【问题记录】面试官经常问:你在工作中遇到过什么比较难问题吗?(持续更新)
文章目录
-
- 序章
- Kafka服务端报错:Too many open files
- Docker报错:OCI runtime create failed
- Redis报错:NOAUTH Authentication required
- RocketMQ报错:MQClientException: No route info for this topic
序章
面试的时候,经常会有面试官会问道:你在工作中遇到的比较有挑战的问题是什么?这时候大脑就飞速运转,从大脑随机持久化的记忆库(MemoryDB)中查询出经手过的大大中中小小项目,遍历,最后冥思苦想,发现好多已经记不起来了,有些问题,当时解决的时候可能很有成就感,但是,最后在MemoryDB中只会有些许碎片被持久化下来,甚至更糟。
SO,好记性不如烂笔头,从现在开始,把问题记录于此。
Kafka服务端报错:Too many open files
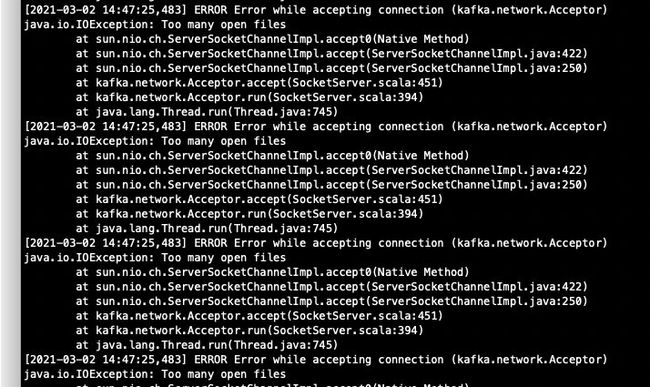
看到这个问题,首先想到的是打开的文件描述符超过了Linux的配置,所以排查过程如下:
查看Kafka进程占用的句柄:
命令:ls /proc/进程号/fd | wc -l
[root@m7-3-6-a1-09-26u-kafka01 logs]# ps -ef|grep kafka1
root 105508 1 7 Mar02 ? 05:27:46 /usr/local/jdk/bin/java -Xmx6G -Xms6G -server -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent -Xloggc:/bigdata/kafka1/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=9999 -Dkafka.logs.dir=/bigdata/kafka1/bin/../logs -Dlog4j.configuration=file:/bigdata/kafka1/bin/../etc/kafka/log4j.properties -cp .:/usr/local/jdk/lib:/usr/local/jdk/jre/lib::/bigdata/kafka1/bin/../share/java/kafka/*:/bigdata/kafka1/bin/../share/java/confluent-support-metrics/*:/usr/share/java/confluent-support-metrics/* -Djava.security.auth.login.config=/bigdata/confluent-4.1.2/etc/kafka/kafka_server_jaas.conf io.confluent.support.metrics.SupportedKafka /bigdata/kafka1/etc/kafka/server.properties
root 205698 204828 0 16:44 pts/0 00:00:00 grep --color=auto kafka1
[root@m7-3-6-a1-09-26u-kafka01 logs]#
[root@m7-3-6-a1-09-26u-kafka01 logs]# ls /proc/105508/fd | wc -l
9753
[root@m7-3-6-a1-09-26u-kafka01 logs]#
查看Linux配置的最大文件描述符打开限制
[root@m7-3-6-a1-09-26u-kafka01 ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 1540996
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 102536
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 1540996
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@m7-3-6-a1-09-26u-kafka01 ~]#
可以看到,Kafka打开的只有9000+,我Linux配置的限制是10W+,但是为什么会报错呢?
猜想:是否每个进程还有自己的限制呢?
于是百度查看进程open files限制的命令
[root@m7-3-6-a1-09-26u-kafka01 system]# cat /proc/105508/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 1540996 1540996 processes
Max open files 4096 4096 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 1540996 1540996 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
[root@m7-3-6-a1-09-26u-kafka01 system]#
果然,看到Max open files为4096
继续猜想,我的Kafka用了Systemd管理,和这个是否有关系呢?
于是礼貌性查看kafka1.service的文件和状态,
[root@m7-3-6-a1-09-26u-kafka01 system]# cat kafka1.service
[Unit]
Description=Apache Kafka Server Of Kafka1
Documentation=http://kafka.apache.org/documentation.html
After=network.target
[Service]
User=root
Group=root
Type=forking
WorkingDirectory=/bigdata/kafka1
ExecStart=/bigdata/kafka1/kafka-start.sh
ExecStop=/bigdata/kafka1/kafka-stop.sh
RestartSec=60
Restart=always
[Install]
WantedBy=multi-user.target
[root@m7-3-6-a1-09-26u-kafka01 system]#

并未看到关于open files的限制,百度是否可以配置systemd管理的应用对应的Max open files
经查找发现可以改,只需要在service文件中加入一行LimitNOFILE=102536,然后reload一下,重启即可
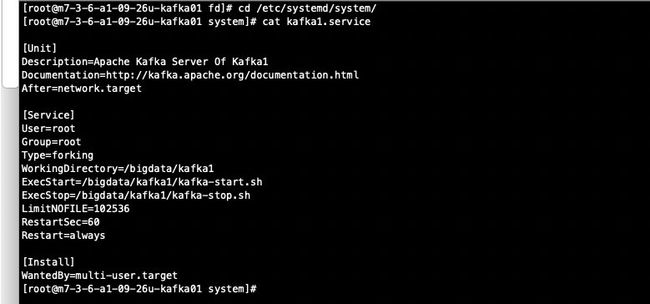
重启之后,查看当前进程的限制,已经改成了配置的102536
Kafka也不再报错了。
Docker报错:OCI runtime create failed
具体的错误信息如下:
OCI runtime create failed: container_linux.go:345: starting container process caused "process_linux.go:281: applying cgroup configuration for process caused \"mkdir /sys/fs/cgroup/memory/docker/0f6e4d298635b40648077c27d143942e2eb76db0c7e95c6a13c6f182dd1a982a: cannot allocate memory\"": unknown

这个错呢,查来查去,说是Linux内核版本和Docker版本不兼容的问题,于是我考虑升级一下Docker
升级就是先卸载,然后重新安装最新的,具体的方法如下:
https://www.runoob.com/docker/centos-docker-install.html
但是呢,我不管怎么升级,经过多次安装,发现我的Docker版本还是没变,我怀疑是卸载的时候没有把docker的脚本文件删除
[root@XXGL-T-TJSYZ-app-026 bin]# which docker
/opt/kube/bin/docker
[root@XXGL-T-TJSYZ-app-026 bin]#
然后我到了这个目录,把所有docker相关的文件都删了,重新安装,安装完之后,默认被安装到了以下路径
[root@XXGL-T-TJSYZ-app-026 bin]# cd /usr/bin/
[root@XXGL-T-TJSYZ-app-026 bin]# ll -h docker*
-rwxr-xr-x 1 root root 69M Mar 3 04:35 docker
-rwxr-xr-x 1 root root 112M Mar 3 04:33 dockerd
-rwxr-xr-x 1 root root 13K Mar 3 04:31 dockerd-rootless-setuptool.sh
-rwxr-xr-x 1 root root 3.9K Mar 3 04:31 dockerd-rootless.sh
-rwxr-xr-x 1 root root 830K Mar 3 04:33 docker-init
-rwxr-xr-x 1 root root 3.6M Mar 3 04:32 docker-proxy
[root@XXGL-T-TJSYZ-app-026 bin]#
这时候,我运行systemctl restart docker,以为成了,但是报错了,查看日志发现,没找到脚本,于是看了一下docker.service文件,里面脚本的路径还是之前的:
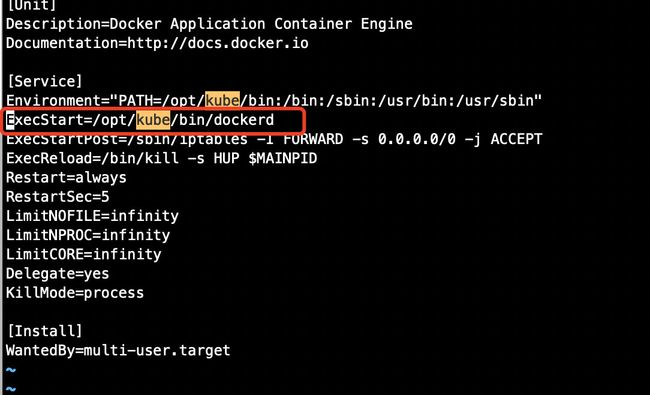
改成:/usr/bin/dockerd后,执行systemctl daemon-reload、systemctl restart docker。
我再试了一下,又来一个错,直呼好家伙
error adding content digest to lease: sha256:c1ff613e8ba25833d2e1940da0940c3824f03f802c449f3d1815a66b7f8c0e9d: unknown method AddResource: not implemented

经查阅,解决方法是:
sudo systemctl restart containerd.service
sudo systemctl restart docker
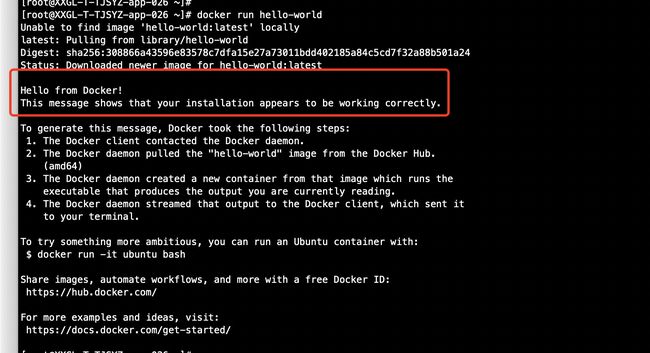
可以看到,已经OK了,如果还是不行,yum -y update升级内核,但是这个需谨慎操作,可能会导致其他应用或组件不兼容
Redis报错:NOAUTH Authentication required
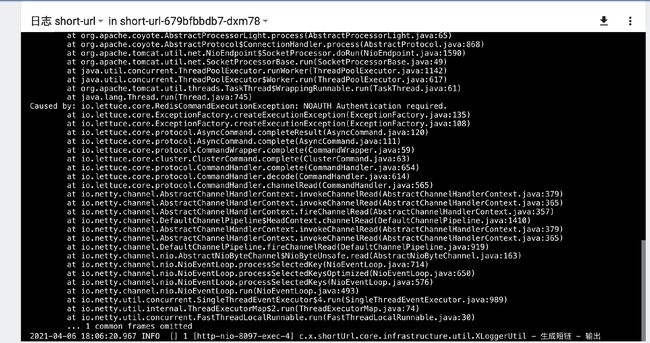
背景:问题发生在测试环境平稳运行的应用
这个错误,第一眼看来,很明确是redis服务端鉴权失败,服务端配置了密码,但是客户端使用的密码错误,但是并没有那么简单。
测试环境前几天运维的ceph出了问题,导致K8s里面应用大面积重启,其中包括了所有的redis集群,当时并没感觉到异常,慢慢有业务团队反映我们的服务报错了,很纳闷,应用一直跑得好好的,也没有改过代码,也没改过redis密码,所以首先排除了代码和配置的问题。
根据redis客户端的原理,做了以下猜测:
1、redis第一次连接集群,会随机连接集群中的一个节点,发送cluster node命令,拿到集群中所有节点;之后每次会随机请求一个节点(猜想);
2、K8s中的redis集群重启之后,所有pod的IP都会变,此时客户端会尝试刷新拓扑图;
3、此时如果之前客户端缓存的节点IP被其他集群使用了,就会出现这种情况,IP端口能连上,但是密码是其他集群的
为什么会出现这种情况呢?K8里面大面积应用重启,IP池有限,导致之前的集群IP被其他集群复用。
RocketMQ报错:MQClientException: No route info for this topic
背景:业务团队使用Canal做数据同步,使用到了RocketMQ,Canal部署在k8s中,RocketMQ部署在阿里云虚拟机。
- 报错信息是topic不存在,确定了topic没问题,怀疑网络问题
- k8s pod无法使用telnet,但是可以使用curl,确定了网络没问题,决定进一步抓包,确定数据是否有问题
- 抓包时,通过curl发送的请求,可以抓到包,但是通过canal发送过来的消息,抓不到包,怀疑canal的rmq版本和服务端不兼容
- 查看canal日志,发现报错,canal使用的客户端是4.5.2,查看了RocketMQ 4.5.2源码后发现:解析客户端nameserver配置的时候,会通过冒号截取IP和端口,也就是说只能配一个IP端口的地址,或者通过域名配置,高版本的客户端支持多个IP端口按分好分隔配置
- 修改成单个IP端口之后试验,问题解决