Docker Cgroup 子系统 CPU/Memory
去启动虚拟机的时候都会要求虚拟机多少资源,之前的namespace对用户的进程进行隔离了,放在了不同的namespace,互相不可见了,但是事实上都是主机fork出来的,运行在同一个操作系统里面的进程,如果不加以管控一定会出现一些问题。
会出现什么问题呢?比如写了一个应用里面有个bug是死循环,这样可能吃掉很多cpu,这样主机可能会变慢了。其他的应用就会受到影响了。还有或者应用内存泄露,那么吃掉了宿主机上面的很多内存,这样主机就整个都不能访问了,因为可能没有内存了。还有磁盘空间也是类似。
除了给容器提供封闭的环境之外,还要做一件事情就是资源管控,比如cpu和内存。
Cgroups
cgroup也分不同的子系统,这些不同的子系统会控制不同的资源,这些资源在cgroup里面叫做subsystem,就是不同的子系统。
cgroup如何去管理进程的,因为进程是树状结构,一个进程会fork出很多的其他进程,cgroup也用了类似的层级结构,也就是(Hierarchy)的方式来组织管理,
- Cgroups (Control Groups)是 Linux 下用于对一个或一组进程进行资源控制和监控的机制
- 可以对诸如 CPU 使用时间、内存、磁盘 I/O 等进程所需的资源进行限制
- 不同资源的具体管理工作由相应的 Cgroup 子系统(Subsystem)来实现
- 针对不同类型的资源限制,只要将限制策略在不同的的子系统上进行关联即可
- Cgroups 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个Cgroup 都可以包含其他的子 Cgroup,因此子 Cgroup 能使用的资源除了受本 Cgroup 配置的资源参数限制,还受到父 Cgroup 设置的资源限制 。
cgroup有不同的子系统,cpu是一个子系统,如果要管控cpu那么是使用cpu的子系统。如果要管控进程的内存,它是用内存子系统去管控的。
Cgroup是怎么管理的?以树状结构去管理的。
Linux 内核代码中 Cgroups 的实现

同样task_struct里面也有css_set这个结构体,这个结构体是用来描述,这个进程所在从group的一个状态的情况。(cgroup也是task_struct里面一个重要的属性)
可配额/可度量 - Control Groups (cgroups)
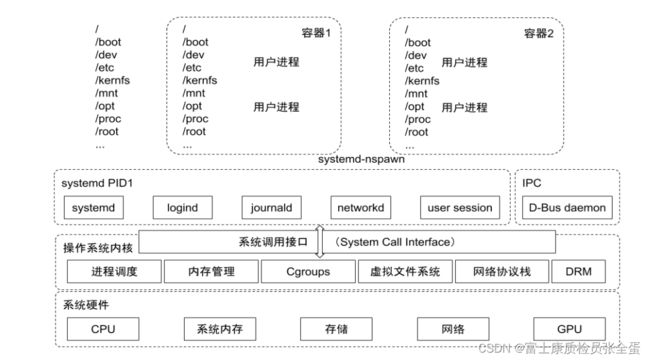
最下面是系统的硬件,在此之上是操作系统内核,它包含了cgroup。内核和用户空间是通过系统调用来调用的。任何操作系统都会有一个初始化的进程,如systemd,对于任何的容器进程都是由systemd fork出来的子进程再fork出来的。
可配额/可度量 - Control Groups (cgroups)
cgroups 实现了对资源的配额和度量。
- blkio:这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 USB 等
- cpu:这个子系统使用调度程序为 cgroup 任务提供 CPU 的访问
- cpuacct:产生 cgroup 任务的 CPU 资源报告
- cpuset:如果是多核心的CPU,这个子系统会为 cgroup 任务分配单独的 CPU 和内存(应用进程可以和cpu做绑定关系,比如说希望某些应用就绑在某个核上)(如果是多核的cpu,可以将某个进程绑定到某个cpu核上面,这样就减少进程的切换了,那么它的TLB表和缓存,都是可以永远复用的,那么你这个程序就可以高效)
- devices:允许或拒绝 cgroup 任务对设备的访问
- freezer:暂停和恢复 cgroup 任务
- memory:设置每个 cgroup 的内存限制以及产生内存资源报告
- net_cls:标记每个网络包以供 cgroup 方便使用
- ns:名称空间子系统
- pid: 进程标识子系统。
CPU 子系统


- cpu.shares 相对值:可出让的能获得 CPU 使用时间的相对值。(假设主机上面有3个cpu,定义了两个cgroup,将第一个进程放到第一个cgroup,将第二个进程放到第二个cgroup,将第一个进程里面的cpu设置为512,将第二个进程里面的cpu设置为1024,那么这就是1:2的比例,这样意味着操作系统在调用这些进程的时候对时间的分配是按照1:2去分配的,这是一个相对值,按照cpu占用时间去分配的)
- cpu.cfs_period_us 绝对值:cfs_period_us 用来配置时间周期长度,单位为 us(微秒)。
- cpu.cfs_quota_us:cfs_quota_us 用来配置当前 Cgroup 在 cfs_period_us 时间内最多能使用的 CPU时间数,单位为 us(微秒)。(绝对值是按照两个文件去配置的,一个文件叫做cpu.cfs_period_us,另外一个叫做cpu.cfs_quota_us,在10w的cpu时间片里面,可以使用多少个时间片)
- cpu.stat :Cgroup 内的进程使用的 CPU 时间统计。
- nr_periods :经过 cpu.cfs_period_us 的时间周期数量。
- nr_throttled :在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。
- throttled_time :Cgroup 中的进程被限制使用 CPU 的总用时,单位是 ns(纳秒)。
cpu share和cpu qutoa区别:cpu share定义的是相对值,相对值意味着有人竞争的时候,大家就按照这个百分比去划分,如果没有人竞争就可以一直使用,B group里面的进程虽然使用了2/3的时间片,但是里面什么都没有跑,没有耗费任何cpu,那么A就可以将所有cpu吃掉。
但是绝对时间,给你设置了0.1的cpu,你就不可能超过它。
可以看到不同的子系统
[root@docker ~]# cd /sys/fs/cgroup/
[root@docker cgroup]# ls
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids rdma systemdcpu子系统当中的配置,这些配置是用来配置目录下面的进程能够使用多少cpu的
[root@docker cgroup]# cd cpu
[root@docker cpu]# ls
cgroup.clone_children cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us cpu.shares notify_on_release tasks
cgroup.procs cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.rt_period_us cpu.stat release_agent user.slice
cgroup.sane_behavior cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.rt_runtime_us docker system.slicecpu.shares是一个相对值,约定一个cpu的相对值。假设有两个不同的文件目录,这个不同的文件目录里面都有cpu.shares。这个cpu.shares就是约定一个相对值,两个cgroup能够使用的cpu是几比几的,也就是比例。
[root@docker cpu]# cat cpu.shares
1024cpu.cfs_quota_us cpu.cfs_period_us 这两个文件是用来控制一个进程使用cpu的绝对值。
cpu.cfs_period_us:可以简单理解为cpu的时间片
cpu.cfs_quota_us:是指在这么多时间片下面,我能够使用多少cpu
[root@master cpu]# cat cpu.cfs_quota_us cpu.cfs_period_us
-1
100000实战 Cgroup对CPU限制
在cpu子系统下面创建一个demo。之前所说的文件都会被创建出来。
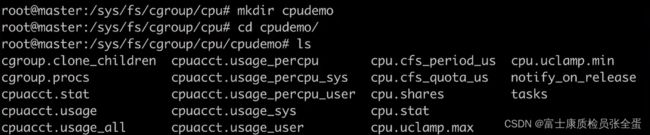
这里有个程序,里面就是跑着死循环,吃cpu资源,现在运行这个程序。
可以看到占用了200%的cpu,如果有这种的应用就会将内存白白吃光了,这是非常危险的,因为没有独立的操作系统。
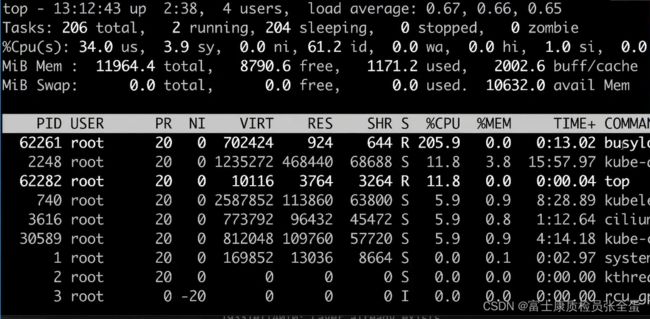
有什么办法来控制呢?这个进程的PID是62261,要通过cgroup去控制这个进程,怎么控制呢?
将这个进程cgroup.procs写入到这个文件告诉cgroup要控制的进程是哪个。
![]()
现在要控制cpu了,控制cpu的参数有两个,cpu.cfs_period_us cpu.cfs_quota_us ,死循环进程现在占用了两个cpu,-1代表不做任何的资源限制。现在设置为100000,也就是使用一个cpu。

可以看到cpu降下去了,只使用了一个cpu。设置为10000的意思呢?
现在cpu.cfs_period_us cpu.cfs_quota_us是相等的,意味着在100000个cpu时间片里面,被控制的进程能够拿到100000个cpu时间片,也就是能够拿到1个cpu。
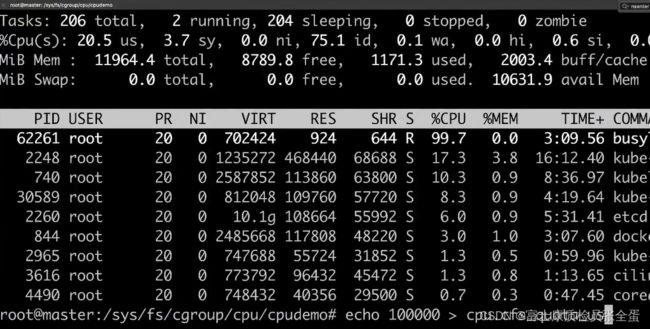
通过这种方式,控制了这个进程使用的cpu。
cpu这种资源叫做可压缩资源,本来程序是消耗两个cpu的,但是给你一个cpu你也可以跑,但是这样程序一定会慢下来,所以在做容器化的时候,本来应用进程跑的好好的,突然部署到某一个地方发现慢了,发一个request就timeout了,这就得看看进程的cpu是不是给少了。
还有一种是不可压缩资源,比如内存。
可不可以在容器当中看cpu资源的使用率呢,进入到容器里面按top是不行的,看到的是主机的top,所以你要在容器里面通过top,通过cpuinfo,memifo来看资源利用率是不行的。
cpuacct 子系统
如果要看cpu怎么看呢? 通过cgroup cpu子系统的cpuacct去查看,这里面会告诉你cpu的使用情况。
[root@docker cpu]# cat cpuacct.usage
5666263771
[root@docker cpu]# cat cpuacct.stat
user 191
system 340用于统计 Cgroup 及其子 Cgroup 下进程的 CPU 的使用情况。
- cpuacct.usage
- cpuacct.stat
Memory 子系统
memory.usage_in_bytes
- cgroup 下进程使用的内存,包含cgroup 及其子 cgroup下的进程使用的内存
memory.max_usage_in_bytes
- Cgroup下进程使用内存的最大值,包含子cgroup 的内存使用量。
memory.limit_in_bytes
- 设置Cgroup 下进程最多能使用的内存。如果设置为-1,表示对该cgroup 的内存使用不做限制。
memory.oom_Control
- 设置是否在 Cgroup中使用 OOM(Out of Memory)Killer,默认为使用。当属于该cgroup的进程使用的内存超过最大的限定值时,会立刻被 OOM Killer 处理。
操作系统的资源像cpu这种资源,是可压缩资源,虽然我这个进程很忙,可能需要两个cpu,但是给他0.1个cpu也是ok的,只不过进程会变慢,但是内存不一样,内存给其限制了,那么超出的内存在做内存申请的时候就申请不出来,导致OOM。

Cgroup driver
上面可以看到cgroup是通过一系列的文件来管控所有的资源分配的,包括创建了一个cgroup,同时将一个cgroup和这个进程进行关联,也就是将进程号echo到那个procs文件里面,同时修改cpu的quota来限制其使用的资源,这一整套都是cgroup的文件系统,cgroup本身可以有不同的driver。
- SyStemd:(整个操作系统是使用了systemd cgroup driver,当使用kubernetes的时候,要将两者统一,如果其他进程是使用systemd拉起来的,systemd拉起来的那些进程就由systemd这套系统去管控的,docker拉起的进程是由cgroupfs这套系统去管控的,这就会出现同一套资源被两套系统往外分,当系统压力大的时候就会引发不必要的问题,所以kubernetes在启动的时候会做一些检查,在启动kubelet的时候,去判断docker使用了哪一个cgroup driver,如果docker本身不是使用systemd,那么它就会默认报错不启动)
当操作系统使用systemd作为init system时,初始化进程生成一个根cgroup目录结构并作为cgroup管理器。
systemd与cgroup紧密结合,并且为每个systemd unit分配cgroup。
- cgroupfs:
docker默认用cgroupfs作为cgroup驱动。
存在问题∶
- 因此,在systemd作为init system的系统中,默认并存着两套groupdriver。
- 这会似的系统中docker和kubelet管理的进程被cgroupfs驱动管,而systemd拉起的服务由systemd驱动管,让cgroup管理混乱且容易在资源紧张时引发问题。
因此kubelet会默认--cgroup-driver=systemd,若运行时cgroup不一致时,kubelet会报错
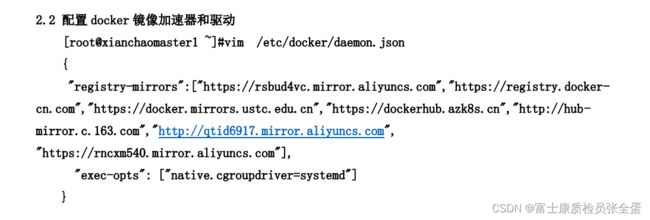
所以在搭建kubrnetes集群的时候,你往往需要去修改docker本身的cgroup driver,那么kubelet才能够启动起来。
总结
实现了在主机上面启动的进程,但是通过cgroup控制使用多少资源,就算你程序有bug也是不能多使用资源。