TensorFlow2.1 模型训练使用
文章目录
- 1、环境安装搭建
- 2、神经网络
-
- 2.1、解决线性问题
- 2.2、FAshion MNIST数据集使用
- 3、卷积神经网络
-
- 3.1、卷积神经网络使用
- 3.2、ImageDataGenerator使用
- 3.3、猫狗识别案例
- 3.4、参数优化
1、环境安装搭建
链接: Windows 安装Tensorflow2.1、Pycharm开发环境
2、神经网络
1、传统方式解决问题

2、机器学习解决方式


2.1、解决线性问题
下面通过两组数据推导出公式:
-1.0, 0.0, 1.0, 2.0, 3.0, 4.0
-3.0, -1.0, 1.0, 3.0, 5.0, 7.0
很明显是一个线性问题,y=2x-1,下面我们通过tensorflow来解决这个问题,输入当x=10的时候求y的值?
import tensorflow as tf
from tensorflow import keras
import numpy as np
def tensor_test1():
# layers表示的是一层神经元,units表示这一层里面只有一个。input_shape输入值
model = keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
# 指定优化和损失函数
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
# epochs 表示训练次数
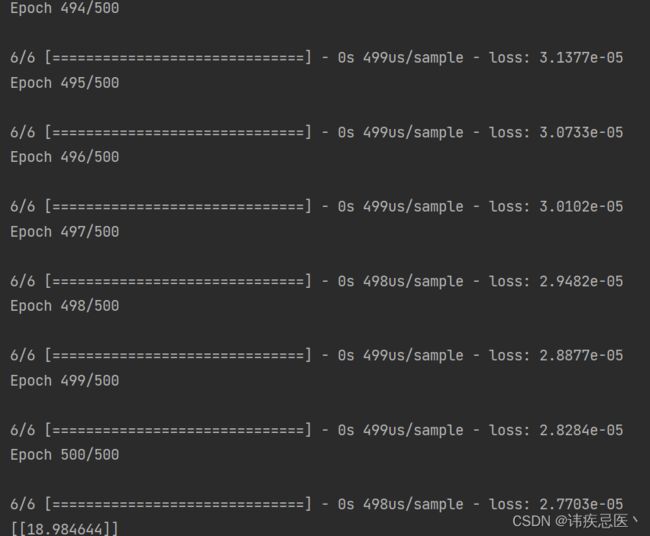
model.fit(xs, ys, epochs=500)
# y = 2x-1
# 通过模型去检测x=10的时候,y等于多少
print(model.predict([10.0]))
if __name__ == '__main__':
tensor_test1()
通过结果可以看出,是一个很接近的值
2.2、FAshion MNIST数据集使用

700000张图片
10个类别
28*28
训练神经元网络
通过tensorflow进行模型构建,通过构建出来的模型对图片进行识别
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
# 使用fashion数据集
# 自动终止
# 深度学习是不是训练的次数越多越好呢,不是次数太多会出现一些过拟合问题,就是做的题目都认识,但是新题目不会
# 所以我们需要通过callback来对他进行终止
class myCallbcak(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if (logs.get('loss') < 0.4):
print("\nloss is low so cancelling training!")
self.model.stop_training = True
def tensor_Fashion():
callbacks = myCallbcak()
fashion_mnist = keras.datasets.fashion_mnist
# 训练数据集,每张图片对应的标签 测试用的图片 测试用的标签
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# print(train_images.shape)
# plt.imshow(train_images[0])
# 构造模型
# 构造一个三层结构,第一层用来接收输入,中间层有512个神经元,这个是任意的,最后层,我们要分的类别有10
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.summary()
# 归一化,更准确
train_images_scaled = train_images / 255.0
# 指定优化
model.compile(optimizer='adam', loss=tf.losses.sparse_categorical_crossentropy
, metrics=['accuracy'])
model.fit(train_images_scaled, train_labels, epochs=100, callbacks=[callbacks])
test_images_scaled = test_images / 255.0
model.evaluate(test_images_scaled, test_labels)
# 判断单张图片的属于哪个类别
print(model.predict([[test_images[0] / 255]]))
# 打印出标签
print(np.argmax(model.predict([[test_images[0] / 255]])))
print(test_labels[0])
3、卷积神经网络
3.1、卷积神经网络使用
通过卷积神经网络对FAshion MNIST数据集进行训练,得出的准确率比神经网络的更准确,当时也更耗时
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
def convolution_nerve():
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 构造模型
model = keras.Sequential([
keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.MaxPooling2D(2, 2),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.MaxPooling2D(2, 2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.summary()
# 归一化
train_images_scaled = train_images / 255.0
# 指定优化
model.compile(optimizer='adam', loss=tf.losses.sparse_categorical_crossentropy
, metrics=['accuracy'])
model.fit(train_images_scaled.reshape(-1, 28, 28, 1), train_labels, epochs=5)
if __name__ == '__main__':
convolution_nerve()
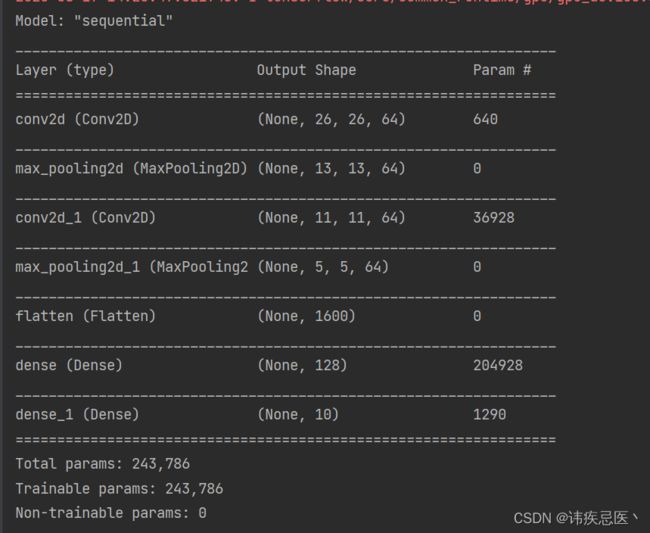
模型结构
1层卷积层
输入是2828,过滤器是33,最后会去掉两个像素,所以是2626,64是过滤器,经过第一次卷积就变成64张图片了,(33+1)64=640
2池化层
尺寸减少原来的1/4,长宽各自减去一半
2层卷积层
(33*64+1)*64=36928
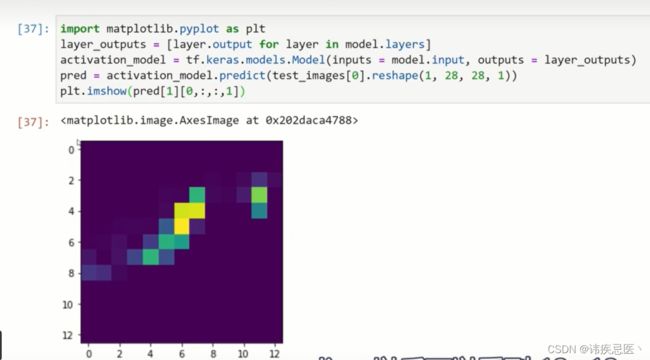
第一层卷积层

max pooling
3.2、ImageDataGenerator使用
1、 真实数据做处理
2、图片尺寸大小不一,需要裁成一样大小
3、数据量比较大,不能一下载装入内容
4、经常需要修改参数,列入尺寸
使用ImageDataGenerator对图片做处理
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 创建两个数据生成器,指定scaling否为0-1
train_datagen = ImageDataGenerator(rescale=1 / 255)
validation_datagen = ImageDataGenerator(rescale=1 / 255)
# 指向训练数据文件夹
train_genrator = train_datagen.flow_from_directory(
'/', # 训练数据所在文件夹
target_size=(300, 300), # 指定输出尺寸
batch_size=32, # 每次提取多少
class_mode='binary' # 指定二分类
)
validation_genrator = validation_datagen.flow_from_directory(
'/', # 训练数据所在文件夹
target_size=(300, 300), # 指定输出尺寸
batch_size=32, # 每次提取多少
class_mode='binary' # 指定二分类
)
3.3、猫狗识别案例
图片资源下载:https://download.csdn.net/download/weixin_45715405/88226536
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
import os
import tensorflow as tf
from tensorflow import keras
import numpy as np
def dogs_cats():
base_dir = 'E:\\BaiduNetdiskDownload\\06.TensorFlow框架课件资料\\Tensorflow课件资料\\猫狗识别项目实战\\猫狗识别\\猫狗识别\data\\cats_and_dogs'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 训练集
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证集
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(64, 64, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid') # 如果是多分类用softmax,2分类用sigmoid就可以了
])
# 设置损失函数,优化函数
model.compile(loss='binary_crossentropy', optimizer=RMSprop(0.001)
, metrics=['acc'])
# 数据预处理
# 都进来的数据会被自动转换成tensor(float32)格式,分别准备训练和验证
# 图像数据归一化(0-1)区间
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 文件夹路径
target_size=(64, 64), # 指定resize的大小
batch_size=20,
# 如果one-hot就是categorical,二分类用binary就可以
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=20,
class_mode='binary'
)
# 训练网络模型
# 直接fit也可以,但是通常不能把所有数据全部放入内存,fit_generator相当于一个生成器,动态产生所需的batch数据
# steps_per_epoch相当给定一个停止条件,因为生成器会不断产生batch数据,说白了就是它不知道一个epoch里需要执行多少个step
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=5,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
3.4、参数优化
安装
pip3 install keras-tuner
优化之后的参数版本
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
import os
from kerastuner.tuners import Hyperband
from kerastuner.engine.hyperparameters import HyperParameters
# 创建两个数据生成器,指定scaling否为0-1
# train_datagen = ImageDataGenerator(rescale=1 / 255)
# validation_datagen = ImageDataGenerator(rescale=1 / 255)
#
# # 指向训练数据文件夹
# train_genrator = train_datagen.flow_from_directory(
# 'E:\\BaiduNetdiskDownload\\06.TensorFlow框架课件资料\\Tensorflow课件资料\\猫狗识别项目实战\\猫狗识别\\猫狗识别\data\\cats_and_dogs\\train', # 训练数据所在文件夹
# target_size=(300, 300), # 指定输出尺寸
# batch_size=32, # 每次提取多少
# class_mode='binary' # 指定二分类
# )
#
# validation_genrator = validation_datagen.flow_from_directory(
# 'E:\\BaiduNetdiskDownload\\06.TensorFlow框架课件资料\\Tensorflow课件资料\\猫狗识别项目实战\\猫狗识别\\猫狗识别\data\\cats_and_dogs\\validation', # 训练数据所在文件夹
# target_size=(300, 300), # 指定输出尺寸
# batch_size=32, # 每次提取多少
# class_mode='binary' # 指定二分类
# )
hp = HyperParameters()
def dogs_cats(hp):
model = tf.keras.models.Sequential()
# values 指定范围
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_layer0', values=[16, 64], default=16),
(3, 3), activation='relu',
input_shape=(64, 64, 3)))
model.add(tf.keras.layers.MaxPooling2D(2, 2))
for i in range(hp.Int('num_conv_layers', 1, 3)):
model.add(tf.keras.layers.Conv2D(hp.Choice(f'num_filters_layer{i}', values=[16, 64], default=16), (3, 3),
activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2, 2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(hp.Int('hidde_units', 128, 512, step=32), activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid')) # 如果是多分类用softmax,2分类用sigmoid就可以了
# 设置损失函数,优化函数
model.compile(loss='binary_crossentropy', optimizer=RMSprop(0.001)
, metrics=['acc'])
return model
base_dir = 'E:\\BaiduNetdiskDownload\\06.TensorFlow框架课件资料\\Tensorflow课件资料\\猫狗识别项目实战\\猫狗识别\\猫狗识别\data\\cats_and_dogs'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 训练集
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证集
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 数据预处理
# 都进来的数据会被自动转换成tensor(float32)格式,分别准备训练和验证
# 图像数据归一化(0-1)区间
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 文件夹路径
target_size=(64, 64), # 指定resize的大小
batch_size=20,
# 如果one-hot就是categorical,二分类用binary就可以
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(64, 64),
batch_size=20,
class_mode='binary'
)
# 训练网络模型
# 直接fit也可以,但是通常不能把所有数据全部放入内存,fit_generator相当于一个生成器,动态产生所需的batch数据
# steps_per_epoch相当给定一个停止条件,因为生成器会不断产生batch数据,说白了就是它不知道一个epoch里需要执行多少个step
# history = model.fit_generator(
# train_generator,
# steps_per_epoch=100,
# epochs=5,
# validation_data=validation_generator,
# validation_steps=50,
# verbose=2)
tuner = Hyperband(
dogs_cats,
objective='val_acc',
max_epochs=15,
directory='dog_cats_params',
hyperparameters=hp,
project_name='my_dog_cat_project'
)
tuner.search(train_generator, epochs=10, validation_data=validation_generator)
# 查看参数情况
best_hps = tuner.get_best_hyperparameters(1)[0]
print(best_hps.values)
# 通过参数将模型构建出来
model = tuner.hypermodel.build(best_hps)
model.summary()