详解Linux文本三剑客
目录
一、grep
1.什么是grep?
2.如何使用?
3.正则
二、sed
1.认识sed?
2.如何使用?
三、awk(重点)
1.awk变量
1.1内置变量
1.2自定义变量
2.awk数组
四、经典实战案例
案例一:筛选IPv4地址
案例二:根据某字段去重
案例三: 统计TCP连接状态数
案例四:统计独立IP
案例五:处理字段缺失的数据
案例六:筛选给定时间范围内的日志
一、grep
1.什么是grep?
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
2.如何使用?
命令格式:grep [option] pattern file
参数选择(option):
-
-A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
-B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。
-
-C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
-c:统计匹配的行数
-
-e :实现多个选项间的逻辑or 关系
-
-E:扩展的正则表达式
-
-f FILE:从FILE获取PATTERN匹配
-
-F :相当于fgrep
-
-i --ignore-case #忽略字符大小写的差别。
-
-n:显示匹配的行号
-
-o:仅显示匹配到的字符串
-
-q: 静默模式,不输出任何信息
-
-s:不显示错误信息。
-
-v:显示不被pattern 匹配到的行,相当于[^] 反向匹配
-
-w :匹配 整个单词
3.正则
格式:
-
. 匹配任意单个字符,不能匹配空行
-
[] 匹配指定范围内的任意单个字符
-
[^] 取反
-
[:alnum:] 或 [0-9a-zA-Z]
-
[:alpha:] 或 [a-zA-Z]
-
[:upper:] 或 [A-Z]
-
[:lower:] 或 [a-z]
-
[:blank:] 空白字符(空格和制表符)
-
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
-
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
-
[:digit:] 十进制数字 或[0-9]
-
[:xdigit:]十六进制数字
-
[:graph:] 可打印的非空白字符
-
[:print:] 可打印字符
-
[:punct:] 标点符号
-
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
-
.* 任意前面长度的任意字符,不包括0次
-
\? 匹配其前面的字符0 或 1次
-
+ 匹配其前面的字符至少1次
-
{n} 匹配前面的字符n次
-
{m,n} 匹配前面的字符至少m 次,至多n次
-
{,n} 匹配前面的字符至多n次
-
{n,} 匹配前面的字符至少n次
注:以上为正则的基本知识,进一步了解可以点击此链接。python正则表达式和断言_第1关:先行断言_《^O^》杜的博客-CSDN博客
二、sed
1.认识sed?
sed 是一种流编辑器,一次处理一行内容,处理时,把当前处理的行存储在临时缓冲区中,接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕 ,然后读入下行,执行下一个循环。
2.如何使用?
命令格式:sed [options] '[地址定界] command'` `file``(s)
选项(options):
-
-n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
-
-e:多点编辑,对每行处理时,可以有多个Script
-
-f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写
-
-r:支持扩展的正则表达式
-
-i:直接将处理的结果写入文件
-
-i.bak:在将处理的结果写入文件之前备份一份
地址定界:
-
不给地址:对全文进行处理
-
单地址:#: 指定的行 /pattern/:被此处模式所能够匹配到的每一行
-
地址范围:#,# #,+# /pat1/,/pat2/ #,/pat1/
-
~:步进 sed -n '1~2p' 只打印奇数行 (1~2 从第1行,一次加2行) sed -n '2~2p' 只打印偶数行
command:
-
d:删除模式空间匹配的行,并立即启用下一轮循环
-
p:打印当前模式空间内容,追加到默认输出之后
-
a:在指定行后面追加文本,支持使用\n实现多行追加
-
i:在行前面插入文本,支持使用\n实现多行追加
-
c:替换行为单行或多行文本,支持使用\n实现多行追加
-
w:保存模式匹配的行至指定文件
-
r:读取指定文件的文本至模式空间中匹配到的行后
-
=:为模式空间中的行打印行号
-
!:模式空间中匹配行取反处理
三、awk(重点)
1.awk变量
1.1内置变量
-
FS :输入字段分隔符,默认为空白字符
-
OFS :输出字段分隔符,默认为空白字符
-
RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
-
ORS :输出记录分隔符,输出时用指定符号代替换行符
-
NF :字段数量,共有多少字段, $NF引用最后一列,$(NF-1)引用倒数第2列
-
NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
-
FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
-
FILENAME :当前文件名
-
ARGC :命令行参数的个数
-
ARGV :数组,保存的是命令行所给定的各参数,查看参数
1.2自定义变量
注:自定义变量区分字符大小写。
(1)-v var=value
举例:第一种:先定义变量,后执行动作print
awk -v name="along" -F: '{print name":"$0}' awkdemo
第二种:在执行动作print后定义变量
awk -F: '{print name":"$0;name="along"}' awkdemo
(2)可以把执行的动作放在脚本中,直接调用脚本 -f
写一个脚本awk.txt ,内容为:{name="along";print name,$1}
使用:awk -F: -f awk.txt awkdemo
2.awk数组
关联数组:
(1)可使用任意字符串;字符串要使用双引号括起来
(2)如果某数组元素事先不存在,在引用时,awk 会自动创建此元素,并将其值初始化为“空串”
(3)若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
(4)若要遍历数组中的每个元素,要使用for 循环:for(var in array) {for-body}
四、经典实战案例
案例一:筛选IPv4地址
从ifconfig命令的结果中筛选出除了lo网卡外的所有IPv4地址。

案例二:根据某字段去重
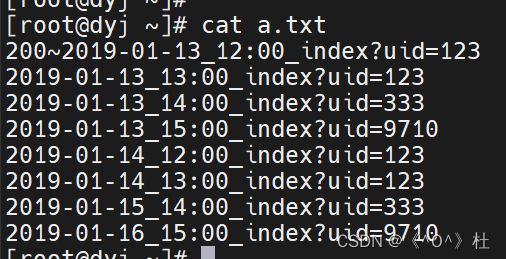
法一:
[root@dyj ~]# awk -F"?" '!arr[$2]++{print}' a.txt
200~2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
法二:
[root@dyj ~]# cat a.txt | awk -F"?" '{arr[$2]=arr[$2]+1;if(arr[$2]==1){print}}'
200~2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
法三:
[root@dyj ~]# cat a.txt |awk -F"?" '{arr[$2]++;if(arr[$2]==1){print}}'
200~2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710案例三: 统计TCP连接状态数

案例四:统计独立IP
统计每个URL的独立访问IP有多少个(去重),并且要为每个URL保存一个对应的文件。
[root@dyj ~]# cat log.txt | awk 'BEGIN{FS="|"}!arr[$1,$2]++{arr1[$1]++}END{for(i in arr1){print i,arr1[i]}}'
a.com.cn 2
c.com.cn 1
b.com.cn 2
[root@dyj ~]# cat log.txt | awk 'BEGIN{FS="|"}!arr[$1,$2]++{arr1[$1]++}END{for(i in arr1){print i,arr1[i]>(i".txt")}}'
[root@dyj ~]# find /root -name "*.com.cn.txt"
/root/b.com.cn.txt
/root/a.com.cn.txt
/root/c.com.cn.txt
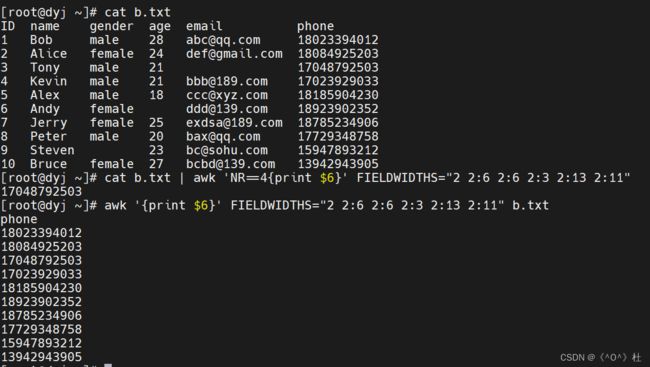
案例五:处理字段缺失的数据
当字段缺失时,直接使用FS划分字段来处理会非常棘手。gawk为了解决这种特殊需求,提供了FIELDWIDTHS变量。FIELDWIDTH可以按照字符数量划分字段。
案例六:筛选给定时间范围内的日志
grep/sed/awk用正则去筛选日志时,如果要精确到小时、分钟、秒,则非常难以实现。但是awk提供了mktime()函数,它可以将时间转换成epoch时间值。
[root@dyj ~]# awk 'BEGIN{print mktime("2019 11 10 03 42 40")}'
1573328560
BEGIN{
# 要筛选什么时间的日志,将其时间构建成epoch值
which_time = mktime("2019 11 10 03 42 40")
}
{
# 取出日志中的日期时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
# 将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
# 通过比较epoch值来比较时间大小
if(tmp_time > which_time){
print
}
}
# 构建的时间字符串格式为:"10/Nov/2019:23:53:44+08:00"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S) {
dt_str = gensub("[/:+]"," ","g",str)
# dt_sr = "10 Nov 2019 23 53 44 08 00"
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}以上为Linux的文本三剑客的详解,还有不足之处后期将进一步完善。