5. 文件I/O:深入探讨
5.1 原子性和竞争条件
原子性是一个在system call里经常能碰到的一个概念,所有的system call都以原子的方式执行。原子性可以类比在微观物理的概念上,很早以前人们大概认为原子不可以再分,所以原子化的程序也是一个不可被打断,需要作为一个整体执行的程序。对于每一个system call的所有步骤都可以被视为一个整体而不可被别的进程或者线程中断。
原子性之所以重要,是因为它可以帮助我们避免很多竞争条件race conditions。之所以会有竞争条件,是因为有的时候共享同一资源的两个进程或者线程进入CPU调用的顺序不明确从而导致可能的混乱。
在下面的内容当中,本书将讨论两种包含文件I/O的竞争条件,然后再进一步讨论如何使用open()消除并保证相关文件操作的原子性。
创造互斥文件
在之前的文章中 4. 文件I/O:通用I/O模型_猴子头头123的博客-CSDN博客提到说关于O_EXCL的大概使用:
O_EXCL 这个一般和O_CREAT一起使用。当文件已经存在的时候,则文件不可以被打开,并且要返回一个错误(errno EEXIST)。换句话说,O_EXCL|O_CREAT是用来确保该process只在没有该文件的情况下创建文件。这一个过程是以atomically的方式执行(原子操作:线程或进程执行过程中不会被打断,也就意味着不会有别的线程进程在同一时间段内使用同一个resource)。5.1中还会继续展开解释。
至于说为什么这个O_EXCL非常重要,我们可以看一个下面的例子,在例子当中本书展示了在缺失O_EXCL的情况下会发生什么:
#include
#include
#include "tlpi_hdr.h"
int
main(int argc, char *argv[])
{
int fd;
if (argc < 2 || strcmp(argv[1], "--help") == 0)
usageErr("%s file\n", argv[0]);
fd = open(argv[1], O_WRONLY); /* Open 1: check if file exists */
if (fd != -1) { /* Open succeeded */
printf("[PID %ld] File \"%s\" already exists\n",
(long) getpid(), argv[1]);
close(fd);
} else {
if (errno != ENOENT) { /* Failed for unexpected reason */
errExit("open");
} else {
printf("[PID %ld] File \"%s\" doesn't exist yet\n",
(long) getpid(), argv[1]);
if (argc > 2) { /* Delay between check and create */
sleep(5); /* Suspend execution for 5 seconds */
printf("[PID %ld] Done sleeping\n", (long) getpid());
}
fd = open(argv[1], O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR);
if (fd == -1)
errExit("open");
printf("[PID %ld] Created file \"%s\" exclusively\n",
(long) getpid(), argv[1]); /* MAY NOT BE TRUE! */
}
}
exit(EXIT_SUCCESS);
} 正常来讲,如果只要一个进程,那么它会先打开上述 Open 1 位置的文件,结果发现不存在,所以之后会进入下面 open的内容部分当中,并新建一个新的文件。
fd = open(argv[1], O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR);
我们假设上述的进程为A。 当进程A执行完Open 1的任务之后,因为多进程调度的原因,这时候执行同样内容的进程B开始被执行(也许高优先级什么的),那么它会顺序执行Open1,然后在进入新建文件的过程,并且新建成功-->结束。这时候交还CPU给进程A,并且进程A也执行上述单行代码,不过因为只有O_WRONLY|O_CREAT的存在,该打开也会被成功执行,虽然并未实际生成新的文件。
那么这个时候,其实进程A会误认为自己才是那个生成新文件的进程,会输出一个进程A 生成文件xxx的内容。当然这并不是我们所期待的东西,所以这样的情况被我们称之为race condition,它会使得程序不再可靠。可以想象更奇特的例子比如打印机,如果进程A刚进入打印程序,进程B插入并占用打印机打印了内容B,这时候再回到进程A,但是进程A误以为自己已经打印了内容A,结果事实上我们只能得到一张上面写有内容B的A4纸,这大概是没有人想要得到的结果。

下面这部分代码是为了帮助实现上面竞争条件而额外加入的内容。也就是当我们在命令行给入超过两个参数的时候它就会实现5秒的休眠,这个时候可以赶快去执行另一个进程则可以实现上面的race condition。
if (argc > 2) { /* Delay between check and create */
sleep(5); /* Suspend execution for 5 seconds */
printf("[PID %ld] Done sleeping\n", (long) getpid());
}测试结果如下:
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out tfile sleep &
[1] 4330
pi@raspberrypi:~/sysprog/learn_tlpi/build $ [PID 4330] File "tfile" doesn't exist yet
./out tfile
[PID 4331] File "tfile" doesn't exist yet
[PID 4331] Created file "tfile" exclusively
pi@raspberrypi:~/sysprog/learn_tlpi/build $ [PID 4330] Done sleeping
[PID 4330] Created file "tfile" exclusively
[1]+ Done ./out tfile sleep
明显可知,这里的PID号4330即是上述A进程,PID号4331即是B进程。很明显B进程输出Created file "tfile" exclusively早于A进程,所以实际是B进程创造了tfile文件而不是A,但是A依然宣称它也创造了。
文件中添加内容
另一个需要原子性的例子是下面这种往同一个文件种写数据。
if (lseek(fd, 0, SEEK_END) == -1)
errExit("lseek");
if (write(fd, buf, len) != len)
fatal("Partial/failed write");上面这个例子当中,我们也会碰到之前生成文件类似的问题,如果进程A执行了lseek,但是被进程B抢占并也执行lseek,紧接着进程B执行write并成功,再返回A。这时候当A继续执行write,但因为fd是和进程绑定,也就意味着并不会因为B进程写入数据后fd(A)则会自动更新到B写完文件的最末端,而是还停留在他们找到的共同的fd文件的当时的末尾。这时候当A调用write的时候,则会覆盖B已经写好的内容。解决问题的办法就是使用O_APPEND打开文件,则可以保证它的原子性。
5.2 文件控制操作: fcntl()
使用语句
#include
#include
int fcntl(int fd, int cmd, ... /* arg */ );
根据man 2 fcntl的提示来说,fcntl的主要通过cmd所输入的命令来控制file descriptor。
5.3 打开文件状态flags
一个fcntl()的应用就是获得或者修改访问模式access mode以及一个打开文件的打开文件状态符 open file status flags - open() 调用时候所给的flags。为了获得这些flags,我们需要给定fnctl中cmd为F_GETFL,例如
int flags, accessMode;
flags = fcntl(fd, F_GETFL);
if (flags == -1)
errExit("fcntl");然后我们可以这样测试返回的flag是否包含我们想要的flag
if (flags & O_SYNC)
printf("writes are synchronized\n")至于访问模式,因为它不仅仅是单bit决定,而是由0,1,2决定,所以需要以以下方式决定
accessMode = flags & O_ACCMODE;
if (accessMode == O_WRONLY || accessMode == O_RDWR)
printf("files is writable\n");我们也可以用fcntl() 的F_SELFL 命令来修改一些open file status flags,可被修改的flags由O_APPEND,O_NONBLOCK,O_NOATIME,O_ASYNC以及O_DIRECT。尝试修改其他flags则会被忽略。
至于为什么要修改open file status flags或者说特别有用的例子有如下:
- 文件没有被程序的调用而被打开,它并没有对open()中所使用的flags的控制权。
- fd从系统调用获得而不是open()。比如系统调用pipe(),它会创造一个新的pipe并返回两个file descriptor
上面两点不是很懂
至于如何改变flag,我们需要先用fcntl()读取到现存flags,然后对我们需要改变的bit位进行修改,最后再将修改完的flag通过fcntl()写入。比如,我们想要启用O_APPEND flag,则
int flags;
flags = fcntl(fd, F_GETFL);
if (flags == -1)
errExit("fcntl");
flags |= O_APPEND;
if (fcntl(fd, F_SETFL, flags) == -1)
errExit("fcntl");5.4 fd和打开文件之间的关系
到目前我们所看到的例子都是fd与被打开的文件之间都是1:1的关系,但事实上并非如此,事实上是可以实现fd与被打开文件是m:1的关系,并且这些fd可以存在于同一个进程或者不同的进程。
具体我们需要来看三个数据结构:
- per-process file descriptor table 以进程为基础的fd表
- system-wide table of open file descriptions 系统范围打开文件表(为所有进程共享)
- file system i-node table 文件系统i-node表
对于每一个进程,kernel都会维持一张open file descriptor table(即表1)。这张表的每一项都记录了一个fd的信息:
- 控制该fd操作的flags的集合
- 对open file descriptor的指针
Kernel还另外维持一张系统级包含所有open file descriptions的表(包含所有打开文件),这张表有的时候也叫 open file table,它的每一项(每一行)也被称为open file handles,他们包含了这个open file的所有信息:
- 目前的file offset -- 会被read(), write()或者lseek()所改变
- status flags 状态flags,在使用open()打开的时候决定
- file mode acess文件访问模式, read only, write only, RW,由open()决定
- 信号驱动I/O相关设置 -见63.3章
- 该文件的i-node的指针
每一个文件系统都有一个i-node表包含了所有存在文件系统里的文件。 这张表将在14章进一步详细讲解。这里我们简单认为它包含了这些内容:
- 文件类型(比如普通文件,socket,FIFO...)还有许可信息
- 指向file locks列表的指针,不是很清楚什么是file locks
- 众多文件特性,包括大小,时间戳等相关信息。

根据上面的图可以清楚发现,file descriptor table:Open file table可以是m:1,open file table 对 i-node table 也是n:1。就是是说打开的文件因为状态和file offset不同,对于同一个在i-node的文件可以是以多个项目的形式连接在open file table。
进一步解释上图:
在进程A中,描述1和20都指向同一个open file描述(23),这可以是由调用dup(), dup2()或者fcntl()所导致。
在进程A中描述2和在进程B中描述2指向同一个open file table项(73),这种情况可以因为调用fork()而发生(比如进程B是进程A的子进程,反之亦然),或者一个进程传递一个描述给另一个进程使用UNIX domain socket。
最后,我们也可以看到进程A的descriptor 0和进程B的descriptor 3指向不同的open file descriptions(0, 86),但是这两个descriptions指向了同一个i-node表项(1976)也就是同一个文件。这是因为每个进程独立打开同一个文件使用open()。
因此,我们可以得出以下隐含结论:
- 两个指向同一个open file table的 fd,当其中一个改变file offset(read(), write() 或者 lseek())的时候,相对于另一个fd,它的file offset也会自动改变。
- 同上一点假设一样,open file status也是同样的道理
- 相比之下,fd flags对于不同进程和不同fd来说都是私有信息。
5.5 复制file descriptors
使用Bourne shell I/O 语句 2>&1 可以使得shell传递standard error标准错误(fd 2)到标准输出(fd 1)
因此,使用下面的命令就可以将标准输出和标准错误的内容都输出到results.log文件中
$ ./myscript > results.log 2>&1这个命令在执行的过程中会将fd2中的标准错误复制并让他指向与fd1相同指向的open file description。这样的效果可以通过dup()或者dup2()实现。
#include
int dup(int oldfd);
int dup2(int oldfd, int newfd);
dup()
dup()接受一个oldfd值,并返回一个新生成指向同一个open file description的newfd值,并且会自动赋予未使用fd值里最小的那一个。
dup2()
dup2是根据给予的newfd而生成新的所对应的fd,并指向与oldfd相同的open file description。这里newfd可以是一个已经被占据的fd值,这时候dup2会先关闭这个newfd所对应值的文件,再赋予对应的newfd新的指向。这中间可能会有错误发生,但是会被软件隐形忽略,所以就编程而言在使用dup2的时候请先主动close() newfd相对应的文件,再使用dup2()。这里的返回值是当dup2成功复制之后,返回原给的newfd的值以表示成功。
如果oldfd本身无效,那么dup2将返回错误EBADF,并且原newfd所对应文件不会被关闭。
如果oldfd = newfd并且有效,那么dup2什么都不会执行,但会返回newfd的值。
还有一种复制的办法就是使用fcntl() 与 F_DUPFD 命令
newfd = fcntl(oldfd, F_DUPFD, startfd);该调用复制oldfd,若成功则赋予从startfd开始的最小值(如果没有被占的)作为newfd返回。这种方法可以在想要使得newfd存在一定范围之内时使用。
当然之前的这些方法在使用的时候,新生成的fd会有自己的flags,并且新的FD_CLOEXEC总是被关闭的。这时候当使用dup3()的时候我们就可以显式控制新fd的close-on-exec flag了。
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include /* Obtain O_* constant definitions */
#include
int dup3(int oldfd, int newfd, int flags);
目前,dup3只支持一个flag也就是O_CLOEXEC。
5.6 在一个特殊的offset上的文件I/O:pread()和pwrite()
pread() 和 pwrite()的执行类似于 read()和write(),只是多一个参数 offset。
#include
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
这种方法等价于原子性地执行以下程序
off_t orig;
orig = lseek(fd, 0, SEEK_CUR); /* Save current offset */
lseek(fd, offset, SEEK_SET);
s = read(fd, buf, len);
lseek(fd, orig, SEEK_SET); /* Restore original file offset */这种方法特别适用于多线程应用,具体的可以看第29章。利用这种方法我们可以在不相互影响别的线程的情况下可以读出来我们想要的数据。但如果使用lseek + read/write的组合的话,那么就会因为中断等等因素而导致出现race condition。另外相比于使用组合方式,一般来说pread()和pwrite()因为更好的优化而拥有更好的性能。
5.7 分散聚集Scatter-Gather I/O: readv(), writev()
#include
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
如之前一样,先上prototype。
该语句与之前read(), write或者说pread(), pwrite()的区别是,它可以一次接受多个buffer的内容读写。pread()的第二个参数是*buf,也就是单一buf的起始地址。
在readv(),writev()当中,buffer的集合被定义在const struct iovec *iov 当中(每一个iov都是一个独立的buffer,传入的参数应该是一个array)。int iovcnt 参数则代表了iov这个array元素的数量。
每一个iov元素的定义均如下:
struct iovec {
void *iov_base; /* start address of buffer */
size_t iov_len; /* number of bytes to transfer to/from buffer */
};以图来表示*iov, iovcn-> iov_base, iov_len ->实际存储位置,可以或者一个更明晰的理解:
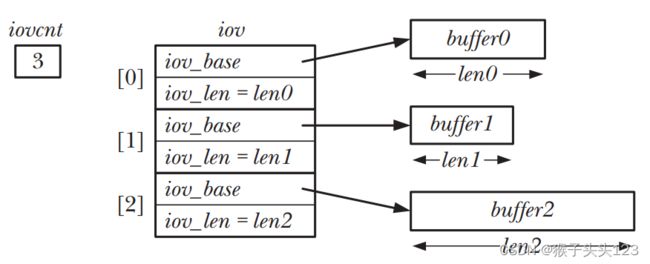
分散输入scatter input
readv()会实现一个分散输入,也就是顺序连续从fd所指向文件当中读出bytes并且分散读入到iov所对应的buffer当中。在读入过程中从iov[0]开始写,等写满之后再转向下一个buffer填入。
readv()的一个很重要的特征就是它具有原子性,这样子即使其他进程或者线程拥有同一个open file description访问权(因考虑到offset),也不会对readv()的使用造成影响,因为在此期间,别的线程或进程并不可以修改该offset。
当成功访问结束之后,readv()会返回所读到数据的bytes,或者如果文件中只有EOF,则会返回0。当然之后使用者需要比较所读到的数据总量和所要求读到的是否一致,因为如果文件中只有少于所需求量的数据存在,那么只有部分buffer会被填充,并且他们中的最后一个被填充的有很大概率只有部分被填充。
这里,书中提供了一个新的测试文件fileio/t_readv.c (from "The Linux Programming Interface")
#include
#include
#include
#include "tlpi_hdr.h"
int
main(int argc, char *argv[])
{
int fd;
struct iovec iov[3];
struct stat myStruct; /* First buffer */
int x; /* Second buffer */
#define STR_SIZE 100
char str[STR_SIZE]; /* Third buffer */
ssize_t numRead, totRequired;
if (argc != 2 || strcmp(argv[1], "--help") == 0)
usageErr("%s file\n", argv[0]);
fd = open(argv[1], O_RDONLY);
if (fd == -1)
errExit("open");
totRequired = 0;
iov[0].iov_base = &myStruct;
iov[0].iov_len = sizeof(struct stat);
totRequired += iov[0].iov_len;
iov[1].iov_base = &x;
iov[1].iov_len = sizeof(x);
totRequired += iov[1].iov_len;
iov[2].iov_base = str;
iov[2].iov_len = STR_SIZE;
totRequired += iov[2].iov_len;
numRead = readv(fd, iov, 3);
if (numRead == -1)
errExit("readv");
if (numRead < totRequired)
printf("Read fewer bytes than requested\n");
printf("total bytes requested: %ld; bytes read: %ld\n",
(long) totRequired, (long) numRead);
exit(EXIT_SUCCESS);
} 这里iov[0]将自己和myStruct类型绑定,这个是来自于sys/stat.h的类型,比较大。iov[1]指向x,一个int长度,iov[2]是一个指向100个char长度的array的变量。
实验结果:filea.txt中存储了17个byte的内容也就是abcdef1234567890,最终可以看到需要读192个bytes,但只读到了17个,因为只有17个存在。
pi@raspberrypi:~/sysprog/learn_tlpi/build $ cat filea.txt
abcedf1234567890
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out filea.txt
Read fewer bytes than requested
total bytes requested: 192; bytes read: 17
聚合输出Gather Output
writev()会进行gather output聚合输出。它会将所有iov buffer里面的内容连接起来,并且把它们以连续顺序的方式写入fd所指向的文件当中。这些内容也是以从iov[0]开始聚合。因为它的原子性,我们可以保证从调用它开始,我们可以将内容以连续顺序而不被别的进程/线程中断的方式写入常规文件当中。
当然writev()也会只写入部分内容,这时候我们要比较返回值是否是我们想要写入的内容量。
至于readv()和writev()的优点自然是他们的方便与速度,比如我们可以将writev()替换成如下:
- 分配一个大buffer,然后将所有数据写入这个大buffer当中,再调用write()输出该buffer到文件中
这种方法不方便,而且需要临时存储额外大量数据到用户空间当中 - 或者可以直接连续多次调用write()以达到多次写所有iov buffer到文件的目的
这种方法首先不安全,因为多次调用write()不具备原子性,而且多次调用非常浪费性能。
在特殊offset上使用scatter-gather I/O
从linux 2.6.30开始开始有两种额外的方法可以结合scatter-gather I/O以及想要在的offset位置,也就是preadv()和pwritev()。
#include
ssize_t preadv(int fd, const struct iovec *iov, int iovcnt, off_t offset);
ssize_t pwritev(int fd, const struct iovec *iov, int iovcnt, off_t offset);
他们本身执行着和readv()以及writev()同样的任务,除过他们可以在文件任意offset上操作之外。这样的操作对于多线程应用来说类似于pread()和pwrite()非常具有优势和实用性,因为他们与目前文件中所指向内容位置没有关系。
5.8 裁剪文件:truncate()和ftruncate()
#include
#include
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length);
如果文件长于length,则超出的数据则会丢失。如果一个文件短于length,则文件则会被以一堆0或者文件洞填充(padding)。
这两个函数的区别在于针对的文件进入方法不同。第一种truncate(),针对于可访问并且可写的文件,并且文件名是以文件地址+名字直接决定或者*path 也可以是一个可被解构的symbolic link。ftruncate()使用已打开的可写的文件的fd,他不会改变任何文件的offset。
对于ftruncate()而言,如果它的length超过文件本身的长度,SUSv3允许ftruncate()在这种情况下出现两种情况:要么文件被扩展到length长度,要么返回错误。但一般来说符合XSI系统的会采取扩展方式,一般SUSv3要求truncate() (注意不是ftruncate())进行扩展。
注意:truncate()是唯一一个系统调用在不用open()打开文件的情况下而可以直接改变文件内容的function。
5.9 非阻碍I/O Nonblocking I/O
当打开文件时使用O_NONBLOCK有两种目的:
- 如果文件不能被直接打开的话,open()返回一个错误并且不产生阻碍。关于阻碍有一个例子就是FIFO()。
- 在成功打开open()之后,接下来的I/O也会以非阻碍态运行。如果一个I/O并不能立刻完成的话,那么要么部分数据被传或者系统调用产生错误EAGAIN或者EWOULDBLOCK。具体哪一个错误会被返回取决于系统调用本身。在LINUX或者多数UNIX系统里面,这两种错误会被当成一种对待。
非阻碍模式用于设备(比如terminals或者pseudoterminals), pipes, FIFOs还有sockets。其中pipes还有sockets的open()不会获得fd,所以我们只能通过fcntl()的F_SETFL操作使能O_NONBLOCK。
对于一般普通文件来说,O_NONBLOCK一般会被普通文件所忽略,因为kernel buffer cache会确保普通文件I/O操作不会被阻碍,具体见13.1。然而,当强制文件上锁使用的时候,O_NONBLOCK则会相应发生作用(见55.4)。
关于更多非阻碍I/O的内容见44.9和第63章。
5.10 大文件的I/O
off_t 作为文件中offset类型一般是signed long integer类型,对于32bit架构处理起来说它会被限制在2GB(  )。然而作为现代系统,一个磁盘容量当然是远远大于该限制,因此需要有一个机制可以处理大型文件。当然64进制
)。然而作为现代系统,一个磁盘容量当然是远远大于该限制,因此需要有一个机制可以处理大型文件。当然64进制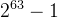 对应的long类型的容量是远远大于磁盘大小,所以在64位系统上不存在大文件的问题。
对应的long类型的容量是远远大于磁盘大小,所以在64位系统上不存在大文件的问题。
为了实现大文件应用,我们可以使用以下两种方法:
- 使用另外的API来支持大文件。但是这样的方法已经被放弃
- 定义一个新的宏_FILE_OFFSE_BITS来编译程序。这种方法更受欢迎,因为它允许程序在不改变源代码的情况下兼容大文件功能。
原书中对第一种方法给出了一个源代码,但是因为书上也说他已经被淘汰了,所以我就不在这里粘贴复制了。
_FILE_OFFSET_BITS宏
最推荐获得大文件功能的方法就是使用这个宏定义。其中一个使用方法就是之前所述的那种在编译过程当中临时定义一个宏:
$ cc -D_FILE_OFFSET_BITS=64 prog.c当然也可以在文件当中直接用#define _FILE_OFFSET_BITS 64定义,但是对于一个使用makefile编译的系统来说上面的编译时定义的宏可能会更合适一些。
宏方法可以使得所有的32bit功能和数据类型直接转换成他们的64bit内容。因此在调用open()的时候事实上它转换成调用open64()和off64_t,只是这些转换都是在不改变源程序的前提之下实现的,所以只要一次重编译即可实现。
传递off_t值给printf()
LFS扩展的一个问题就是它并不能传递off_t的值给printf()调用。在普通情况下,当printf输出pid_t, uid_t的时候,他们对应的类型是long,所以我们使用%ld作为解析符。但是如果我们使用LFS扩展,那么%ld就不够使用了,因为off_t里的数的大小很有可能会大于long,这个时候为了还能够正常输出,则需要cast它的数据类型到long long上,并且使用 %lld输出:
#define _FILE_OFFSET_BITS 64
off_t offset; /* Will be 64 bits, the size of 'long long' */
/* Other code assigning a value to 'offset' */
printf("offset=%lld\n", (long long) offset);5.11 /dev/fd文件夹
对于每一进程,kernel都提供一个特殊的虚拟文件夹/dev/fd。这个文件夹包含了/dev/fd/n形式的文件名,其中n代表了该进程当中的一个打开的file descriptor。因此,比如说/dev/fd/0代表了进程的标准输入。
打开一个在/dev/fd文件夹种的文件相当于复制了一个相应的fd。相应于语句:
fd = open("/dev/fd/1", O_WRONLY);
fd = dup(1); /* Duplicate standard output */这种情况下它会拥有和原始descriptor相同的访问模式。
事实上,/dev/fd实际上是一个到/proc/self/fd文件夹的symbolic link,或者/proc/PID/fd。
位于/dev/fd的文件实际上也很少被用于程序中。它们最多被使用的地方是shell里。很多用户级命令采用文件名参数,并且有的时候我们会把他们放在pipeline,标准输入输出当中。为了这种目的,一些程序比如diff,ed,tar还有comm进化出使用单一 - 来使用标准输入或者输出该文件名参数。因此,比较一个从ls来的文件列表和之前建的列表我们可能会使用以下方式:
$ ls | diff - oldfilelist
这种方式有诸多问题。首先,他要求特别的对-符号的解释,但很多程序并不会去解释这个-符号。第二点,很多程序会使用-做别的目的。
这时候使用/dev/fd就可以消除这些问题并允许标注输入,输出以及错误作为一个文件名参数来使用他们。因此我们可以这样写shell command
$ ls | diff /dev/fd/0 oldfilelist
或者用一种更容易理解的写法使用 /dev/stdin,/dev/stdout还有/dev/stderr来代替/dev/fd/0, dev/fd/1,dev/fd/2。
5.12 临时文件
一些程序在运行过程中需要创造临时文件,在程序截至是则需要被删掉。比如说,很多编译器在编译过程中生成临时文件。GNU C库就提供了大量库函数为此目的。这里,我们描述其中的两个函数:mkstemp()和tmpfile()。
mkstemp()产生一个由调用者提供的临时并且唯一的变量名并打开该临时文件,同时返回一个fd可以用来I/O系统操作。用法如下:
#include
int mkstemp(char *template); template变量名就是路径名,其中在输入的时候给定最后的6个字符是xxxxxx,他们是使得文件名变唯一的字符位。最后template被修改成该形式并返回。mkstemp()所产生的文件对文件的拥有者来说具有读写的权力,并且它打开的时候也使用了O_EXCL,则可以保证调用者是唯一一个进入该文件的(文章开始所提到的原子性的内容)。典型来说,一个临时文件在打开之后很快会使用unlink()被unlinked(deleted)掉。因此我们可以这样使用mkstemp():
int fd;
char template[] = "/tmp/somestringXXXXXX";
fd = mkstemp(template);
if (fd == -1)
errExit("mkstemp");
printf("Generated filename was: %s\n", template);
unlink(template); /* Name disappears immediately, but the file
is removed only after close() */
/* Use file I/O system calls - read(), write(), and so on */
if (close(fd) == -1)
errExit("close");tmpfile()可以创造一个唯一名的临时文件,它可以用来读写,并且同时拥有O_EXCL。
用法:
#include
FILE *tmpfile(void); 如果调用成功的话,tmpfile()返回一个可以被stdio库使用的文件流。在临时文件被关闭的时候则会被自动删除。因此可以想见tmpfile()内部调用了unlink()在打开文件之后立刻移除该文件。