进行分析,提供其BIC,BIC最小是为最优模型。

针对建模集数据,将候选自变量的所有组合均进行分析,提供其AUC,AUC是不能用于最优子集的,放在这里是有其他原因,见教学视频。

12 Lasso
可以进行 Lasso 回归。注意,针对的是训练集进行分析。
- 在菜单界面点击
Lasso,切换到 Lasso 回归界面。
- lasso1,针对建模集数据进行交叉lasso,返回图形1。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。。

- lasso2,针对建模集数据进行交叉lasso,返回图形2。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Lambda,针对建模集数据进行交叉lasso,返回Lambda.min、Lambda.1se。

- Lambda.min Coef,针对建模集数据进行交叉lasso,返回lambda.min筛选出的变量,结果可以表格形式下载本地。

- Lambda.1se Coef,针对建模集数据进行交叉lasso,返回lambda.1se筛选出的变量,结果可以表格形式下载本地。

Lambda Score,针对建模集数据进行交叉lasso,返回建模集、测试集的预测概率与线性预测值,即lasso评分,结果可以表格形式下载本地

13 随机森林模型
可以进行随机森林分析。注意,针对的是训练集进行分析。
- 在菜单界面点击
Random Forest,切换到 随机森林界面。
- 针对建模集数据进行随机森林分析,返回模型结果,显示袋外错误率等信息。

- Plot the error rates,绘制随机森林错误率。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Variable Importance Plot,绘制随机森林模型变量重要性排序及评分。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Rf pred,针对建模集数据进行随机森林,返回建模集、测试集预测概率,结果可以表格形式下载本地。

14 几种常见的机器学习
可以进行随机森林分析。注意,针对的是训练集进行模型构建。这里面是利用Baseline中的变量进行模型构建,所以如果你确定好了哪些变量来构建模型,需要回到Baseline界面中指定。
- 最后一列是SVM得到得预测概率。建模集和测试集都有预测概率,但是模型是建模集构建得。

- 最后一列是GBM得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

- 最后一列是ANN得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

- 最后一列是treebag得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

- 最后一列是pls得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

- 最后一列是nnet得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

最后一列是bayes得到得预测概率。。建模集和测试集都有预测概率,但是模型是建模集构建得。

15 Nomogram
- 在菜单界面点击
Nomogram,切换到绘制列线图界面。
- 在列线图界面,通过
Y设置因变量,通过X多选框来选择自变量名称。点击Submit。
- Simple Nomogram,针对建模集数据进行列线图绘制。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Various Nomogram,针对建模集数据进行列线图绘制。右侧参数可进行图形的线条类型、粗细、颜色、坐标轴等个性化设置。图形可导出本地。导出时高度与宽度根据具体设置合适大小。

- Variable Score,针对建模集数据进行列线图分析,得到每一个变量的评分。


- Total Score,针对建模集数据进行列线图分析,得到建模集、测试集的评分以及预测概率。结果可以表格形式下载本地。

16 Bootstrap & CV
针对列线图构建的模型进行Bootstrap & CV验证。针对的是建模集自身。
- 菜单界面

- 自动输出LGOCV的验证结果,勾选
roc将返回AUC、灵敏度、特异度结果;不勾选roc将返回准确率结果。
- 自动输出K-fold的验证结果,勾选
roc将返回AUC、灵敏度、特异度结果;不勾选roc将返回准确率结果。
- 自动输出LOOCV的验证结果,勾选
roc将返回AUC、灵敏度、特异度结果;不勾选roc将返回准确率结果。
- 自动输出K-fold的验证结果,勾选
roc将返回AUC、灵敏度、特异度结果;不勾选roc将返回准确率结果。
17 ROC 曲线绘制
可以自动进行训练集和验证集的 ROC 曲线绘制。ROC 曲线的颜色、线条、坐标轴等可进行个性化设置。
- 在菜单界面点击
ROC-plots,切换到绘制 ROC 曲线界面。
- Simple ROC-train,针对建模集数据进行ROC绘制。可通过参数对图形的颜色、线条等进行个性化设置。

- Simple ROC-test,利用建模集模型在测试集数据上进行ROC。可通过参数对图形的颜色、线条等进行个性化设置。

- Simple ROC Train & Test,将建模集ROC、测试集ROC绘制在同一图形上。可通过参数对图形的颜色、线条等进行个性化设置。

- Complex ROC-train,针对建模集数据进行ROC绘制。可通过参数对图形的颜色、线条等进行个性化设置。

- Complex ROC-test,利用建模集模型在测试集数据上进行ROC。可通过参数对图形的颜色、线条等进行个性化设置。

- Complex ROC Train & Test,将建模集ROC、测试集ROC绘制在同一图形上。可通过参数对图形的颜色、线条等进行个性化设置。

- CI ROC-train,针对建模集数据进行bootstrap ROC绘制。可通过参数对图形的颜色、线条等进行个性化设置。

- CI ROC-test,利用建模集模型在测试集数据上进行bootstrap ROC。可通过参数对图形的颜色、线条等进行个性化设置。

- CI ROCTrain & Test,将建模集ROC、测试集bootstrap ROC绘制在同一图形上。可通过参数对图形的颜色、线条等进行个性化设置。

- 同时也可绘制PR图形。可通过参数对图形的颜色、线条等进行个性化设置。




- 输出训练集的的 ROC 曲线各个指标数值大小。

- 输出验证集的的 ROC 曲线各个指标数值大小。

18 校准曲线绘制
可以自动进行训练集和验证集的校准曲线绘制以及 C 指数的计算。校准曲线的颜色、线条、坐标轴等可进行个性化设置。
- 在菜单界面点击
Calibration-plots,切换到绘制校准曲线界面。
- Simple CAL-train,针对建模集数据进行CAL绘制。结果可以pdf形式下载本地。

- Complex CAL-train,针对建模集数据进行CAL绘制。结果可以pdf形式下载本地。

- Simple CAL-test,利用建模集模型在测试集数据上进行CAL。结果可以pdf形式下载本地。

- Complex CAL-test,利用建模集模型在测试集数据上进行CAL。结果可以pdf形式下载本地。
部分结果如下:
- 训练集、验证集的C指数及其可信区间,bootstrap校正C指数。

- 训练集的HL拟合优度检验

- 验证集的HL拟合优度检验

19 DCA 曲线绘制
可以自动进行训练集和验证集的DCA 曲线绘制,以及净收益的计算。DCA 曲线的颜色、线条、坐标轴等可进行个性化设置。
- 在菜单界面点击
DCA-plots,切换到绘制 DCA 曲线界面。

- Standardize DCA-train,针对建模集数据进行标准化净获益率DCA绘制。

- Standardize DCA-train,利用建模集模型在测试集数据上进行标准化净获益率DCA。

- Standardize DCA-Train & test,利用建模集、测试集进行标准化净获益率DCA绘制在同一幅图上。

- Unstandardize DCA-train,针对建模集数据进行非标准化净获益率DCA绘制

- Unstandardize DCA-train,利用建模集模型在测试集数据上进行非标准化净获益率DCA。

- Unstandardize DCA-Train & test,利用建模集、测试集进行非标准化净获益率DCA绘制在同一幅图上。

- CIC-train,针对建模集数据进行CIC绘制。

- CIC-test,利用建模集模型在测试集数据上进行CIC绘制。

- 分别输出建模集、验证集的DCA曲线的数值结果。


20 NRI、IDI 计算
可以自动进行训练集和验证集的 NRI、IDI 指标。
- 在菜单界面点击
NRI&IDI,切换到计算 NRI、IDI 界面。在弹出的界面,通过Y设置因变量,通过Model New多选框来选择旧模型的自变量名称。通过Model New多选框来选择新模型的自变量名称。通过cutoff:来选择模型概率的截断值。点击Submit
- Train-cat NRI,针对建模集数据,计算新旧模型的cat NRI

- Train-cont NRI,针对建模集数据,计算新旧模型的cont NRI

- Train-IDI,针对建模集数据,计算新旧模型的IDI,其中 M1 表示 IDI M2 表示 NRI M3 表示中位数差异。

- Test-cat NRI,针对测试集数据,计算新旧模型的cat NRI

- Test-cont NRI,针对测试集数据,计算新旧模型的cont NRI

Test-IDI,针对测试集数据,计算新旧模型的IDI,其中 M1 表示 IDI M2 表示 NRI M3 表示中位数差异。

21 多模型
可进行最多20个模型的ROC、CAL、DCA图形绘制,并可对多个模型的ROC进行两两delong检验,比较其AUC是否有差异。
- 多模型菜单界面

- 多模型操作界面

- 建模集的多模型ROC曲线

- 建模集的多模型ROC曲线进行两两比较

- 验证集的多模型ROC曲线

- 验证集的多模型ROC曲线进行两两比较

- 建模集的多模型校准曲线

- 验证集的多模型校准曲线

- 建模集的多模型bootstrap校正的校准曲线

- 验证集的多模型bootstrap校正的校准曲线

- 建模集的多模型非标准化的DCA校准曲线

- 验证集的多模型非标准化的DCA校准曲线

- 建模集的多模型标准化的DCA校准曲线

- 验证集的多模型标准化的DCA校准曲线

22 交互作用
- 交互作用菜单界面

- 交互作用操作界面

- 相乘交互作用

- 相加交互作用

23 Curve
- Logistic Curve菜单界面

- Logistic Curve操作界面

- Logistic Curve图形,可个性化设置颜色、线条等。

24 亚组分析
- 亚组分析菜单界面

- 亚组分析操作界面

- 组分析结果

25 RCS
绘制限制性立方样条图,可个性化设置图形颜色、线条等。
- 限制性立方样条图菜单界面

- 限制性立方样条图操作界面

- 绘制几幅不同风格的限制性立方样条图




联系方式
傻瓜式零代码临床预测模型
加我微信 859929351,获取软件。 ——大鹏
![个人微信号859929351,非机器人]()
本文由mdnice多平台发布