k8s组件理解
一、k8s组件交互关系由下图可大致体现
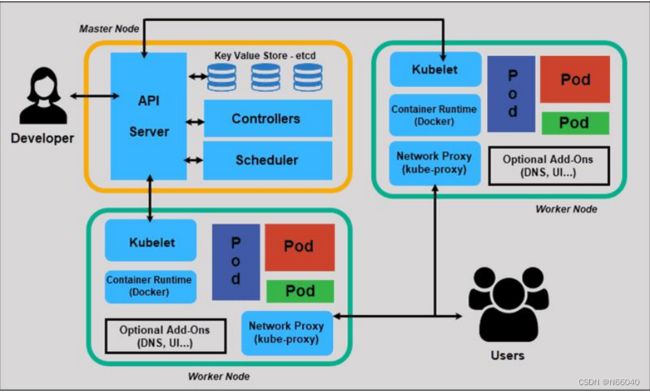
二、k8s master组件理解
(1)kube-apiserver组件:
kube-apiserver | Kubernetes
kubernets API server 提供了k8s各类资源对象的增删改查及watch等Http Rest接口,这些对象包括pods、services、relicationcontrollers等,API server为REST操作提供服务,并为集群共享状供前端,所有的其他k8s组件(kube-scheduler、kube-controllermanager、kube-proxy、kubelet)都通过该前端进行交互。 kubectl 命令行管理工具也需要apiserver去交互。etcd也只会和apiserver进行交互。可以说apiserver是我们所有的服务访问入口,在整个k8s集群是非常繁忙的,所以比较消耗CPU资源,对内存需要倒是不多。
和apiserver交互要经历如下步骤:
1.身份认证
2.验证指令
3.验证操作鉴权
4.返回结果
举个kubectl和apisever交互的例子
执行kubectl get node命令会出现如下图信息

我们会看到集群节点名字、状态、角色、运行时长、版本。apiserver 验证信息记录在我们管理员文件/root/.kube/config里。如图
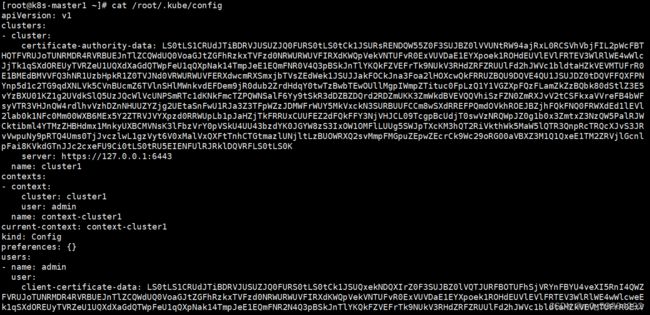
当我们去执行这条命令会向apiserver请求交互。交互的地址在我们的/root/.kube/config文件的server值的地址,也就是我们apiserver地址。admin用户一般是定义为作为集群管理员用户,一般clusterrolebinding 绑定集群内置最高的用户角色权限(所有权限),所以kubectl 才能有权限进行增删改查操作。kubectl向apiserver 发起操作请求后,apiserver验证admin用的客户端证书,如果发现这个证书是由集群的ca颁发的签证,则会通过身份认证。然后验证指令的合法性,验证是否符合apiVersion的资源类型,符合后,还验证是否有该操作权限,kubectl get node 操作是需要get权限的。admin用户是拥有查看的权限的,所以验证操作权限通过。 接下来apiserver会去向etcd交互获取我们所查询的结果,并由apiserver将结果返回终端回显。
注意: 上述涉及所有验证操作和返回结果都是apiserver通过etcd交互完成的。
(2)kube-scheduler组件
1.通过调度算法为待调度pod列表的每个pod从可用的node列表中选择一个最合适的node,并调用apiserver将信息写入etcd中。
2.node节点上的kubelet通过apiserver监听到kubernetes Scheduler产生的pod绑定信息,然后获取对应得pod清单,下载image,并启动容器。
3.策略:
3.1 LeastRequestedPrority
优先从备选节点中选择资源消耗最小的节点(cpu+内存)
3.2 CalculateNodeLabelPriority
优先选择含有指定Lable的节点
3.3 BalanceResourceAllocation
优先从备节点列表中选择各项资源使用率最均衡的节点
先排除不符合条件的节点,在剩下节点中选出最符合条件的节点。可以说scheduler有个评分机制,node得分高的优先选择,若得分一样则随机选择一个node去运行pod。
(3)kube-crontrollermanager组件
维持 pod 副本的期望数,是我们 K8S 中的重要组件,Controller Manager还包括一些子控制器(副本控制器、节点控制器、命名空间控制器和服务账号控制器等),控制器作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个 Node 意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群中的pod副本始终处于预期的工作状态。
• controller-manager 控制器每间隔5秒检查一次节点的状态。
• 如果 controller-manager 控制器没有收到自节点的心跳,则将该node节点被标记为不可达。
• controller-manager将在标记为无法访问之前等待40秒。
• 如果该 node节点被标记为无法访问后5分钟还没有恢复,controller-manager会删除当前
• node节点的所有pod并在其它可用节点重建这些pod。
pod 高可用机制:
• node monitor period:节点监视周期每隔 5 秒一次
• node monitor grace period:节点监视器宽限期,也就是说超过 40 秒 node 不恢复的话就会把他标记为不可用
• pod eviction timeout:pod驱逐超时时间,然后再等 5 分钟将 pod 驱除至可用节点并进行重建
三、k8s node组件理解
(1)kube-proxy组件
kube-proxy运行在每个节点上,监听 API Server 中服务对象的变化,再通过管理 IPtables 或者IPVS 规则 来实现网络的转发。负责写入我们的规则至 iptables 、或者是 ipvs 实现服务映射访问的
Kube-Proxy 不同的版本可支持三种工作模式:
• UserSpace:k8s v1.1之前使用,k8s 1.2及以后就已经淘汰
• IPtables : k8s 1.1版本开始支持,1.2开始为默认
• IPVS: k8s 1.9引入到1.11为正式版本,需要安装ipvsadm、ipset 工具包和加载 ip_vs 内 核模块
IPVS 相对 IPtables 效率会更高一些,因为ipvs 工作内核层,而IPtable是工作在应用层。当然使用IPVS模式时也是要调用IPtables做规则转发的,所以ipvs也是依赖IPtables的。用 IPVS 模式需要在运行 Kube-Proxy 的节点上安装 ipvsadm、ipset 工具包和加载 ip_vs 内核模块,当 Kube-Proxy 以 IPVS 代理模式启动时,Kube-Proxy 将验证节点上是否安装了 IPVS 模块,如果未安装,则 Kube-Proxy 将回退到 IPtables 代理模式
使用IPVS模式,Kube-Proxy会监视 Kubernetes Service 对象和 Endpoints,调用宿主机内核 Netlink 接口以相应地创建 IPVS 规则并定期与 Kubernetes Service 对象 Endpoints 对象同步 IPVS 规则,以确保 IPVS 状态与期望一致,访问服务时,流量将被重定向到其中一个后端 Pod,IPVS 使 用哈希表作为底层数据结构并在内核空间中工作,这意味着 IPVS 可以更快地重定向流量,并且在同步代理规则时具有更好的性能,此外,IPVS 为负载均衡算法提供了更多选项,例如:rr (轮询调度)、lc (最小连接数)、dh (目标哈希)、sh (源哈希)、sed (最短期望延迟)、nq(不排队调度)等。
(2)kubelet组件
Kubelet直接跟 docker 或者容器引擎交互实现容器的生命周期管理,可以这样理解 kubelet 接收到指令以后,先把我们K8S 发送过来的指令进行理解,理解完成以后再去把对应的指令直接转化我们的 container(容器)能够听懂的命令,并且让他去创建达到这么一个 pod 创建的流程。其实这个过程就是一个调用 container runc 的一个过程
由 api server 来分配任务,api server 会将任务写到 etcd 里面,kubelet 在通过 api server 拿到这些事件,然后再由 kube-scheduler 调度任务,最后在通过 kubelet 来执行这些任务
kubelet是运行在每个worker节点的代理组件,它会监视已分配给节点的pod,具体功能如下:
• 向 master 汇报 node 节点的状态信息
• 接受指令并在 Pod 中创建 docker 容器
• 准备 Pod 所需的数据卷
• 返回 pod 的运行状态
• node 节点执行容器健康检查
k8s集群已搭建完
