【教学类-38】20230724京剧脸谱涂色(Python 彩图彩照转素描线描稿)
一、作品预览
京剧脸谱(涂色)学具展示(64份)
二、背景需求:
1、大班主题《我是中国人》里面有一个“京剧脸谱”的子主题。从网上下载的彩色脸谱(红黄绿蓝紫黑白),作为环境装饰。引导幼儿了解“脸谱色彩和人物性格”。
2、2023年9月开始幼儿园购买“梨园梦”的体验课程,6月培训课中,导师展示了幼儿照着范例在“京剧脸谱线描稿”上涂色的 一款学具,当时听到同事私语:“这一本也就几个人物能涂色,不够画啊!”
3、由于不确定是一班一套,还是每个孩子人手一套。所以我很想为孩子提供更多数量的“脸谱涂色”材料,作为个别化美工区学习材料。
4、网上有大量的彩色京剧脸谱彩色图案,也有少量的黑白线描脸谱,但是很难找到一套“有彩图又有线描稿的脸谱”,大部分线描稿京剧脸谱需要到淘宝购买。同时大部分脸谱没有备注,我也不知道它是哪位京剧人物,出自那一部京剧。
三、解决策略:
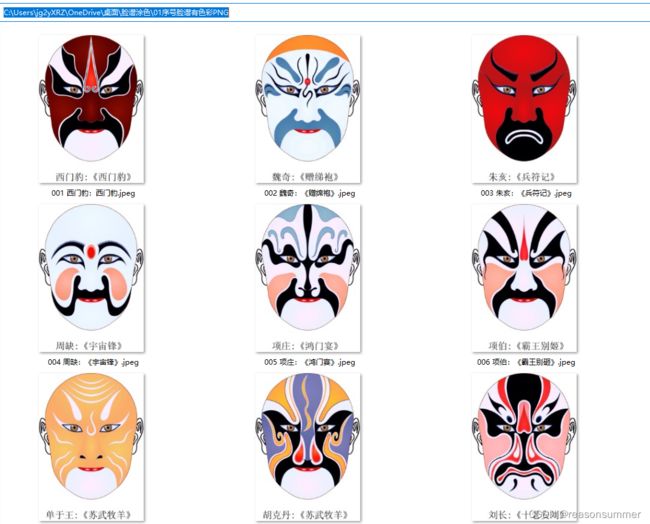
通过百度图片,搜索到“堆糖”上的一套京剧脸谱,不仅有人物名字和京剧名称,而且数量众多(实际下载468张),

脸谱人物名字和京剧名称的文字附在脸谱图片上
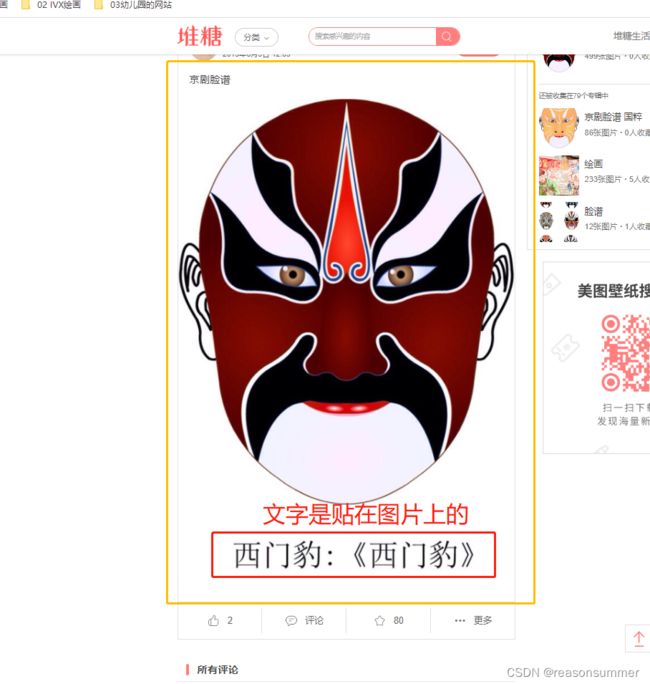
把467张脸谱下载(使用UIBOT,放大图片,读取“图片上的文字信息”,另存为“三位数序号+人物名字+京剧名称.jpeg
(文字识别度有误差,全部下载后,还需要对着脸谱图片上的文字手动修改图片的文件名字,有几个生僻字还需要网络搜搜读音)
(花了2天才全部下载完,调整号名字)

四、素材准备:
彩色脸谱

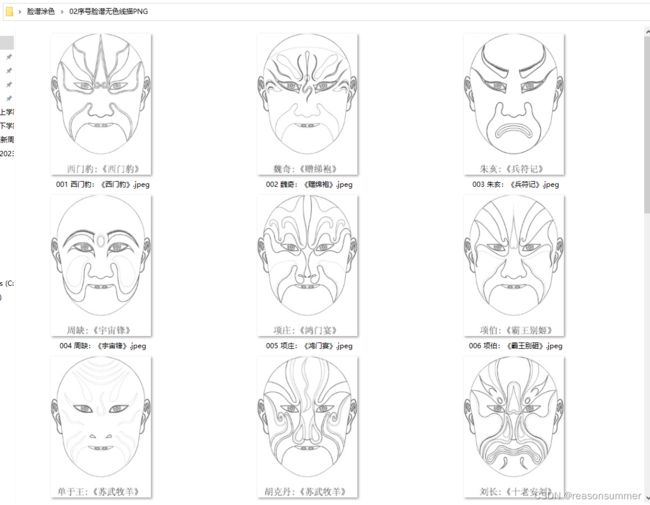
线描脸谱(空)

五:“彩图 转 线描图”的代码展示
# https://blog.csdn.net/weixin_44421798/article/details/113027414?ops_request_misc=&request_id=&biz_id=102&utm_term=Python%EF%BC%8C%E7%85%A7%E7%89%87%E4%B8%80%E9%83%A8%E5%88%86%E6%8F%8F%E8%BE%B9&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-2-113027414.142^v90^control_2,239^v3^insert_chatgpt&spm=1018.2226.3001.4187
'''将彩色脸谱转化为线描脸谱(黑白线条)'''
from PIL import Image
import os
import os
from PIL import Image
pathall=[]
p=r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\01序号脸谱有色彩PNG"
# 过滤:只保留png结尾的图片
imgs=os.listdir(p)
for img in imgs:
if img.endswith(".jpeg"):
pathall.append(p+'\\'+img)
# 所有图片的路径
print(pathall)
print(imgs)
for dz in range(len(pathall)):
# 图像组成:红绿蓝 (RGB)三原色组成 亮度(255,255,255)
image =pathall[dz]
img = Image.open(image)
new = Image.new("L", img.size, 255)
width, height = img.size
img = img.convert("L")
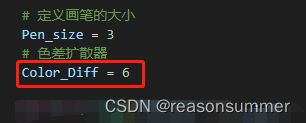
# 定义画笔的大小
Pen_size = 3
# 色差扩散器
Color_Diff = 6
for i in range(Pen_size + 1, width - Pen_size - 1):
for j in range(Pen_size + 1, height - Pen_size - 1):
# 原始的颜色
originalColor = 255
lcolor = sum([img.getpixel((i - r, j)) for r in range(Pen_size)]) // Pen_size
rcolor = sum([img.getpixel((i + r, j)) for r in range(Pen_size)]) // Pen_size
# 通道----颜料
if abs(lcolor - rcolor) > Color_Diff:
originalColor -= (255 - img.getpixel((i, j))) // 4
new.putpixel((i, j), originalColor)
ucolor = sum([img.getpixel((i, j - r)) for r in range(Pen_size)]) // Pen_size
dcolor = sum([img.getpixel((i, j + r)) for r in range(Pen_size)]) // Pen_size
# 通道----颜料
if abs(ucolor - dcolor) > Color_Diff:
originalColor -= (255 - img.getpixel((i, j))) // 4
new.putpixel((i, j), originalColor)
acolor = sum([img.getpixel((i - r, j - r)) for r in range(Pen_size)]) // Pen_size
bcolor = sum([img.getpixel((i + r, j + r)) for r in range(Pen_size)]) // Pen_size
# 通道----颜料
if abs(acolor - bcolor) > Color_Diff:
originalColor -= (255 - img.getpixel((i, j))) // 4
new.putpixel((i, j), originalColor)
qcolor = sum([img.getpixel((i + r, j - r)) for r in range(Pen_size)]) // Pen_size
wcolor = sum([img.getpixel((i - r, j + r)) for r in range(Pen_size)]) // Pen_size
# 通道----颜料
if abs(qcolor - wcolor) > Color_Diff:
originalColor -= (255 - img.getpixel((i, j))) // 4
new.putpixel((i, j), originalColor)
new.save(r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\02序号脸谱无色线描PNG\{}".format(imgs[dz]))
# i = os.system('mshta vbscript createobject("sapi.spvoice").speak("%s")(window.close)' % '您的图片转换好了')
# os.system(img_save)
终端展示
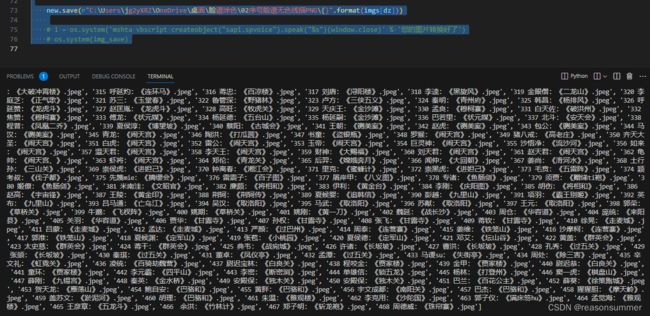
说明: 转换比较慢:
(1)一张彩色脸谱转线描脸谱的转换时间:37秒
(2) 预计:268张用时2小时45分16秒(2023年7月24日18:00:00-20:45:16)
(3)实际:2023年7月24日
18点00分—21点19分:下载149张
18点00分—23点09分:下载306张


(中间中断15分钟,实际运行速度不都是37秒一张)

太晚了,明天继续下载
(4)实际:2023年7月25日
8点07分—11点54分:编号306开始,下载167张(共473张)



说明:因为要检测图案中色块与色块的边缘线条(色差检测)并补充黑灰线条(线描),所以彩色图片转换线描稿非常费时,尽量不要用几百张图片转换。
六、代码选择的特别说明:
我需要涂色脸谱,前期测试“消除彩色”、“黑白灰”的两个代码(运行速度很快),效果不佳,因在第三次选择了“彩图转素描的代码”(色块边缘线检测线条,所以费时)
测试1:“图案去除彩色”
结果:图案保留了所有含黑色的线条、块面,不是黑色的轮廓线也消失了

测试2:“图案转(黑白)灰色”
结果:脸谱外形保留,出现没有彩色的黑白灰效果。但能够涂色的地方也都被黑色、灰色覆盖,不仅涂不了颜色,打印起来也浪费墨水。

测试3(最终效果):“图案转素描(线描)”
结果:脸谱保留所有的线条(描边3磅),而且深色块面颜色也被清除了,完全符合块面涂色的需求!

七、制作脸谱学具:
材料准备:

图片 文件夹1
图片 文件夹2 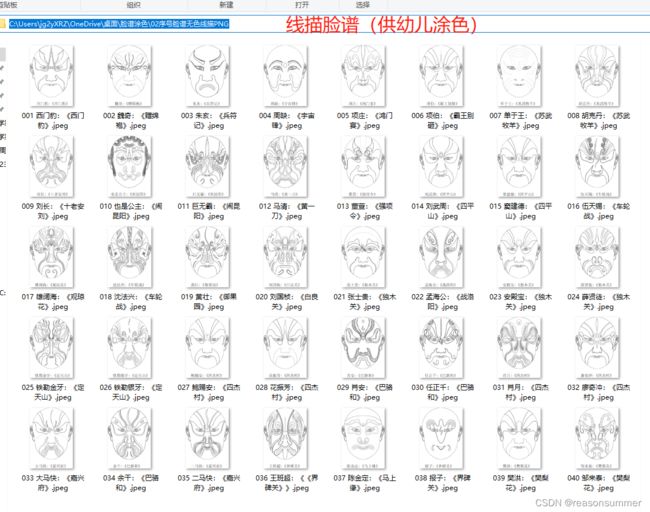
彩色脸谱的数量和线描脸谱的数量要一致(468张),制作学具时,需要按编号一一对应。
WORD模板

“彩色脸谱+线描脸谱”组合学具的代码展示:
# -*- coding: utf-8 -*-
'''
目的:
1、京剧脸谱彩色和黑白对应,制作涂色学具 一共468张,
2、作者:阿夏
时间:2023年7月24日)
'''
import os
# num=int(input('生成多少份(28人)\n'))
# Number=4
print('----------第1步:提取所有的京剧脸谱的路径------------')
# 有颜色的 彩色脸谱
path1=[]
p1=r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\01序号脸谱有色彩PNG"
# 过滤:只保留png结尾的图片
imgs1=os.listdir(p1)
for img1 in imgs1:
if img1.endswith(".jpeg"):
path1.append(p1+'\\'+img1)
# 所有图片的路径
print(path1)
print(imgs1)
# 没有有颜色的 黑白脸谱
path2=[]
# 有颜色的
p2=r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\02序号脸谱无色线描PNG"
# 过滤:只保留png结尾的图片
imgs2=os.listdir(p2)
for img2 in imgs2:
if img2.endswith(".jpeg"):
path2.append(p2+'\\'+img2)
# 所有图片的路径
print(path2)
print(imgs2)
# print('----------第2步:新建一个临时文件夹------------')
# # 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,len(path2)):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\脸谱涂色左右测试.docx')
# # 制作列表
# for z in range(2): # 5行组合循环2次 每页两张表
# # # 23个图形随机抽取12个
# # figure=random.sample(path,Number) # 12个图片随机写入4个
# # print(figure)
# # 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\20医生_1.png']
# # 提取名称
# title=[]
# for t in figure:
# tt=t[44:-6]
# title.append(tt)
# # 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\20医生_1.png']
# print(title)
table = doc.tables[0] # 只有一个表格
# 帖图片的单元格
# bg1=['00','01']
# for t1 in range(len(bg1)): # 02
# pp1=int(bg1[t1][0:1])
# qq1=int(bg1[t1][1:2])
# # print(p)
# k1=figure[t1]
# print(pp1,qq1,k1)#
# 写入彩色图片
run=doc.tables[0].cell(0,0).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(path1[nn]),width=Cm(14.04),height=Cm(19.2)) # 1.5的图片最多6个
table.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# 写入黑白图片
run=doc.tables[0].cell(0,1).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(path2[nn]),width=Cm(14.04),height=Cm(19.2)) # 1.5的图片最多6个
table.cell(0,1).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/(打印合集)脸谱涂色线描稿(共{}份).pdf".format(len(path2)))
file_merger.close()
# doc.Close()
# # # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word') #递归删除文件夹,即:删除非空文件夹
终端演示:(彩图片转换线描太慢了,先做64个图片)
"零时文件夹"里的图片,逐步生成word和PDF,最后合并PDF,并自动删除“零时文件夹”
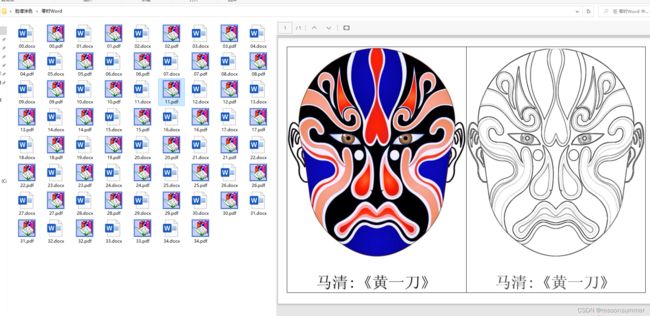
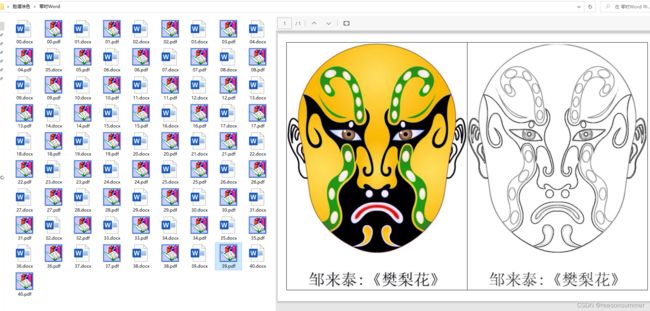
作品展示:

PDF学具(A4横版)
左右两个图案是一样的(有颜色和没有颜色,便于幼儿涂色,最好用水彩笔,但是实际情况只有“米罗可儿12色粗蜡笔",所以“468份脸谱合并的PDF”在打印时,教师最好有意识挑选一些涂色块面大、脸谱色彩能对应12色蜡笔(有这种颜色的蜡笔)的脸谱图案——打印当前页。凑满30份。)
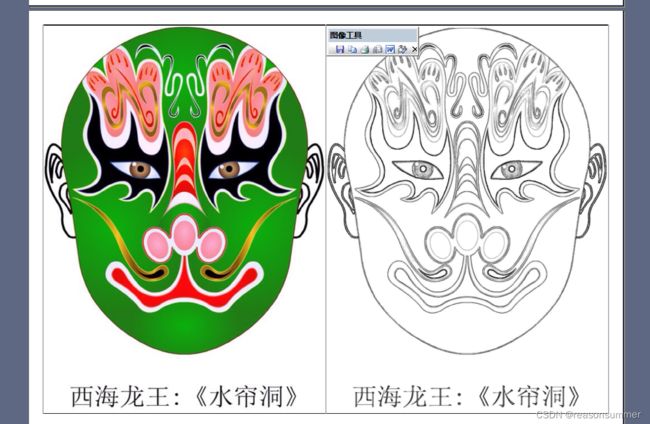
视频GIF:京剧脸谱(涂色)学具展示(64份)
花了两天时间,才把473张脸谱转成线描,然后生成PDF
从2023年7月25日12点14分,一直生成到13:00分,46分钟才跑完


感悟:
1、有了”照片/简笔画彩图 转 线描素描稿”的代码后,就可以将更多的彩色简笔画图片转为线稿,从而为幼儿提供涂色类学具。、
2、对称的线稿图片,还可以用切割代码切除右边部分,让幼儿尝试画对称图案。
3、线稿图片,切割N*N块,进行拼图。