arcgis空间分析工具集阐释
密度分析
密度分析是根据输入要素数据计算整个区域的数据聚集状况。
密度分析是通过离散点数据或者线数据进行内插的过程,根据插值原理不同,主要是分为核密度分析和普通的点\线密度分析。核密度分心中,落入搜索区的点具有不同的权重,靠近搜索中心的点或线会被赋予较大的权重,反之,权重较小,它的计算结果分布较平滑。在普通的点\线密度分析中,落在搜索区域内的点或线有相同的权重,先对其求和,再除以搜索区域的大小,从而得到每个点的密度值。
ArcGIS 的空间分析工具箱中提供了密度分析工具集中的三个工具:

1. Kernel Density(核密度分析)

输入值可以是点或者线。
工作原理引自帮助:
概念上,每个点/线上方均覆盖着一个平滑曲面。在点/线所在位置处表面值最高,随着与点的距离的增大表面值逐渐减小,在与点/线的距离等于搜索半径的位置处表面值为零。仅允许使用圆形邻域。曲面与下方的平面所围成的空间的体积等于此点的 Population 字段值,如果将此字段值指定为 NONE 则体积为 1。每个输出栅格像元的密度均为叠加在栅格像元中心的所有核表面的值之和。核函数以 Silverman 的著作(1986 年版,第 76 页,方程 4.5)中描述的二次核函数为基础。
对于点,如果 population 字段设置使用的是除 NONE 之外的值,则每项的值用于确定点被计数的次数。例如,值 3 会导致点被算作三个点。值可以为整型也可以为浮点型。
对于线,如果 population 字段使用的是除 NONE 之外的值,则线的长度将由线的实际长度乘以此线的 population 字段的值而得出。
2. Point Density / Line Density(点、线密度分析):

这两个工具的输出与核密度工具的输出的区别在于:
对于点密度和线密度,需要指定一个邻域,以便计算出各输出像元周围像元的密度。而核密度则可将各点的已知总体数量从点位置开始向四周分散。在核密度中,在各点周围生成表面所依据的二次公式可为表面中心(点位置)赋予最高值,并在搜索半径距离范围内减少到零。对于各输出像元,将计算各分散表面的累计交汇点总数。
1)点密度分析
每个栅格像元中心的周围都定义了一个邻域(邻域可以使用圆形、矩形、环形、楔形的形状来定义),将邻域内点的数量相加,然后除以邻域面积,即得到点要素的密度。如果 Population 字段设置使用的是 NONE 之外的值,则每项的值用于确定点被计数的次数。例如,值为 3 的项会导致点被算作三个点。值可以为整型也可以为浮点型。
2)线密度分析
使用搜索半径以各个栅格像元中心为圆心绘制一个圆。每条线上落入该圆内的部分的长度与 Population 字段值相乘。对这些数值进行求和,然后将所得的总和除以圆面积。
上图中显示的是栅格像元与其圆形邻域。线 L1 和 L2 表示各条线上落入圆内部分的长度。相应的 population 字段值分别为 V1 和 V2。因此:
Density = ((L1 * V1) + (L2 * V2)) / (area_of_circle)
如果 population 字段使用的是除 NONE 之外的值,则线的长度将等于线的实际长度乘以其 population 字段的值。
距离分析
距离分析相关的工具:

ArcGIS中,主要可以通过如下的几种方式进行距离分析:
1) 欧氏距离分析
2) 成本加权距离分析
3) 用于垂直移动限制和水平移动限制的成本加权距离分析
4) 获取最短路径
使用ArcGIS空间分析扩展实现距离分析,最主要的是欧氏距离分析和成本加权距离分析两类工具。
一、欧氏距离工具
欧氏距离工具测量每个像元距离最近源的直线距离(像元中心至像元中心的距离)。
欧氏距离(Euclidean Diatance)—— 求得每个像元至最近源的距离。
欧氏方向(Euclidean Direction)—— 求得每个像元至最近源的方向。
欧氏分配(Euclidean Allocation)—— 求得每个像元的最近的源。
TIPS:
1. 源(Source)
可以是感兴趣的地物的位置,数据方面,既可以是栅格数据,也可以是矢量数据。但注意:如果数据选用了栅格数据,数据中必须仅包含表示源的像元,其他像元需要是Nodata。如果选用矢量,在执行工具之时,内部会将其先转成栅格。
2. 欧氏距离的算法
简单理解为:工具会求得每个像元至每个源的距离,然后取得每个像元至每个源的最短距离以输出。其中,欧氏距离是像元中心与源像元的中心的直线距离。

如果像元与两个或更多源之间的距离相等,则计算都基于像元扫描过程中遇到的第一个源。无法控制该扫描过程。
帮助中有这样的描述:工具在实际执行的过程中,进行两次顺序扫描。这样,工具的执行速度与源像元的数目、分布以及最大距离无关。影响工具执行速度的唯一因素是栅格的大小。计算时间与“分析”窗口中的像元数成线性比例。暂且不知道进行了什么样的两次顺序扫描。
3. 欧氏距离输出栅格结果
投影平面上,像元与最近源之间的最短直线距离。如下图:

4. 欧氏方向输出栅格结果
像元与最近源之间的方位角方向(以度为单位)。使用 360 度圆,刻度 360 指北,90指东,从刻度 1 顺时针增加。值 0 供源像元使用。如下图:

5. 欧氏分配输出栅格结果
输出的每个像元都是距其最近源的值。如下图:

二、成本加权距离工具
成本加权距离工具可以看成是对欧氏直线距离的进一步修改,将经过某个像元的距离赋以成本因素。举个简单的例子,翻过一座山到达目的地是最短的直线距离,绕行这座山距离较长,但是更节省时间和体力,那就后者的成本加权距离最短了。
1)成本距离(Cost Distance):求得每个像元至最近源的成本距离。
2)成本回溯链接(Cost back link):求的一个方向栅格,可以从任意像元沿最小成本路径返回最近源。
3)成本分配(Cost Allocation):求得每个像元的最近的源。
4)成本路径(Cost Patch):求的任意像元到最近源的最小成本路径。
TIPS:
1. 成本栅格可以是整形或者浮点型,但是其值中不能含有负值或者0。成本栅格中的Nodata视为障碍。
2. 成本距离输出栅格数据
这里的简单示例中,下面一层黑白渲染的是成本栅格,颜色深的像元代表成本比较高,反之较低。结果如下:
2. 成本距离回溯链接
要注意的是,它并不会求的要返回哪一个源像元以及如何返回。而是记录从任意像元回溯到最近源的路径上,每个像元向下一个像元指向的方向,这个方向以0-8的代码形式记录。如下图:


3. 成本距离分配
这个类似于前面的欧氏距离分配,得到的是每个像元至最近源的成本距离。
三、路径距离工具
路径距离工具与成本距离相似,也可以确定从某个源到栅格上各像元位置的最小累积行程成本。但是,路径距离不仅可计算成本表面的累积成本,而且会考虑到行驶的实际曲面距离,和影响到移动总成本的水平和垂直因子。主要包含这几个工具
1)路径距离(Path Distance)
2)路径回溯链接(Path back link)
3)路径分配(Path Allocation)
这些工具生成的累积成本表面可用于扩散模型、流动和最低成本路径分析。
四、 获得最短路径
1. 成本距离路径
任意像元到最近源的最小成本路径,需要引用到上面工具中生成的成本距离和成本回溯链接栅格数据。如下图:

2. 廊道
另外要说的是廊道分析工具(Corridor)。此工具用于计算两个成本栅格的累积成本栅格结果,为了求得从一个源到另一个源且经过该像元位置的最小成本路径。
输出栅格不是单个最小成本路径,但会得到源之间累积成本的范围。
最后我们可以配合其他工具将小于某一阈值的结果提取出来,例如工具Extract by Attribute提取,或者通过Con进行条件赋值等等方法,获取结果。
如下如所示:
学校A、B成本距离分析结果:
学校C、D、E的成本距离分析结果:

有此两个距离成本结果,来分析得到A、B到C、D、E之间的廊道,也就是两组源之间的最小累积成本距离。

然后结果中我们可以按照一定的阈值来提取结果。例如累积成本在75以下的我才能接受:

常用工具
空间分析扩展模块中提供了很多方便栅格处理的工具,其中提取(Extraction)、综合(Generalization)等工具集中提供的功能是在分析处理数据中经常会用到的。
一、提取(Extraction)
顾名思义,这组工具就是方便我们将栅格数据按照某种条件来筛选提取。
工具集中提供了如下工具:

xtract by Attribute:按属性提取,按照SQL表达式筛选像元值。
Extract by Circle:按圆形提取,定义圆心和半径,按圆形提取栅格。
Extract by Mask:按掩膜提取,按指定的栅格数据或者矢量数据的形状的提取像元。
Extract by Point:按点提取,按给定坐标值列表进行提取。
Extract by Polygon:按多边形提取,按给定坐标序列作为节点的多边形进行提取。
Extract by Rectangle:按矩形提取,按给定的图层的Extent,或者定义了四至的矩形进行提取。
Extract Value to Point :按照点要素的位置提取对应的(一个/多个)栅格数据的像元值,其中,提取的Value可以使用像元中心值或者选择进行双线性插值提取。
Extract Multi Value to Point:同上,只是提取多个栅格的像元值。
Sample:采样,根据给定的栅格或者矢量数据的位置提取像元值,采样方法可选:最邻近分配法(Nearest)、双线性插值法(Bilinear)、三次卷积插值法(Cubic)。
以上工具用来提取栅格中的有效值、兴趣区域\点等很有用的。
二、综合(Generalization)
这组工具主要用来清理栅格数据,可以大致分为三个方面的功能:更改数据的分辨率、对区域进行概化、对区域边缘进行平滑。
这些工具的输入都要求为整型栅格。
1. 更改数据分辨率:
Aggregate: 聚合,生成降低分辨率的栅格。
其中,Cell Factor需要是一个大于1的整数,表示生成栅格的像元大小是原来的几倍。
生成新栅格的像元值可选:新的大像元所覆盖的输入像元的总和值、最小值、最大值、平均值、中间值。
效果如下,Cell factor设置为 6: ==>
==>
2. 对区域进行概化:
Expand: 扩展,按指定的像元数目扩展指定的栅格区域。
 ==>
==> 
Shrink: 收缩,按指定像元数目收缩所选区域,方法是用邻域中出现最频繁的像元值替换该区域的值。同Expand。
Nibble: 用最邻近点的值替换掩膜范围内的栅格像元的值。
Thin: 细化,通过减少表示要素宽度的像元数来对栅格化的线状对象进行细化。
Region Group: 区域合并,记录输出中每个像元所属的连接区域的标识。每个区域都将被分配给唯一编号。
工作原理:扫描的第一个区域接收值 1,第二个区域接收值 2,依此类推,直到所有区域都已赋值。扫描将按从左至右、从上至下的顺序进行。被赋予输出区域的值取决于系统在扫描过程中是在什么时候遇到它们的。
其中,添加链接选项为“真”时。这将在输出栅格的属性表中创建名为 LINK 的项,其保留输入栅格的每个像元的原始值。
如下图,原始数据具有相同值的区域有的并不连通,这时会新生成很多Region:
 ==>
==>
3. 对区域边缘进行平滑:
Boundary Clean: 边界清理,通过扩展和收缩来平滑区域间的边界。该工具会去更改X或Y方向上所有少于三个像元的位置。
Majority Filter: 众数滤波,根据相邻像元数据值的众数替换栅格中的像元。可以认为是“少数服从多数”,太突兀的像元被周围的大部队干掉了。其中“大部队”的参数可设置,相邻像元可以4邻域或者8邻域,众数可选,需要大部分(3/4、5/8)还是过半数即可。
TIPS: 这两个工具仅支持整形栅格输入。
看如下示例,清理后,还是有明显变化的,细碎像元已经被处理掉了。


表面分析

坡向(Aspect):获得栅格表面的坡向。求得每个像元到其相邻像元方向像元值的变化率最大的下坡方向。
等值线(Contour):根据栅格表面创建等值线(等值线图)的线要素类。
等值线序列(Contour List):根据栅格表面创建所选等值线值的要素类。
含障碍的等值线(Contour with Barriers):根据栅格表面创建等值线。如果包含障碍要素,则允许在障碍两侧独立生成等值线。
曲率(Curvature):计算栅格表面的曲率,包括剖面曲率和平面曲率。
填挖方(Cut Fill):计算两表面间体积的变化。通常用于执行填挖操作。
山体阴影(HillShade):通过考虑照明源的角度和阴影,根据表面栅格创建地貌晕渲。
视点分析(Observer Point):识别从各栅格表面位置进行观察时可见的观察点。
坡度(Slope):判断栅格表面的各像元中的坡度(梯度或 z 值的最大变化率)。
视域(Viewshed):确定对一组观察点要素可见的栅格表面位置。
下面分类来看一下这些工具:
一、 各种等值线工具
1) 等值线(Contour)
根据栅格表面数据创建等值线线要素类。可以指定起算线和间隔。

2) 等值线列表(Contour list)
根据栅格表面创建所指定等值线值的要素类。
3)含障碍的等值线(Contour with Barriers)
根据栅格表面创建等值线。如果包含障碍要素,则允许在障碍两侧独立生成等值线。
TIPS: 关于等值线的质量问题
少数情况下,所创建等值线的轮廓可能会呈方形或不均匀,看起来犹如沿着栅格像元的边界。出现这种情况可能是因为各栅格的值为整数且恰好落在等值线上。这并不是个问题,该等值线不过是原样呈现数据而已。
如果希望等值线更平滑,可行的方法包括对源数据进行平滑处理或调整起始等值线。
二、表面特征相关工具
1) 坡向(Aspect)
此工具求得每个像元到其相邻的各个像元方向的 z 值上变化率最大的下坡方向。
从概念上讲,坡向工具将根据要处理的像元或中心像元周围一个 3 x 3 的像元邻域的 z 值拟合出一个平面。该平面的朝向就是待处理像元的坡向。
输出栅格的值将是坡向的罗盘方向。坡向由 0 到 359.9 度之间的正度数表示,以北为基准方向按顺时针进行测量。会为输入栅格中的平坦(具有零坡度)像元分配 -1 坡向。
2) 坡度(Slope)
坡度是指各像元中 z 值的最大变化率。
从概念上讲,该工具会将一个平面与要处理的像元或中心像元周围一个 3 x 3 的像元邻域的 z 值进行拟合。该平面的坡度值通过最大平均值法来计算。
如果邻域内某个像元位置的 z 值为 NoData,则将中心像元的 z 值指定给该位置。如果直接邻域(3 x 3 窗口)中的中心像元为 NoData,则输出将为 NoData。

确定输出坡度数据的测量单位(度或百分比)。
DEGREE — 坡度倾角,单位:度,范围:0 ~ 90。
PERCENT_RISE — 高程增量百分比,也称为百分比坡度,范围:0 ~ ∞。
该工具可与其他类型的连续数据(如人口)配合使用,用来识别值的急剧变化。
关于工具的详细算法:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000vz000000/
3) 曲率(Curvature)
主要输出结果为每个像元的表面曲率。曲率是表面的二阶导数,或者可称之为坡度的坡度。曲率为正说明该像元的表面向上凸。曲率为负说明该像元的表面开口朝上凹入。值为 0 说明表面是平的。
可供选择的输出曲率类型为:剖面曲率(沿最大斜率的坡度)和平面曲率(垂直于最大坡度的方向)。
从应用的角度看,该工具的输出可用于描述流域盆地的物理特征,从而便于理解侵蚀过程和径流形成过程。坡度会影响下坡时的总体移动速率。坡向将决定流向。剖面曲率将影响流动的加速和减速,进而将影响到侵蚀和沉积。平面曲率会影响流动的汇聚和分散。
三、 填挖方(Cut Fill)
计算两表面间体积的变化。通常用于执行填挖操作。
默认情况下,将使用专用渲染器来高亮显示执行填挖操作的位置。该渲染器将被挖的区域绘制成蓝色,将被填的区域绘制成红色。没有变化的区域将显示为灰色。



四、 山影(Hillshade)

此工具考虑的主要因素是太阳(照明源)在天空中的位置。看下此工具的参数设置:

方位角(Azimuth)指的是太阳的角度方向,是以北为基准方向在 0 到 360 度范围内按顺时针进行测量的。90º 的方位角为东。
此工具默认方向角为 315º (NW)。

高度(Altitude)指的是太阳高出地平线的角度或坡度。高度的单位为度,范围为 0(位于地平线上)到 90(位于头上)之间。
此工具默认值为 45 度。

Model sahdows
通过对选择 Model sahdows,可计算局部照明度以及像元是否落入阴影内。阴影值为0,所有其他像元的编码为介于 1 和 255 之间的整数。
Z 因子(Z factor)
z 单位与输入表面的 x,y 单位不同时,可使用 z 因子调整 z 单位的测量单位。计算最终输出表面时,将用 z 因子乘以输入表面的 z 值。
如果 x,y 单位和 z 单位采用相同的测量单位;则 z 因子为 1。这是默认值。此外,z 因子还可用于地形夸大。
例如,如果 z 单位是英尺而 x,y 单位是米,则应使用 z 因子 0.3048 将 z 单位从英尺转换为米(1 英尺 = 0.3048 米)
关于工具的详细算法:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000z2000000/
五、可见性分析
1) 视点分析
视点工具生成的是在观测点处能够看到哪些位置的像元的二进制编码信息。观察点被限制为最多16 个。此工具仅支持点要素输入。
可见性信息存储在 VALUE 项中。如果要显示通过视点 3 能看到的所有栅格区域,就打开输出栅格属性表,然后选择视点 3 (OBS3) 等于 1 而其他所有视点等于 0 的记录。
例如,如下是7个观测点的可视性分析结果的属性表:
2) 视域
视域工具会创建一个栅格数据,以记录可从输入视点 或 视点折线要素 位置看到每个区域的次数。该值记录在输出栅格表的 VALUE 项中。
TIPS:控制可见性分析
通过在要素属性数据集中指定不同的项,可限制所检查的栅格区域。共有九项:SPOT、OFFSETA、OFFSETB、AZIMUTH1、AZIMUTH2、VERT1、VERT2、RADIUS1 和 RADIUS2。
附图帮助理解:



这些值的默认值:
选项 默认值 参数意义
SPOT 使用双线性插值进行估计 观测点位置的高程
OFFSETA 1 观测点高(例如,仪器高),必须为正数
OFFSETB 0 各像元高(例如,目标高),必须为正数
AZIMUTH1 0 观测起始方位角
AZIMUTH2 360 观测终止方位角
VERT1 90 观测起始竖直角
VERT2 -90 观测终止竖直角
RADIUS1 0 起始可见半径
RADIUS2 无穷大 终止可见半径
如果视点要素数据集是点要素类,则每个观测点都可具有属性表中的唯一一组观测约束。如果视点要素数据集是折线要素类,则沿输入折线的每个折点都会使用属性表的折线记录中包含的相同观测约束。如果某项不存在,将使用默认值。

邻域分析
ArcGIS 的空间分析扩展中,提供了这样一组邻域分析工具:

- 1. 块统计(Block Statistics)
- 2. 滤波器(Filter)
- 3. 焦点流(Focal Flow)
- 4. 焦点统计(Focal Statistics)
- 5. 线统计
- 6. 点统计
1. 块统计(Block Statistics)
分块统计,按照指定邻域类型计算区域统计值,输出区域为指定邻域类型的外接矩形。
以下为邻域的形式:
- NbrAnnulus({innerRadius}, {outerRadius}, {CELL | MAP})
- NbrCircle({radius}, {CELL | MAP}
- NbrRectangle({width}, {height}, {CELL | MAP})
- NbrWedge({radius}, {start_angle}, {end_angle}, {CELL | MAP})
- NbrIrregular(kernel_file)
- NbrWeight(kernel_file)
Irregular与Weight邻域类型需要指定核文件( .txt 文件)。
可以进行统计的计算类型:
- MEAN/平均值;
- MAJORITY/众数(出现次数最多的值);
- MAXIMUM/最大值;
- MEDIAN/中值;
- MINIMUM/最小值;
- MINORITY/少数(出现次数最少的值);
- RANGE/范围(最大值和最小值之差)。
- STD/标准差。
- SUM/总和。
- VARIETY/变异度(唯一值的数量)。
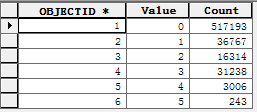
例如,输入为圆形邻域,输出为外接矩形的像元范围:
2. 滤波器(Filter)
对栅格执行平滑(低通)滤波器或边缘增强(高通)滤波器。
滤波器工具既可用于消除不必要的数据,也可用于增强数据中不明显的要素的显示。
低通滤波(平滑边界):

高通滤波(边缘增强):

3. 焦点流(Focal Flow)
焦点流工具使用直接的 3 x 3 邻域来确定一个像元的八个相邻点中哪一个流向此像元。
焦点流也可以是液体由高到低流动的方向,也可以是定义的任何移动(比如污染物向污染浓度较低的地方流入)。

举个例子,各个方向流向像元中心像元的值总和是最终值。

4. 焦点统计(Focal Statistics)
为每个输入像元位置计算其周围指定邻域内的值的统计数据。
统计类型与邻域形状与块统计是相同的,区别在于,块统计的输出是整个邻域的外接矩形范围,而焦点统计的输出,是邻域内的焦点栅格。如下图:

5. 线统计
工具用于为每个输出栅格像元周围的圆形邻域内所有线的指定字段值计算统计量。
可用的统计量类型有:均值、众数、最大值、中位数、最小值、少数、范围、标准差以及变异度。只有众数、少数和中位数统计量是根据线长度进行加权的。

还没有想到此工具的应用场景,以后有了再来追加。
6. 点统计
该工具类似于焦点统计工具,不同之处在于它直接对点要素而非栅格进行操作。直接对要素进行操作的其中一个优点在于,即使点距离过近,在转换成栅格时点也不会丢失。
区域分析
空间分析扩展中,有关区域分析,提供了如下工具:

可以将其分为这样几类:
一、确定区域中类的面积的工具
面积制表(Tabulate Area)
面积制表工具以表的形式进行输出。在此表中:
1)区域数据集的每个唯一值均有一条记录。
2)类数据集的每个唯一值均有一个字段。
3)每个记录将存储每个区域内每个类的面积。

TIPS:
使用此工具的常见错误:
1.“一个或多个输入没有关联属性表” 错误
此错误通常是由于区域输入中没有所需的属性表而导致的。
如果区域输入是一个栅格数据,请先使用构建栅格属性表为其创建一个属性表。
如果区域输入是一个要素数据集,则在内部转换为栅格的过程中会自动创建属性表。
2.“无法分配内存” 错误
程序使用内部表执行面积计算。如果区域输入的值域非常大(百万级别),则处理这些表的内存需求可能会接近或超出指定的系统分页文件大小。
如果所配置的内存总量不足,操作将失败,并将显示“无法分配内存”消息。此问题通常有两种解决方法:
A) 您可增大虚拟内存设置以避免出现此错误。但是,要注意的是,工具执行完毕后,操作系统不会立即释放其所占用的虚拟内存。从而可能会降低计算机的总体性能。
B) 另一种方法是减小区域的值域(建议方法)。步骤如下:首先向区域属性表添加一个新项和一个索引值,然后对该项使用面积制表,最后再将结果与原始区域输入相关联。
例如,如有仅有三个区域值 2,120,000、4,070,000 和 9,540,000,则可将它们除以 10,000,从而得到区域值 212、407 和 954。
3.输出面积小于预计结果
输出表中的某些面积值可能小于预计结果。
这通常与输入中的 NoData 像元有关,经重采样以匹配其他更为粗糙的输入之后,这些具有高分辨率的像元将变为更大的 NoData 区域。
为避免此情况,请对较粗糙的输入栅格进行重采样以使其与较精细的输入栅格的分辨率相匹配,或者将像元大小栅格分析环境设置为输入的最小值。
二、填充指定区域的工具
区域填充(Zonal Fill )
输入区域栅格数据可以为整型或浮点型。使用权重栅格数据沿区域边界的最小像元值填充区域。
区域填充可用作水文分析的一部分,将洼地填充至分水岭边界的最小高程。
此工具有待实践,结合水文分析学习。
三、作用于区域形状的工具
分区几何统计(Zonal Geometry)
这里说的区域是指具有相同值的所有像元。各区无需相连。栅格和要素数据集都可用于工具的输入。
这个工具的亮点在于可以统计区的总面积(AREA)、总周长(PERIMETER)、厚度(THICKNESS)、质心(CENTROID)。其他三个比较好理解,我们看下厚度的概念。
分区厚度分析可计算输入栅格上各个区域中最深或最厚点距其周围像元的距离。
实际上,厚度就是可在各个区域中(不包括区域外部的任何像元)绘制的最大圆的半径(以像元为单位)。如下图:
以表格显示分区几何统计(Zonal Geometry as Table)
将上述统计结果输出到Table表中。

其中,最后三个参数,用于描述各个区域的椭圆近似的形状。定义椭圆形状和大小的参数为长轴、短轴和方向。各椭圆的面积与为其分配的区域的面积相等。
MAJORAXIS:长轴的长度;MINORAXIS:短轴的长度。以地图单位表示。
ORIENTATION 值的单位为度,取值范围为 0 至 180。方向定义为 x 轴与椭圆长轴之间的角度。方向的角度值以逆时针方向增加,起始于东方向(右侧水平位置)的 0 值,在长轴垂直时通过 90 位置。如果某个特定区域仅由一个像元组成,或者该区域为单个像元方块,那么会将椭圆(在此情况下为圆)的方向设置为 90 度。

四、确定某输入栅格值在另一区域中的频数分布的工具
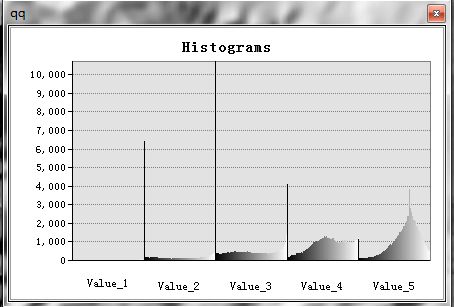
区域直方图(Zonal Histogram)
创建显示各唯一区域值输入中的像元值频数分布的表和直方图(Graph类型)。
区域字段必须为整型或字符串类型。

五、作用于区域属性的工具
分区统计(Zonal Statistics)
以表格显示分区统计(**Zonal Statistics as Table**)
这两个工具是,计算在另一个数据集的区域内栅格数据值的统计信息。这里的区域定义为输入中具有相同值的所有区。各区无需相连。栅格和要素数据集都可用于区域输入。
前者生成栅格数据,后者生成统计表。


多元分析
通过多元统计分析可以探查许多不同类型的属性之间的关系。
有两种可用的多元分析:分类(监督分类与非监督分类/Supervised&Unsupervised))和主成分分析/Principal Component Analysis (PCA)。
ArcGIS 提供了如下工具:

- 一、确定区域中类的面积的工具
- 面积制表(Tabulate Area)
- 二、填充指定区域的工具
- 区域填充(Zonal Fill )
- 三、作用于区域形状的工具
- 分区几何统计(Zonal Geometry)
- 以表格显示分区几何统计(Zonal Geometry as Table)
- 四、确定某输入栅格值在另一区域中的频数分布的工具
- 区域直方图(Zonal Histogram)
- 五、作用于区域属性的工具
- 分区统计(Zonal Statistics)
一、波段集统计工具(Band Collection Statistics)
栅格波段必须具有一个公共交集。如果不存在公共交集,则会出现错误,且不会创建任何输出。
如果栅格波段的范围不同,统计数据将以所有输入栅格波段的共同的空间范围来计算。默认情况下,像元大小为输入栅格的最大像元的大小;否则,将取决于栅格分析环境设置。
此工具计算每个图层的基本统计测量值(最小值、最大值、平均值和标准差),如果勾选协方差和相关矩阵,还可以得到这两个值。

二、创建特征(Create Signature)
创建由输入样本数据和一组栅格波段定义的类的 ASCII 特征文件。该工具可创建将用作其他多元分析工具的输入参数的文件。
该文件由两部分组成:
1) 所有类的常规信息,例如图层数、输入栅格名称和类别数。
2) 每个类别的特征文件,由样本数、平均值和协方差矩阵组成。
三、编辑特征(Edit Signature)
通过合并、重新编号和删除类特征来编辑和更新特征文件。
输入特征重映射文件是 ASCII 文件,其每一行有两列值与之对应,以冒号分隔。第一列是原始类 ID 值。第二列包含用于在特征文件中更新的新类 ID。文件中的所有条目必须基于第一列以升序进行排序。
编辑特征文件的写法是固定的,如下:
只有需要编辑的类才必须被放入特征重映射文件;任何在重映射文件中不存在的类将保持不变。
要合并一组类,原类 ID:新类 ID。
要删除类特征,使用 -9999 作为该类第二列的值。
要重新编号,将类 ID 重新编号为某个不存在于输入特征文件中的值。
示例:
1 2 3 4 |
2 : 3 4 : 11 5 : -9999 9 : 3 |
上例将使用 3 合并类 2 和 类 9,使用 11 合并类 4,并将删除类 5。
四、树状图(Dendrogram)
构造可显示特征文件中连续合并类之间的属性距离的树状图。
有关其工作原理,详见:http://help.arcgis.com/zh-cn/arcgisdesktop/10.0/help/index.html#/na/009z000000q6000000/
五、最大似然法分类(Maximum Likelihood Classification)
最大似然法分类工具所用的算法基于两条原则:
1) 每个类样本中的像元在多维空间中呈正态分布
2) 贝叶斯决策理论
TIPS:工具中有几个参数需要注意:
reject_fraction:将因最低正确分配概率而得不到分类的像元部分。
默认值为 0.0;将对每个像元进行分类。共有 14 个有效输入:0.0、0.005、0.01、0.025、0.05、0.1、0.25、0.5、0.75、0.9、0.95、0.975、0.99 和 0.995。
a_priori_probabilities:指定将如何确定先验概率。
- EQUAL — 所有类将具有相同的先验概率。
- SAMPLE — 先验概率将与特征文件内所有类中采样像元总数的相关的各类的像元数成比例。
- FILE — 先验概率将会分配给输入 ASCII 先验概率文件中的各个类。
以下是通过三类样本的特征文件,分类的栅格数据的示例:
六、Iso 聚类(Iso Cluster)
Iso表示:iterative self-organizing –迭代自组织方法。
Iso聚类工具对输入波段列表中组合的多元数据执行聚类。所生成的特征文件(*.gsg)可用作生成非监督分类栅格的分类工具(例如最大似然法分类)的输入。
类数的最小有效值为二。不存在最大聚类数。通常情况下,聚类越多,所需的迭代就越多。
七、Iso 聚类非监督分类(Iso Cluster Unsupervised Classification)
此工具为脚本工具,此工具结合了 Iso 聚类工具与最大似然法分类工具的功能。输出经过分类的栅格。
八、类别概率(Class Probability)
如果发现分类中的某些区域被分配给某一类的概率不是很高,则说明可能存在混合类。
例如,根据分类概率波段,一个已被分类为森林的区域属于森林类的概率只有 55%。您又发现同一区域属于草地类的概率却有 40%。显然,该区域既不属于森林类也不属于草地类。它更可能是一个森林草地混合类。对于使用分类概率工具生成的分类概率,最好检查分类结果。
生成的多波段栅格数据的波段数等于类别数,每个波段表示某种分类的可能概率,像元值从0至100。
九、主成分分析(Principal Components)
对一组栅格波段执行主成分分析 (PCA) 并生成单波段栅格作为输出。此工具生成的是波段数与指定的成分数相同的多波段栅格。
主成分分析工具用于将输入多元属性空间中的输入波段内的数据变换到相对于原始空间对轴进行旋转的新的多元属性空间。新空间中的轴(属性)互不相关。之所以在主成分分析中对数据进行变换,主要是希望通过消除冗余的方式来压缩数据。
以上提到的几个工具,在ArcGIS 10.x版本中,除了在ArcToolbox中可以找到,在 Image Classification 工具条中也可以找到对应的功能,如下图:

这个工具集涉及很多遥感的理论知识,仅仅使用工具是不够的,后面需要多多学习……
插值分析
在实际工作中,由于成本的限制、测量工作实施困难大等因素,我们不能对研究区域的每一位置都进行测量(如高程、降雨、化学物质浓度和噪声等级)。这时,我们可以考虑合理选取采样点,然后通过采样点的测量值,使用适当的数学模型,对区域所有位置进行预测,形成测量值表面。插值之所以可称为一种可行的方案,是因为我们假设,空间分布对象都是空间相关的,也就是说,彼此接近的对象往往具有相似的特征。
ArcGIS的空间分析中,提供了插值(Interpolation)工具集,如下:

- 1. 反距离权重法(IDW–Inverse Distance Weighted)
- 2. 克里金法(Kriging)
- 3. 自然邻域法(Natural Neighbor)
- 4. 样条函数(Spline)
- 5. 含障碍的样条函数(Spline with Barriers)
- 6. 地形转栅格(Topo to Raster)
- 7. 趋势(trend)
1. 反距离权重法(IDW–Inverse Distance Weighted)
此方法假定所映射的变量因受到与其采样位置间的距离的影响而减小。
幂参数:
IDW主要依赖于反距离的幂值。基于距输出点的距离,幂参数可以控制已知点对内插值的影响。幂参数是一个正实数,默认值为 2,一般在0.5至3之间取值。随着幂值的增大,内插值将逐渐接近最近采样点的值。指定较小的幂值,将对距离较远的周围点产生更大影响,会产生更加平滑的表面。由于反距离权重公式与任何实际物理过程都不关联,因此无法确定特定幂值是否过大。作为常规准则,认为值为 30 的幂是超大幂,因此不建议使用。此外还需牢记一点,如果距离或幂值较大,则可能生成错误结果。
障碍:
障碍是一个用作可限制输入采样点搜索的隔断线的折线 (polyline) 数据集。一条折线 (polyline) 可以表示地表中的悬崖、山脊或某种其他中断。仅将那些位于障碍同一侧的输入采样点视为当前待处理像元。
注意事项:
(1)因为反距离权重法是加权平均距离,所以该平均值不可能大于最大输入或小于最小输入。因此,如果尚未对这些极值采样,便无法创建山脊或山谷。
(2)此工具最多可处理约 4,500 万个输入点。如果输入要素类包含 4,500 万个以上的点,工具可能无法创建结果。
工具执行截图:

2. 克里金法(Kriging)
克里金法假定采样点之间的距离或方向可以反映可用于说明表面变化的空间相关性。克里金法是一个多步过程;它包括数据的探索性统计分析、变异函数建模和创建表面,还包括研究方差表面。该方法通常用在土壤科学和地质中。
3. 自然邻域法(Natural Neighbor)
可找到距查询点最近的输入样本子集,并基于区域大小按比例对这些样本应用权重来进行插值。该插值也称为 Sibson 或“区域占用 (area-stealing)”插值。
4. 样条函数(Spline)
使用二维最小曲率样条法将点插值成栅格表面。生成的平滑表面恰好经过输入点。
5. 含障碍的样条函数(Spline with Barriers)
通过最小曲率样条法利用障碍将点插值成栅格表面。障碍以面要素或折线要素的形式输入。样条函数法工具所使用的插值方法使用可最小化整体表面曲率的数学函数来估计值。
6. 地形转栅格(Topo to Raster)
将点、线和面数据插值成符合真实地表的栅格表面。
依据文件实现地形转栅格(Topo to Raster by file)
通过文件中指定的参数将点、线和面数据插值成符合真实地表的栅格表面。通过这种技术创建的表面可更好的保留输入等值线数据中的山脊线和河流网络。
7. 趋势(trend)
使用趋势面法将点插值成栅格曲面。趋势表面会逐渐变化,并捕捉数据中的粗尺度模式。
以上是插值工具的简单说明与比较,这些工具的背后都有庞大的理论基础和复杂的算法,需要进一步学习整理和补充。
水文分析
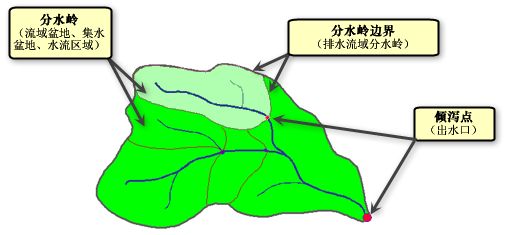
接收雨水的区域以及雨水到达出水口前所流经的网络被称为水系。流经水系的水流只是通常所说的水文循环的一个子集,水文循环还包括降雨、蒸发和地下水流。水文分析工具重点处理的是水在地表上的运动情况。“水文分析”工具用于为地表水流建立模型。

盆域分析(Basin):创建描绘所有流域盆地的栅格。
填洼(Fill):通过填充表面栅格中的汇来移除数据中的小缺陷。
流量(Flow Accumulation):创建每个像元累积流量的栅格。可选择性应用权重系数。
流向(Flow Direction):创建从每个像元到其最陡下坡相邻点的流向的栅格。
水流长度(Flow length):计算沿每个像元的流路径的上游(或下游)距离或加权距离。
汇(Sink):创建识别所有汇或内流水系区域的栅格。
捕捉倾泻点(Snap pour point):将倾泻点捕捉到指定范围内累积流量最大的像元。
河流连接(Stream link):向各交汇点之间的栅格线状网络的各部分分配唯一值。
河网分级(Stream Order):为表示线状网络分支的栅格线段指定数值顺序。
栅格河网矢量化(Stream to Feature):将表示线状网络的栅格转换为表示线状网络的要素。
分水岭(Watershed):确定栅格中一组像元之上的汇流区域。
了解水系的术语,如下图:
以下流程图显示的是从数字高程模型 (DEM) 中提取水文信息(如分水岭边界和河流网络)的过程:

现在就以手中的这个DEM为例来依次使用工具集中的工具,来学习这部分功能:

一、流向(Flow Direction)
流向工具的输出是值范围介于 1 到 255 之间的整型栅格。从中心出发的各个方向值为:
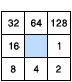
例如,如果最陡下降方向位于当前处理像元的左侧,则将该处理像元的流向编码将为 16。
如果像元的 z 值在多个方向上均发生相同变化,并且该像元是凹陷点的一部分,则该像元的流向将被视为未定义。此时,该像元在输出流向栅格中的值将为这些方向的总和。例如,如果 z 值向右(流向 = 1)和向下(流向 = 4)的变化相同,则该像元的流向为 1 + 4 = 5。可以使用汇工具将具有未定义流向的像元标记为凹陷点。

二、汇(Sink)
汇是指流向栅格中流向无法被赋予八个有效值之一的一个或一组空间连接像元。汇被视为具有未定义的流向,并被赋予等于其可能方向总和的值。
汇工具的输出是一个整型栅格,其中每个汇都被赋予一个唯一值。汇的编号介于 1 到汇的数量之间。

三、填洼(Fill)
通过填充表面栅格中的汇来移除数据中的小缺陷。
凹陷点是指具有未定义流域方向的像元;其周围的像元均高于它。倾泻点相对于凹陷点的汇流区域高程最低的边界像元。如果凹陷点中充满了水,则水将从该点倾泻出去。
TIPS:有关填充的Z限制
要填充的凹陷点与其倾泻点之间的最大高程差。如果凹陷点与其倾泻点之间的 z 值差大于 z 限制,则不会填充此凹陷点。
默认情况下将填充所有凹陷点(不考虑深度)。
四、流量(Flow Accumulation)
创建每个像元累积流量的栅格。流量累积将基于流入输出栅格中每个像元的像元数。
高流量的输出像元是集中流动区域,可用于标识河道。流量为零的输出像元是局部地形高点,可用于识别山脊。
流量工具不遵循压缩环境设置。输出栅格将始终处于未压缩状态。
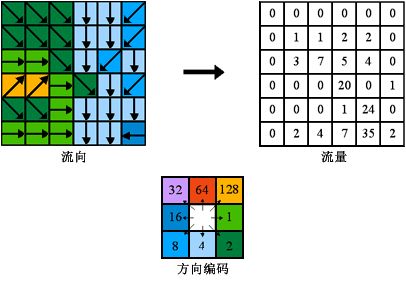
通过上面的填洼,求流向,得到如下流量图,看到了河道:

五、河网分级(Stream Order)
河网分级是一种将级别数分配给河流网络中的连接线的方法。此级别是一种根据支流数对河流类型进行识别和分类的方法。仅需知道河流的级别,即可推断出河流的某些特征。
河网分级工具有两种可用于分配级别的方法。这两种方法由 Strahler (1957) 和 Shreve (1966) 提出。在这两种方法中,始终将 1 级分配给上游河段。
Strahler 河流分级方法:
在 Strahler 法中,所有没有支流的连接线都被分为 1 级,它们称为第一级别。当级别相同的河流交汇时,河网分级将升高。
因此,两条一级连接线相交会创建一条二级连接线,两条二级连接线相交会创建一条三级连接线,依此类推。但是,级别不同的两条连接线相交不会使级别升高。例如,一条一级连接线和一条二级连接线相交不会创建一条三级连接线,但会保留最高级连接线的级别。

Shreve 河流分级方法:
Shreve 法考虑网络中的所有连接线。与 Strahler 法相同,所有外连接线都被分为 1 级。但对于 Shreve 法中的内连接线,级别是增加的。例如,两条一级连接线相交会创建一条二级连接线,一条一级连接线和一条二级连接线相交会创建一条三级连接线,而一条二级连接线和一条三级连接线相交则会创建一条五级连接线。
因为级别可增加,所以 Shreve 法中的数字有时指的是量级,而不是级别。在 Shreve 法中,连接线的量级是指上游连接线的数量。

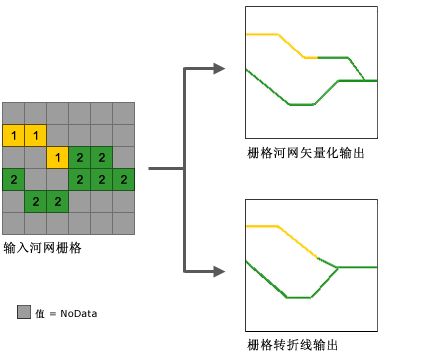
六、栅格河网矢量化(Stream to Feature)
栅格河网矢量化工具使用的算法主要用于矢量化河流网络或任何表示方向已知的栅格线性网络的栅格。
该工具使用方向栅格来帮助矢量化相交像元和相邻像元。可将两个值相同的相邻栅格河网矢量化为两条平行线。
这与栅格转折线 (Raster to Polyline) 工具相反,后者通常更倾向于将线折叠在一起。下图是两者的对比:
七、河流连接(Stream link)
向各交汇点之间的栅格线状网络的各部分分配唯一值。
“连接”是指连接两个相邻交汇点、连接一个交汇点和出水口或连接一个交汇点和分水岭的河道的河段。


八、水流长度(Flow Length)
水流长度工具的主要用途是计算给定盆地内最长水流的长度。该度量值常用于计算盆地的聚集时间。这可使用 UPSTREAM 选项来完成。
该工具也可通过将权重栅格用作下坡运动的阻抗,来创建假设降雨和径流事件的距离-面积图。

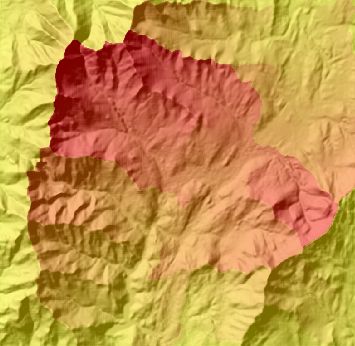
九、捕捉倾泻点(Snap pour point)
捕捉倾泻点工具用于确保在使用分水岭工具描绘流域盆地时选择累积流量大的点。
捕捉倾泻点将在指定倾泻点周围的捕捉距离范围内搜索累积流量最大的像元,然后将倾泻点移动到该位置。
十、分水岭(Watershed)
确定栅格中一组像元之上的汇流区域。

十一、盆域
创建描绘所有流域盆地的栅格。
通过识别盆地间的山脊线,在分析窗口中描绘流域盆地。通过分析输入流向栅格数据找出属于同一流域盆地的所有已连接像元组。通过定位窗口边缘的倾泻点(水将从栅格倾泻出的地方)及凹陷点,然后再识别每个倾泻点上的汇流区域,来创建流域盆地。这样就得到流域盆地的栅格。
以下是盆域分析示例:
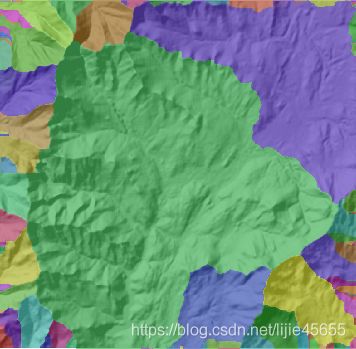
转自穆晓燕博客,比较喜欢她写的技术文章,讲的很细,也很清楚:http://kikitamap.com/