论文阅读 - Large-scale weakly-supervised pre-training for video action recognition
文章目录
- 1 概述
- 2 数据的收集方式
- 3 使用的模型
- 4 预训练时的一系列问题
-
- 4.1 预训练的数据是不是越多越好?
- 4.2 用于预训练的模型是不是越大越好?
- 4.3 预训练数据的标签种类和数量是不是越多越好?
- 4.4 用于预训练的每个video有长有短,时长该如何选取?
- 5 总结
1 概述
本文是对论文Large-scale weakly-supervised pre-training for video action recognition的阅读笔记。在视频领域,一直没有一个像图像中ImageNet那样的标准,庞大且适用于各种下游任务的预训练数据集。这篇文章就是提出了一种构建video action recognition这一任务的预训练数据集的制作方法。因为预训练这种操作,是只要有大佬用N机N卡在N大的数据集上花N天训练好之后分享出来,我们一机一卡的老百姓就可以直接拿过来finetune一下提升自己任务的指标了,所以是非常实惠的一个东西。这么好的东西,自然要记录并分享一下。
代码可见:microsoft/computervision-recipes
论文对预训练这件事抛出了几个问题,并根据他们的实验结果,自行解答了一下,本文第4节也会按这几个问题进行总结。
- 预训练的数据是不是越多越好?
- 用于预训练的模型是不是越大越好?
- 预训练数据的标签种类和数量是不是越多越好?
- 用于预训练的每个video有长有短,时长该如何选取?
2 数据的收集方式
论文当中的数据都是通过搜索的方式下载的网上的公开视频,因此只要有功夫,数据量可以一直大下去。搜索的时候是根据label去搜索的,而且也会对label的单词进行换位,尽可能搜索到所有相关的视频,比如在找label=“catching a fish"的视频时,也会去搜索"catch fish”,"fish catching"等等。这样收集到的数据必然有一个问题,就是会有很多的视频标签是错的,也就是一大堆脏数据,但这个问题不大,数据的多样性和庞大的数据量可以outdo这个影响。
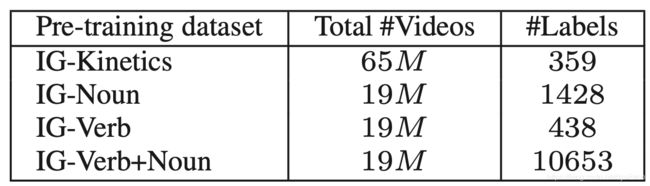
那么这些label是哪里来的呢?因为是预训练的模型,所以希望这个label涵盖的范围可以尽可能地大。文中有4中类型的label,分别是"IG-Kinetics",“IG-Noun”,“IG-Verb”,“IG-Verb+Noun”。"IG"不用管他,就是说明出自这篇文章的一个标识。"IG-Kinetics"的label来源于Kinetics-400数据集,共359个labels;"IG-Noun"的label来源于ImageNet-1K中的名词,共1428个labels;"IG-Verb"的label来源于"Kinetics"和"VerbNet"中的动词,共438个labels;"IG-Verb+Noun"的label来源于以上两个标签集中名词和动词的组合,共10653个labels。
3 使用的模型
使用什么模型并不是论文当中的重点,只要是能够测出预训练数据的变化对模型训练的影响就行,论文当中选取了R(2+1)D-d模型,其中 d d d表示模型的深度,可以是 { 18 , 34 , 101 , 152 } \{18, 34, 101, 152\} {18,34,101,152}。
训练时,虽然一个video可能有多个标签,但是按多标签的方法去训练的话,实验结果不佳,故论文用多类别的方式去训练的模型,也就是如果一个video有多个标签的话,每次从中随机选一个作为训练时的类别。
4 预训练时的一系列问题
4.1 预训练的数据是不是越多越好?
是的。
论文从"IG-Kinetics"中选取了6个子集,数据量的大小分别是 { 500 K , 1 M , 5 M , 10 M , 19 M , 65 M } \{500K, 1M, 5M, 10M, 19M, 65M\} {500K,1M,5M,10M,19M,65M},然后做预训练时候,分别在"Kinetics"和"Epic-Kitchens"上进行finetune,finetune采用了整个网络finetune(full-ft)和只finetune最后的全连接层(fc-only)两种方式。为了证明预训练有助于模型的训练,论文还用不用预训练的直接训练的模型结果作为baseline。
下图中,(a)是在"Kinetics"上finetune的结果,纵轴是top-1准确率,横轴是预训练用到的数量大小,其中的黄点(67.0)是baseline的准确率,该值和横轴无关。可见随着数据量的增大,准确率近似对数线性提升,相对baseline有较大提升。同时也可以发现,full-ft的准确率更高,但随着数据量的增大,fc-only的准确率慢慢逼近full-ft。
(b)是在"Epic-Kitchens"上finetune的结果,纵轴是mAP,横轴是预训练用到的数量大小,其中的黄点(12.3)是baseline的准确率,该值和横轴无关。其结论与(a)类似。不过full-ft的结果会比fc-only一直好很多。
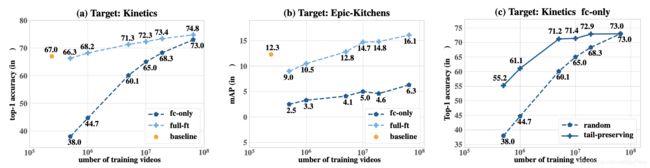
在预训练的数据集中,有很多长尾的标签,图©对采集预训练数据时的方式进行了对比。虚线是随机采样的数据训练得到的结果,实线是把长尾类别的videos都保留训练得到的结果,在fc-only上,保留长尾数据有明显更好的效果。当数据量增大时,随机采样和保留长尾的采样数据越来越接近,训练结果也就越来越接近。
4.2 用于预训练的模型是不是越大越好?
一定程度上,是的。
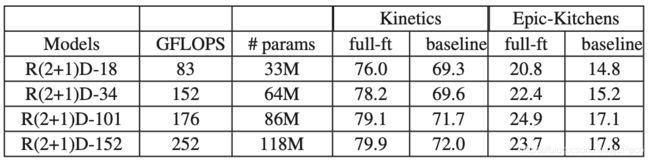
这里的大,指的是模型的层数越来越多。下表就是论文在"IG-Kinetics-65M"上用 d = { 18 , 34 , 101 , 152 } d=\{18, 34, 101, 152\} d={18,34,101,152}训练得到的结果。可见随着模型越来越深,准确率也越来越高。但我们也可以看到在"Epic-Kitchens"上, 101 101 101的准确率要高于 152 152 152的准确率。论文认为是数据量限制了大模型的效果,不过这也是猜测而已,尚待深究。当然,大模型消耗的资源更多,速度也更慢,这是一个trade-off,现在来看, R ( 2 + 1 ) D − 101 R(2+1)D-101 R(2+1)D−101是个不错的选择。
4.3 预训练数据的标签种类和数量是不是越多越好?
标签种类和目标数据集标签种类越一致越好,数量越多并不一定好,标签的多样性和数量同时增长才好。
下图是论文用"IG-Kinetics",“IG-Noun”,“IG-Verb”,“IG-Verb+Noun"分别作为预训练数据,然后在"Kinetics”,“Epic-Kitches-Noun”,"Epic-Kitchens-Verb"和"Epic-Kitchens-Action"上finetune得到的结果。同时也用了"Sports-1M"和"Kinetics"作为预训练数据,把其结果作为baseline参考。
可以观察到(a)中的"Kinetics",在"IG-Kinetics"数据集上预训练后得到的结果最好,(b)中的"Epic-Kitches-Noun"在"IG-Noun"上的结果最好,©和(d)也是如此,都是在和自己label最接近的预训练数据集上的表现最好。但是"IG-Noun-Verb"里什么label都有呀,为没有其他的好呢?论文认为是标签分布不均匀导致的。
总之,预训练的标签和目标数据集的标签越一致越好。

论文还进行了另两个实验,就是固定预训练数据集的总量,改变其中标签的数量。当标签数量比目标数据集标签数量大时,随着标签数量的增加,提升的效果一下子就饱和了;当标签数量比目标数据集小时,则随着标签数量的增加,准确率也近似线性提升。

4.4 用于预训练的每个video有长有短,时长该如何选取?
视频数量固定时,长视频更有利;视频总时长固定时,短视频更有利。
通过搜索得到的视频长短是不齐的,长的视频中并不一定是整个视频都和标签相对应的,这就引入了temporal noise,但长视频同时也有更多但visual diversity,这就是个trade-off。
论文把"IG-Kinetics"拆成了3份,分别是
- short-N: N个时长在1-5秒的短视频
- long-N: N个时长在55-60秒的长视频
- long-center-N: N个截取long-N中视频的中间4秒得到的视频
论文先是固定了每份中视频的总数量,然后分别预训练后得到结果,发现都是长视频的效果更好,见下表F1。论文又固定了视频的总时长,然后预训练后得到结果,发现都是短视频的效果更好。真实情况下,还是要我们自行判断。我个人认为,都是短视频就可以了。

5 总结
Large-scale weakly-supervised pre-training for video action recognition主要讨论了预训练这件事,给我们自己做项目提升模型性能提供了一个“便宜”的方法。