Flink学习笔记【巨详细!】(一)
一、Flink的简介
1.1 Flink的概述
Flink和Spark一样,是一个大数据处理引擎。主要区别在于Flink做的是流处理,Spark做的是批处理。

Flink处理的是无界的和有界的数据流,做有状态的计算。
1.1.1 Flink发展时间线:
- 2014 年 8 月,Flink 第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在
Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司,
主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。 - 2014 年 12 月,Flink 项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。
- 2015 年 4 月,Flink 发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这
时开始关注、并参与到 Flink 社区建设的。 - 2019 年 1 月,长期对 Flink 投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data
Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的 Flink 1.9.0
版本进行了合并。自此之后,Flink 被越来越多的人所熟知,成为当前最火的新一代
大数据处理框架。
Flink 的官网主页地址 https://flink.apache.org
1.1.2 Flink框架处理流程

flink框架处理流程图解
flink主要处理的是数据流,比方说网上有很多实时数据(交易、日志、物联网、点击流)要传输到控制中心做处理、响应。这些源源不断数据flink都是在不停的收集,另外这些数据可以存储到这些数据库、文件系统、键值存储,不管在哪里,flink都是实时读取,一直在做拉数据的操作,然后做各种类型的处理,比如说可以做事件驱动型的应用、可以做其他的流水线处理,后面还可以做流分析或者是批处理的分析(一批数据收集齐可以分析特征、提取特点、统计指标),这个处理过程是实时的,每来一个新的数据都可以得到对应的响应(因为它是事件驱动的)。最终它可以给应用程序做一个响应,也可以重新把它写入到事件日志里面去,也可以把处理的结果写入到数据库文件系统或者键值存储里面去,这就是flink流处理整体的框架
Flink是事件驱动,来一个新的事件就会响应。它从外部把实时数据读取进来,处理完之后,传给后面的程序或事件日志,文件系统等,相当于一个管道一样。(从不同的存储介质中读取数据,再写入到不同的存储介质
1.2 Flink 的应用
- Flink 是一个大数据流处理引擎,它可以为不同的行业提供大数据实时处理的解决方案。
随着 Flink 的快速发展完善,如今在世界范围许多公司都可以见到 Flink 的身影。 - 目前在全球范围内,北美、欧洲和金砖国家均是 Flink 的应用热门区域。当然,这些地区
其实也就是 IT、互联网行业较发达的地区。 - Flink 在国内热度尤其高,一方面是因为阿里的贡献和带头效应,另一方面也跟中国的应
用场景密切相关。中国的人口规模与互联网使用普及程度,决定了对大数据处理的速度要求越来越高,也迫使中国的互联网企业去追逐更高的数据处理效率。试想在中国,一个网站可能要面对数亿的日活用户、每秒数亿次的计算峰值,这对很多国外的公司来说是无法想象的。而Flink 恰好给我们高速准确的处理海量流式数据提供了可能。
1.2.1 Flink 在企业中的应用
- Flink 为全球许多公司和企业的关键业务应用提供了强大的支持。
- 对于数据处理而言,任何行业、任何公司的需求其实都是一样的:数据规模大、实时性要求高、确保结果准确、方便扩展、故障后可恢复——而这些要求,作为新一代大数据流式处理引擎的 Flink 统统可以满足!这也正是 Flink 在全世界范围得到广泛应用的原因。
- 以下是 Flink 官网列出的知名企业用户,如图 1-3 所示,他们在生产环境中有各种各样有趣的应用。
- 以大家熟悉的阿里为例。阿里巴巴这个庞大的电商公司,为买方和卖方提供了交易平台。它的个性化搜索和实时推荐功能就是通过 Blink 实现的(当然我们知道,Blink 就是基于 Flink的,现在两者也已合体)。用户所购买或者浏览的商品,可以被用作推荐的依据,这就是为什么我们经常发现“刚看过什么、网站就推出来了”。当用户数据量非常庞大时,快速地分析响应、实时做出精准的推荐就显得尤为困难。而 Flink 这样真正意义上的大数据流处理引擎,就能做到这些。这也是阿里在 Flink 上充分发力并成为引领者的原因。
1.2.2 Flink 主要的应用场景
- 电商和市场营销
举例:实时数据报表、广告投放、实时推荐
- 在电商行业中,网站点击量是统计 PV、UV 的重要来源,也是如今“流量经济”的最主要
数据指标。很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。 - 网站获得的点击数据可能是连续且不均匀的,还可能在同一时间大量产生,这是典型的数据流。如果我们希望把它们全部收集起来,再去分析处理,就会面临很多问题:首先,我们需要很大的空间来存储数据;其次,收集数据的过程耗去了大量时间,统计分析结果的实时性就大大降低了;另外,分布式处理无法保证数据的顺序,如果我们只以数据进入系统的时间为准,可能导致最终结果计算错误。
- 我们需要的是直接处理数据流,而 Flink 就可以做到这一点。
- 物联网(IOT)
举例:传感器实时数据采集和显示、实时报警,交通运输业
- 物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关键。
- 交通运输业也体现了流处理的重要性。比如说,如今高铁运行主要就是依靠传感器检测数据,测量数据包括列车的速度和位置,以及轨道周边的状况。这些数据会从轨道传给列车,再从列车传到沿途的其他传感器;与此同时,数据报告也被发送回控制中心。因为列车处于高速行驶状态,因此数据处理的实时性要求是极高的。如果流数据没有被及时正确处理,调整意见和警告就不能相应产生,后果可能会非常严重。
- 物流配送和服务业
举例:订单状态实时更新、通知信息推送
- 在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发,不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理。
- 银行和金融业
举例:实时结算和通知推送,实时检测异常行为
- 银行和金融业是另一个典型的应用行业。用户的交易行为是连续大量发生的,银行面对的是海量的流式数据。由于要处理的交易数据量太大,以前的银行是按天结算的,汇款一般都要隔天才能到账。所以有一个说法叫作“银行家工作时间”,说的就是银行家不仅不需要 996,甚至下午早早就下班了:因为银行需要早点关门进行结算,这样才能保证第二天营业之前算出准确的账。这显然不能满足我们快速交易的需求。在全球化经济中,能够提供 24 小时服务变得越来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以接到实时的推送通知。这就需要我们能够实时处理数据流。
- 另外,信用卡欺诈的检测也需要及时的监控和报警。一些金融交易市场,对异常交易行为的及时检测可以更好地进行风险控制;还可以对异常登录进行检测,从而发现钓鱼式攻击,从而避免巨大的损失。
1.3 流式数据处理的发展和演变
1.3.1 流处理和批处理
- 数据处理有不同的方式。
- 对于具体应用来说,有些场景数据是一个一个来的,是一组有序的数据序列,我们把它叫作“数据流”;而有些场景的数据,本身就是一批同时到来,是一个有限的数据集,这就是批量数据(有时也直接叫数据集)。
- 容易想到,处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处理;因为这种处理是即时的,所以也叫实时处理。与之对应,处理批量数据自然就应该一批读入、一起计算,这种方式就叫作批处理,也叫作离线处理。
- 那真实的应用场景中,到底是数据流更常见、还是批量数据更常见呢?
- 生活中,这两种形式的数据都有,如图所示。比如我们日常发信息,可以一句一句地说,也可以写一大段一起发过去。一句一句的信息,就是一个一个的数据,它们构成的序列就是一个数据流;而一大段信息,是一组数据的集合,对应就是批量数据(数据集)。

- 当然,有经验的人都会知道,一句一句地发,你一言我一语,有来有往这才叫聊天;一大段信息直接砸过去,别人看着都眼晕,很容易就没下文了——如果是很重要的整篇内容(比如表白信),写成文档或者邮件发过去可能效果会更好。
- 所以我们看到,“聊天”这个生活场景,数据的生成、传递和接收处理,都是流式的;而“写信”的场景,数据的生成尽管应该也是流式的(字总得一个个写),但我们可以把它们收集起来,统一传输、统一处理(当然我们还可以进一步较真:处理也是流式的,字得一个一个读)。不论传输处理的方式是怎样的,数据的生成,一般都是流式的。
- 在 IT 应用场景中,这一点会体现得更加明显。企业的绝大多数应用程序,都是在不停地接收用户请求、记录用户行为和系统日志,或者持续接收采集到的状态信息。所以数据会在不同的时间持续生成,形成一个有序的数据序列——这就是典型的数据流。
- 所以流数据更真实地反映了我们的生活方式。真实场景中产生的,一般都是数据流。那处理数据流,就一定要用流处理的方式吗?
- 这个问题似乎问得有点无厘头。不过仔细一想就会发现,很多数据流的场景其实也可以用“攒一批”的方式来处理。比如聊天,我们可以收到一条信息就回一条;也可以攒很多条一起回复。对于应用程序,也可以把要处理的数据先收集齐,然后才一并处理。
- 但是这样做的缺点也非常明显:数据处理不够及时,实时性变差了。流处理,是真正的即时处理,没有“攒批”的等待时间,所以会更快、实时性更好。
- 另外,在批处理的过程中,必须有一个固定的时间节点结束“攒批”的过程、开始计算。而数据流是连续不断、无休无止的,我们没有办法在某一时刻说:“好!现在收集齐所有数据了,我们可以开始分析了。”如果我们需要实现“持续计算”,就必须采用流处理的方式,来处理数据流。
- 很显然,对于流式数据,用流处理是最好、也最合理的方式。
- 但我们知道,传统的数据处理架构并不是这样。无论是关系型数据库、还是数据仓库,都倾向于先“收集数据”,然后再进行处理。为什么不直接用流处理的方式呢?这是因为,分布式批处理在架构上更容易实现。想想生活中发消息聊天的例子,我们就很容易理解了:如果来一条消息就立即处理,“微信秒回”,这样做一定会很受人欢迎;但是这要求自己必须时刻关注新消息,这会耗费大量精力,工作效率会受到很大影响。如果隔一段时间查一下新消息,做个“批处理”,压力明显就小多了。当然,这样的代价就是可能无法及时处理有些消息,造成一定的后果。
- 想要弄清楚流处理的发展演变,我们先要了解传统的数据处理架构。
1.3.2 传统事务处理
IT 互联网公司往往会用不同的应用程序来处理各种业务。比如内部使用的企业资源规划(ERP)系统、客户关系管理(CRM)系统,还有面向客户的 Web 应用程序。这些系统一般都会进行分层设计:“计算层”就是应用程序本身,用于数据计算和处理;而“存储层”往往是传统的关系型数据库,用于数据存储,如图所示: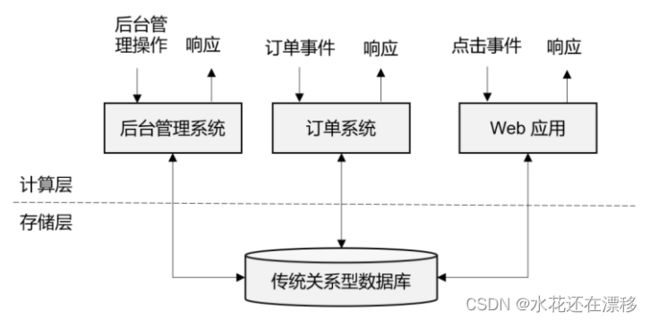
- 我们发现,这里的应用程序在处理数据的模式上有共同之处:接收的数据是持续生成的事件,比如用户的点击行为,客户下的订单,或者操作人员发出的请求。处理事件时,应用程序需要先读取远程数据库的状态,然后按照处理逻辑得到结果,将响应返回给用户,并更新数据库状态。一般来说,一个数据库系统可以服务于多个应用程序,它们有时会访问相同的数据库或表。
- 这就是传统的“事务处理”架构。系统所处理的连续不断的事件,其实就是一个数据流。而对于每一个事件,系统都在收到之后进行相应的处理,这也是符合流处理的原则的。所以可以说,传统的事务处理,就是最基本的流处理架构。
- 对于各种事件请求,事务处理的方式能够保证实时响应,好处是一目了然的。但是我们知道,这样的架构对表和数据库的设计要求很高;当数据规模越来越庞大、系统越来越复杂时,可能需要对表进行重构,而且一次联表查询也会花费大量的时间,甚至不能及时得到返回结果。
- 于是,作为程序员就只好将更多的精力放在表的设计和重构,以及 SQL 的调优上,而无法专注于业务逻辑的实现了——我们都知道,这种工作费力费时,却没法直接体现在产品上给老板看,简直就是噩梦。
- 那有没有更合理、更高效的处理架构呢?
1.3.3 有状态的流处理
- 不难想到,如果我们对于事件流的处理非常简单,例如收到一条请求就返回一个“收到”,那就可以省去数据库的查询和更新了。但是这样的处理是没什么实际意义的。在现实的应用中,往往需要还其他一些额外数据。我们可以把需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。在传统架构中,这个状态就是保存在数据库里的。这就是所谓的“有状态的流处理”。
- 为了加快访问速度,我们可以直接将状态保存在本地内存,如图所示。当应用收到一个新事件时,它可以从状态中读取数据,也可以更新状态。而当状态是从内存中读写的时候,这就和访问本地变量没什么区别了,实时性可以得到极大的提升。
- 另外,数据规模增大时,我们也不需要做重构,只需要构建分布式集群,各自在本地计算就可以了,可扩展性也变得更好。
- 因为采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们可以定期地将应用状态的一致性检查点(checkpoint)存盘,写入远程的持久化存储,遇到故障时再去读取进行恢复,这样就保证了更好的容错性。

- 有状态的流处理是一种通用而且灵活的设计架构,可用于许多不同的场景。具体来说,有以下几种典型应用。
- 事件驱动型(Event-Driven)应用
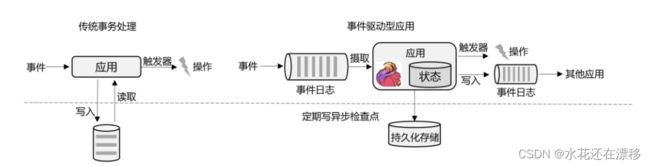
- 事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 Kafka 为代表的消息队列几乎都是事件驱动型应用。
- 这其实跟传统事务处理本质上是一样的,区别在于基于有状态流处理的事件驱动应用,不再需要查询远程数据库,而是在本地访问它们的数据,如图 1-7 所示,这样在吞吐量和延迟方面就可以有更好的性能。
- 另外远程持久性存储的检查点保证了应用可以从故障中恢复。检查点可以异步和增量地完成,因此对正常计算的影响非常小。
- 数据分析(Data Analysis)型应用
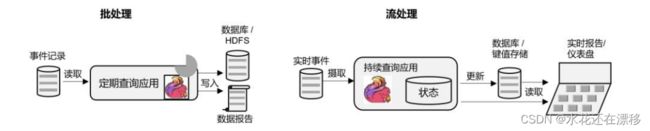
- 所谓的数据分析,就是从原始数据中提取信息和发掘规律。传统上,数据分析一般是先将数据复制到数据仓库(Data Warehouse),然后进行批量查询。如果数据有了更新,必须将最新数据添加到要分析的数据集中,然后重新运行查询或应用程序。
- 如今,Apache Hadoop 生态系统的组件,已经是许多企业大数据架构中不可或缺的组成部分。现在的做法一般是将大量数据(如日志文件)写入 Hadoop 的分布式文件系统(HDFS)、S3 或 HBase 等批量存储数据库,以较低的成本进行大容量存储。然后可以通过 SQL-on-Hadoop类的引擎查询和处理数据,比如大家熟悉的 Hive。这种处理方式,是典型的批处理,特点是可以处理海量数据,但实时性较差,所以也叫离线分析。
- 如果我们有了一个复杂的流处理引擎,数据分析其实也可以实时执行。流式查询或应用程序不是读取有限的数据集,而是接收实时事件流,不断生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。
- Apache Flink 同时支持流式与批处理的数据分析应用,如图 1-8 所示。
- 与批处理分析相比,流处理分析最大的优势就是低延迟,真正实现了实时。另外,流处理不需要去单独考虑新数据的导入和处理,实时更新本来就是流处理的基本模式。当前企业对流式数据处理的一个热点应用就是实时数仓,很多公司正是基于 Flink 来实现的。
- 数据管道(Data Pipeline)型应用

- ETL 也就是数据的提取、转换、加载,是在存储系统之间转换和移动数据的常用方法。在数据分析的应用中,通常会定期触发 ETL 任务,将数据从事务数据库系统复制到分析数据库或数据仓库。
- 所谓数据管道的作用与 ETL 类似。它们可以转换和扩展数据,也可以在存储系统之间移动数据。不过如果我们用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再去周期性触发了。比如,数据管道可以用来监控文件系统目录中的新文件,将数据写入事件日志。连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用,可以用于更多的场景。
- 如上图所示,展示了 ETL 与数据管道之间的区别。
- 有状态的流处理架构上其实并不复杂,很多用户基于这种思想开发出了自己的流处理系统,这就是第一代流处理器。Apache Storm 就是其中的代表。Storm 可以说是开源流处理的先锋,最早是由 Nathan Marz 和创业公司 BackType 的一个团队开发的,后来才成为 Apache 软件基金会下属的项目。Storm 提供了低延迟的流处理,但是它也为实时性付出了代价:很难实现高吞吐,而且无法保证结果的正确性。用更专业的话说,它并不能保证“精确一次” (exactly-once);即便是它能够保证的一致性级别,开销也相当大。
1.3.4 Lambda 架构
- 对于有状态的流处理,当数据越来越多时,我们必须用分布式的集群架构来获取更大的吞吐量。但是分布式架构会带来另一个问题:怎样保证数据处理的顺序是正确的呢?
- 对于批处理来说,这并不是一个问题。因为所有数据都已收集完毕,我们可以根据需要选择、排列数据,得到想要的结果。可如果我们采用“来一个处理一个”的流处理,就可能出现“乱序”的现象:本来先发生的事件,因为分布处理的原因滞后了。怎么解决这个问题呢?
- 以 Storm 为代表的第一代分布式开源流处理器,主要专注于具有毫秒延迟的事件处理,特点就是一个字“快”;而对于准确性和结果的一致性,是不提供内置支持的,因为结果有可能取决于到达事件的时间和顺序。另外,第一代流处理器通过检查点来保证容错性,但是故障恢复的时候,即使事件不会丢失,也有可能被重复处理——所以无法保证 exactly-once。
- 与批处理器相比,可以说第一代流处理器牺牲了结果的准确性,用来换取更低的延迟。而批处理器恰好反过来,牺牲了实时性,换取了结果的准确。
- 我们自然想到,如果可以让二者做个结合,不就可以同时提供快速和准确的结果了吗?正是基于这样的思想,Lambda 架构被设计出来,如图 1-10 所示。我们可以认为这是第二代流处理架构,但事实上,它只是第一代流处理器和批处理器的简单合并。
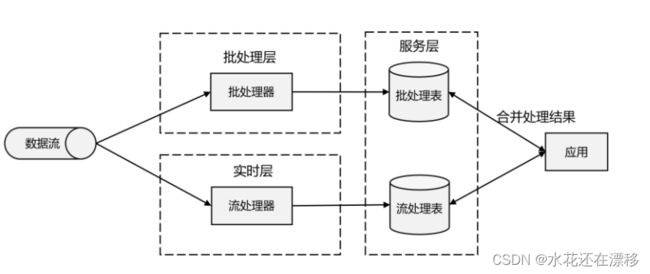
- Lambda 架构主体是传统批处理架构的增强。它的“批处理层”(Batch Layer)就是由传统的批处理器和存储组成,而“实时层”(Speed Layer)则由低延迟的流处理器实现。数据到达之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间,等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从快速表中删除不准确的结果。最终,应用程序会合并快速表和批处理表中的结果,并展示出来。
- Lambda 架构现在已经不再是最先进的,但仍在许多地方使用。它的优点非常明显,就是兼具了批处理器和第一代流处理器的特点,同时保证了低延迟和结果的准确性。而它的缺点同样非常明显。首先,Lambda 架构本身就很难建立和维护;而且,它需要我们对一个应用程序,做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,它们的 API也完全不同。为了实现一个应用,付出了双倍的工作量,这对程序员显然不够友好。
1.3.5 新一代流处理器
- 之前的分布式流处理架构,都有明显的缺陷,人们也一直没有放弃对流处理器的改进和完善。终于,在原有流处理器的基础上,新一代分布式开源流处理器诞生了。为了与之前的系统区分,我们一般称之为第三代流处理器,代表当然就是 Flink。
- 第三代流处理器通过巧妙的设计,完美解决了乱序数据对结果正确性的影响。这一代系统还做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流处理器。另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了 Lambda 架构两套系统的工作,它的出现使得 Lambda 架构黯然失色。
- 除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可用的设置,以及与资源管理器(如 YARN 或 Kubernetes)的紧密集成等等。
1.4 Flink 的特性总结
Flink 是第三代分布式流处理器,它的功能丰富而强大。
1.4.1 Flink 的核心特性
Flink 区别与传统数据处理框架的特性如下。
- 高吞吐,低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-only)的状态一致性保证
- 可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
- 高可用,支持动态拓展。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。
- 能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态。
1.4.2 分层 API
除了上述这些特性之外,Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分层 API,整体 API 分层如图 :
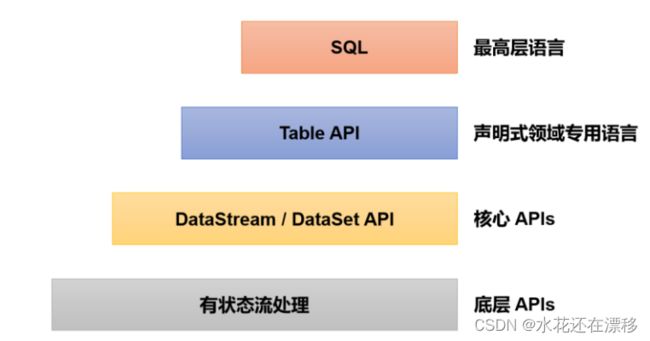
- 最底层级的抽象仅仅提供了有状态流,它将处理函数(Process Function)嵌入到了DataStream API 中。底层处理函数(Process Function)与 DataStream API 相集成,可以对某些操作进行抽象,它允许用户可以使用自定义状态处理来自一个或多个数据流的事件,且状态
具有一致性和容错保证。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。 - 实际上,大多数应用并不需要上述的底层抽象,而是直接针对核心 API(Core APIs) 进行编程,比如 DataStream API(用于处理有界或无界流数据)以及 DataSet API(用于处理有界数据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations)、连接(joins)、聚合(aggregations)、窗口(windows)操作等。DataSet API为有界数据集提供了额外的支持,例如循环与迭代。这些 API 处理的数据类型以类(classes)的形式由各自的编程语言所表示。
- Table API 是以表为中心的声明式编程,其中表在表达流数据时会动态变化。Table API 遵循关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、join、group-by、aggregate 等。
- 尽管 Table API 可以通过多种类型的用户自定义函数(UDF)进行扩展,仍不如核心 API更具表达能力,但是使用起来代码量更少,更加简洁。除此之外,Table API 程序在执行之前会使用内置优化器进行优化。
- 我们可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与DataStream 以及 DataSet 混合使用。
- Flink 提供的最高层级的抽象是 SQL。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL 查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
- 目前 Flink SQL 和 Table API 还在开发完善的过程中,很多大厂都会二次开发符合自己需要的工具包。而 DataSet 作为批处理 API 实际应用较少,2020 年 12 月 8 日发布的新版本 1.12.0, 已经完全实现了真正的流批一体,DataSet API 已处于软性弃用(soft deprecated)的状态。用Data Stream API 写好的一套代码, 即可以处理流数据, 也可以处理批数据,只需要设置不同的执行模式。这与之前版本处理有界流的方式是不一样的,Flink 已专门对批处理数据做了优化处理。本篇中以介绍 DataStream API 为主,采用的版本是 Flink 1.13.0。
总结流处理的发展演变
官网上列举典型的应用架构
- 事件驱动型应用

- 传统数据处理架构:事件来了后结合数据库里面的信息来做存取然后返回响应(读写外部数据然后触发一个操作)
- 流处理器架构:也是读取一个事件,只不过是这个事件从不同的外部系统摄取的,也就是说当前并不是一个外部服务器了,不是直接去接收网络请求的,而是在事件日志(消息队列),所以最常见的应用是flink直接连接消息队列(kafka),flink从kafka读取数据后本地的状态取代了原先的关系型数据库,这个状态进行读写操作之后就可以触发外部的,或者也可以把计算的结果再次写入到kafka或者其他的外部系统,然后再由其他的应用去读取,持久化存储是为了流处理的故障恢复。这种流处理的事件驱动型应用是与传统事务处理非常相似的
- 数据分析型应用

-
另外也可以做数据分析,可以做olap,hadoop、spark大数据处理引擎跟hive结合起来做离线数仓,我们把这个事件先记录起来,放在某个存储介质里,然后把它读取出来,定期跑sql查询,查询的结果可以写入到数据库、hdfs或者直接就生成一个数据报告,这是比较熟悉的离线处理。
-
有状态的流处理做数据分析,实时的事件放在kafka或者mysql里,flink通过jdbc连接外部数据库读取它的变化,然后把它作为实时事件输入给流处理器输入给flink,flink对其进行查询计算分析处理,接着就可以更新到数据库或者键值存储,也可以生成实时报告
-
数据管道型应用
相当于某一个管道进来,然后中间进行处理,接着一个管道出去,用flink也可以实现这样的需求
1.5 Flink vs Spark
- 谈到大数据处理引擎,不能不提 Spark。Apache Spark 是一个通用大规模数据分析引擎。它提出的内存计算概念让大家耳目一新,得以从 Hadoop 繁重的 MapReduce 程序中解脱出来,可以说是划时代的大数据处理框架。除了计算速度快、可扩展性强,Spark 还为批处理(SparkSQL)、流处理(Spark Streaming)、机器学习(Spark MLlib)、图计算(Spark GraphX)提供了统一的分布式数据处理平台,整个生态经过多年的蓬勃发展已经非常完善。
- 然而正在大家认为 Spark 已经如日中天、即将一统天下之际,Flink 如一颗新星异军突起,使得大数据处理的江湖再起风云。大数据处理框架,到底选择 Spark,还是 Flink 这就需要我们了解两者的主要区别,理解它们在不同领域的优势。
1.5.1 数据处理架构
- 我们已经知道,数据处理的基本方式,可以分为批处理和流处理两种。
- 批处理针对的是有界数据集,非常适合需要访问海量的全部数据才能完成的计算工作,一般用于离线统计。
- 流处理主要针对的是数据流,特点是无界、实时, 对系统传输的每个数据依次执行操作,一般用于实时统计。
- 从根本上说,Spark 和 Flink 采用了完全不同的数据处理方式。可以说,两者的世界观是截然相反的。
- Spark 以批处理为根本,并尝试在批处理之上支持流计算;在 Spark 的世界观中,万物皆批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流处理框架 Spark Streaming 而言,其实并不是真正意义上的“流”处理,而是“微批次”(micro-batching)处理,如图所示

而 Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世
界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。如图
1-13 所示,就是所谓的无界流和有界流。
- 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如图所示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。 - 有界数据流(Bounded Data Stream)对应的,有界数据流有明确定义的开始和结束,如图所示,所以我们可以通过获取所有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据集进行排序。有界流的处理也就是批处理。

正因为这种架构上的不同,Spark 和 Flink 在不同的应用领域上表现会有差别。一般来说,
Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在
流处理的低延迟上做到极致。在低延迟流处理场景,Flink 已经有明显的优势。而在海量数据的批处理领域,Spark 能够处理的吞吐量更大,加上其完善的生态和成熟易用的 API,目前同样优势比较明显。
两者底层实现:
1.5.2 数据模型和运行架构
- 除了三观不合,Spark 和 Flink 在底层实现最主要的差别就在于数据模型不同。
- Spark 底层数据模型是弹性分布式数据集(RDD),Spark Streaming 进行微批处理的底层接口 DStream,实际上处理的也是一组组小批数据 RDD 的集合。可以看出,Spark 在设计上本身就是以批量的数据集作为基准的,更加适合批处理的场景。(数据不动代码动)
- 而 Flink 的基本数据模型是数据流(DataFlow),以及事件(Event)序列。Flink 基本上是完全按照 Google 的 DataFlow 模型实现的,所以从底层数据模型上看,Flink 是以处理流式数据作为设计目标的,更加适合流处理的场景。(代码不动数据动)
- 数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。Spark 做批计算,需要将任务对应的 DAG 划分阶段(Stage),一个完成后经过 shuffle 再进行下一阶段的计算。而Flink 是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
1.5.3 Spark 还是 Flink?
- Spark 和 Flink 可以说目前是各擅胜场,批处理领域 Spark 称王,而在流处理方面 Flink 当仁不让。具体到项目应用中,不仅要看是流处理还是
批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度等多个方面进行权衡。 - 如果在工作中需要从 Spark 和 Flink 这两个主流框架中选择一个来进行实时流处理,我们更加推荐使用 Flink,主要的原因有:
- Flink 的延迟是毫秒级别,而 Spark Streaming 的延迟是秒级延迟。
- Flink 提供了严格的精确一次性语义保证。
- Flink 的窗口 API 更加灵活、语义更丰富。
- Flink 提供事件时间语义,可以正确处理延迟数据。
- Flink 提供了更加灵活的对状态编程的 API。
- 基于以上特点,使用 Flink 可以解放程序员, 加快编程效率, 把本来需要程序员花大力气手动完成的工作交给框架完成。
- 当然,在海量数据的批处理方面,Spark 还是具有明显的优势。而且 Spark 的生态更加成熟,也会使其在应用中更为方便。相信随着 Flink 的快速发展和完善,这方面的差距会越来越小。
- 另外,Spark 2.0 之后新增的 Structured Streaming 流处理引擎借鉴 DataFlow 进行了大量优化,同样做到了低延迟、时间正确性以及精确一次性语义保证;Spark 2.3 以后引入的连续处理(Continuous Processing)模式,更是可以在至少一次语义保证下做到 1 毫秒的延迟。而 Flink自 1.9 版本合并 Blink 以来,在 SQL 的表达和批处理的能力上同样有了长足的进步。
- 那如果现在要学习一门框架的话,优先选 Spark 还是 Flink 呢?其实我们可以看到,不同的框架各有利弊,同时它们也在互相借鉴、取长补短、不断发展,至于未来是 Spark 还是 Flink、甚至是其他新崛起的处理引擎一统江湖,都是有可能的。作为技术人员,我们应该对不同的架构和思想都有所了解,跳出某个框架的限制,才能看到更广阔的世界。
第二章 Flink 快速上手
Flink 底层是以 Java 编写的,并为开发人员同时提供了完整的 Java 和 Scala API。在本篇中,代码示例将全部用 Java 实现;而在具体项目应用中,可以根据需要选择合适语言的 API 进行开发。
2.1 环境准备
- 系统环境为 Windows 10
- 需提前安装 Java 8
- 集成开发环境(IDE)使用 IntelliJ IDEA,具体的安装流程参见 IntelliJ 官网
- 安装 IntelliJ IDEA 之后,还需要安装一些插件——Maven 和 Git。Maven 用来管理项目依赖;通过 Git 可以轻松获取我们的示例代码,并进行本地代码的版本控制。
2.2 创建项目
- 创建工程
(1) 打开 IntelliJ IDEA,创建一个 Maven 工程
(2) 将这个 Maven 工程命名为 FlinkDemo

- 添加项目依赖
在项目的 pom 文件中,增加标签设置属性,然后增加标签引入需要的依赖。我们需要添加的依赖最重要的就是 Flink 的相关组件,包括 flink-java、flink-streaming-java,以及 flink-clients(客户端,也可以省略)。另外,为了方便查看运行日志,我们引入 slf4j 和 log4j 进行日志管理。
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
这里做一点解释:
在属性中,我们定义了
- 配置日志管理
在目录 src/main/resources 下添加文件:log4j.properties,内容配置如下:
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2.3 编写代码
Flink 入门的 WordCount 程序
2.3.1 批处理
对于批处理而言,输入的应该是收集好的数据集。这里我们可以将要统计的文字,写入一个文本文档,然后读取这个文件处理数据就可以了。
(1)在工程根目录下新建一个 input 文件夹,并在下面创建一份 word.txt 文本文件
(2)在 words.txt 中输入一些文字,例如:
hello world
hello flink
hello java
(3)在 online.liujiahao.flink01 包下新建 Java 类 BatchWordCount,在静态 main 方法中编写测试代码。我们进行单词频次统计的基本思路是:先逐行读入文件数据,然后将每一行文字拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次。
具体代码及详细的注释如下:
package online.liujiahao.flink01;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args)throws Exception {
//1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2. 从文件读取数据(按行读)
DataSource<String> lineDS = env.readTextFile("input/word.txt");
//3. 转换数据格式(因为是一行一行的读进来,需要将字段进行切割,并且调用flatmap方法,扁平化之后,按第一个字段统计个数)
//这里需要两个参数,第一个(String line)是读入的每行数据,第二个(Collector>)是用来做转换之后,输出的这个操作。注意,java中没有Tuple,用的是flink api提供的tuple,导包的时候别导成scala的了。
//对于flink而言,flatmap的输出不是直接定义出来的,而是需要用一个Collector(收集器)来进行处理
//简单来说,就是我们需要将这个流中需要向下游传送输出的那些数据,先放到一个收集器里面,然后一条一条的发送出去。
//收集器也需要范型,范型用来确定转换之后 输出的数据类型是什么,这里就写什么类型,我们要得到一个二元元组类型,这里就写元组类型 这里这个 out 是起的别名
// ->前是lambda表达式要传的参数和类型,->后就是lambda表达式的具体实现了。
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
//todo 把line用空格做一个切分,用一个String数组来存
String[] words = line.split(" ");
//todo 切分后,得到words中的每一个单词,遍历,输出一个二元元组,怎么实现计数呢?来一个单词,就给后面加上一个 1 ,输出(world , 1 ) (hello,1)这样的形式
for (String word :
words) {
//out.collect表明要返回输出这样一个语句
//为什么不直接用最后一行作为lambda表达式的返回值? 因为用方法调用,你想输出多条就可以输出多条,for循环每遍历一次,就输出一条out.collect()数据
//因为flatmap是输出一个扁平化打散的输出,如果只是retain一个值的话,就无法实现输出多个值的操作了
out.collect(Tuple2.of(word, 1L));
}
})
//java不支持函数式编程,所以他的输出会出现范型擦除的现象,就是只知道输出了一个二元元组,而不知道元组里面值的类型
//所以下面加一个类型声明的方法.returns()
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//todo 4. 按照word进行分组(根据一个字段进行分组,按元组第一个元素进行分组)
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
//todo 5. 分组内聚合统计(sum需要指定一个字段,传入的是一个索引,根据第二个字段求和,索引需要传入的是1)
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 将结果向控制台打印
sum.print();
}
}
代码说明和注意事项:
- Flink 在执行应用程序前应该获取执行环境对象,也就是运行时上下文环境。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
- Flink 同时提供了 Java 和 Scala 两种语言的 API,有些类在两套 API 中名称是一样的。所以在引入包时,如果有 Java 和 Scala 两种选择,要注意选用 Java 的包。
- 直接调用执行环境的 readTextFile 方法,可以从文件中读取数据。
- 我们的目标是将每个单词对应的个数统计出来,所以调用 flatmap 方法可以对一行文字进行分词转换。将文件中每一行文字拆分成单词后,要转换成(word,count)形式的二元组,初始 count 都为 1。returns 方法指定的返回数据类型 Tuple2,就是 Flink 自带的二元组数据类型。
- 在分组时调用了 groupBy 方法,它不能使用分组选择器,只能采用位置索引或属性名称进行分组。2.
// 使用索引定位
dataStream.groupBy(0)
// 使用类属性名称
dataStream.groupBy("id")
- 在分组之后调用 sum 方法进行聚合,同样只能指定聚合字段的位置索引或属性名称。
输出结果: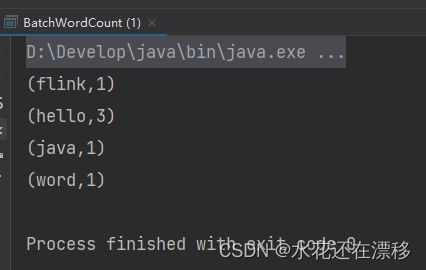
- 可以看到,我们将文档中的所有单词的频次,全部统计出来,以二元组的形式在控制台打印输出了。
- 需要注意的是,这种代码的实现方式,是基于 DataSet API 的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。所以从 Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理(在flink run后面加一个参数:runtime-mode 运行时的执行模式=BATCH):
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
- 这样,DataSet API 就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只要维护一套 DataStream API 就可以了。这里只是为了方便大家理解,我们依然用 DataSet API做了批处理的实现。
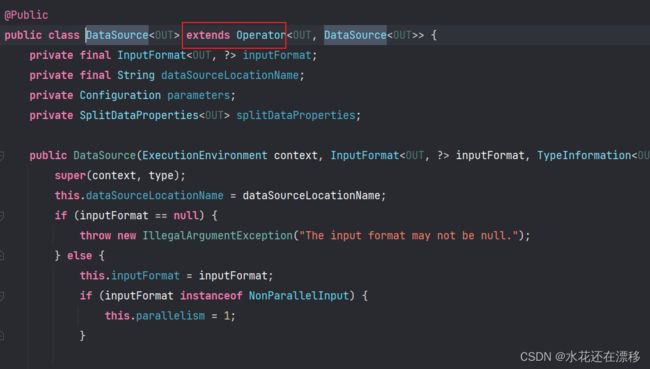
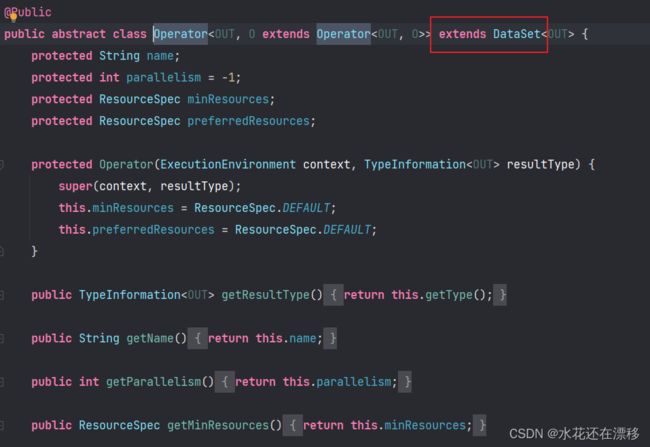
如上图所示,DataSource继承自Operator,Operator继承自DataSet,所有的转换操作都是基于DataSet(其他转换操作类也是最终继承自DataSet,我们把调用DataSet这套API叫做DataSet API)
2.3.2 流处理
- 我们已经知道,用 DataSet API 可以很容易地实现批处理;与之对应,流处理当然可以用DataStream API 来实现。对于 Flink 而言,流才是整个处理逻辑的底层核心,所以流批统一之后的 DataStream API 更加强大,可以直接处理批处理和流处理的所有场景。
- DataStream API 作为“数据流”的处理接口,又怎样处理批数据呢?
- 回忆一下上一章中我们讲到的 Flink 世界观。在 Flink 的视角里,一切数据都可以认为是流,流数据是无界流,而批数据则是有界流。所以批处理,其实就可以看作有界流的处理。
- 对于流而言,我们会在获取输入数据后立即处理,这个过程是连续不断的。当然,有时我们的输入数据可能会有尽头,这看起来似乎就成了一个有界流;但是它跟批处理是截然不同的——在输入结束之前,我们依然会认为数据是无穷无尽的,处理的模式也仍旧是连续逐个处理。
- 下面我们就针对不同类型的输入数据源,用具体的代码来实现流处理。
注意:这里就不能使用之前的ExecutionEnviroment了,因为用它的对象去调用readTextFile方法得到的将会时一个DataSource,那就又变成DataSetAPI了,所以他们之间的区别就是执行环境的不同。
- 读取文件
我们同样试图读取文档 words.txt 中的数据,并统计每个单词出现的频次。这是一个“有界流”的处理,整体思路与之前的批处理非常类似,代码模式也基本一致。
(1) 在 online.chenyunde.flink 包下新建 Java 类BoundedStreamWordCount,在静态 main 方法中编写测试代码。具体代码实现如下:
package online.liujiahao.flink01;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
//1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2. 读取文件
//这里调用读取文件方法 得到的是 DataStreamSource,所以后面的这一套就叫做DataStreamSourceAPI
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/word.txt");
//3. 转换数据格式(处理过程和批处理是一样的)
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4. 分组(按照二元元组的第一个值作为key,点进Tuple2可以看到两个元素分别是f0和f1,所以keyBy的参数给f0)
//可以看到,返回的是KeyedStream,而不是UnsortedGrouping了
//点进keyStream,可以看到它是继承DataStream的,所以这一套都叫DataStreamAPI
KeyedStream<Tuple2<String, Long>, String> wordAndOneUG = wordAndOneTuple.keyBy(data -> data.f0);
//5. 求和(之前用的sum,这边跟之前用的也是一样的)
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
//6. 打印
//但是这里直接打印是没结果的,因为我们当前这个操作是读取文件,这个文件是有界的,但是实际处理的时候流处理默认文件是无界的。而这个print打印是个一次性操作
//所以我们应该加上第7步,等待新的数据进来,每当有新数据进来,就执行一次定义好的操作。
sum.print();
//todo 到第六步,我们都只是定义好了整个数据的执行流程,并没有真正的让程序去执行,第七步相当于是把这些执行流程当作一个线程挂起了,监视,只要有数据进来就开始执行
//7. 执行
env.execute();
}
}
主要观察与批处理程序 BatchWordCount 的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 每一步处理转换之后,得到的数据对象类型不同。
- 分组操作调用的是 keyBy 方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的 key 是什么。
- 代码末尾需要调用 env 的 execute 方法,开始执行任务。
输出结果: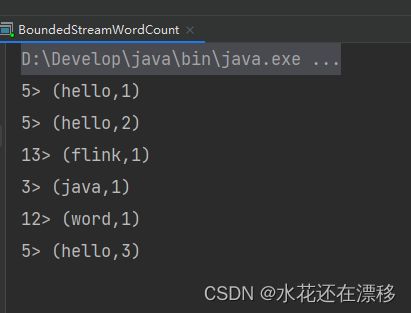
- 我们可以看到,这与批处理的结果是完全不同的。批处理针对每个单词,只会输出一个最终的统计个数;而在流处理的打印结果中,“hello”这个单词每出现一次,都会有一个频次统计数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。我们通过打印结果,可以清晰地看到单词“hello”数量增长的过程。
- 看到这里大家可能又会有新的疑惑:我们读取文件,第一行应该是“hello flink”,怎么这里输出的第一个单词是“world”呢?每个输出的结果二元组,前面都有一个数字,这又是什么呢?
- 我们可以先做个简单的解释。Flink 是一个分布式处理引擎,所以我们的程序应该也是分布式运行的。在开发环境里,会通过多线程来模拟 Flink 集群运行。所以这里结果前的数字,其实就指示了本地执行的不同线程,对应着 Flink 运行时不同的并行资源。这样第一个乱序的问题也就解决了:既然是并行执行,不同线程的输出结果,自然也就无法保持输入的顺序了。
- 另外需要说明,这里显示的编号为 1~4,是由于运行电脑的 CPU 是 4 核,所以默认模拟的并行线程有 4 个。这段代码不同的运行环境,得到的结果会是不同的。关于 Flink 程序并行执行的数量,可以通过设定“并行度”(Parallelism)来进行配置,我们会在后续章节详细讲解这些内容。
- 读取文本流
- 在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要保持一个监听事件的状态,持续地处理捕获的数据。
- 为了模拟这种场景,我们就不再通过读取文件来获取数据了,而是监听数据发送端主机的指定端口,统计发送来的文本数据中出现过的单词的个数。具体实现上,我们只要对BoundedStreamWordCount 代码中读取数据的步骤稍做修改,就可以实现对真正无界流的处理。
(1)新建一个 Java 类 StreamWordCount,将BoundedStreamWordCount 代码中读取文件数据的 readTextFile 方法,替换成读取 socket 文本流的方法 socketTextStream。具体代码实现如下:
package online.liujiahao.flink01;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import scala.Int;
import java.lang.reflect.Parameter;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从参数中去提取主机名和端口号
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
Integer port = parameterTool.getInt("port");
// 2.读取文本流
//这里调用socketTextStream方法,传入两个参数,hostname和端口号
DataStreamSource<String> lineDataStream = env.socketTextStream(hostname,port);
// 3.转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4.分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5.求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6.打印
sum.print();
// 7.执行
env.execute();
}
}
代码说明和注意事项:
- socket 文本流的读取需要配置两个参数:发送端主机名和端口号。这里代码中指定了主机“hadoop102”的 7777 端口作为发送数据的 socket 端口,读者可以根据测试环境自行配置。
- 在实际项目应用中,主机名和端口号这类信息往往可以通过配置文件,或者传入程序运行参数的方式来指定。
- socket文本流数据的发送,可以通过Linux系统自带的netcat工具进行模拟。
(2)在 Linux 环境的主机 hadoop102 上,执行下列命令,发送数据进行测试:
[atguigu@hadoop102 ~]$ nc -lk 7777
(3)启动 StreamWordCount 程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的——因为 Flink 的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
(4)从 hadoop102 发送数据:

可以看到控制台输出结果如下:
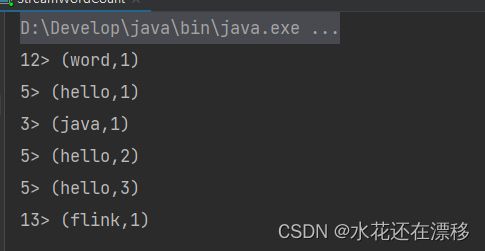
我们会发现,输出的结果与之前读取文件的流处理非常相似。而且可以非常明显地看到,每输入一条数据,就有一次对应的输出。
2.4 本章总结
本章主要实现一个 Flink 开发的入门程序——词频统计 WordCount。通过批处理和流处理两种不同模式的实现,可以对 Flink 的 API 风格和编程方式有所熟悉,并且更加深刻地理解批处理和流处理的不同。另外,通过读取有界数据(文件)和无界数据(socket 文本流)进行流处理的比较,我们也可以更加直观地体会到 Flink 流处理的方式和特点。