Linux——文件(进阶篇)
文章目录
- 原子操作和竞争条件
- 文件操作控制:fcntl()
-
- 获得打开文件状态
- 修改打开文件的状态
- 文件描述符和打开文件之间的关系
- 文件描述符的复制:dup和fcntl
- 文件偏移I/O:pread和pwrite
- 分散式输入和集中输出:readv 和 writev
-
- 分散输入:readv
- 分散输出:writev
- 在指定的文件偏移量处执行分散输入/集中输出:preadv和pwritev
- 截断文件:truncate和ftruncate
- 文件在磁盘中的存储
- 参考文献
写在前面:此系列主要参考自UNIX系统编程手册,将会有大量demo
阅读此文章前,推荐没有基础的小伙伴先阅读姐妹篇:Linux——文件(基础篇)
书籍链接:微云链接
原子操作和竞争条件
熟悉多线程编程的小伙伴可能有疑惑了,如果我两个线程同时对这个文件去进行write操作,是否会发生数据覆盖的事情呢?
确实,我们平时没有太多去关注系统调用的线程安全问题。这是因为,所有系统调用都是以原子操作的方式去执行的。内核保证了系统调用中的所有步骤会作为独立操作而一次性加以执行,期间不会被其他进程或线程中断。
一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
thread: 139974751966976 input: V
thread: 139974743574272 input: S
thread: 139974735181568 input: M
再看看文件中的内容:
a.txt
123456789 10 11 12 V S M
可以看到,它在不加锁的情况下,并没有发生数据覆盖的现象。
文件操作控制:fcntl()
#include fcntl() 的用途之一是针对一个打开的文件,获取或修改其访问模式和状态标志。
获得打开文件状态
要获取我们设置文件的flag,我们可以将cmd参数设置F_GETFL。这个参数就会限定 fcntl 的返回值为当前文件的打开方式。
一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
open file by O_RDWR
注意事项:
由于O_RDONLY、O_WRONLY、O_RDWR这三个常量并不与打开文件状态标志中的单个比特位对于。因此要判断访问模式需要以O_ACCMODE与一下。
修改打开文件的状态
通过指定 fcntl 的cmd参数为F_SETFL,我们可以在后面跟上状态flag以修改文件状态。
一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
open file by O_RDWR and O_NONBLOCK
文件描述符和打开文件之间的关系
在姊妹篇中我画了一幅图,上面显示着文件描述符和打开文件之间的关系。但是并不完整,从图中其实没有显示出多个文件描述符指向同一打开文件这一特性。
事实上,有关文件描述符和打开文件之间的关系,我们可以从以下三个表中获得:
- 进程级的文件描述符表
- 系统级的打开文件表
- 文件系统的i-node表
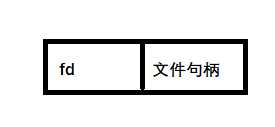
就像之前介绍的那样:针对每个进程,内核为其为了打开文件的描述符表,改表的每一个条目都记录了单个文件描述符的相关信息:
-
控制文件描述符操作的标志
-
对打开文件句柄的引用
同时,内核对所有打开的文件维护有一个系统级的描述表格。被称为打开文件表,并将表中各条目称为打开文件句柄。一个打开文件句柄存储了与一个打开文件的全部信息: -
当前文件偏移量
-
打开文件的状态标志
-
文件访问模式
-
与信息驱动I/O相关设置
-
对i-node对象的引用

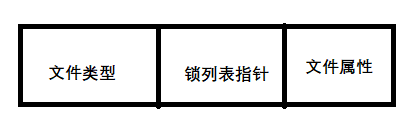
对于每个文件,系统都会为驻留在系统上的文件简历一个i-node表: -
文件类型
-
指向锁列表的指针
-
文件的各种属性
以下这张图生动的显示了这三个表的联系:

文件描述符的复制:dup和fcntl
??? 嗯?复制文件描述符我不可以这样么:
int file_fd2 = file_fd1;
这样其实复制的只是这个文件描述符的值,其并没有在文件描述符表中多加一行。
Linux提供了以下系统调用来使得进行文件描述符的复制,虽然说文件描述符不同,但是实际上这两个文件描述符都是代表着同一个文件
#include 一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
new fd: 4 old fd: 3
可以看到,我们获得的新的文件描述符的值为:4
那如果我们想要获得指定的文件描述符那该怎么办呢?可以使用如下系统调用:
#include 一个简单的demo:
//和上一段代码高度雷同,就写一下替换部分
int newfd = dup2(file_fd,5);
if(newfd !=-1)
{
cout<<"new fd: "<<newfd<<"old fd: "<<file_fd<<endl;
}
输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
new fd: 5 old fd: 3
注意事项:
如果oldfd 并非有效的文件描述符,那么dup2()调用将失败并返回错误EBADF,且不关闭newfd。
如果oldfd有效,且与newfd的值相等,那么dup2()将什么也不做。
当然,处理dup2,还可以将 fcntl 的cmd设置为F_DUPFD来复制一个文件描述符。fcntl 是真的强大啊!
一个简单的demo:
//同样,只提供关键代码
int newfd = fcntl(file_fd,F_DUPFD,5);
if(newfd !=-1)
{
cout<<"new fd: "<<newfd<<"old fd: "<<file_fd<<endl;
}
输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
new fd: 5 old fd: 3
文件偏移I/O:pread和pwrite
对于pread 和 pwrite来说,做的主要工作就是在特定的偏移位置进行read / write操作。
#include 一个简单的demo:
// a.txt文件内容
//123456789 10 11 12
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
read bytes:15 456789 10 11 12
read bytes:18 123hello9 10 11 12
可以看到,在指定的偏移量的地方,文件内容发生了改变。
其实 pread 系统调用相当于将以下调用一起纳入原子操作:
off_t origin = lseek(file_fd,0,SEEK_CUR);
lseek(file_fd,offset,SEEK_SET);
int length = read(file_fd,buf,len);
lseek(fd,origin,SEEK_SET);
相比于这种方式,pread 无疑是更加高效的,它将多次系统调用融为一次,减少了频繁内核态、用户态切换的开销。
分散式输入和集中输出:readv 和 writev
以下两个系统调用并非只对单个缓冲区进行读写操作,而是一次即可传输多个缓冲区的数据,数组iov定了了一组用来传输数据的缓冲区
#include 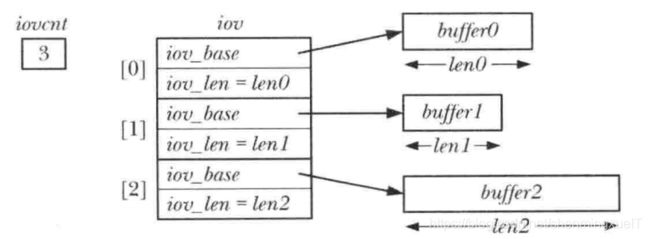
分散输入:readv
readv 系统调用实现了分散输入的功能:从文件描述符fd所代指的文件中读取一片连续的字节,然后将其散置与iov指定的缓冲区中。这一散置动作从iov[0] 开始,依次填满每个缓冲区。
一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
read bytes:18
12
34
56789 10 11 12
分散输出:writev
writev系统调用实现了集中输出:将iov所指定的所有缓冲区中数据拼接起来,然后以连续的字节序列写入文件描述符fd所代指的文件中。对缓冲区中数据的开始于iov[0] 所指定的缓冲去,并按数组顺序展开。
一个简单的demo:
#include 输出:
ik@ik-virtual-machine:~/桌面/test/bin$ ./test1 a.txt
write bytes:11
在指定的文件偏移量处执行分散输入/集中输出:preadv和pwritev
preadv和pwritev这两个函数将分散输入/集中输出和指定文件偏移量集中于一,虽然说在linux 2.6.30版本并非标准的系统调用,但是获得了 现代 BSD支持,需要宏定义_BSD_SOURCE
#define _BSD_SOURCE
#include 关于这两个函数,博主的linux版本是:
ik@ik-virtual-machine:~/桌面/test/bin$ cat /proc/version
Linux version 5.4.0-70-generic (buildd@lgw01-amd64-039)
(gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) #78~18.04.1-Ubuntu SMP Sat Mar 20 14:10:07 UTC 2021
目前来看是支持的,但是通过百度、谷歌等途径是基本没有找到相关资料的。小伙伴可以在自己的虚拟机上实验一下。
截断文件:truncate和ftruncate
truncate 和 ftruncate 系统调用将文件大小设置为length参数指定的值:
#include 若文件当前长度大于参数length,调用将丢弃超出部分,若小于参数,调用将在文件尾部添加一系列空字节或者是一个文件空洞。
两个系统调用之间的差别在于如何指定操作文件。
truncate以路径名字符串来指定文件,并要求可访问该文件,且对文件拥有写权限。而ftruncate使用之前,需要以可写方式打开操作文件,获取其文件描述符以代指该文件,该系统调用不会修改文件偏移量。
一个简单的demo:
//只演示truncate
#include 文件中内容:

文件在磁盘中的存储
在文件系统中,用来分配空间的基本单位时逻辑块。亦即文件系统所在磁盘设备上若干连续的物理块。在linux的ext2系统上,逻辑块的大小为1024、2048和4096字节。
图示为磁盘分区和文件系统之间的关系:

文件系统有以下及部分组成:
- 引导块:总是作为文件的首块,包含引导操作系统的信息
- 超级块:包含与文件系统有关的参数信息
i 节点表容量
文件系统中逻辑块大小
以逻辑块,文件系统的大小 - i 节点表:文件系统中每个文件或目录在 i 节点表中都对应着唯一一条记录。这条记录登记了关于文件的各种信息
- 数据块:文件系统的大部分空间都用于存放数据
i 节点:
内核在 i 节点维护有一组指针,其中前12个指针指向文件前12个块在文件系统中的位置。接下来,是一个指向指针块的指针,提供了文件的第13个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小。
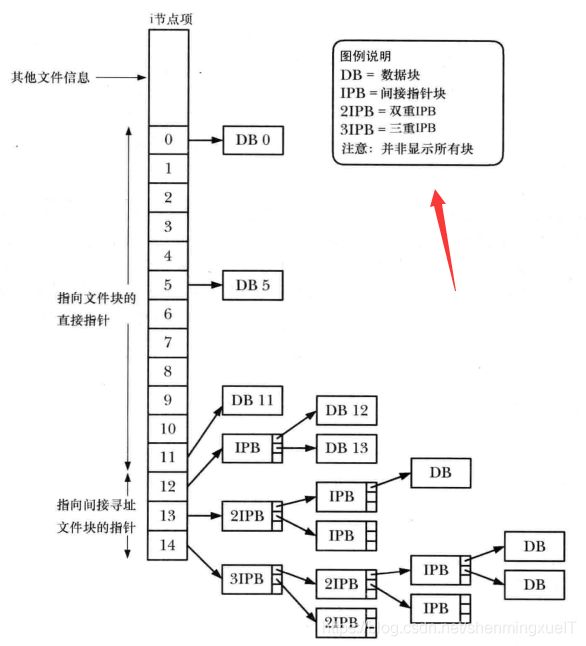
这一设计考虑了举行文件的处理,对于大小4096字节的块,理论上文件大小可略高于102410241024*4096(4TB)字节。
同时,这种设计还可以有文件黑洞。文件系统只需将 i 节点和间接指针块中的相应指针打上标记(0),表明这些指针并未指向实际的磁盘块,而无需为文件黑洞分配空字节数据块。
参考文献
[1] UNIX 系统编程手册(上) 第五章 深入探究文件I/O
[2] UNIX 系统编程手册(上) 第十四章 系统编程概念