大数据之超级详细的KafKa集群搭建过程
大数据
大数据之超级详细的KafKa集群搭建过程
文章目录
- 大数据
-
- 大数据之超级详细的KafKa集群搭建过程
- 前言
- 一、Kafka集群配置方法
-
- 1.1 将Kafka的安装包上传到虚拟机,并解压(三个虚拟机同样操作)
- 1.2 使用root用户在所有的slave节点上配置系统环境变量
- 1.3 使环境变量生效
- 1.4 修改 server.properties
- 1.5 启动服务器(都启动)
- 二、Kafka集群的基本操作
-
- 2.1 创建topic
- 2.2 生产消息到Kafka(hadoop102)
- 2.3 从Kafka消费消息(hadoop103)
- 2.4 停止kafka集群
- 总结
前言
分布式消息系统kafka的提供了一个生产者、缓冲区、消费者的模型
下面我将详细介绍Kafka集群配置的方法和Kafka集群的基本操作
一、Kafka集群配置方法
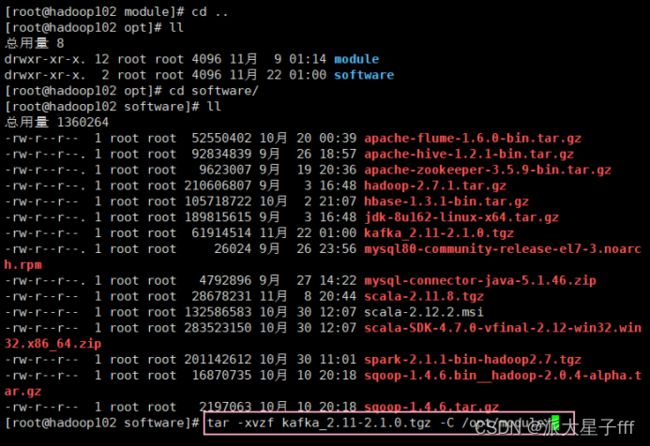
1.1 将Kafka的安装包上传到虚拟机,并解压(三个虚拟机同样操作)
tar -xvzf kafka_2.11-2.1.0.tgz -C /opt/module/
cd module/
1.2 使用root用户在所有的slave节点上配置系统环境变量
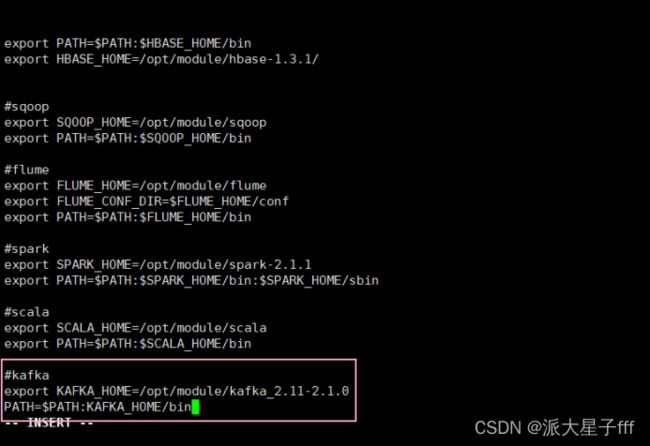
先vi /etc/profile 进入配置文件
#kafka
export KAFKA_HOME=/opt/module/kafka_2.11-2.1.0
PATH=$PATH:KAFKA_HOME/bin
1.3 使环境变量生效
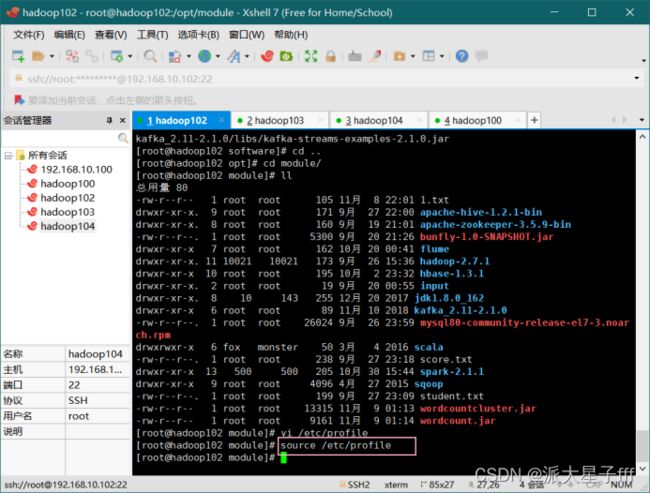
source /etc/profile
1.4 修改 server.properties
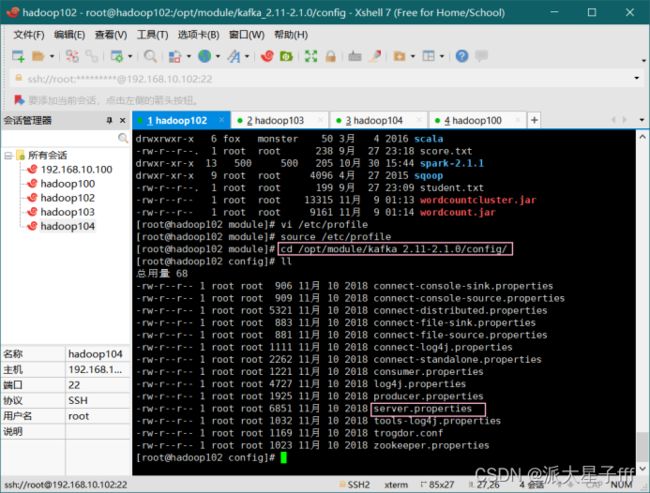
cd /opt/module/kafka_2.11-2.1.0/config/
vi server.properties
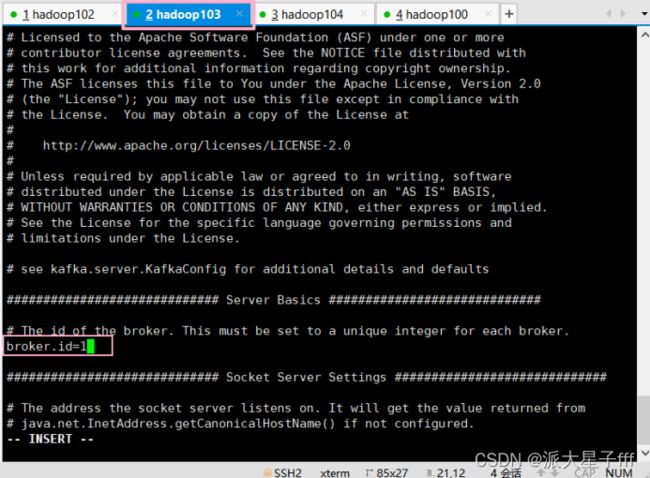
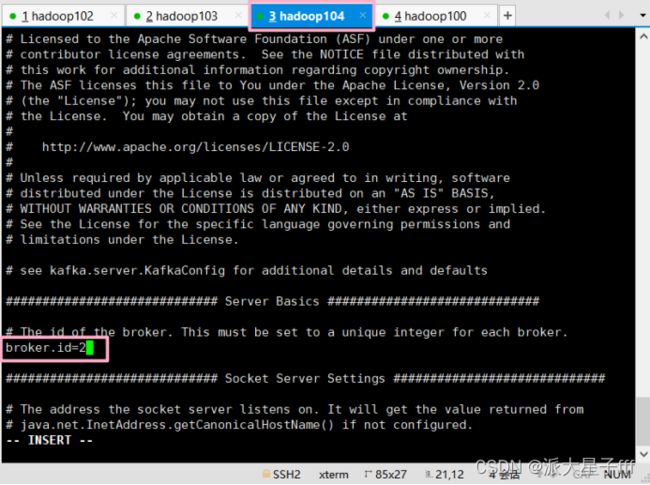
指定broker的id
broker.id=0(三个节点id不同!!!)
hadoop102:id=0,hadoop103:id=1,hadoop104:id=2)
指定Kafka数据的位置
log.dirs=/opt/module/kafka_2.11-2.1.0/data
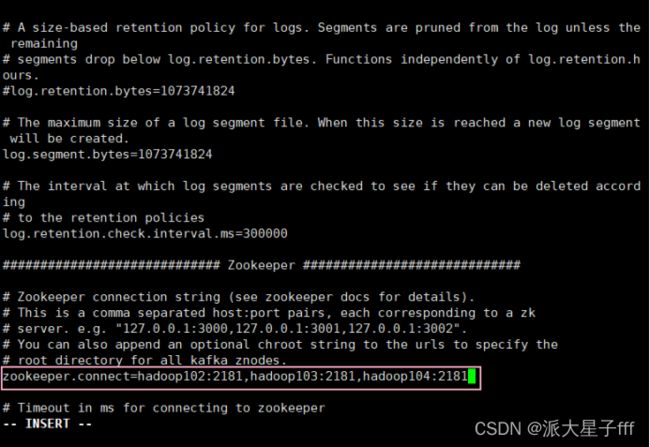
配置zk的三个节点
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
说明:
broker.id : 集群内全局唯一标识,每个节点上需要设置不同的值
log.dirs :存放kafka消息的
zookeeper.connect : 配置的是zookeeper集群地址


1.5 启动服务器(都启动)
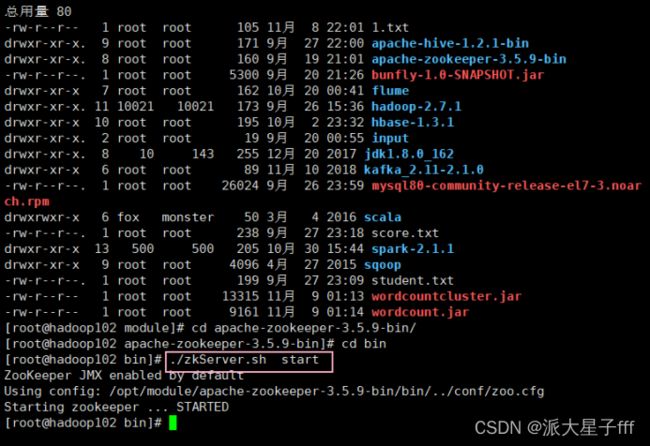
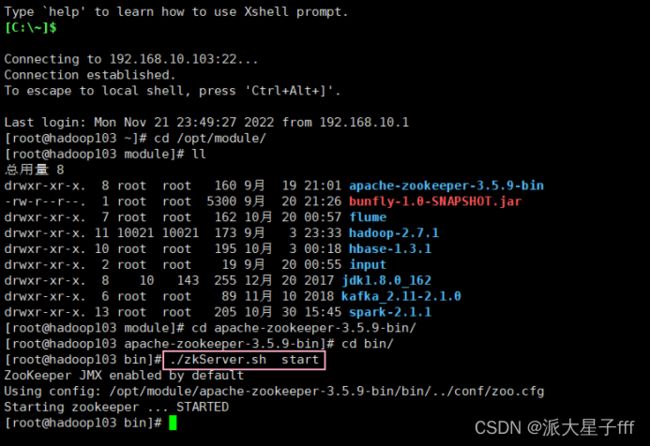
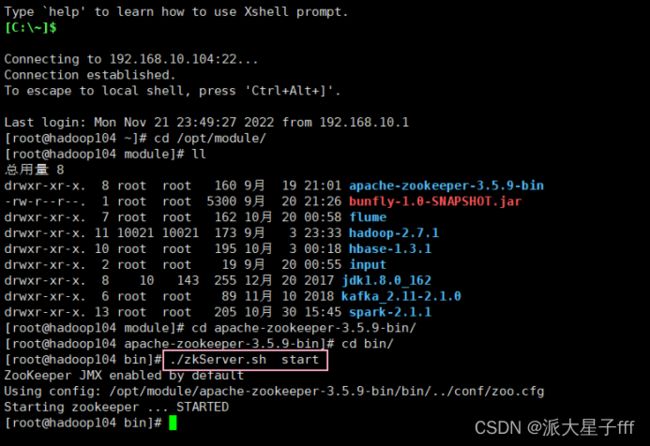
启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &

启动Kafka
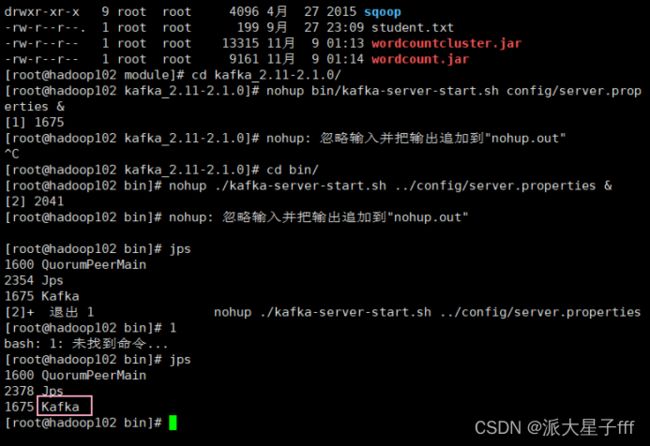
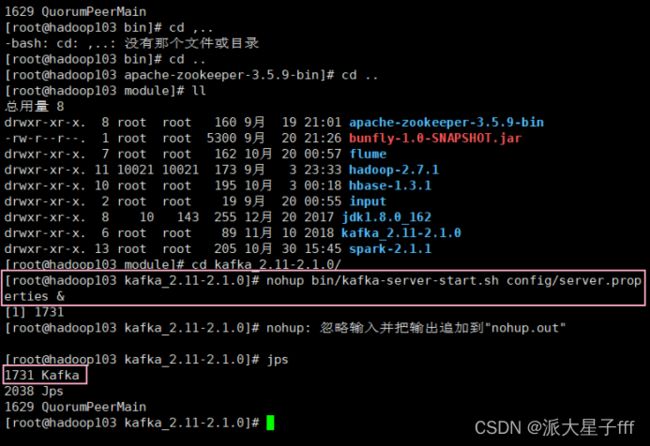
cd /opt/module/kafka_2.11-2.1.0
nohup bin/kafka-server-start.sh config/server.properties &
或者
./kafka-server-start.sh -daemon /opt/module/Kafka_2.11-2.1.0/config/server.properties
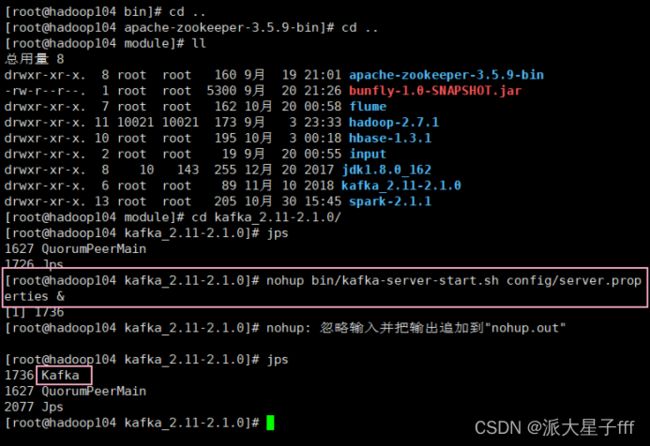

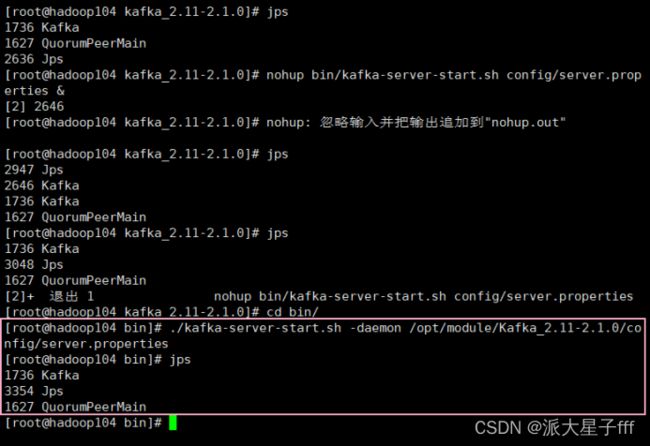
测试Kafka集群是否启动成功
bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
#还没有创建主题所以什么都不显示
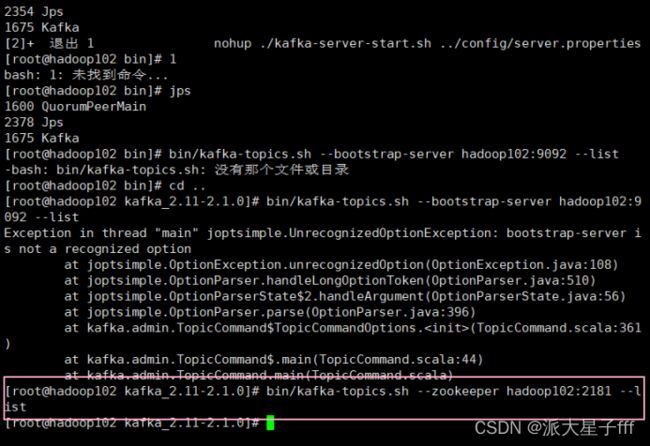
二、Kafka集群的基本操作
2.1 创建topic
创建一个topic(主题)。Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为fjrKafka的主题
./kafka-topics.sh --create --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --replication-factor 1 --partitions 1 --topic fjrKafka
参数解释:
– replication- factor:用于指定主题目录的副本数量
–partitions: 用于指定创建的主题下的分区数量
–topic:用于指定创建的主题名称
注意:
1、必须指定分区数和副本数
2、每个broker最多只能存储1个副本,也就是副本数不能大于broker的数量
3、若不设置- replica -assignment,kafka会 自动根据负载均衡策略,将多个副本分配到各个broker
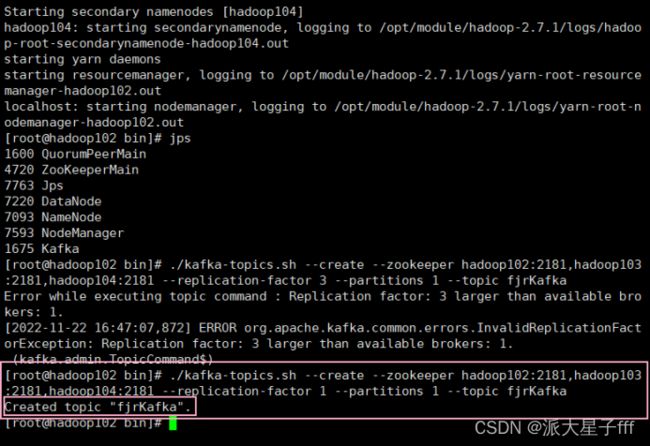
# 查看目前Kafka中的主题
./kafka-topics.sh --list --zookeeper hadoop102:2181
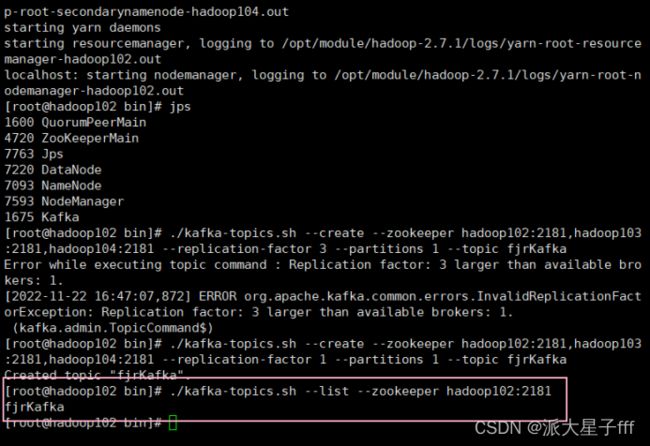
#查看主题具体信息
./kafka-topics.sh --describe --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic fjrKafka
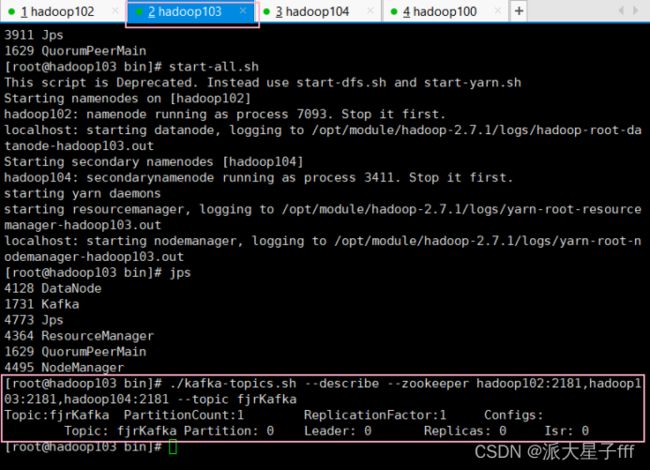
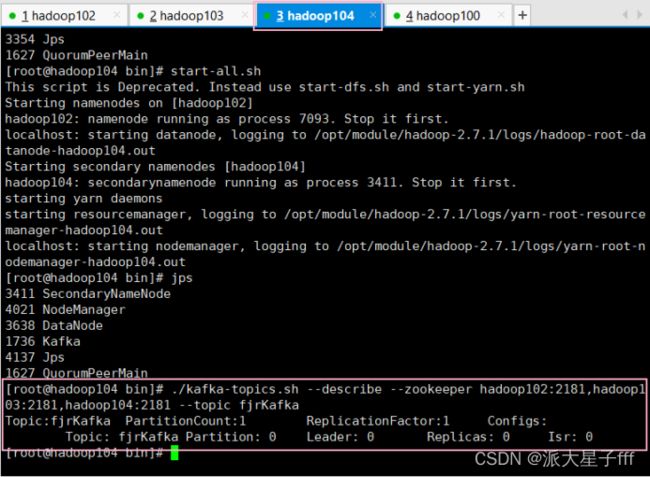
2.2 生产消息到Kafka(hadoop102)
使用Kafka内置的测试程序,生产一些消息到Kafka的fjrKafka 主题中。
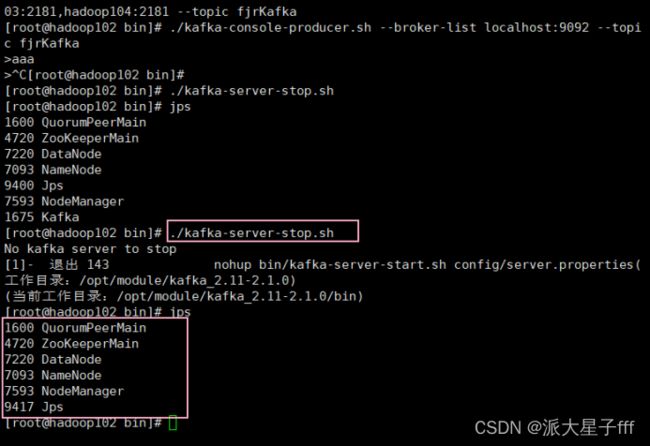
./kafka-console-producer.sh --broker-list localhost:9092 --topic fjrKafka
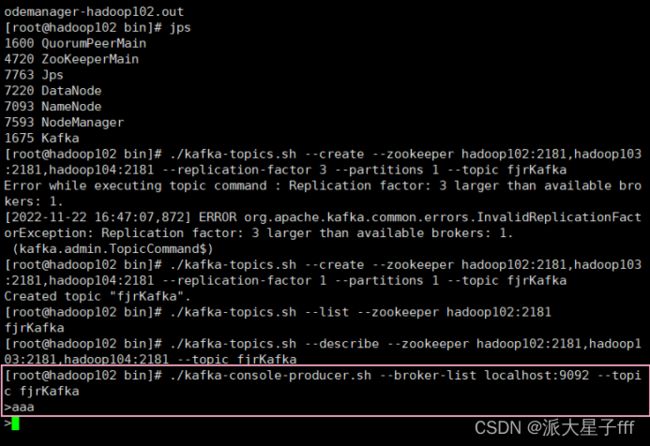
输入aaa传给hadoop103
2.3 从Kafka消费消息(hadoop103)
使用下面的命令来消费 fjrKafka 主题中的消息。
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic fjrKafka --from-beginning
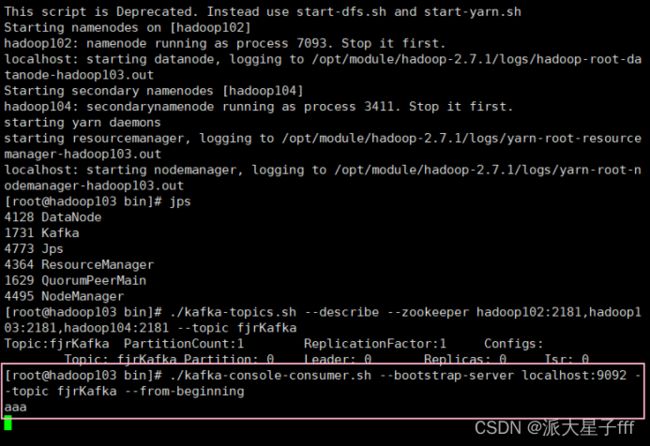
接收到hadoop102传来的aaa了
2.4 停止kafka集群
./kafka-server-stop.sh
总结
以上就是今天要讲的内容,本文仅仅简单介绍了大数据之超级详细的KafKa集群搭建过程,结合书本内容和以上详细步骤,相信你也可以成功。