OneRel: Joint Entity and Relation Extraction with One Module in One Step
目录
Abstract
Introduction
Related Work
Multi Module Multi Step(可以被理解成pipline方法)
Multi Module One Step(可以理解成联合抽取方法)
Task Definition
Method(Scoring-based Classifier)
Abstract
为了解决以往联合方法的导致的级联错误和信息冗余。本文提出了一种新的模型OneRel,将联合抽取转换为一个细粒度的三分类(即关系抽取的主体,关系类型,客体)问题。具体来说,我们的模型包括一个基于评分的分类器和一个针对特定关系的角标记策略。前者评估一个标记对和一个关系是否属于一个事实三元组。后者保证了一个简单而有效的解码过程。
Introduction
由于Pipline的方法忽略了实体抽取和关系抽取之间的交互,可能会导致出现错误传播问题。为了更好地开展复杂任务,我们通常将联合抽取分为多模块多步骤和多模块一步完成两种方法,具体详见下图1.
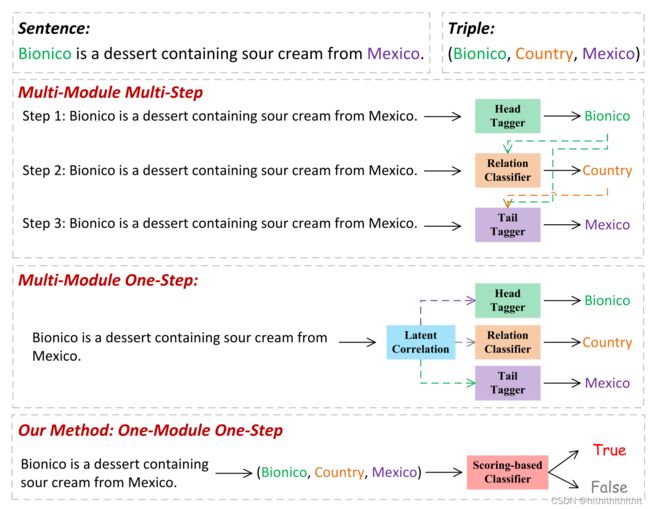
图1 图中虚线表示依赖
由上图可知,在多模块多步骤方法中,由于是分成三步去获取实体和关系,预测前期的实体如果产生错误会导致之后地预测错误。多模块一步骤方法分离地识别实体和关系,并且通过他们之间地隐藏关系将他们结合成一个三元组。但是,由于单独识别过程中实体和关系之间缺乏相互约束,这种方法容易产生冗余信息,导致装配三元组时出现错误。所以我们在这个方法中直接识别三元组地正确性。这样做地好出有三个,一是将头部实体,关系实体和尾部实体同时输入到一个分类模块中可以充分捕捉三个元素之间地依赖关系,从而减少冗余信息。第二,只使用一步分类,可以有效避免级联错误。第三,一模块一步的简单架构,使网络直观,易于训练。
Related Work
Multi Module Multi Step(可以被理解成pipline方法)
1. 识别句子中全部的实体,然后对每个实体对进行关系分类;
2. 先识别句子中的关系,不保留重复的关系;然后预测头部实体和尾部实体;
3. 首先识别句子中所有的头部实体,然后通过序列标注或者问答去推断相应的关系类型和尾部实体
缺点:会造成级联错误传播。
Multi Module One Step(可以理解成联合抽取方法)
1. 将实体和关系视作一个填表任务;
2. 将联合抽取任务视作一个集合预测问题,避免了考虑多个三元组的预测顺序问题;
缺点:但由于在单独的识别过程中,实体和关系之间没有足够的相互约束,这种多模块一步法不能完全捕获被预测实体和关系之间的依赖关系,导致在三元组构造过程中存在信息冗余。
Task Definition
对于给出的句子![]() 和预先定义的关系类型
和预先定义的关系类型![]() ,从句子中找出所有可能的三元组
,从句子中找出所有可能的三元组![]() ,其中N表示的是三元组的数量,然后我们用
,其中N表示的是三元组的数量,然后我们用![]() 来表示第q到第p个单词。
来表示第q到第p个单词。
下面通过这个图来详细解释这个方法。
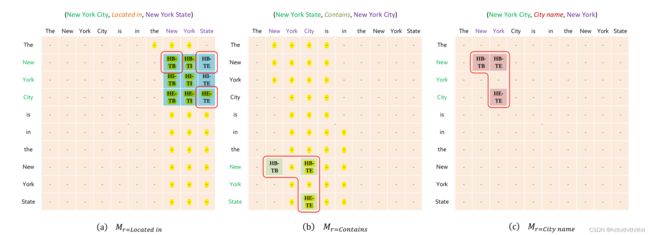 图2 Examples of the Rel-Spec Horns Tagging
图2 Examples of the Rel-Spec Horns Tagging
由上图,每种实体关系类型对应着一个矩阵,图中一共有3个二维矩阵,也就是我们得到的是一个3维矩阵。我们使用BIE标签去标记单词在实体中的位置,其中H表示的头部实体,T表示的是尾部实体。HB表示的是头部实体的第一个单词,HE表示的是头部单词的最后一个单词,以此类推下去。其中矩阵a表示的是"New York City"和"New York State"之间的关系为"Located in"。对比矩阵b,c,我们只用了HB-TB,HB-TE,HE-TE三个标签来表示实体之间的对应。这样做的好处是仅使用3个标记可以在分类时有效的缩小搜索空间,且有足够的负样本,在解码的时候也会简单有效.
Method(Scoring-based Classifier)
1. ![]() ,
, 表示的时对应的token嵌入和位置嵌入之和。
表示的时对应的token嵌入和位置嵌入之和。
2. 枚举所有可能的三元组![]() ,然后设计一个分类器去指定一个高信度标签,其中r_{k}表示的时随机初始化的关系类型。然后把三元组作为简单分类网络的输入。这样做可能有两个缺点,一个是简单网络无法学习到较多的信息,一个是这样做的时间复杂度很高,因为一个句子要有L*L*K次输入。
,然后设计一个分类器去指定一个高信度标签,其中r_{k}表示的时随机初始化的关系类型。然后把三元组作为简单分类网络的输入。这样做可能有两个缺点,一个是简单网络无法学习到较多的信息,一个是这样做的时间复杂度很高,因为一个句子要有L*L*K次输入。
3.我们从知识图谱嵌入技术中受启发,创建了如下的分数函数![]() ,其中
,其中![]() 。
。
![]() ,其中;表示concatenate,使用了ReLU激活函数。
,其中;表示concatenate,使用了ReLU激活函数。
4.最终的分数函数:
![]()
其中,![]() 同时计算token对
同时计算token对![]() 对应的
对应的![]() 的显著性(salience),
的显著性(salience), 表示分数向量
表示分数向量
5.将![]() 喂入softmax去预测相应的标签
喂入softmax去预测相应的标签
![]()
6.损失函数
![]()
其中![]() 表示黄金标签。
表示黄金标签。