大数据集群搭建全部过程(Vmware虚拟机、hadoop、zookeeper、hive、flume、hbase、spark、yarn)
大数据集群搭建进度及问题总结
所有资料在评论区那里可以得到

第一章:
1.网关配置(参照文档)
注意事项:第一台虚拟机改了,改为centos 101 ,地址为192.168.181.130 网关依然是192.168.181.2,但是一定要注意,它在D盘的文件名称是Hadoop 101,后面重新搭建的会命名文件夹为hadoop 101,hadoop 102和hadoop 103,然后发到一个总的文件夹hadoop_03里面去

VMnet8的IP地址一定是自己的,自动获取的,不能和张部长的192.168.110.1一样,要自己的才可以,不然后续网络是ping不通的,ping www.baidu.com会报错。网关是通过ip地址来配置的,网关和计算机网络学的一样,地址的网络好一定一定要和主机的一样,就是如果是C类的,那么前面三项一定是一样的,最后一个不一样。
==注意:==配置时,1.首先线自动获取IP地址,此时是没有网关的,然后通过cmd 查看ipconfig中的VMnet8的地址,然后确定地址后,也就确定网关了,在把网关填到VMnet8中(使用下面的IP地址),然后把DNS域名服务器也写上,谷歌的默认是8.8.8.8,然后就可以去cmd再次查看。另外配置的虚拟机地址也是要前三项一样。
下面这个修改前是小写后面就要改成小写,要保持一致

对应克隆后的虚拟机,要注意改下面这些内容
1.vim /etc/udev/rules.d/70-persistent-net.rules
2.vim /etc/sysconfig/network-scripts/ifcfg-eth0
3.vim /etc/sysconfig/network
4.vim /etc/hosts
5.reboot
6.进入C:\Windows\System32\drivers\etc路径,打开hosts文件并添加如下内容:
192.168.110.102 hadoop102
2.securecrt
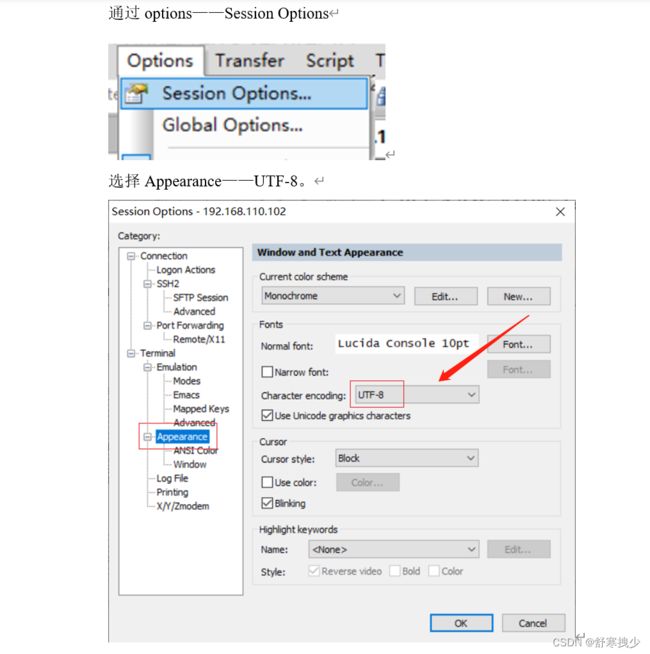
3.对于报错
对于报错的信息,首先第一个要想到的是能不能ping www.baidu.com,不能ping的通就是网络没有设置好,要一个一个检测,最应该看的就是前面第一个提到的网络的IP地址是不是直接获取的,还是别人的。
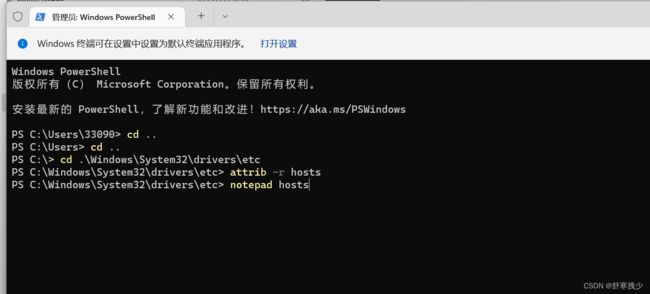
4.hosts文件编辑不了
问题:hosts文件编辑不了,显示权限不够
解决办法:
修改权限:1.window+x 选择管理员模式,然后进入到对应的文件目录,然后输入attrib -r hosts 去掉只读模式,然后在notepad + hosts(文件名)打开编辑。
windows的hosts目录:C:\Windows\System32\drivers\etc
5.centos6 yum 失效
问题:
直接输入yum makecache会报错: yum makecache

CentOS 6已经随着2020年11月的结束进入了EOL(Reaches End of Life),不过有一些老设备依然需要支持,CentOS官方也给这些还不想把CentOS6扔进垃圾堆的用户保留了最后一个版本的镜像,只是这个镜像不会再有更新了官方便在12月2日正式将CentOS 6相关的软件源移出了官方源,随之而来逐级镜像也会陆续将其删除。
不过有一些老设备依然需要维持在当前系统,CentOS官方也给这些还不想把CentOS6扔进垃圾堆的用户保留了各个版本软件源的镜像,只是这个软件源不会再有更新了。换成大白话就是:Centos 6已经不被官方支持,所以想要使用就要用其他代理比如阿里云Vault镜像。
张部长解决方案:
五行命令,五步 ,一步步复制到CRT操作即可。不嫌麻烦直接在虚拟机里面命令行手敲也可以,一定要打对!
| sed -i “s|enabled=1|enabled=0|g” /etc/yum/pluginconf.d/fastestmirror.conf |
|---|
| mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup |
| curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo |
| yum clean all |
| yum makecache |
确保最后yum makecache时,出现如下内容:

最后显示如下内容表示正常加载完成:

网上方案1:
原因:目前,CentOS6已停止更新支持,并且官方将已有的yum源删除了,因此需要更换yum源,否则会出现更新软件失败的现象。
解决方法:在终端上分别输入如下三行指令即可:
wget -O /etc/yum.repos.d/CentOS-Base.repo http://files.tttidc.com/centos6/Centos-6.repo
wget -O /etc/yum.repos.d/epel.repo http://files.tttidc.com/centos6/epel-6.repo
yum makecache
第二章:(看下面这些)
MySQL的配置
yum前面的全部弄好了,安装MySQL完成,但是MySQL是免密登录的,暂时还没有设置密码,==即直接输入MySQL就可以进入,或者输入mysql -u root也可以进入MySQL。==后续用到在重新弄。MySQL配置时参考的博文:https://blog.csdn.net/xp_zyl/article/details/81060479
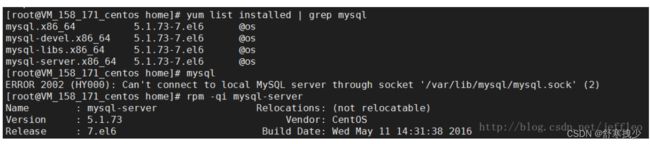
一、查看CentOS下是否已安装mysql
输入命令 :yum list installed | grep mysql
二、删除已安装mysql
输入命令:
yum -y remove mysql
如果有:其他的文件也移除
yum -y remove mysql-libs.x86_64
yum -y remove mysql5.7-community-release.noarch
看到complete就说明成功了
三、从yum库中的安装mysql
输入命令:
yum list | grep mysql
yum -y install mysql mysql-server mysql-devel
四、验证是否安装成功
输入命令:rpm -qi mysql-server
五、启动MySql服务
输入命令:service mysqld start
MySQL设置登录密码
直接输入 mysql 并回车,如果成功,将出现MySQL提示符 >
C:\Users\Administrator>cd C:\Program Files\MySQL\MySQL Server 5.5\bin
C:\Program Files\MySQL\MySQL Server 5.5\bin>mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.5.35 MySQL Community Server (GPL)
Copyright © 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type ‘help;’ or ‘\h’ for help. Type ‘\c’ to clear the current input statement.
mysql>
6.切换到mysql表
mysql>USE mysql;
7.可以修改密码了:
UPDATE user SET password=PASSWORD(“020819”) WHERE user=“root”;
8.刷新权限,不要忘记了:
mysql>FLUSH PRIVILEGES;
9.退出:(退出的方法很多 有quit、exit、ctrl+c、\q 等等); 10.注销或重启计算机,然后打开MySQL服务,使用用户名root和设置的新密码就可以登录了。
原文链接:https://blog.csdn.net/weixin_42440389/article/details/113230553(包含怎么设置登录密码)
设置完登录报错:
1.报错如下:
[root@hadoop101 ~]# mysql
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
[root@hadoop101 ~]# mysql -h 192.168.181.101 -u root -p020819;
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.181.101' (111)
[root@hadoop101 ~]# mysql -h 192.168.181.101 -u root -p020819
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.181.101' (111)
[root@hadoop101 ~]# mysql -h localhost -u root -p020819
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
[root@hadoop101 ~]#
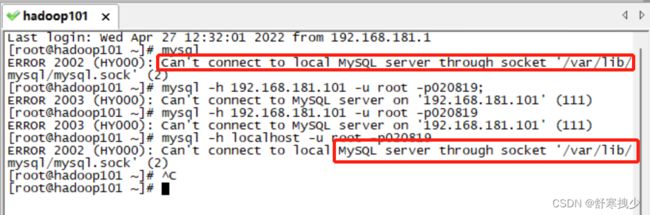
2.解决方法:没有重启MySQL服务,重启一下,然后用密码登录就可以了:service mysqld start
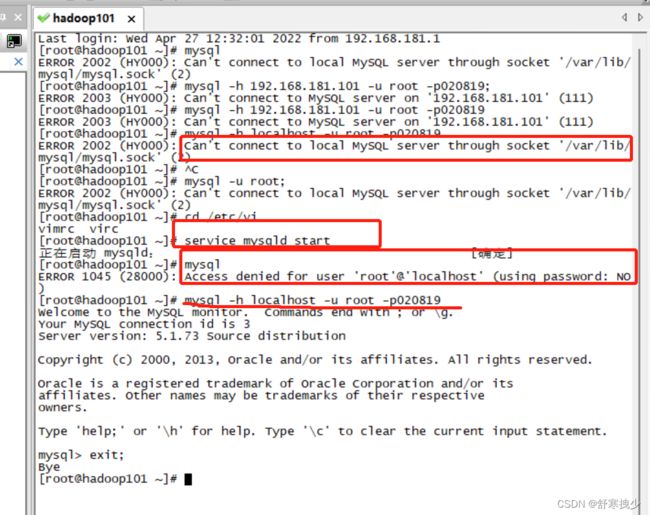
MySQL乱码
使用命令行操作mysql时中文数据出现乱码
因为本机mysql与虚拟机mysql连接 mysql -h 192.168.181.101 -u root -p
-h 虚拟机IP地址 -u 用户名 -p表示使用密码登录
而本机mysql使用的是utf-8 虚拟机mysql使用的是gbk所以出现乱码
使用
set names gbk
完结:
MySQL全部搞好,登录密码也设置了,密码为020819,如果出现有关mysql.sock的错误,第一个是考虑上面的问题,有没有重启MySQL,要启动MySQL服务。第二个就是要考虑是不是断电问题,导致下载时没有下载好,就要进入到MySQL的相关目录,然后删掉之前的sock,这里推荐看看是不是mysql 启动出问题的文章。
Linux的目录结构:
1./home:通常的配置下,每个用户都会在/home目录中拥有一个属于自己的目录。普通用户只能在自己的主目录中创建文件。这一限制可以保护系统免遭错误的用户行为的破坏
2./opt 用来安装其它可选的软件。主要用来存放可能安装在系统中的商业软件
3./var/log 包含的日志文件,记录了各种系统活动。这些文件非常重要,并且应该时不时监控它们。其中最有用的文件是/var/log/messages.安全起见,只有超级用户才能查看日志文件
4./tmp 供用户存放各类程序创建的临时文件的目录。某些配置使得每次系统重启时都会清空该目录
5./etc 是放置配置文件的地方
文件目录:还是和之前一样,新建了export: 在/export/softwars里面存放软件的压缩包,然后解压后的软件发在/export/servers里面。
redis的安装与配置(完结)
redis的安装可以直接下面操作:
1.安装gcc
yum install gcc
yum install gcc-c++
2.下载redis
下载地址要自己新建目录,我自己的是建了/export/softwares 和/export/servers,其中softwares是放压缩包的,而servers是放解压后的文件的,下面这个要在softwares目录下执行。
wget http://download.redis.io/redis-stable.tar.gz
如何解压到servers目录下:tar -zxvf redis-stable.tar.gz -C ../servers
3.编译、安装:
make
make install
redis的配置可以直接下面操作+文档
1.配置文件一般放在/etc/下,创建redis目录:
cd /etc/
mkdir redis
2.dump file、进程pid、log目录等,一般放在/var/目录下:
cd /var/
mkdir redis
cd redis
mkdir data log run
3.修改配置文件,配置参数,首先拷贝解压包下的redis.conf文件至/etc/redis
cd redis-stable #进入redis-stable目录的意思
cp redis.conf /etc/redis/
4.查看/etc/redis/redis.conf并进行修改
cd /etc/redis/
ll
vim redis.conf
5.修改的内容:98行左右将看看端口是不是 port 6379是就不用改,一般是不用改的。然后大概279行左右有个要改成:pidfile /var/redis/run/redis.pid (他可能是redis_6379,就是现在改,然后后面可能会在改回来)然后444行左右改成
dir /var/redis/data 292行左右改成 logfile /var/redis/log/redis.log 然后247行左右有个daemonize no 中要把no改成yes.改为后保存然后reboot重启虚拟机,然后redis-server /etc/redis/redis.conf 启动服务。
6.查看pid信息,进入/var/redis/run目录,然后ll看看total是不是4,是就对了,在/var/redis/data/ 到这个目录ll看看是不是4,是就对了,最后在到/var/redis/log/目录ll看看是不是4或者8,如果是就对了,8是因为日志没打开一次就生成一个,是累加的。
7.测试客户端连接:到/bin/目录下,然后敲 redis-cli 看看有没有进入到端口号,有就可以了,退出就直接Ctrl+C
redis 服务及开机自启动
1.拷贝解压包下utils下redis启动脚本至/etc/init.d/:
cp utils/redis_init_script /etc/init.d/
2.修改脚本名称为redis,即在/etc/init.d/的目录下执行:mv redis_init_script redis
3.修改这个redis文件,即在/etc/init.d/目录下直接vim redis
4.修改内容:直接把最后那个PIDFILE和CONF改成下面这两个目录:
PIDFILE=/var/redis/run/redis_${REDISPORT}.pid (注意有redis,要全部一样,看清楚)
CONF="/etc/redis/redis_${redisport}.conf"
5.对应修改文件名
mv /var/redis/run/redis.pid /var/redis/run/redis_6379.pid
mv /etc/redis/redis.conf /etc/redis/redis_6379.conf
6.把/etc/redis/redis.conf(此时redis.conf应该变成了redis_6379.conf,文档里面错了,不管它)中279行改成 pidfile /var/redis/run/redis_6379.pid
7.在/etc/init.d/目录下看看能不能启动和关闭redis
service redis start
service redis stop 没报错就是可以。
8.给启动脚本添加权限,使他可以在其他目录下可以启动:
chmod +x /etc/init.d/redis
删除权限是: chmod –x /etc/init.d/redis
9.设置自启动: chkconfig reids on
第三章:Hadoop集群的搭建
注意:三台虚拟机登录时为root 和123456,密码是老师设好了,没有改
1.克隆后的虚拟机需要注意的点:
1.vim /etc/udev/rules.d/70-persistent-net.rules 删除eth0该行;将eth1修改为eth0,同时复制物理ip地址
2.vim /etc/sysconfig/network-scripts/ifcfg-eth0
HWADDR=00:0c:29:7f:24:b3
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.110.101
NETMASK=255.255.255.0
GATEWAY=192.168.110.2
DNS1=8.8.8.8
3.vim /etc/sysconfig/network 改主机名
4.vim /etc/hosts 修改hosts文件:
192.168.110.101 hadoop101.hadoop.com hadoop101
192.168.110.102 hadoop102.hadoop.com hadoop102
192.168.110.103 hadoop103.hadoop.com hadoop103
5.service iptables stop
chkconfig iptables --list
chkconfig iptables off
chkconfig iptables --list
6.reboot 重启
host文件放在 vim /etc/hosts中 ,修改主机名:vim /etc/sysconfig/network
yum 安装程序:yum -y install 软件名
2.定时任务:
crontab -e 编辑,然后输入:*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
查看:crontab -l
3.相关指令:
创建目录:mkdir -p /export/servers
window上传文件;rz -E
移动文件:mv jdk..tar.gz /export/softwares
解压:cd /export/softwares/ tar -zxvf jdk..tar.gz -C ../servers/
拷贝文件: scp -r /export/servers/jdk.../ hadoop102:/export/servers/
配置环境变量:vim /etc/profile
使配置生效:source /etc/profile
格式化HDFS:如果是第一次格式化可以直接在hadoop-3.1.2目录下执行:bin/hdfs namenode -formate 如果不是第一次格式化,就要先关掉进程,即(stop-dfs) 在删掉datas文件夹和logs 文件夹。
4.启动和关闭集群命令:
/export/servers/hadoop-3.1.3/sbin/start-dfs.sh
/export/servers/hadoop-3.1.3/sbin/start-yarn.sh
mapred --daemon start historyserver
启动hdfs后可以在第一台看到:namenode、datanode、secondarynamenode
http://192.168.181.101:50070/dfshealth.html#tab-overview
启动yarn后可以在第一台看到:nodeManger、ResourceManager
http://192.168.81.101:8088/cluster
/export/servers/hadoop-3.1.2/sbin/stop-all.sh
mapred --daemon stop historyserver
第四五章:HDFS 、Mapreduce(虚拟机可不用操作)
…此处省略“亿”万字 两个文件里面的知识点要细看
1.查看文件
1.查看生成的文件:
hadoop fs -ls /wordcount/output
2.查看统计结果:
hadoop fs -cat /wordcount/output/part-r-00000
2.IDEA打包文件
使用maven将项目打包成jar包,点击maven,在Lifecycle中双击选择package


此时,留意地下的Run窗口在进行打包。
打包后,在工程中生成target文件夹
其中mapreduce_wordcount-1.0-SNAPSHOT.jar就是打包好的jar包。
把 mapreduce_wordcount-1.0-SNAPSHOT.jar 拷贝出来。

MapReduce作业运行
采用集群运行模式
-
将 MapReduce 程序提交给 Yarn 集群, 分发到很多的节点上并发执行
-
处理的数据和输出结果应该位于 HDFS 文件系统
-
提交集群的实现步骤: 将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
运行hadoop作业:
1.将项目打包成mapreduce_wordcount-1.0-SNAPSHOT.jar,并且上传到hadoop101机器的/export/software 目录
| cd /export/softwares/ |
|---|
| rz -E |

2.运行写好的wordcount代码:
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar com.zhang.mapreduce.WcMrJob
提交作业,运行作业
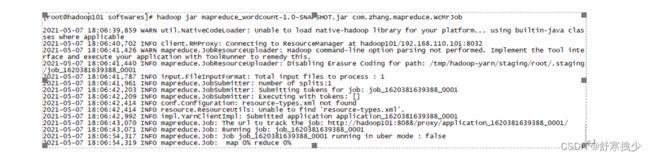
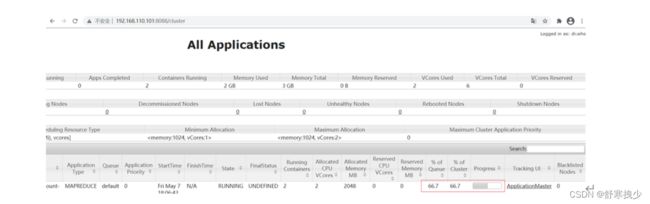
执行后打开yarn的资源调度平台 http://192.168.181.101:8088/cluster
如下,比如现在的进度只有66.7%,要等全部运行完成。
等待一段时间。
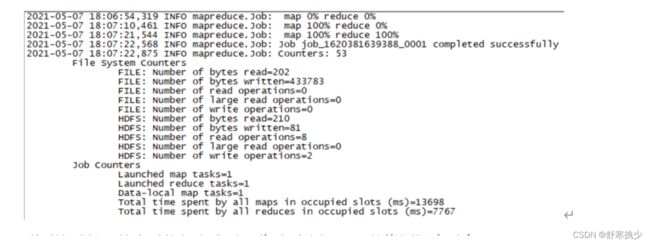
到了这时候,就表示执行完成了。此时再访问yarn的资源调度平台 http://192.168.181.101:8088/cluster

3.查看生成的文件:
hadoop fs -ls /wordcount/output
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V4bOYt40-1651310939665)(C:\Users\33090\AppData\Roaming\Typora\typora-user-images\image-20220430172656459.png)]](http://img.e-com-net.com/image/info8/48ab2f69f0f647a3932618b5b81132a3.jpg)
或者查看 http://192.168.181.101:50070/explorer.html#/wordcount
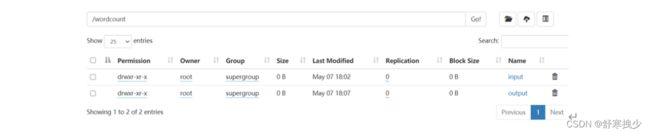
留意wordcount目录下已经生成output结果了。里面有两个文件
SUCCESS:这个是mapreduce作业执行成功的标志。
part-r-00000:这个是执行成功后,结果数据保存的文件。
4.查看统计结果:
hadoop fs -cat /wordcount/output/part-r-00000

可以看到词频统计的结果。
第六章:zookeeper
搭建集群zookeeper
1.cd /export/softwares/
2.rz -E
3.tar -zxvf zookeeper-3.4.10.tar.gz -C /export/servers/(目录为softwares)
4.修改zookeeper的名称为zookeeper:
cd /export/servers/
mv zookeeper-3.4.10 zookeeper
5.修改配置文件:
将/export/server/zookeeper/conf这个路径下的zoo_sample.cfg拷贝一份并改名zoo.cfg;
cd zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
6.打开zoo.cfg文件,修改dataDir路径:
dataDir=/export/servers/zookeeper/zkData
然后在最后面加上:
server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
7.在/export/servers/zookeeper/这个目录上创建zkData文件夹;
[root@hadoop101 conf]# cd ..
[root@hadoop101 zookeeper]# mkdir zkData
8.在/export/software/zookeeper/zkData目录下创建一个myid的文件
[root@hadoop101 zookeeper]# cd zkData
[root@hadoop101 zkData]# touch myid
9.编辑myid,填写server对应的编号,101填1,102填2,103填3
[root@hadoop101 zkData]# vi myid
1
10.编辑日志存放的目录
[root@hadoop101 zookeeper]# cd bin
[root@hadoop101 bin]# vim zkEnv.sh
注意里面的ZOO_LOG_DIR="."表示在哪里启动zookeeper,就把日志写在哪里,可以找个地方存放日志,修改为:
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/export/servers/zookeeper/logs"
fi
11.拷贝配置好的zookeeper到其他机器上
[root@hadoop101 bin]# cd /export/servers/
[root@hadoop101 servers]# scp -r zookeeper/ hadoop102:$PWD
[root@hadoop101 servers]# scp -r zookeeper/ hadoop103:$PWD
12.并分别在hadoop102、hadoop103上修改myid文件中内容为2、3
[root@hadoop102 zkData]# vi myid
2
[root@hadoop103 zkData]# vi myid
3
13.最后检测102和103是否有对应的文件,比如:/export/servers/zookeeper/zkData/myid
的数字是否正确,myid是不是在zkData目录下。还有检查配置文件:/export/servers/zookeeper/conf下的zoo.cfg看看dataDir有没有改过来,已经下面有没有2888.3888这些。最后查看/export/servers/zookeeper/bin/下面的zkEnv.sh文件,看看里面的ZOO_LOG_DIR是不是logs的目录。可以就对了。
启动zookeeper集群
三台主机分别启动:
[root@hadoop101 zookeeper]# bin/zkServer.sh start
然后查看状态:
[root@hadoop102 zookeeper]# bin/zkServer.sh status
只有一半以上启动整个集群才会启动,不然可能会报错
查看jps:有:QuorumPeerMain
启动客户端:[root@hadoop101 zookeeper]# bin/zkCli.sh
退出客户端:quit
关闭zookeeper:bin/zkServer.sh stop
第七章:hive(文档+下面这个)
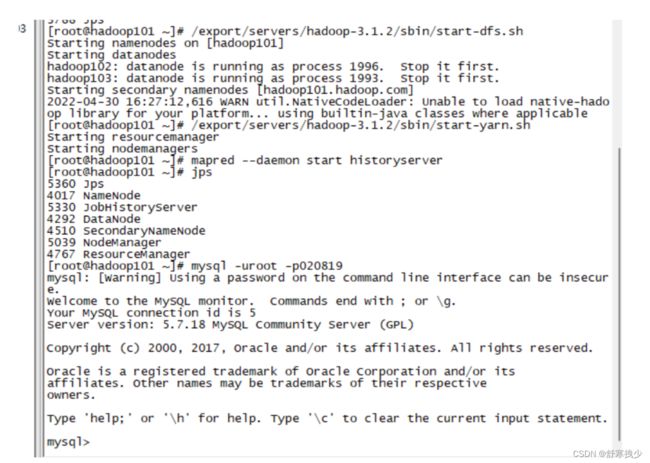
安装MySQL 5.7.18(密码:Root020819!)
安装步骤
rpm包形式安装
需要注意,这些命令全部在root用户下执行。
卸载CentOS自带MySQL
service mysqld stop
rpm -qa | grep -i mysql
rpm -e mysql组件名称 --nodeps
或者和上面的一样可以直接这样操作:(都一样)
一、查看CentOS下是否已安装mysql
输入命令 :yum list installed | grep mysql
二、删除已安装mysql
输入命令:
yum -y remove mysql
如果有:其他的文件也移除
yum -y remove mysql-libs.x86_64
yum -y remove mysql5.7-community-release.noarch
看到complete就说明成功了
获取与上传安装包
安装包可由以下地址下载。
https://downloads.mysql.com/archives/community/
或执行以下命令下载。
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.18-1.el6.x86_64.rpm-bundle.tar
将mysql-5.7.18-1.el6.x86_64.rpm-bundle.tar上传到服务器,并进行解压。
cd /export/softwares
mkdir -p /export/softwares/mysql
第一种方法:速度很慢,已经下载过了,在软件的目录下
在mysql目录下执行:wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.18-1.el6.x86_64.rpm-bundle.tar 即下载这个东西到mysql这个目录下,(下载速度可能及其慢)然后解压,也是到这个目录下
第二种方法:比较快:
直接谷歌打开下载:https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.18-1.el6.x86_64.rpm-bundle.tar ,记住下载位置,然后到mysql的目录下直接rz -E 把文件拉进来
解压:
tar -xvf mysql-5.7.18-1.el6.x86_64.rpm-bundle.tar -C /export/softwares/mysql
安装MySQL
rpm -ivh mysql-community-common-5.7.18-1.el6.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.18-1.el6.x86_64.rpm
rpm -ivh mysql-community-client-5.7.18-1.el6.x86_64.rpm
rpm -ivh mysql-community-server-5.7.18-1.el6.x86_64.rpm
MySQL启动
service mysqld start
原文链接:https://blog.csdn.net/xuhf_1988/article/details/109988002
遇到问题:安装MySQL的那些rpm出问题
[root@hadoop101 mysql]# cd ..
[root@hadoop101 softwares]# sudo rpm -ivh mysql-community-common-5.7.18-1.el6.x86_64.rpm
error: open of mysql-community-common-5.7.18-1.el6.x86_64.rpm failed: No such file or directory
[root@hadoop101 softwares]# rpm -ivh mysql-community-common-5.7.18-1.el6.x86_64.rpm
error: open of mysql-community-common-5.7.18-1.el6.x86_64.rpm failed: No such file or directory

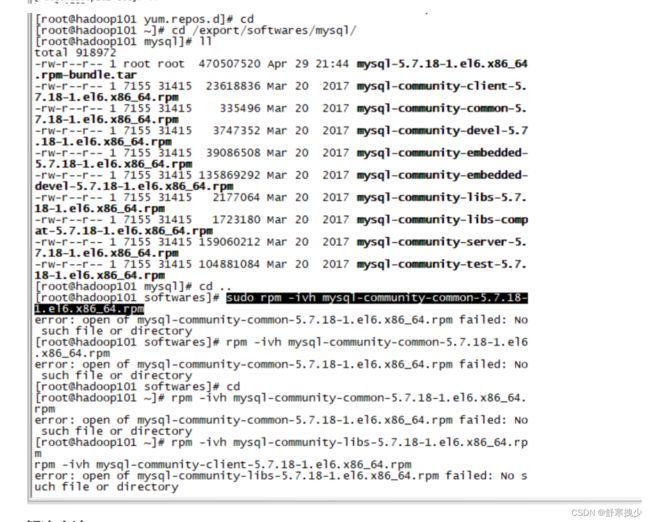
解决方法:
1.查看mysql依赖,这种错误就是依赖的问题,首先检查依赖有没有删除
rpm -qa | grep mysql
2.如果查看有mysql依赖,就删除mysql依赖,
rpm -e --nodeps rpm -qa | grep mysql
3.再次查是否有mysql依赖
rpm -qa | grep mysql
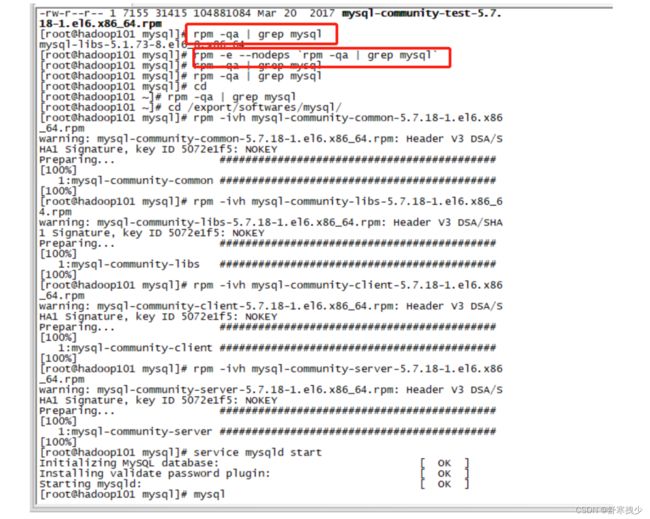
MySQL登录
MySQL启动
service mysqld start
修改MySQL密码
mysql在初始化的时候会生成临时密码,我们通过日志中,将临时密码找到。
grep 'temporary password' /var/log/mysqld.log
在A temporary password is generated for root@localhost:后面的就是默认密码,我们将默认密码进行复制。
登录MySQL
mysql -uroot -p
输入默认密码进行登录。登录后,使用如下命令修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root020819!';
(有些是可以直接set password=password('020819'))
MySQL服务器装好以后,默认只能在localhost上登录,如果你要是从另外的IP地址登录,即使是本机登录也会出现问题。
grant all privileges on *.* to 'root'@'%' identified by 'Root020819!' with grant option;
最好在添加下面这个,因为这样设置后面hive可能还好报错,所有在设置下面这个,以防万一:
mysql> grant all on *.* to 'root'@'hadoop101.hadoop.com' identified by 'Root020819!';
Query OK, 0 rows affected, 1 warning (0.00 sec)
FLUSH PRIVILEGES;
原文链接:https://blog.csdn.net/xuhf_1988/article/details/109988002
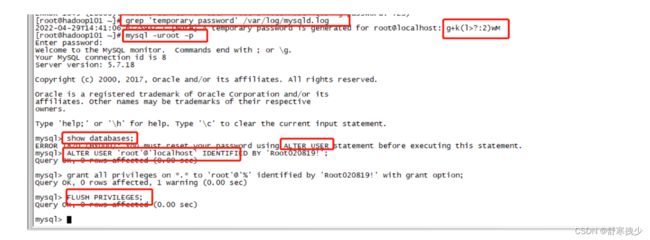
注意:如果要允许其他主机登录或者本机登录就要将root用户登录设置%,即都可以登录的意思:
查看是不是%:
1.show databases;
2.use mysql;
3.show tables;
4.select host,user from user;
不是就改,命令如下:在mysql 下面执行
方法一:
grant all privileges on . to ‘root’@‘%’ identified by ‘Root020819!’ with grant option;
FLUSH PRIVILEGES;
方法二:
update mysql.user set host=‘%’ where user=‘root’;
FLUSH PRIVILEGES;
配置MySQL
修改/etc/my.cnf 配置文件,主要是为了修改字符编码,在修改完成后,将MySQL重新启动。
vim /etc/my.cnf
在配置文件中,在[mysqld]下新增如下:
character_set_server=utf8
在文件最后增加如下配置:
[client]
default-character-set=utf8
最后重启MySQL。
service mysqld restart
重新登录数据库,执行如下命令:
SHOW VARIABLES LIKE 'character%';
我们可以看到,字符编码已经修改为utf8。
设置开启自启
chkconfig --add mysqld
chkconfig mysqld on
原文链接:https://blog.csdn.net/xuhf_1988/article/details/109988002
修改已经设置过的密码
报错:Your password does not satisfy the current policy requirements
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> update user set password = password ('020819') where user = 'root';
ERROR 1054 (42S22): Unknown column 'password' in 'field list'
mysql> update user set host = host ('020819') where user = 'root';
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '('020819') where user = 'root'' at line 1
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '020819';
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
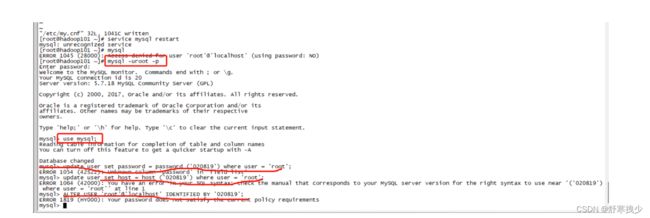
这是 mysql 初始化时,使用临时密码,修改自定义密码时,由于自定义密码比较简单,就出现了不符合密码策略的问题。
解决方法1:(针对自己的)
1、查看 mysql 初始的密码策略,
输入语句 “ SHOW VARIABLES LIKE ‘validate_password%’; ” 进行查看,
2、首先需要设置密码的验证强度等级,设置 validate_password_policy 的全局参数为 LOW 即可,
输入设值语句 “ set global validate_password_policy=LOW; ” 进行设值,
3.当前密码长度为 8 ,如果不介意的话就不用修改了,按照通用的来讲,设置为 6 位的密码,设置 validate_password_length 的全局参数为 6 即可,
输入设值语句 “ set global validate_password_length=6; ” 进行设值,
4.现在可以为 mysql 设置简单密码了,只要满足六位的长度即可,
输入修改语句 “ ALTER USER ‘root’@‘localhost’ IDENTIFIED BY ‘123456’; ” 可以看到修改成功,表示密码策略修改成功了!!!
5.刷新权限:flush privileges;

解决方法2:
1.修改MySQL的登录设置:
vim /etc/my.cnf
在[mysqld]的段中加上一句:skip-grant-tables
2.重新启动mysql
service mysql restart
3.登录并修改MySQL的root密码
mysql> use mysql;
Database changed
mysql> update user set password = password ('new-password') where user = 'root';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 5 Changed: 0 Warnings: 0
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
mysql> quit
4.将MySQL的登录设置修改回来
vim /etc/my.cnf
将刚才在[mysqld]的段中加上的skip-grant-tables注释
保存并且退出vim
5.重新启动mysql
service mysql restart
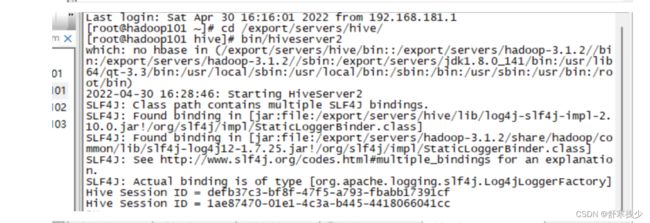
将Hive元数据配置到MySQL
启动hive之前要先启动hdfs 、yarn、mapreduce.
启动命令:
/export/servers/hadoop-3.1.2/sbin/start-hdfs.sh
/export/servers/hadoop-3.1.2/sbin/start-yarn.sh
mapred --daemon start historyserver
启动hive初始化命令报错
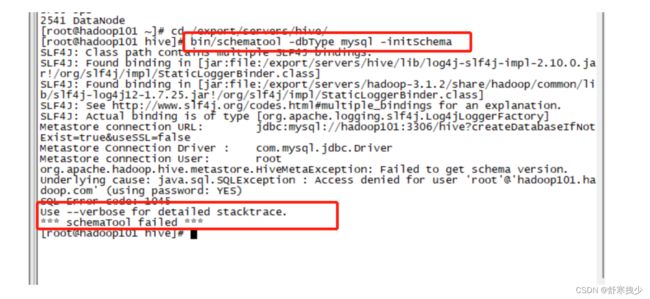
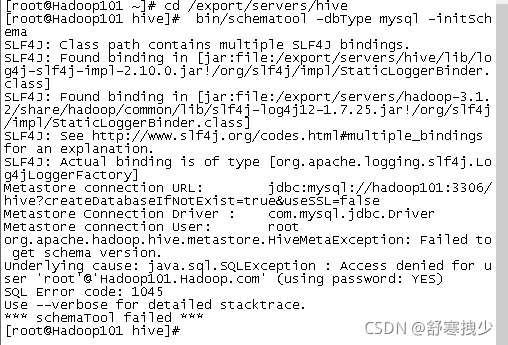
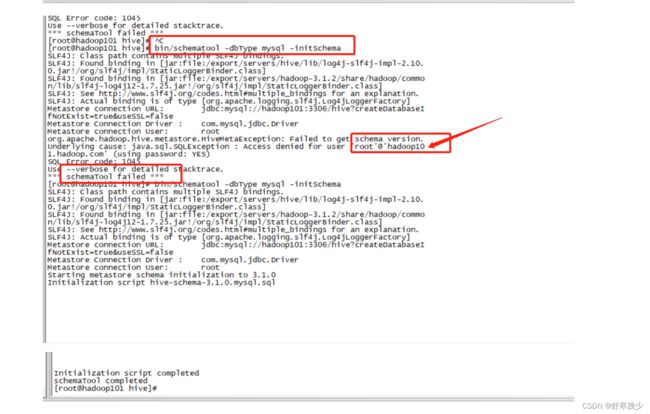
[root@hadoop101 hive]# bin/schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/servers/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/servers/hadoop-3.1.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hadoop101:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : Access denied for user 'root'@'hadoop101.hadoop.com' (using password: YES)
SQL Error code: 1045
Use --verbose for detailed stacktrace.
*** schemaTool failed ***
之前的解决方法
1.启动hive需要执行初始化命令:(可在101开另一个终端执行)
bin/schematool -dbType mysql -initSchema
遇到的问题:
查了一下说是root用户权限不够。百度了好多,跟着弄了好几个,都错了,最后发现可能是我配置文件和自己设置的密码不一样导致的错误,最后我是这样解决的【修改hive-site.xml文件,使密码一致】,【service mysql restart】重启mysql服务,这时候应该会输入密码,输入之后,就可以正常授权了。
! 
打开hive-site.xml ,找到下面连接密码这里,将1234给为你登录MySQL的密码即可。
现在的问题:密码没错,但是还是报错了
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : Access denied for user ‘root’@‘hadoop101.hadoop.com’ (using password: YES)
具体原因可能是用户权限不足。之前感觉设置了,但是可能没有设置到。
解决方法:
参考:https://blog.csdn.net/peterchan88/article/details/78341852
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
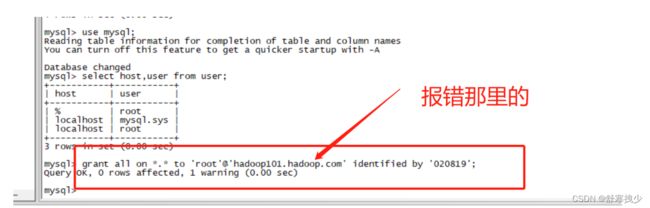
mysql> select host,user from user;
+-----------+-----------+
| host | user |
+-----------+-----------+
| % | root |
| localhost | mysql.sys |
| localhost | root |
+-----------+-----------+
3 rows in set (0.00 sec)
mysql> grant all on *.* to 'root'@'hadoop101.hadoop.com' identified by '020819';
Query OK, 0 rows affected, 1 warning (0.00 sec)
连接hiveserver2出错:
报错1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9jKS1FJ3-1651310939668)(C:\Users\33090\AppData\Roaming\Typora\typora-user-images\image-20220430163907345.png)]](http://img.e-com-net.com/image/info8/a9f912a45d184327904354143cdfa16e.jpg)
解决方法:
可以在hadoop的core-site.xml(/export/servers/hadoop-3.1.2/etc/hadoop/core-site.xml)中增加如下配置信息
<!-- 解决root is not allowed to impersonate root错误 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>root</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
并重启,即可解决。
报错2:
[main]: WARN jdbc.HiveConnection: Failed to connect to hadoop101:10000
Could not open connection to the HS2 server. Please check the server URI and if the URI is correct, then ask the administrator to check the server status.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop101:10000: java.net.ConnectException: Connection refused (Connection refused) (state=08S01,code=0)

解决方法
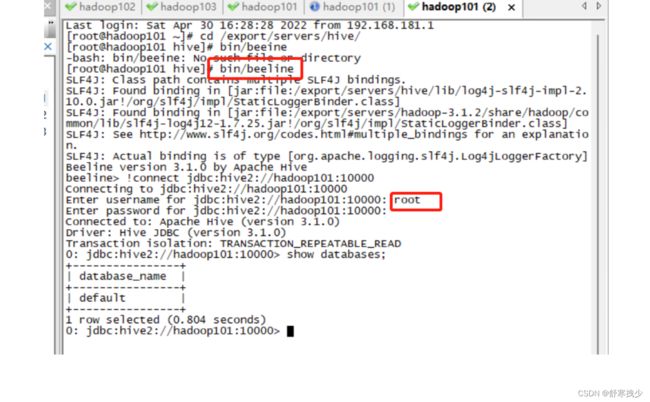
百度了大半个下午,一直没有找到解决的办法,最后在一篇博客看到了启动的顺序,发现第一次是我MySQL没有启动,然后重新配置完hadoop的core-site.xml后重启虚拟机后,忘了要启动hdfs和yarn,结果搞了半天没有明白为什么错。最后才知道就是启动顺序的问题:按下面顺序启动可以解决上面的的问题。
1.启动hdfs和yarn,mapreduce
2.启动mysql
3.在另一个终端启动bin/hiveserver2
4,在开一个终端启动:bin/beeline
5.完美启动。
第八章:flume(以下123可以直接敲的)
1.flume的安装步骤
(2和3是实操的,涉及一个监听的问题,所有可以一起配置进去,最后面的实操是可以暂时不弄,现在是先配置能用就行,实操后面有时间可以跟着操作)
1)将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下
[root@hadoop101 softwares]# cd /export/softwares/
[root@hadoop101 softwares]# rz -E
2)解压apache-flume-1.7.0-bin.tar.gz到/export/servers/目录下
[root@hadoop101 softwares]# tar -zxf apache-flume-1.7.0-bin.tar.gz -C /export/servers/
3)修改apache-flume-1.7.0-bin的名称为flume
[root@hadoop101 softwares]# cd /export/servers/
[root@hadoop101 softwares]# mv apache-flume-1.7.0-bin flume
4)将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
[root@hadoop101 softwares]# cd flume/conf
[root@hadoop101 conf]# mv flume-env.sh.template flume-env.sh
[root@hadoop101 conf]# vi flume-env.sh
在中间添加这一句
export JAVA_HOME=/export/servers/jdk1.8.0_141

2.监控工具的安装
1.安装netcat工具
[root@hadoop101 softwares]# cd /export/servers
[root@hadoop101 softwares]# yum install -y nc
2.判断44444端口是否被占用
[root@hadoop101 softwares]# netstat -tunlp | grep 44444
没有占用则不输出任何信息。确保该端口目前没有被占用。
3.创建Flume Agent配置文件flume-netcat-logger.conf
在flume目录下创建job文件夹并进入job文件夹。Job中主要放置各种各样的配置文件。
[root@hadoop101 softwares]# cd flume/
[root@hadoop101 flume]# mkdir job
[root@hadoop101 flume]# cd job/
在job文件夹下创建Flume Agent配置文件flume-netcat-logger.conf。(输入源是netcat,输出是logger)
[root@hadoop101 job]# touch flume-netcat-logger.conf
在flume-netcat-logger.conf文件中添加如下内容。注意下面已经将a1.sources.r1.bind中的localhost改成0.0.0.0了,这样本机也可以直接监控发信息了
[root@hadoop101 job]# vim flume-netcat-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.监听步骤:
1.先开启flume监听端口
第一种写法:
[root@hadoop101 job]# cd /export/servers/flume
[root@hadoop101 flume]# bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
第二种写法:
[root@hadoop101 flume]# bin/flume-ng agent -c conf/ -n a1 –f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
2.在第二个终端中,通过netsat命令查看一下44444端口的占用情况。
[root@hadoop101 ~]# netstat -nltp | grep 44444
3.使用netcat工具向本机的44444端口发送内容
[root@hadoop101 ~]# nc localhost 44444
123
4.因为上面已经将localhost改成0.0.0.0了,所以也可以通过nc hadoop101 44444进行发送信息。
查看Java路径
echo $JAVA_HOME
第九章 Hbase
1:安装步骤(配合文档直接下面操作,张部长的有的地方要改)
1.首先保证Zookeeper集群的正常部署,并启动之:
[root@hadoop101 zookeeper]# bin/zkServer.sh start
[root@hadoop102 zookeeper]# bin/zkServer.sh start
[root@hadoop103 zookeeper]# bin/zkServer.sh start
Hadoop集群的正常部署并启动:
[root@hadoop101 hadoop-3.1.2]# sbin/start-dfs.sh
[root@hadoop102 hadoop-3.1.2]# sbin/start-yarn.sh
启动后jps查看:(保证有下面这些节点启动)
8033 JobHistoryServer
7187 SecondaryNameNode
9716 QuorumPeerMain
6724 NameNode
6871 DataNode
10604 Jps
7629 NodeManager
7469 ResourceManager
2.解压HBase到指定目录:
[root@hadoop101 software]# tar -zxvf hbase-1.3.1-bin.tar.gz -C /export/servers/
[root@hadoop101 software]# cd /export/servers/
[root@hadoop101 servers]# ln -s hbase-1.3.1/ hbase
注意注意:上面这个ln -s 是软链接的意思,实际目录是看不到的,但是它和mv hbase-1.3.1/ hbase 差不多是一个意思,可以直接servers/hbase ,在里面修改的东西和在hbase-1.3.1的内容是一样的,也是同步的。
3.修改HBase对应的配置文件。
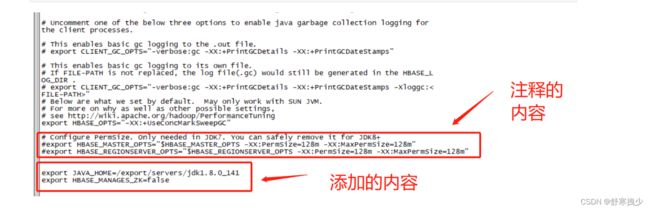
1)hbase-env.sh修改内容:(hbase/conf目录下)添加一下内容:
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
然后找到下面这两个,把他注释掉
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
2)hbase-site.xml修改内容:(hbase/conf目录下)
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/servers/zookeeper/zkData</value>
</property>
</configuration>
注意注意注意:这里面有几个地方要改:
1.<value>hdfs://hadoop101:8020/hbase</value>
看看自己电脑是101的还是110的,如果是110就要改成hadoop110。
另外一个,也是特别特别重要的,也是我花了将近一个晚上才解决的问题,就是端口问题,我自己的hdfs端口是8020,结果一开始没看清,而且张部长的文档写的是9000,然后我直接复制过去,一开始没注意到,然后运行也没有报错,和他的一样,我去尚硅谷看了视频也是一样,没问题,但是就是你后面访问hbase的时候会一直访问不了,就访问hadoop101:16010或者192.168.181.101的时候,一直是访问不了的,一定要把端口改成8020才可以。就是配置里面的所有要改的东西,你都要一个一个看好,复制过去后一定一定要改成自己的目录,路径和端口等等,不然一点点的东西都可能会导致你启动不了。而且而且要三台都改,或者后面用分发也行。
2.<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value> 这里的也一样,要看好。
3.<value>/export/servers/zookeeper-3.4.10/zkData</value> 这里是zookeeper的zkData,有的人不是zkData,看看自己设的是什么,我自己是zookeeper/zkData ,有些人是zookeeper-3.4.10的,要注意改过去。另外一个要注意hadoop的大小写问题。
3)regionservers:(hbase/conf目录下)
hadoop101
hadoop102
hadoop103
4)软连接hadoop配置文件到hbase:(最好是手敲,复制可能都会出错)
[root@hadoop101 servers]# ln -s /export/servers/hadoop3.1.2/etc/hadoop/core-site.xml /export/servers/hbase/conf/core-site.xml
[root@hadoop101 servers]# ln -s /export/servers/hadoop3.1.2/etc/hadoop/hdfs-site.xml /export/servers/hbase/conf/hdfs-site.xml
5)可以在/etc/profile中把hbase添加到环境变量PATH中(注意3台都要)
# HBASE_HOME
export HBASE_HOME=/export/servers/hbase
export PATH=$HBASE_HOME/bin:$PATH
在hadoop102、hadoop103机器上的/etc/profile文件中也可以加上hbase的环境变量。
4.HBase远程发送到其他集群
[root@hadoop101 servers]# scp -r hbase -1.3.1/ hadoop102:$PWD
[root@hadoop101 servers]# scp -r hbase -1.3.1/ hadoop103:$PWD
[root@hadoop102 servers]# ln -s hbase-1.3.1/ hbase
[root@hadoop103 servers]# ln -s hbase-1.3.1/ hbase
分发完成后,HBase就算是准备好了
2:Hbase 服务的启动
1.启动方式1(只能启动当前的那一台)
[root@hadoop101 servers]# cd hbase
[root@hadoop101 hbase]# bin/hbase-daemon.sh start master
[root@hadoop101 hbase]# bin/hbase-daemon.sh start regionserver
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
解决方法,设置时钟同步,可以先查看时钟是否同步,不同步就要设,有两种方法,一种是把2,3的时间设置和1的一样,另一种是把3台的时间都设置和阿里云的时钟一样,一般选第二种,前面有说到,如下:
crontab -e 编辑,然后输入:*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
查看:crontab -l 注意:三台都要编辑输入上面的内容。
2.启动方式2(推荐这一种,这种是3台都启动的)
[root@hadoop101 hbase]# bin/start-hbase.sh
3.启动成功后jps可以看到有HRegionServer这个进程。表示启动成功。
4.要看一下能不能访问下面这几个网站(根据自己的IP和Hadoop的命名来)
http://hadoop101:16010
http://192.168.181.101:16010
http://hadoop101:16030
http://192.168.181.101:16030
完结:怒肝一周结束

新章程:spark
1.安装步骤:
1.cd /export/softwares/
rz -E
2.tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /export/servers
3.mv spark-3.0.0-bin-hadoop3.2/ spark-local
4.启动:[root@hadoop101 spark]# bin/spark-shell
启动成功后,可以输入网址进行Web UI监控页面访问
输入网页地址:http://hadoop-001:4040
2.SecureCRT中Scala中无法退格和删除
问题:在写scala代码的时候,发现一个问题,就是写好了代码,却无法删除,这基本上就不能写代码了
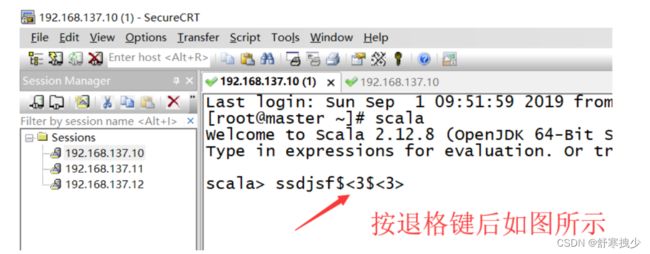
解决办法:
1.修改终端为Linux
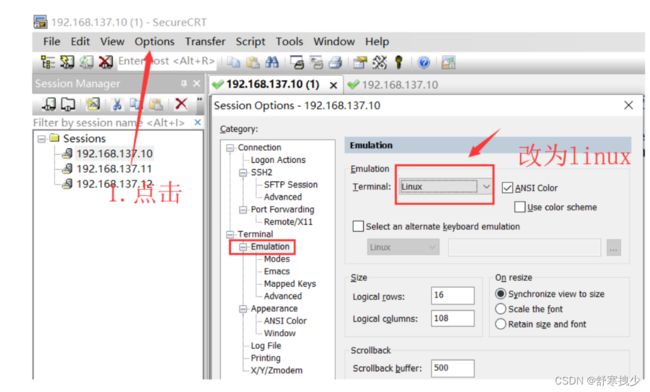
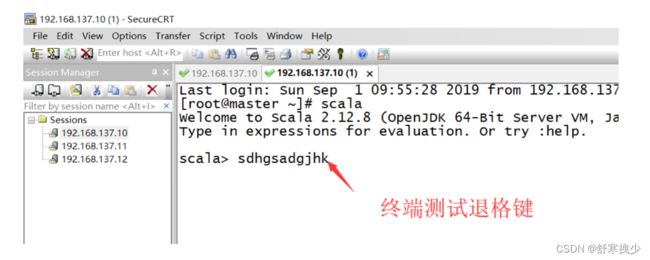
2.勾选图示两个映射。

3.重新打开终端测试退格键,已经可以成功删除。
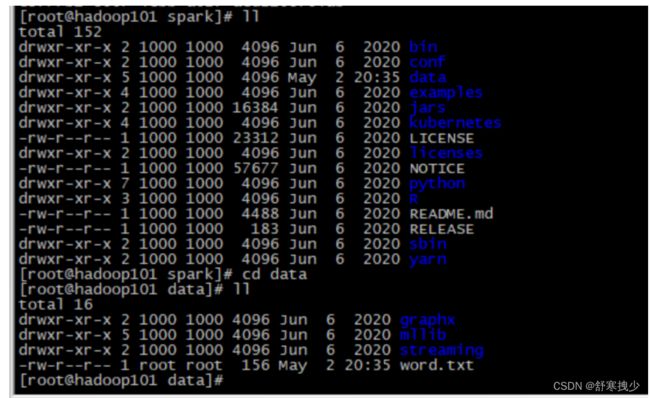
3.命令行工具
在解压缩文件夹下的data目录中,添加word.txt文件。在命令行工具中执行如下代码指令(和IDEA中代码简化版一致)
[root@hadoop101 data]#touch word.txt
[root@hadoop101 data]#vi word.txt
hadoop scala spark
hadoop hadoop hadoop
hadoop hadoop hadoop
hadoop hadoop hadoop
scala scala scala
scala scala scala
spark spark spark
scala hadoop hadoop
sc.textFile(“data/word.txt”).flatMap(.split(" ")).map((,1)).reduceByKey(+).collect

4.退出本地模式
按键Ctrl+C或输入Scala指令
:quit
5.直接提交应用
1:直接提交local本地应用,不用输入bin/spark-shell, 直接[root@hadoop101 spark]#输入
bin/spark-submit
–class org.apache.spark.examples.SparkPi
–master local[4]
./examples/jars/spark-examples_2.12-3.0.0.jar
10
-
–class表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
-
–master local[4] 部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量(看自己的,网络适配器那里的处理器可以查看多少个cup的)
-
spark-examples_2.12-3.0.0.jar 运行的应用类所在的jar包,实际使用时,可以设定为咱们自己打的jar包
-
数字10表示程序的入口参数,用于设定当前应用的任务数量
2.实战
1:代码:
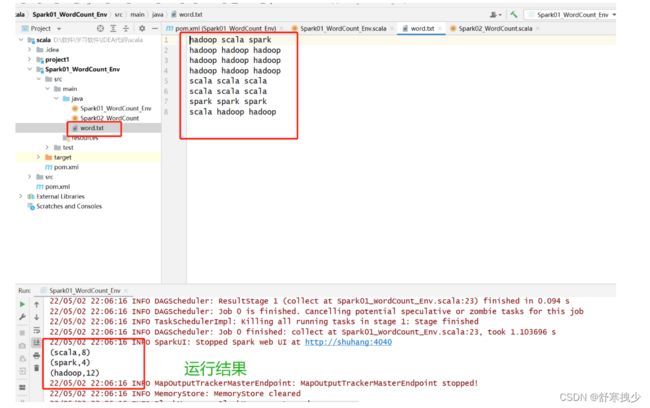
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount_Env {
def main(args: Array[String]): Unit = {
// TODO 使用Spark 25
// Spark是一个计算【框架】。
// 1. 能找到他 :增加依赖
// 2. 获取Spark的连接(环境)
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
// 读取文件
val lines = sc.textFile("D:/软件/学习软件/IDEA代码/scala/Spark01_WordCount_Env/src/main/java/word.txt")
println(lines)
println("--------------------")
// 将文件中的数据进行了分词
val words = lines.flatMap(_.split(" "))
// 将分词后的数据进行了分组
val wordGroup = words.groupBy(word => word)
// 对分组后的数据进行统计分析
val wordCount = wordGroup.mapValues(_.size)
// 将统计结果打印在控制台上
wordCount.collect().foreach(println)
sc.stop()
}
}
2.打包
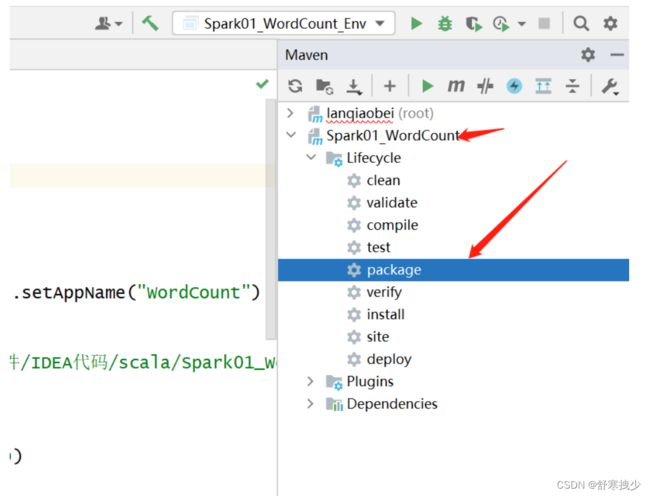

然后将这个文件移到Linux上的对应文件里面即:example下面的jars 。第一步移错位置了,后面改了,在/export/servers/spark/example/jars/

bin/spark-submit
–class Spark01_WordCount_Env
–master local[4]
./examples/jars/Spark01_WordCount-1.0-SNAPSHOT.jar
运行报错:
22/05/03 15:20:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/05/03 15:20:50 WARN DependencyUtils: Local jar /export/servers/spark/local[4] does not exist, skipping.
Error: Failed to load class Spark01_WordCount_Env--master.
22/05/03 15:20:50 INFO ShutdownHookManager: Shutdown hook called
22/05/03 15:20:50 INFO ShutdownHookManager: Deleting directory /tmp/spark-bd8f5055-446d-4796-8198-cbacdf8ca528

解决方法:
Standalone模式
1.安装
1.将spark-3.0.0-bin-hadoop3.2.tgz文件上传到Linux并解压缩在指定位置
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /export/servers
cd /export/servers
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2.修改配置文件
1)进入解压缩后路径的conf目录,修改slaves.template文件名为slaves
mv slaves.template slaves
2)修改slaves文件,添加worker节点(看自己电脑的命名)
hadoop101
hadoop102
hadoop103
3)修改spark-env.sh.template文件名为spark-env.sh
修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
export JAVA_HOME=/export/servers/jdk1.8.0_141
SPARK_MASTER_HOST=hadoop101
SPARK_MASTER_PORT=7077
上面要注意的是主机名和Java的路径,7077是默认端口 Java路径查询方法:
[root@hadoop101 spark-standalone]# echo $JAVA_HOME
/export/servers/jdk1.8.0_141
3.分发到另外两台主机
[root@hadoop101 servers]# scp -r spark-standalone/ hadoop102:$PWD
[root@hadoop101 servers]# scp -r spark-standalone/ hadoop103:$PWD
2.启动集群
- 执行脚本命令:
[root@hadoop101 spark-standalone]# sbin/start-all.sh
- 查看三台服务器运行进程
================hadoop-001================
3330 Jps
3238 Worker
3163 Master
================hadoop-002================
2966 Jps
2908 Worker
================hadoop-003================
2978 Worker
3036 Jps
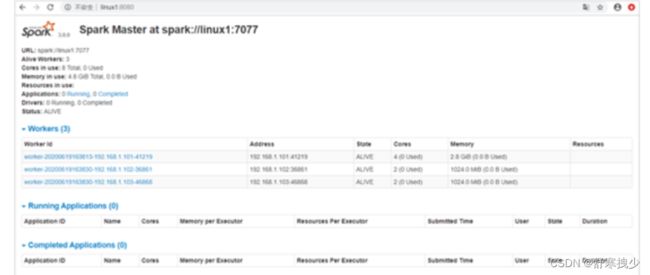
- 查看Master资源监控Web UI界面: http://hadoop-001:8080
- 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
-
–class表示要执行程序的主类
-
–master spark://hadoop-001:7077 独立部署模式,连接到Spark集群
-
spark-examples_2.12-3.0.0.jar 运行类所在的jar包
-
数字10表示程序的入口参数,用于设定当前应用的任务数量
3.配置历史服务
- 由于spark-shell停止掉后,集群监控hadoop-001:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
如何配置
1) 修改spark-defaults.conf.template文件名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(直接复制进去就好)
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop101:8020/directory
注意:这里不是hadoop-001:9820,因为自己访问hdfs的端口是8020
注意:需要启动hadoop集群,HDFS上的directory目录需要提前存在。(可以到hdfs上面看到)
sbin/start-dfs.sh
hadoop fs -mkdir /directory
3) 修改spark-env.sh文件, 添加日志配置(下面也是改成hadoop101:8020,然后直接复制进去)
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop101:8020/directory
-Dspark.history.retainedApplications=30"
- 参数1含义:WEB UI访问的端口号为18080
- 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4) 分发配置文件(分发到另外两台去)
[root@hadoop101 conf]# scp -r spark-env.sh/ hadoop102:$PWD
[root@hadoop101 conf]# scp -r spark-env.sh/ hadoop103:$PWD
[root@hadoop101 conf]# scp -r spark-defaults.conf/ hadoop102:$PWD
[root@hadoop101 conf]# scp -r spark-defaults.conf/ hadoop103:$PWD
分发后到相应的目录查看一下是否和第一台的一样。
5) 重新启动集群和历史服务
[root@hadoop101 spark-standalone]# sbin/start-all.sh
[root@hadoop101 spark-standalone]# jps
3873 NameNode
4949 Master
4022 DataNode
5081 Jps
5021 Worker
4334 SecondaryNameNode
[root@hadoop101 spark-standalone]# sbin/start-history-server.sh
6) 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
7) 查看历史服务:http://hadoop101:18080
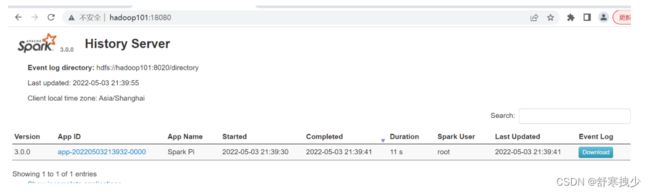
4.配置高可用(HA)
所谓的高可用是因为当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置
配置方式
1) 停止集群
[root@hadoop101 spark-standalone]# sbin/stop-all.sh
2) 修改spark-env.sh文件添加如下配置
[root@hadoop101 conf]# vi spark-env.sh
注释如下内容:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop101,hadoop102,hadoop103
-Dspark.deploy.zookeeper.dir=/spark"
3) 分发到另外两台:
[root@hadoop101 conf]# scp -r spark-env.sh/ hadoop102:$PWD
[root@hadoop101 conf]# scp -r spark-env.sh/ hadoop103:$PWD
4) 启动Zookeeper(3台都要,逐个启动)
[root@hadoop101 conf]# cd /export/servers/zookeeper/bin
[root@hadoop101 bin]# ./zkServer.sh start
5) .启动hdfs
cd /export/servers/hadoop-3.1.2/
sbin/start-dfs.sh
6) 启动集群
[root@hadoop101 spark-standalone]# cd sbin/
[root@hadoop101 sbin]# ./start-all.sh
[root@hadoop101 sbin]# jps
3200 Master
2289 QuorumPeerMain
3333 Jps
2536 NameNode
3016 SecondaryNameNode
3275 Worker
2685 DataNode
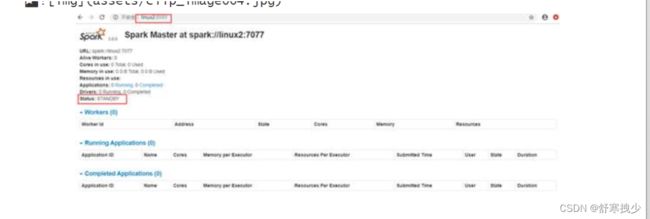
7) 启动linux2的单独Master节点,此时linux2节点Master状态处于备用状态
[root@linux2 spark-standalone]# sbin/start-master.sh
7) 提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077/,hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
8) 停止linux1的Master资源监控进程

9) 查看linux2的Master 资源监控Web UI,稍等一段时间后,linux2节点的Master状态提升为活动状态
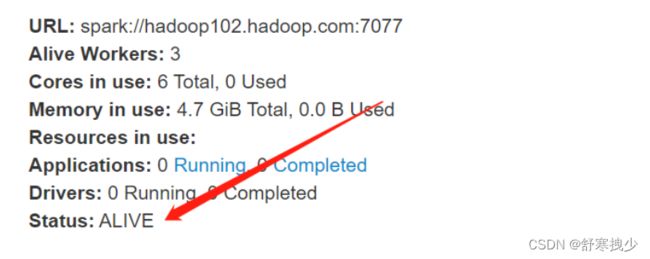
Yarn模式
[1]解压spark
tar -zxvf spark-2.1.1-bin-hadoop2.7 -C /export/servers/
[2]进入到/export/servers目录,修改spark-2.1.1-bin-hadoop2.7名称为spark-yarn
mv spark-2.1.1-bin-hadoop2.7/ spark-yarn
[3] 修改hadoop配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
直接添加下面内容,第二个可能已经有了
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
[4]分发配置文件
scp -r yarn-site.xml/ hadoop102:$PWD
scp -r yarn-site.xml/ hadoop103:$PWD
[5]修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
mv spark-env.sh.template spark-env.sh
vi spark-env.sh(下面这两个自己查一下目录在复制进去)
export JAVA_HOME=/export/servers/jdk1.8.0_212
YARN_CONF_DIR=/export/servers/hadoop-3.1.2/etc/hadoop
[6]分发spark-yarn
scp -r spark-yarn/ hadoop102:$PWD
scp -r spark-yarn/ hadoop103:$PWD
[7]启动HDFS以及YARN集群
start-dfs.sh
start-yarn.sh
[8]启动zookeeper(逐个启动)把那些其他节点(master,work这些)关了。
bin/zkServer.sh start
[9] 提交应用(要看自己example/jars目录下的jar的版本要对应上)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
报错
2022-05-04 10:27:18,727 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-05-04 10:27:18,765 INFO client.RMProxy: Connecting to ResourceManager at hadoop101/192.168.181.101:8032
2022-05-04 10:27:18,924 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
2022-05-04 10:27:19,199 INFO conf.Configuration: resource-types.xml not found
2022-05-04 10:27:19,199 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-05-04 10:27:19,209 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (1024 MB per container)
Exception in thread "main" java.lang.IllegalArgumentException: Required executor memory (1024 MB), offHeap memory (0) MB, overhead (384 MB), and PySpark memory (0 MB) is above the max threshold (1024 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.

解决方法:
改一下yarn-site.xml这个配置文件:
之前的配置文件:
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop101:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop101:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop101:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop101:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop101:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 设置不检查虚拟内存的值,不然内存不够会报错 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///export/servers/hadoop-3.1.2/datas/nodemanager/nodemanagerDatas</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///export/servers/hadoop-3.1.2/datas/nodemanager/nodemanagerLogs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/export/servers/hadoop-3.1.2/datas/remoteAppLog/remoteAppLogs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>18144000</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<!-- yarn上面运行一个任务,最少需要1.5G内存,虚拟机没有这么大的内存就调小这个值,不然会报错 -->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
直接改成下面这个,复制粘贴就可以:(注意主机名)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
注意改完配置文件后,需要重新启动hdfs和yarn以及zookeeper

[10]查看hadoop101:8088 页面,点击History,查看历史页面
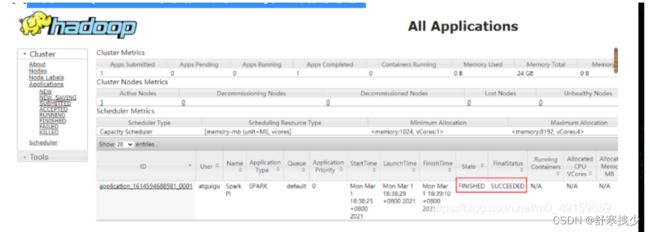
部署模式对比

端口号
-
Spark查看当前Spark-shell运行任务情况端口号:4040(计算)
-
Spark Master内部通信服务端口号:7077
-
Standalone模式下,Spark Master Web端口号:8080(资源)
-
Spark历史服务器端口号:18080
-
Hadoop YARN任务运行情况查看端口号:8088