谷粒商城学习笔记
一、项目简介
1、项目背景
1)、电商模式

2)、谷粒商城
谷粒商城是一个 B2C 模式的电商平台,销售自营商品给客户。
2、项目架构图
1、项目微服务架构图
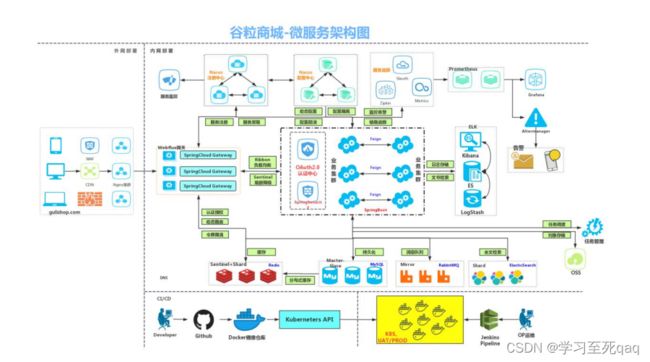
2、微服务划分图

3、项目技术&特色

4、项目前置要求

二、分布式基础概念
2、集群&分布式&节点
分布式是指将不同的业务分布在不同的地方。
集群指的是将几台服务器集中在一起,实现同一业务。
例如:京东是一个分布式系统,众多业务运行在不同的机器,所有业务构成一个大型的业务集群。每一个小的业务,比如用户系统,访问压力大的时候一台服务器是不够的。我们就 应该将用户系统部署到多个服务器,也就是每一个业务系统也可以做集群化; 分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。 节点:集群中的一个服务器
4、负载均衡

7、服务熔断&服务降级
1)、服务熔断 a. 设置服务的超时,当被调用的服务经常失败到达某个阈值,我们可以开 启断路保护机制,后来的请求不再去调用这个服务。本地直接返回默认 的数据
2)、服务降级 a. 在运维期间,当系统处于高峰期,系统资源紧张,我们可以让非核心业 务降级运行。降级:某些服务不处理,或者简单处理【抛异常、返回 NULL、 调用 Mock 数据、调用 Fallback 处理逻辑】。
三、项目架构
架构图

微服务划分图

四、环境搭建
docker
centos安装docker
https://docs.docker.com/engine/install/centos/
设置开机自启
systemctl enable docker
设置开机自启docker容器mysql服务
docker update mysql --restart=always
配置阿里云镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-‘EOF’
{
“registry-mirrors”: [“https://76ra8yjq.mirror.aliyuncs.com”]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
docker安装mysql
启动docker镜像
docker run -p 3306:3306
–name mysql
-v /mydata/mysql/log:/var/log/mysql
-v /mydata/mysql/data:/var/lib/mysql
-v /mydata/mysql/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root
-d mysql:5.7
参数说明-p 3306:3306:将容器的 3306 端口映射到主机的 3306 端口 -v /mydata/mysql/conf:/etc/mysql:将配置文件夹挂载到主机 -v /mydata/mysql/log:/var/log/mysql:将日志文件夹挂载到主机 -v /mydata/mysql/data:/var/lib/mysql/:将配置文件夹挂载到主机 -e MYSQL_ROOT_PASSWORD=root:初始化 root 用户的密码
进入docker容器
docker exec -it f1178d5b0bd8 /bin/bash
修改mysql配置文件
vi /mydata/mysql/conf/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect=‘SET collation_connection = utf8_unicode_ci’
init_connect=‘SET NAMES utf8’
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
使配置文件生效
docker ps
docker restart mysql
docker安装redis
挂载可能会把文件当成目录,所以预先创建好文件
mkdir -p /mydata/redis/conf
touch /mydata/redis/conf/redis.conf
docker run -p 6379:6379 --name redis -v /mydata/redis/data:/data \
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf
连接容器内redis客户端
docker exec -it redis redis-cli
当前数据保存在内存中,需要配置持久化规则
vim /mydata/redis/conf/redis.conf
appendonly yes
docker restart redis
maven

git使用ssh连接

git管理仓库

开发生产者模型:开发在dev分支,开发完成合并到master分支
idea新建项目

创建微服务项目

从模块中复制一个pom文件放在根目录下,进行修改
可以取消这两个勾选,它会检查分析代码,包括TODO


数据库设计
整合人人开源-后台管理系统
下载
https://gitee.com/renrenio 下载renren-fast和renren-fast-vue
快速搭建后台管理系统:renren-fast整合到gulimall项目中;vscode打开renren-fast-vue配置开发环境
npm install npm run dev
配置前端运行环境
node.js

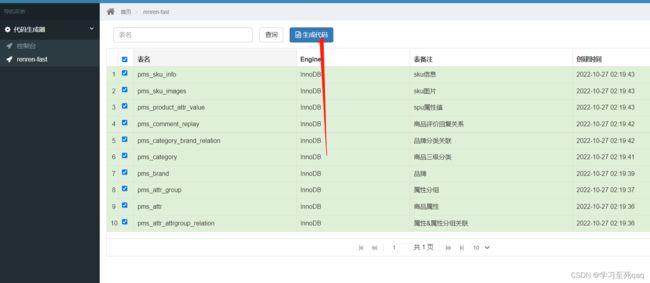
代码生成器(逆向工程)
下载:https://gitee.com/renrenio/renren-generator.git
整合进gulimall项目,修改配置文件,先生成product模块基本文件

运行服务,访问localhost,点击生成下载.zip压缩文件,解压放进gulimall-product
缺失很多依赖,创建common模块,引入依赖和renren-fast中的部分依赖文件
shift+f6修改模块名称
修改逆向工程,不使用shiro依赖,重新生成代码

分布式组件
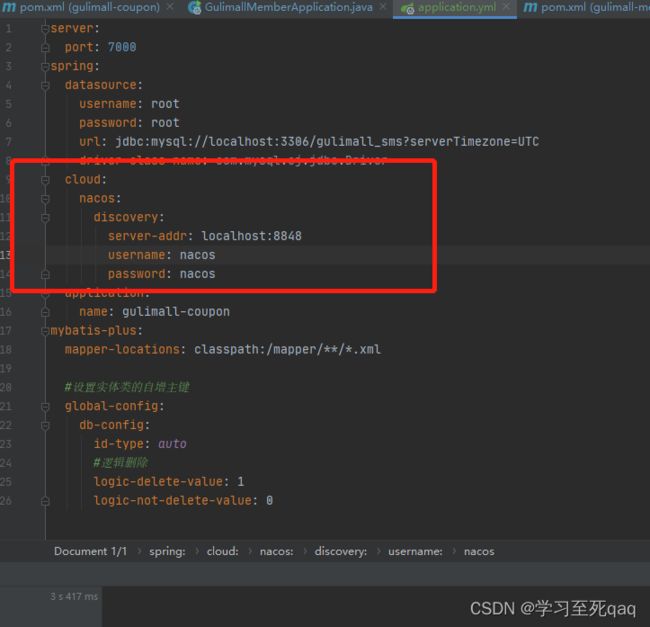
服务注册
1、引入依赖

2、开启服务注册

3、编写配置文件
feign
1、导入依赖

2、开启支持feign远程调用
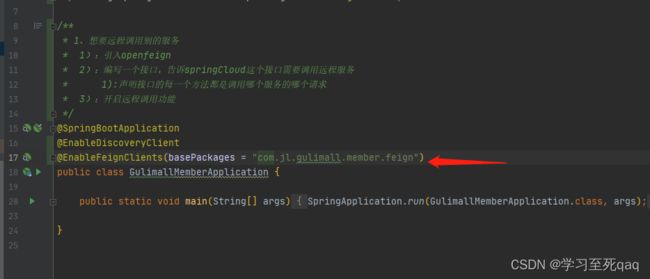
3、编写声明式接口

配置中心
如何使用nacos作为配置中心统一管理配置
1、引入依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
2、创建一个bootstrap.properties文件
spring.application.name=guli-coupon
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
3、需要给配置中心默认添加一个叫 数据集(Data Id)guli-coupon.properties。默认规则:应用名.properties
4、给 应用名.properties添加任何配置
5、动态获取配置
@RefreshScope:动态获取并刷新配置
@Value(“${配置项的名称}”):获取配置
配置中心优先级>本地配置优先级
gateway
前端内容
ES6
ECMAScript 6.0(以下简称 ES6,ECMAScript 是一种由 Ecma 国际(前身为欧洲计算机制造商 协会,英文名称是 European Computer Manufacturers Association)通过 ECMA-262标准化的脚本 程序设计语言)是 JavaScript 语言的下一代标准
模块化
vue
1、文件夹内终端敲入命令:npm init -y
2、npm install vue
3、引入vue,script中src=“./node_modules/vue/dist/vue.js”


vue模块化开发

目录结构

项目开发
商品服务
1、数据库导入数据
2、运行renren-vue和后台
配置网关
请求转发Service Unavailable问题
https://blog.csdn.net/kitahiragawa/article/details/124229580
原因:这是由于版本不兼容引发的问题,我当前使用的springcloud alibaba版本为2021.0.1.0,而springcloud alibaba在2020版之后不支持ribbon,而springcloud gateway使用ribbon,就导致了gateway无法路由到目标服务
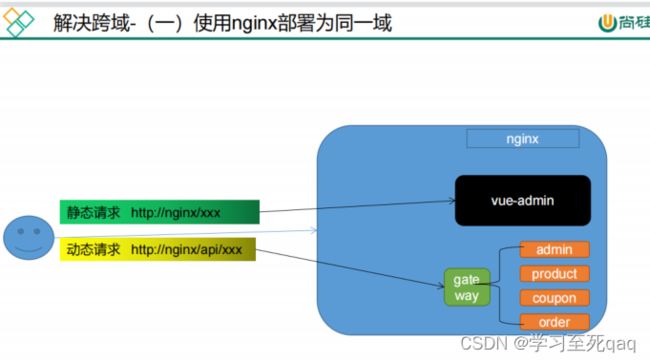
跨域问题
不是简单请求就需要发送一个Options方式的预检请求
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Access_control_CORS

解决跨域

product模块逻辑删除
1)、配置全局的逻辑删除规则(省略)
2)、配置逻辑删除的组件Bean(省略)
3)、给Bean加上逻辑删除注解@TableLogic
商品服务-三级分类
商品服务-品牌管理
oss上传
根据github上springCloudAlibaba演示demo引入
https://github.com/alibaba/spring-cloud-alibaba

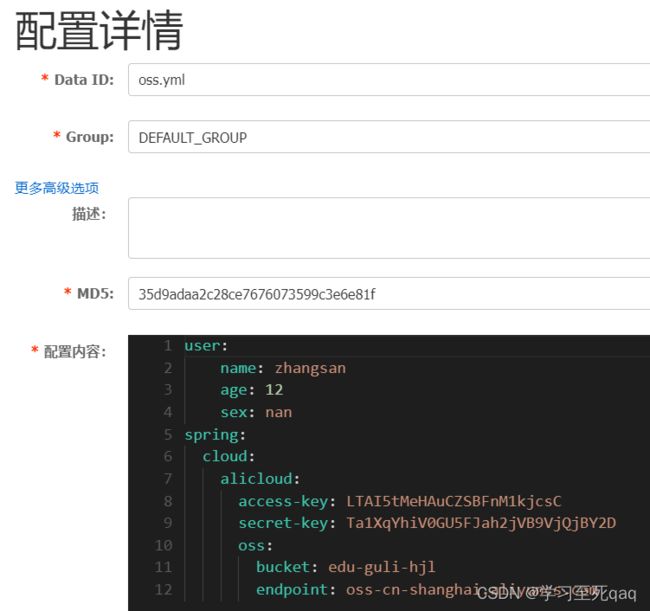
nacos config配置:
yml文件配置
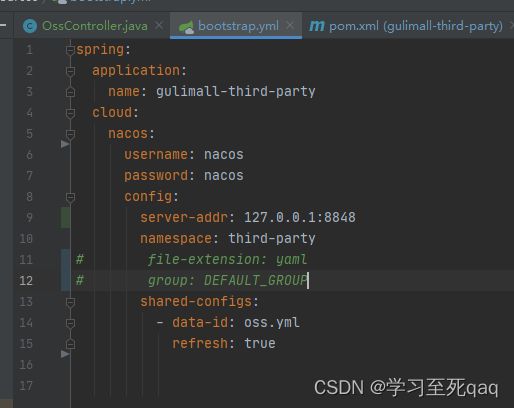
注意点:需要加如下依赖
org.springframework.cloud
spring-cloud-starter-bootstrap

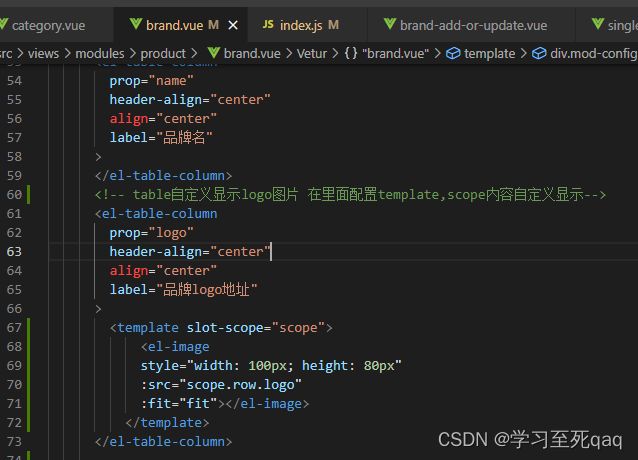
table显示图片
table->自定义模板->在里面配置template,scope内容自定义显示
异常排查:

1、main.js是否引入elementui
2、main.js引入的是src下的elementui
3、elemnetui/index.js中没有引入image
4、去element官网快速上手配置引入image
jsr303数据校验
JSR303
1)、给Bean添加校验注解:javax.validation.constraints,并定义自己的message提示
2)、开启校验功能@Valid
效果:校验错误以后会有默认的响应;
3)、给校验的bean后紧跟一个BindingResult,就可以获取到校验的结果
4)、分组校验(多场景的复杂校验)
1)、 @NotBlank(message = “品牌名必须提交”,groups = {AddGroup.class,UpdateGroup.class})
给校验注解标注什么情况需要进行校验
2)、@Validated({AddGroup.class})
3)、默认没有指定分组的校验注解@NotBlank,在分组校验情况@Validated({AddGroup.class})下不生效,只会在@Validated生效;
5)、自定义校验
1)、编写一个自定义的校验注解
2)、编写一个自定义的校验器 ConstraintValidator
3)、关联自定义的校验器和自定义的校验注解
统一异常处理
统一的异常处理
@ControllerAdvice
1)、编写异常处理类,使用@ControllerAdvice。
2)、使用@ExceptionHandler标注方法可以处理的异常。
spu、sku
SPU:Standard Product Unit(标准化产品单元)
SKU:Stock Keeping Unit(库存量单位)
iphoneX 是 SPU、MI 8 是 SPU
iphoneX 64G 黑曜石 是 SKU
MI8 8+64G+黑色 是 SKU
Object划分


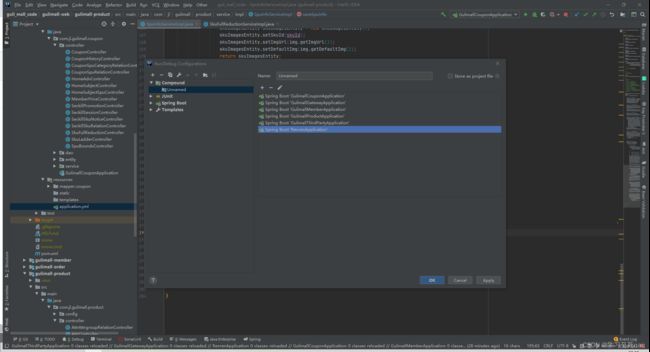
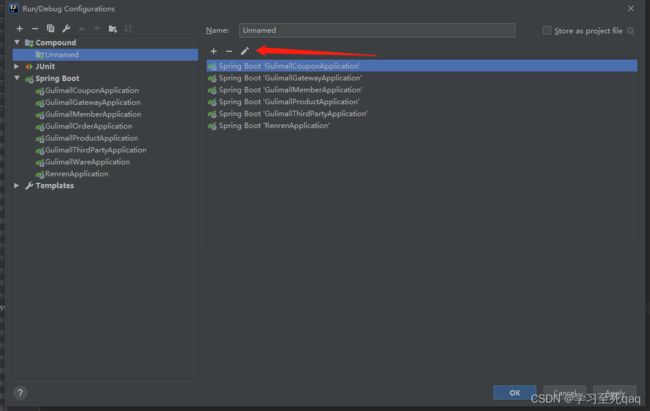
项目运行内存配置
1、新建、配置compound
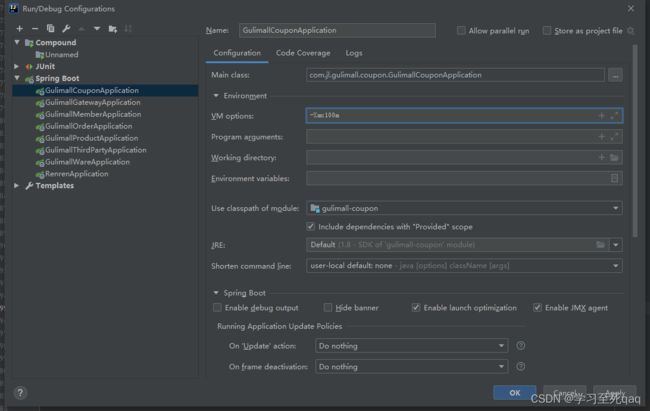
2、配置最大占用内存
@Transactional分析
断点执行看不到之前代码的入库数据:
1、因为事务没有提交之前,数据是读不出来的;
2、mysql默认的隔离级别是可重复读,就是最起码读到已经提交了的数据,为了测试方便,将当前会话的隔离级别等级设置为读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
3、然后就可以很方便得查看数据库变化
让@Transactional事务遇到异常不回滚
1、可以使用try catch捕获异常
2、

库存&采购流程
采购需求->合并整单->采购单->库存

基础篇总结
#
分布式高级篇
ElasticSearch
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
官方中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html 社区中文: https://es.xiaoleilu.com/index.html http://doc.codingdict.com/elasticsearch/0/

1、下载镜像文件
docker pull elasticsearch:7.4.2 存储和检索数据
docker pull kibana:7.4.2 可视化检索数据
2、创建实例
1、ElasticSearch
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo “http.host: 0.0.0.0” >> /mydata/elasticsearch/config/elasticsearch.yml
chmod -R 777 /mydata/elasticsearch/ 保证权限
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e “discovery.type=single-node”
-e ES_JAVA_OPTS=“-Xms64m -Xmx512m” \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
http.host: 0.0.0.0 : es可以被远程任何机器访问
-e:配置参数
-p:暴露端口-9200是我们给es的restAPI发请求的端口-9300是es在分布式集群状态下的节点通信端口
discovery.type:单节点模式
ES_JAVA_OPTS:不指定的话es一启动会将内存全部占用,虚拟机就卡死了
-d:后台启动
以后再外面装好插件重启即可;
特别注意: -e ES_JAVA_OPTS=“-Xms64m -Xmx256m” \ 测试环境下,设置 ES 的初始内存和最大内存,否则导 致过大启动不了 ES
查看日志:docker logs elasticsearch
访问:http://192.168.233.141:9200/
2、Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.233.141:9200 -p 5601:5601 \ -d kibana:7.4.2
访问:http://192.168.233.141:5601/app/kibana#/dev_tools/console?_g=()
初步检索


_seq_no可以作乐观锁








样本数据 acounts.json
https://github.com/elastic/elasticsearch/blob/7.5/docs/src/test/resources/accounts.json
进阶检索
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/getting-started-search.html
启动docker容器
docker ps -a
docker start containerId
开机自启
docker update containerId --restart=always
mapping
type是keyword类型:不会进行全文检索,只会精确匹配
type是text类型的:全文检索,保存数据的时候进行分词,检索的时候按照分词进行匹配
ES5.0及以后的版本取消了string类型,将原先的string类型拆分为text和keyword两种类型。它们的区别在于text会对字段进行分词处理而keyword则不会进行分词。
也就是说如果字段是text类型,存入的数据会先进行分词,然后将分完词的词组存入索引,而keyword则不会进行分词,直接存储。
text类型的数据被用来索引长文本,例如电子邮件主体部分或者一款产品的介绍,这些文本会被分析,在建立索引文档之前会被分词器进行分词,转化为词组。经过分词机制之后es允许检索到该文本切分而成的词语,但是text类型的数据不能用来过滤、排序和聚合等操作。
keyword类型的数据可以满足电子邮箱地址、主机名、状态码、邮政编码和标签等数据的要求,不进行分词,常常被用来过滤、排序和聚合
安装ik分词器
1、下载https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2
2、解压到plugin文件夹,装在ik目录中
3、进入es容器:docker exec -it 容器id /bin/bash,elasticsearch-plugin list
4、重启容器
docker restart elasticsearch


docker安装nginx

es自定义词库


springboot整合es
为什么不用js直接操作es
1、安全性
2、js对es支持度低
分析:
1、方便检索
{
skuId:1
spuId:11
skuTitle:华为xx
price:998
saleCount:99
attrs:[{尺寸:4寸},{CPU:高通945},{分辨率:全高清}]
}
冗余:100w商品 每个商品20个属性,假设合起来2kb数据 100w2kb=2000MB=2G 商城系统多了2G
2、
sku索引{
skuId:1
spuId:11
xxxxxx
}
attr索引{
spuId:11
attrs:[{尺寸:4寸},{CPU:高通945},{分辨率:全高清}]
}
问题: 搜索’小米’ 粮食、手机、电器
1w个 4k个spu
分步:4k个spu对应的所有可能属性
esClient请求搜索4k个spuId,每个都是long型数据 4k8=32000byte=32kb
1w人在商城检索商品:1w*32kb=320MB 一次光数据传输320mb,高并发情况下会网络阻塞
总结:空间和时间不能二者兼得,所以我们这里选择第一种设计模型
PUT product
{
“mappings”: {
“properties”: {
“skuId”: {
“type”: “long”
},
“spuId”: {
“type”: “keyword”
},
“skuTitle”: {
“type”: “text”,
“analyzer”: “ik_smart”
},
“skuPrice”: {
“type”: “keyword”
},
“skuImg”: {
“type”: “keyword”,
“index”: false,
“doc_values”: false
},
“saleCount”: {
“type”: “long”
},
“hasStock”: {
“type”: “boolean”
},
“hotScore”: {
“type”: “long”
},
“brandId”: {
“type”: “long”
},
“catalogId”: {
“type”: “long”
},
“brandName”: {
“type”: “keyword”,
“index”: false,
“doc_values”: false
},
“brandImg”: {
“type”: “keyword”,
“index”: false,
“doc_values”: false
},
“catalogName”: {
“type”: “keyword”,
“index”: false,
“doc_values”: false
},
“attrs”: {
“type”: “nested”,
“properties”: {
“attrId”: {
“type”: “long”
},
“attrName”: {
“type”: “keyword”,
“index”: false,
“doc_values”: false
},
“attrValue”: {
“type”: “keyword”
}
}
}
}
}
}
index:false 表示该属性不可用来被检索
doc_values: true 表示可以用来作聚合、排序、脚本等操作,进行空间节省
“type”: “nested” 表示属性子对象中的某些值进行检索
nginx+windows搭建域名访问环境

域名解析:我们在浏览器上敲gulimall.com,windows如何知道哪个域名对应哪个ip地址?
1、查看系统内部系统映射规则(网卡带我们转过去)
2、如果系统没告诉gulimall.com在哪个地址,那就去网络上的dns(比如114.114.114.114,8.8.8.8),解析出域名(dns中保存了每个域名对应每个ip地址,在公网保存),查看ip映射规则
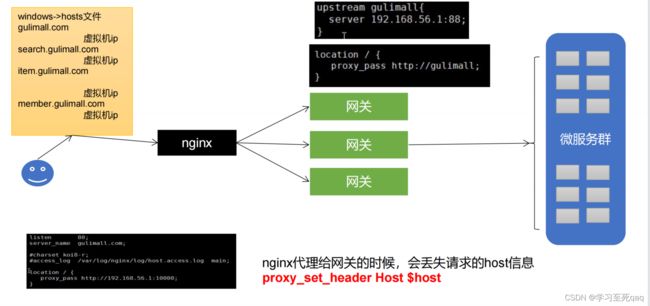
1、配置hosts
192.168.233.141 gulimall.com,http://gulimall.com:9200/测试配置是否成功
2、配置nginx配置文件,请求发到网关
3、在网关配置转发策略
4、域名请求依然是404
因为nginx代理给网关的时候,会丢失请求的host信息
配置proxy_set_header Host $host




压力测试

java内存模型
压测数据
| 压测内容 | 路径 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|---|
| Nginx | http://192.168.233.141:80/ | 50 | 2335 | 11 | 944 |
| Gateway | http://localhost:88/ | 50 | 10367 | 8 | 31 |
| 简单服务 | localhost:10000/hello | 50 | 11341 | 8 | 17 |
| 首页一级菜单渲染 | localhost:10000 | 50 | 270(db,thymeleaf) | 267 | 365 |
| 首页渲染(thymeleaf开缓存) | localhost:10000 | 50 | 290 | 251 | 365 |
| 首页渲染(thymeleaf开缓存、 优化数据库、降低日志级别日 志(关日志)) | localhost:10000 | 50 | 700 | 105 | 183 |
| 三级分类数据获取 | localhost:10000/index/catalog.json | 50 | 2(db)/8(加索引) | ||
| 三级分类(优化业 务,减少与数据库的交互) | localhost:10000/index/catalog.json | 50 | 111 | 571 | 896 |
| 三 级 分 类 ( 使 用 redis 作为缓存) | localhost:10000/index/catalog.json | 50 | 411 | 153 | 217 |
| 首页全量数据获取 | localhost:10000 | 50 | 7(静态资源) | ||
| Nginx+Gateway | 50 | ||||
| Gateway+简单服务 | localhost:88/hello | 50 | 3126 | 30 | 125 |
| 全链路 | gulimall.com/hello | 50 | 800 | 88 | 310 |
监控内存使用率等数据:docker stats
测nginx
简单服务

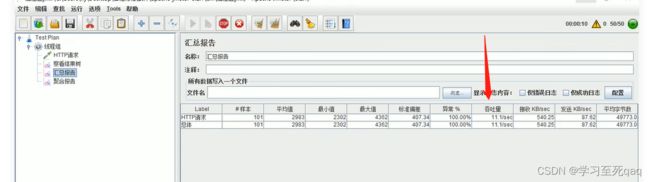
首页全量数据获取


开thymeleaf缓存、优化数据库、关日志、nginx动静分离
效果还是不明显,吞吐量从7-11

 开thymeleaf缓存、优化数据库、关日志、nginx动静分离、调节内存
开thymeleaf缓存、优化数据库、关日志、nginx动静分离、调节内存
-Xms 堆内存的初始大小,默认为物理内存的1/64
-Xmx 堆内存的最大大小,默认为物理内存的1/4
-Xmn 堆内新生代的大小。通过这个值也可以得到老生代的大小:-Xmx减去-Xmn
-Xss 设置每个线程可使用的内存大小,即栈的大小
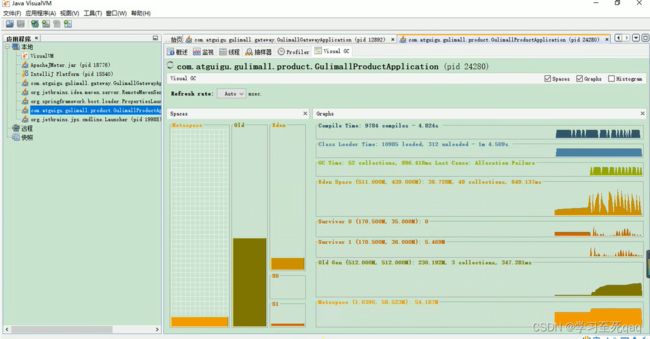

测试服务崩溃


三 级 分 类 ( 使 用 redis 作为缓存)

问题:压测报错


解决:
TODO:压测产生堆歪内存溢出:OutOfDirectMemoryError
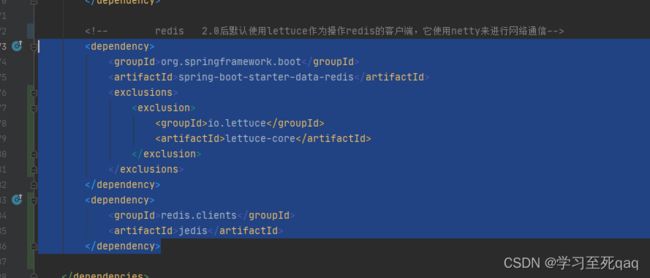
1):springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty来进行网络通信
2):lettuce的bug导致netty堆外内存溢出 -Xmx300m netty如果没有指定堆外内存,默认使用-Xmx300m
可以通过-Dio.netty.maxDirectMemory进行设置
解决方案:不能使用-Dio.netty.maxDirectMemory只去调大堆外内存(调大内存只能延缓报错的时间)
1、升级lettuce客户端
2、切换使用jedis客户端
总结:
1、中间件越多,性能损失越大,大多都损失在网络交互了;
2、业务:
Db(MySQL 优化) 模板的渲染速度(缓存) 静态资源
优化数据库
新建索引

动静分离
1、在nginx的html文件夹中新建static文件夹
2、将guli-product中的index下静态资源复制到static文件夹下
3、将href和