2022/6/22 RabbitMQ讲解(入门案例)
目录
1丶什么是中间件
2丶为什么需要使用消息中间件
3丶中间件特点
4丶在项目中什么时候使用中间件技术
5丶中间件技术及架构的概述
6丶消息中间件应用的场景
7丶RabbitMQ简介
7.1丶RabbitMQ除了像兔子一样跑的很快以外,还有这些特点:
7.2丶MQ典型应用场景
7.3丶常见MQ对比
8丶AMQP协议和RabbitMQ
8.1丶常用交换器
8.1.1丶Direct Exchange
8.1.2丶Topic Exchange
8.1.3丶Fanout Exchange
8.1.4丶Headers Exchange
9丶安装RabbitMQ
9.1丶配置docker-compose
9.2丶 拉取镜像
9.3丶访问客户端
10丶使用RabbitMQ
10.1丶创建生产者丶消费者模块以及RabbitMQ工具类
10.1.1丶RabbitMQ工具类
10.1.2丶创建生产者
10.1.3丶创建消费者
10.2丶运行结果
10.2.1丶启动生产者
10.2.2丶启动消费者
11丶更多案例及资料

1丶什么是中间件
我国企业从20世纪80年代开始就逐渐进行信息化建设,由于方法和体系的不成熟,以及企业业务的市场需求的不断变化,一个企业可能同时运行着多个不同的业务系统,这些系统可能基于不同的操作系统、不同的数据库、异构的网络环境。现在的问题是,如何把这些信息系统结合成一个有机地协同工作的整体,真正实现企业跨平台、分布式应用。中间件便是解决之道,它用自己的复杂换取了企业应用的简单。
中间件(Middleware)是处于操作系统和应用程序之间的软件,也有人认为它应该属于操作系统中的一部分。人们在使用中间件时,往往是一组中间件集成在一起,构成一个平台(包括开发平台和运行平台),但在这组中间件中必须要有一个通信中间件,即中间件+平台+通信,这个定义也限定了只有用于分布式系统中才能称为中间件,同时还可以把它与支撑软件和使用软件区分开来
2丶为什么需要使用消息中间件
具体地说,中间件屏蔽了底层操作系统的复杂性,使程序开发人员面对一个简单而统一的开发环境,减少程序设计的复杂性,将注意力集中在自己的业务上,不必再为程序在不同系统软件上的移植而重复工作,从而大大减少了技术上的负担,中间件带给应用系统的,不只是开发的简便、开发周期的缩短,也减少了系统的维护、运行和管理的工作量,还减少了计算机总体费用的投入。
3丶中间件特点
为解决分布异构问题,人们提出了中间件(middleware)的概念。中间件时位于平台(硬件和操作系统)和应用之间的通用服务,如下图所示,这些服务具有标准的程序接口和协议。针对不同的操作系统和硬件平台,它们可以有符合接口的协议规范的多种实现。
也很难给中间件一个严格的定义,但中间件应具有如下的一些特点:
- 满足大量应用的需要
- 运行于多种硬件和 OS平台
- 支持分布计算,提供跨网络、硬件和 OS平台的透明性的应用或服务的交互
- 支持标准的协议
- 支持标准的接口
由于标准接口对于可移植性和标准协议对于互操作性的重要性,中间件已成为许多标准化工作的主要部分。对于应用软件开发,中间件远比操作系统和网络服务更为重要,中间件提供的程序接口定义了一个相对稳定的高层应用环境,不管底层的计算机硬件和系统软件怎样更新换代,只要将中间件升级更新,并保持中间件对外的接口定义不变,应用软件几乎不需任何修改,从而保护了企业在应用软件开发和维护中的重大投资。
简单说:中间件有个很大的特点,是脱离于具体设计目标,而具备提供普遍独立功能需求的模块。这使得中间件一定是可替换的。如果一个系统设计中,中间件是不可替代的,不是架构、框架设计有问题,那么就是这个中间件,在别处可能是个中间件,在这个系统内是引擎。
4丶在项目中什么时候使用中间件技术
在项目的架构和重构中,使用任何技术和架构的改变我们都需要谨慎斟酌和思考,因为任何技术的融入和变化都可能人员,技术,和成本的增加,中间件的技术一般现在一些互联网公司或者项目中使用比较多,如果你仅仅还只是一个初创公司建议还是使用单体架构,最多加个缓存中间件即可,不要盲目追求新或者所谓的高性能,而追求的背后一定是业务的驱动和项目的驱动,因为一旦追求就意味着你的学习成本,公司的人员结构以及服务器成本,维护和运维的成本都会增加,所以需要谨慎选择和考虑。
但是作为一个开放人员,一定要有学习中间件技术的能力和思维,否则很容易当项目发展到一个阶段在去掌握估计或者在面试中提及,就会给自己带来不小的困扰,在当今这个时代这些技术也并不是什么新鲜的东西,如果去掌握和挖掘最关键的还是自己花时间和经历去探讨和研究。
5丶中间件技术及架构的概述

6丶消息中间件应用的场景
- 跨系统数据传递
- 高并发的流量削峰
- 数据的并发和异步处理
- 大数据分析与传递
- 分布式事务
7丶RabbitMQ简介
官网:Messaging that just works — RabbitMQ
以熟悉的电商场景为例,如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或者失败,会带来较差的用户体验,如果在高并发的场景下,这样的处理显然是不合适的,那怎么进行优化呢?这就需要消息队列登场了。
消息队列提供一个异步通信机制,消息的发送者不必一直等待到消息被成功处理才返回,而是立即返回。消息中间件负责处理网络通信,如果网络连接不可用,消息被暂存于队列当中,当网络畅通的时候在将消息转发给相应的应用程序或者服务,当然前提是这些服务订阅了该队列。如果在商品服务和订单服务之间使用消息中间件,既可以提高并发量,又降低服务之间的耦合度。
RabbitMQ就是这样一款我们苦苦追寻的消息队列。RabbitMQ是一个开源的消息代理的队列服务器,用来通过普通协议在完全不同的应用之间共享数据。
RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于AMQP协议的。Erlang语言在数据交互方面性能优秀,有着和原生Socket一样的延迟,这也是RabbitMQ高性能的原因所在。可谓“人如其名”,RabbitMQ像兔子一样迅速。
7.1丶RabbitMQ除了像兔子一样跑的很快以外,还有这些特点:
- 开源、性能优秀,稳定性保障
- 提供可靠性消息投递模式、返回模式
- 与Spring AMQP完美整合,API丰富
- 集群模式丰富,表达式配置,HA模式,镜像队列模型
- 保证数据不丢失的前提做到高可靠性、可用性
7.2丶MQ典型应用场景
- 异步处理。把消息放入消息中间件中,等到需要的时候再去处理。
- 流量削峰。例如秒杀活动,在短时间内访问量急剧增加,使用消息队列,当消息队列满了就拒绝响应,跳转到错误页面,这样就可以使得系统不会因为超负载而崩溃。
- 日志处理
- 应用解耦。假设某个服务A需要给许多个服务(B、C、D)发送消息,当某个服务(例如B)不需要发送消息了,服务A需要改代码再次部署;当新加入一个服务(服务E)需要服务A的消息的时候,也需要改代码重新部署;另外服务A也要考虑其他服务挂掉,没有收到消息怎么办?要不要重新发送呢?是不是很麻烦,使用MQ发布订阅模式,服务A只生产消息发送到MQ,B、C、D从MQ中读取消息,需要A的消息就订阅,不需要了就取消订阅,服务A不再操心其他的事情,使用这种方式可以降低服务或者系统之间的耦合。
7.3丶常见MQ对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
| 单机吞吐量 | 万级,比RocketMQ丶Kafka低一个数量级 | 同ActiveMQ | 10万级,支撑高吞吐 | 10万级,高吞吐,一般配合大数据类的系统类的系统来进行实时数据计算丶日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十到几百个时候,吞吐量会大幅下降,在同等机器下,Kafka尽量保证topic数量不要过多,如果要支撑大规模的topic,需要增加更多的机器资源 | ||
| 时效性 | ms级 | 微秒级,这是RabbitMQ的一大特点,延迟最低 | ms级 | 延迟在ms级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到0丢失 | 同RocketMQ |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,并发性能很强,性能极好,延迟很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用 |
参考文档:MQ详解及四大MQ比较_cjrjc的博客-CSDN博客_各种mq对比
8丶AMQP协议和RabbitMQ
提到RabbitMQ,就不得不提AMQP协议。AMQP协议是具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
先了解一下AMQP协议中间的几个重要概念:
- Server:接收客户端的连接,实现AMQP实体服务。
- Connection:连接,应用程序与Server的网络连接,TCP连接。
- Channel:信道,消息读写等操作在信道中进行。客户端可以建立多个信道,每个信道代表一个会话任务。
- Message:消息,应用程序和服务器之间传送的数据,消息可以非常简单,也可以很复杂。有Properties和Body组成。Properties为外包装,可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body就是消息体内容。
- Virtual Host:虚拟主机,用于逻辑隔离。一个虚拟主机里面可以有若干个Exchange和Queue,同一个虚拟主机里面不能有相同名称的Exchange或Queue。
- Exchange:交换器,接收消息,按照路由规则将消息路由到一个或者多个队列。如果路由不到,或者返回给生产者,或者直接丢弃。RabbitMQ常用的交换器常用类型有direct、topic、fanout、headers四种,后面详细介绍。
- Binding:绑定,交换器和消息队列之间的虚拟连接,绑定中可以包含一个或者多个RoutingKey。
- RoutingKey:路由键,生产者将消息发送给交换器的时候,会发送一个RoutingKey,用来指定路由规则,这样交换器就知道把消息发送到哪个队列。路由键通常为一个“.”分割的字符串,例如“com.rabbitmq”。
- Queue:消息队列,用来保存消息,供消费者消费。
我们完全可以直接使用 Connection 就能完成信道的工作,为什么还要引入信道呢?
试想这样一个场景, 一个应用程序中有很多个线程需要从 RabbitMQ 中消费消息,或者生产消息,那么必然需要建立很多个 Connection,也就是许多个 TCP 连接。然而对于操作系统而言,建立和销毁 TCP 连接是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。 RabbitMQ 采用 TCP 连接复用的方式,不仅可以减少性能开销,同时也便于管理 。
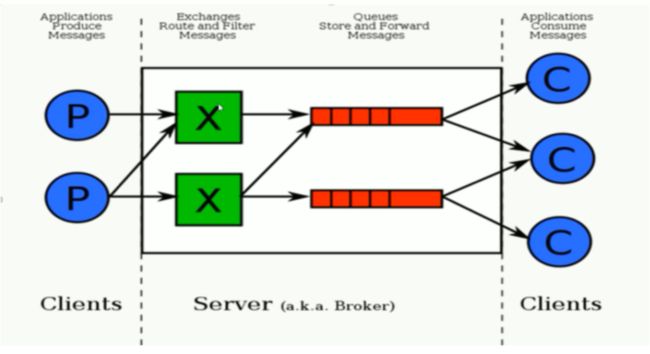
下图是AMQP的协议模型:

正如图中所看到的,AMQP协议模型有三部分组成:生产者、消费者和服务端。
生产者是投递消息的一方,首先连接到Server,建立一个连接,开启一个信道;然后生产者声明交换器和队列,设置相关属性,并通过路由键将交换器和队列进行绑定。同理,消费者也需要进行建立连接,开启信道等操作,便于接收消息。
接着生产者就可以发送消息,发送到服务端中的虚拟主机,虚拟主机中的交换器根据路由键选择路由规则,然后发送到不同的消息队列中,这样订阅了消息队列的消费者就可以获取到消息,进行消费。
最后还要关闭信道和连接。
RabbitMQ是基于AMQP协议实现的,其结构如下图所示,和AMQP协议简直就是一模一样。
8.1丶常用交换器
RabbitMQ常用的交换器类型有direct、topic、fanout、headers四种。
8.1.1丶Direct Exchange
该类型的交换器将所有发送到该交换器的消息被转发到RoutingKey指定的队列中,也就是说路由到BindingKey和RoutingKey完全匹配的队列中。
Exchange将RoutingKey和某Topic进行模糊匹配,其中“”用来匹配一个词,“#”用于匹配一个或者多个词。例如“com.#”能匹配到“com.rabbitmq.oa”和“com.rabbitmq”;而"login."只能匹配到“com.rabbitmq”。

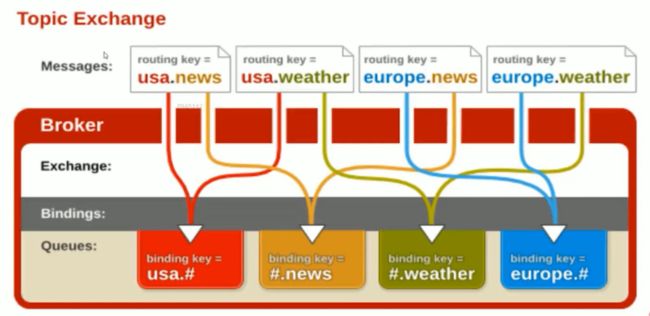
8.1.2丶Topic Exchange
该类型的交换器将所有发送到Topic Exchange的消息被转发到所有RoutingKey中指定的Topic的队列上面。
Exchange将RoutingKey和某Topic进行模糊匹配,其中“”用来匹配一个词,“#”用于匹配一个或者多个词。例如“com.#”能匹配到“com.rabbitmq.oa”和“com.rabbitmq”;而"login."只能匹配到“com.rabbitmq”。
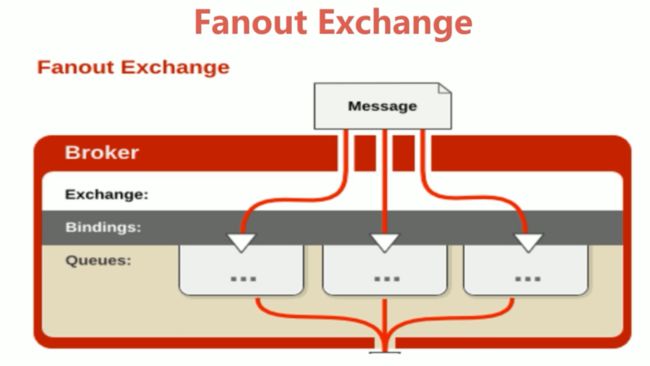
8.1.3丶Fanout Exchange
该类型不处理路由键,会把所有发送到交换器的消息路由到所有绑定的队列中。优点是转发消息最快,性能最好。
8.1.4丶Headers Exchange
该类型的交换器不依赖路由规则来路由消息,而是根据消息内容中的headers属性进行匹配。headers类型交换器性能差,在实际中并不常用。
9丶安装RabbitMQ
由于本机安装比较麻烦,这里我使用docker-compose安装到服务器上
9.1丶配置docker-compose
版本选择rabbitmq:3.9.14-management,带management标识的有客户端,需要开放4个端口号,15672与4396为客户端端口,5672与25672为服务端端口
rabbitmq:
hostname: rabbitmq
environment:
RABBITMQ_DEFAULT_VHOST: "root"
RABBITMQ_DEFAULT_USER: "root"
RABBITMQ_DEFAULT_PASS: "123456"
image: "rabbitmq:3.9.14-management"
restart: always
volumes:
- "/usr/local/bank/rabbitmq/data:/var/lib/rabbitmq"
- "/usr/local/bank/rabbitmq/log:/var/lib/rabbitmq/log"
ports:
- "15672:15672"
- "4369:4369"
- "5672:5672"
- "25672:25672"version: "3"
services:
mysql:
container_name: mysql
image: mysql:5.7
environment:
- MYSQL_ROOT_PASSWORD=123456
volumes:
- /app/cloud/mysql/data:/var/lib/mysql
ports:
- "3307:3306"
restart: always
nacos:
image: nacos/nacos-server:1.4.1
container_name: nacos
hostname: nacos
restart: always
environment:
- MODE=standalone
- TZ=Asia/Shanghai
- NACOS_SERVER_PORT=8848
- SPRING_DATASOURCE_PLATFORM=mysql
- MYSQL_SERVICE_HOST=xx.xxx.xxx.xx
- MYSQL_SERVICE_PORT=3307
- MYSQL_SERVICE_DB_NAME=nacos_config
- MYSQL_SERVICE_USER=root
- MYSQL_SERVICE_PASSWORD=123456
- PREFER_HOST_MODE=hostname
volumes:
- /app/cloud/nacos/logs:/home/nacos/logs
ports:
- "8848:8848"
sentinel:
image: bladex/sentinel-dashboard:1.8.0
container_name: sentinel
volumes:
- /etc/timezone:/etc/timezone
- /etc/localtime:/etc/localtime
ports:
- "8858:8858"
restart: always
rabbitmq:
hostname: rabbitmq
environment:
RABBITMQ_DEFAULT_VHOST: "root"
RABBITMQ_DEFAULT_USER: "root"
RABBITMQ_DEFAULT_PASS: "123456"
image: "rabbitmq:3.9.14-management"
restart: always
volumes:
- "/usr/local/bank/rabbitmq/data:/var/lib/rabbitmq"
- "/usr/local/bank/rabbitmq/log:/var/lib/rabbitmq/log"
ports:
- "15672:15672"
- "4369:4369"
- "5672:5672"
- "25672:25672"9.2丶 拉取镜像
运行这两句话服务器会自动拉取安装并启动服务
1丶docker-compose down 关闭容器所有服务
2丶docker-compose up -d 后台运行容器所有服务
9.3丶访问客户端
访问路径为你的服务器ip地址加端口号15672
这里我们设置了默认账号密码,账号为root ,密码为123456,登录进去。
这样就安装好了!
10丶使用RabbitMQ
10.1丶创建生产者丶消费者模块以及RabbitMQ工具类
10.1.1丶RabbitMQ工具类
所需jar包
com.rabbitmq
amqp-client
5.8.0
commons-io
commons-io
2.6
package com.hzf.common.utils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* rabbitmq的工具类
* @ClassName RabbitMQUtil
* @Description TODO
* @Author Mr.Huang
* @Date 2022/6/21 22:38
* @Version 1.0
**/
public class RabbitMQUtil {
public static Channel getChannel(){
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置主机 用户名 密码 虚拟分区
factory.setHost("xx.xxx.xxx.xx"); //主机地址填你的
factory.setUsername("root");
factory.setPassword("123456");
factory.setVirtualHost("root");
//channel 实现了自动 close 接口 自动关闭 不需要显示关闭
//创建连接
Connection connection = null;
Channel channel = null;
try {
connection = factory.newConnection();
//获取信道
channel=connection.createChannel();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return channel;
}
}10.1.2丶创建生产者
import com.rabbitmq.client.Channel;
/**
* 消息的生产者
* @ClassName Producer
* @Description TODO
* @Author Mr.Huang
* @Date 2022/6/21 22:05
* @Version 1.0
**/
public class Producer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtil.getChannel();
//通过信道可以发送消息,先定义队列,再给队列去发送消息
System.out.println("连接成功!");
/**
* 生成一个队列
* 1.队列名称
* 2.队列里面的消息是否持久化 也就是是否用完就删除
* 3.该队列是否只供一个消费者进行消费 是否进行共享 true 可以多个消费者消费
* 4.是否自动删除 最后一个消费者端开连接以后 该队列是否自动删除 true 自动删除
* 5.其他参数
*/
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "hello world";
/**
* 发送一个消息
* 1.发送到那个交换机
* 2.路由的 key 是哪个
* 3.其他的参数信息
* 4.发送消息的消息体
*/
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("消息发送完毕");
}
}10.1.3丶创建消费者
package com.hzf.consumer;
import com.hzf.common.utils.RabbitMQUtil;
import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
/**
* 消息的消费者
* @ClassName Consumer
* @Description TODO
* @Author Mr.Huang
* @Date 2022/6/21 22:11
* @Version 1.0
**/
public class Consumer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtil.getChannel();
System.out.println("等待接收消息.........");
//推送的消息如何进行消费的接口回调
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
//发送的消息,具体消费的内容
String message = new String(delivery.getBody());
System.out.println(message);
};
//取消消费的一个回调接口 如在消费的时候队列被删除掉了
//取消消息发送
CancelCallback cancelCallback = (consumerTag) -> {
System.out.println("消息消费被中断");
};
/**
* 消费者消费消息 - 接受消息
* 1.消费哪个队列
* 2.消费成功之后是否要自动应答 true 代表自动应答 false 手动应答
* 3.消费者未成功消费的回调
* 4.消息被取消时的回调
*/
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
10.2丶运行结果
10.2.1丶启动生产者


可以看到在客户端看到有一条消息待消费
10.2.2丶启动消费者

可以看到消息已经被消费。
- 消费者会一直监视着消息队列,一旦有消息进来,马上就会进行消费。
- 消息队列是不需要区分先有消费者还是先有生产者。
- 当多个消费者同时消费一个队列的消息时默认使用轮询消费,如果挂掉其中一个消费者,那么剩余消费者进行消费。
11丶更多案例及资料
地址:RabbitMQ - 知识体系 | OddFar's Notes
本文参考此网站