树形结构在关系数据库中的设计
在程序设计中,经常以树形结构表示数据的层次关系,如菜单的结构、商品的分类等。
这样的层次结构在关系数据库中难以直观地表示。常见的一种做法是用一个字段指向上级节点来表示记录的上下级关系。
| fid | pid | fname |
| 1 | Food | |
| 2 | 1 | Fruit |
| 3 | 2 | Red |
| 4 | 3 | Cherry |
| 5 | 2 | Yellow |
| 6 | 5 | Banana |
| 7 | 1 | Meat |
| 8 | 7 | Beef |
| 9 | 7 | Pork |
当要查询某一节点的上一级节点,比如 Beff,可以查询 Beff(pid=7) 指向的那条记录。
SELECT * FROM food WHERE fid = 7;
当要查询某一节点的下一级节点,比如 Fruit,可以查询 pid 指向 Fruit(fid=2) 的记录。
SELECT * FROM food WHERE pid = 2;
另有一种基于左右值编码的设计,这种设计方式的表结构如下:
| fid | fname | lft | rgt |
| 1 | Food | 1 | 18 |
| 2 | Fruit | 2 | 11 |
| 3 | Red | 3 | 6 |
| 4 | Cherry | 4 | 5 |
| 5 | Yellow | 7 | 10 |
| 6 | Banana | 8 | 9 |
| 7 | Meat | 12 | 17 |
| 8 | Beef | 13 | 14 |
| 9 | Pork | 15 | 16 |
fid 跟节点的层次完全没有关系,仅仅用来标识节点。引入了左右值来表示节点之间的关系,如下图所示。
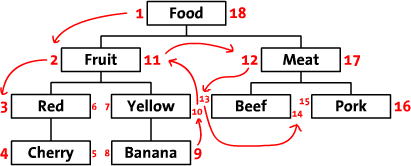
这样的设计能够方便地遍历一棵树,从左值数到右值便是先序遍历了一棵(子)树。更多详细的设计,参见 http://www.sitepoint.com/hierarchical-data-database/ 和 http://blog.csdn.net/monkey_d_meng/article/details/6647488
最后一种自己想到的设计:用字符串 str 来标识节点,并约定标识其上级节点的字符串为 substr(str, 1, length(str)-1)。例如,有一节点的以 "abc" 标识,则其上级节点以 "ab" 标识。
| fid | fname |
| a | Food |
| aa | Fruit |
| aaa | Red |
| aaaa | Cherry |
| aab | Yellow |
| aaba | Banana |
| ab | Meat |
| aba | Beef |
| abb | Pork |
当要查询某一节点的上一级节点,比如 Beff,因为 Beff 的 fid 为 "aba", 所以其上级节点的 fid 为 "ab"。
SELECT * FROM food WHERE fid = 'ab';
当要查询某一节点的路径,比如 Beff,因为 Beff 的 fid 为 "aba",所有其路径为 a/ab/aba。
SELECT * FROM food WHERE fid IN ('a', 'ab', 'aba') ORDER BY fid;
当要查询某一节点的下一级节点,比如 Fruit,因为 Fruit 的 fid 为 "aa",所以其下一级节点的 fid 是以 "aa" 开头且比 "aa" 多一个字符的字符串。
SELECT * FROM food WHERE fid LIKE 'aa_';
当要查询某一节点的所有下级节点,比如 Fruit,因为 Fruit 的 fid 为 "aa",所以其所有下级节点的 fid 是以 "aa" 开头的字符串。
SELECT * FROM food WHERE fid LIKE 'aa%' AND fid != 'aa';
总结
第一种设计方式, 直观方便,但是在对树的遍历过程中需要递归查询,数据量大时,对效率的影响很大。这种设计适合的场景:1) 数据量不大的时候; 2) 只会经常查询节点的下一级节点而不会频繁查询节点的所有下级节点。
基于左右值编码的设计方式,消除了遍历树时的递归操作,查询效率高,但是设计较为复杂,增删节点的代价较大。
第三种设计方式,同样删除了遍历树是的递归操作,无论是广度优先搜索(ORDER BY LENGTH(fid))还是深度优先搜索(ORDER BY fid),都极为方便。这种设计在增删节点时会影响着节点的所有下级节点的标识编码。这种设计方式适合的场景:1) 树形结构基本稳定,很少需要对其增删节点; 2) 需要频繁地查询某个节点的所有下级节点。