论文阅读——Bridge the Gap Between CV and NLP! A Gradient-based Textual Adversarial Attack Framework
Bridge the Gap Between CV and NLP! A Gradient-based Textual Adversarial Attack Framework
作者:Lifan Yuan, Yichi Zhang, Yangyi Chen, WeiWei
类别:黑盒 基于决策的对抗攻击
摘要
尽管基于优化的对抗攻击在计算机视觉领域是有效的,但是不能直接用于自然语言处理领域的离散文本。为解决这一问题,作者提出了一种统一的框架,将CV领域基于优化的对抗攻击方法扩展到自然语言处理领域来生成对抗样本。在该框架中,连续优化的扰动被添加到嵌入层并在前向传播过程中被放大,然后潜在空间上到的扰动被使用masked language model解码来获得潜在的对抗样本。
解决的问题:
- CV领域基于优化的对抗攻击不适用文本攻击;
- 基于决策的文本攻击少有研究。
引言
尽管深度神经网络在现实世界已经取得了巨大成功,但其对对抗样本仍是脆弱的。对抗样本是在原始输入上添加微小且人不易感知的扰动的来生成对抗样本,并且改变受害者模型的输出结果。在计算机视觉领域,大量的对抗攻击方法已经被提出用于评估深度神经网络的鲁棒性并且对应的防御方法也被广泛关注。针对图像的对抗性攻击被定义为在特定样本上使用梯度上升算法最大化模型损失函数来生成对抗样本。但是由于文本空间的离散和不可微性导致针对文本的对抗攻击更具有挑战性。这也导致无论在白盒还是黑盒状态下,基于优化的方法都不适用于文本的对抗攻击。为解决这一问题,多名研究者探索启发式方法开生成离散扰动。例如,利用语料库知识或语境化信息操纵文本中最重要的词和一阶近似的梯度法在词汇表中寻找最优候选词进行替换。
作者将基于优化的方法应用于自然语言处理领域。具体而言:运用梯度在token embeddings上生成对抗样本,进而转换对抗样本的搜索问题到连续可微的嵌入空间。
研究现状(文本对抗)
根据攻击对象模型的可及性,现有的文本攻击可以大致分为白盒攻击和黑盒攻击。白盒攻击方法,也称为基于梯度的攻击方法,假设攻击者完全了解受害者模型,包括模型结构和所有参数。在现实世界中,白盒攻击的应用场景很少,因此大多数白盒攻击模型被探索以揭示受害者模型的弱点,包括通用对抗性触发器和快速梯度符号启发方法。黑盒攻击模型可以进一步分为基于得分和基于决策两种不同的攻击设置。**前者假设攻击者可以从受害者模型中获得决策和相应的置信度分数。**大多数关于黑盒攻击的研究工作都集中在这个设置上,探索不同的词替换方法和搜索算法来降低受害者模型的置信度得分。后者攻击假设攻击者只能从受害者模型中获得决策,这更具挑战性。
方案
两个模型:
局部代理模型:利用梯度信息优化生成对抗样本
真实的受害者模型(victim model):攻击者试图欺骗的模型
整体概述:
- 在攻击者本地数据集上微调的proxy BERT model编码每个离散文本实例为连续的token
embeddings****并对其添加连续的对抗性扰动; - 根据受害者模型的预测输出,使用proxy model的梯度迭代优化对抗扰动;
- 扰动完成,使用MLM的head解码扰动后的潜在表示来生成候选对抗样本。
详细描述:
定义 x x x为输入文本, y y y表示对应的标签, e e e表示 x x x的embedding, h h h表示hidden state, y ^ \hat y y^表示最终的预测,f表示神经网络,由 f 0 f_0 f0, f 1 f_1 f1, f 2 f_2 f2三个部分组成,即
f ( x ) = f 2 ( f 1 ( f 0 ( x ) ) ) f(x) = {f_2}({f_1}({f_0}(x))) f(x)=f2(f1(f0(x)))
f 0 f_0 f0表示embedding layer, f 1 f_1 f1表示从第1层到第m层的隐藏层, f 2 f_2 f2定义神经网络的剩余部分。因此,前向传播过程可以描述为,
e = f 0 ( x ) , h = f 1 ( e ) , y ^ = f 2 ( h ) e = {f_0}(x),h = {f_1}(e),\hat y = {f_2}(h) e=f0(x),h=f1(e),y^=f2(h)
latent-space perturbation
对于每个文本输入,首先计算前向传播过程任务的特定损失,然后执行后向传播获得关于输入文本token embedding损失的梯度。生成的梯度视为添加到token embedding用于更新扰动的信息,可以在下面优化求解:
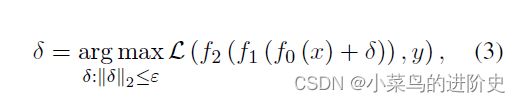
δ \delta δ表示扰动, L \mathcal{L} L表示损失函数。现有方法大多线性化损失来近似扰动 δ \delta δ,但这类方法这些一次性的方法可能导致较大的步长扰动,违反了局部线性化的假设。为解决这一问题,作者在每个步长使用微小的变化调整添加到token embedding上的连续扰动,然后使用扰动迭代更新输入实例的token embedding知道生成成功的对抗样本。
重构
MLM-head是一个预训练的 H × V H \times V H×V的线性层, H H H表示隐藏状态的size, V V V表示vocabulary的size。给定连续的hiddern states h h h,可以使用 t = h A T + b t = h{A^T} + b t=hAT+b预测token IDs, A A A和 b b b都是调优参数。IDs可以使用预定义ID-token mapping的tokenizer解码为text。对抗样本的重构过程如下:

one-off attack model 倾向于选择token b b b代替token a a a,一次查找就会跨越解码边界。作者提出的方法,
- 通过迭代搜索,将扰动累积到越过决策边界,到达过渡点 t 3 t_3 t3,将其解码为最优解 c c c。然后将 a a a替换为 c c c,得到对抗样本,以查询受害者模型的决策;
- 如果这个对抗性样本未能欺骗受害者模型,我们从当前的扰动令牌嵌入开始下一个搜索迭代,即上图中的 t 3 t_3 t3,而不是从解码令牌 c c c的嵌入开始。通过利用虚拟嵌入作为过渡点,该迭代攻击框架可以保留累积的梯度信息并避免破坏局部线性化假设。

上述过程的伪代码如下:![在这里插入图片描述](https://img-blog.csdnimg.cn/432b0cee720d4701b19bb1a93e8fba8b.png
实验
模型:SST-2、MNLI、AG’s News
数据集:World、 Sports、 Business、 Science/Technology
基准方法:BERT、RoBERTa、ALBERT、ALBERT
评估指标:语义一致性、语法、频率、攻击成功率