基础15:npm、yarn、pnpm
npm2
用 node 版本管理工具把 node 版本降到 4,那 npm 版本就是 2.x 了。
执行 npm init, npm install express,可以看到node_modules目录如下:

可以看到,npm2的node_modules是嵌套的。
这种方式的优点就是模块依赖关系清晰。
缺点也比较明显:
- 依赖层级太深,会导致文件路径过长的问题,尤其在 window 系统下,最多260多个字符。
- 大量重复的包被安装,文件体积超级大。比如跟 foo 同级目录下有一个baz,两者都依赖于同一个版本的lodash,那么 lodash 会分别在两者的 node_modules 中被安装,也就是重复安装。
- 模块实例不能共享。比如 React 有一些内部变量,在两个不同包引入的 React 不是同一个模块实例,因此无法共享内部变量,导致一些不可预知的 bug。
当时npm还没解决这些问题,社区就出来一个新的解决方案了,那就是 yarn。
yarn
yarn生成的node_modules目录如下:

将所有内部依赖平铺到最外面一层,解决了上述嵌套方案的缺陷。
后面npm3 + 也采用类次方案实现了。
所有的依赖都被拍平到node_modules目录下,不再有很深层次的嵌套关系。这样在安装新的包时,根据 node require 机制,会不停往上级的node_modules当中去找,如果找到相同版本的包就不会重新安装,解决了大量包重复安装的问题,而且依赖层级也不会太深。
之前的问题是解决了,但仔细想想这种扁平化的处理方式,它真的就是无懈可击吗?并不是。它照样存在诸多问题:
- 依赖结构的不确定性。
- 扁平化算法本身的复杂性很高,耗时较长。
- 项目中仍然可以非法访问没有声明过依赖的包。
怎么理解第一条中的不确定性呢?
假如现在项目依赖两个包 foo 和 bar,这两个包的依赖又是这样的:
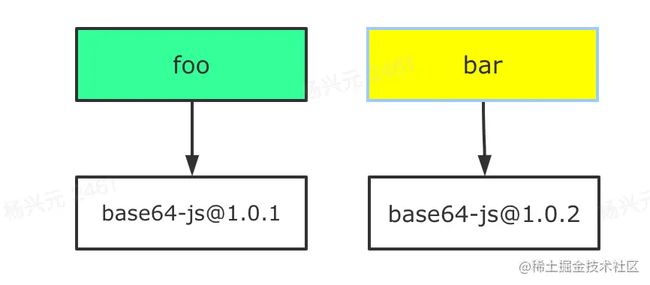
那么 npm/yarn install 的时候,通过扁平化处理之后,究竟是这样

还是这样的?
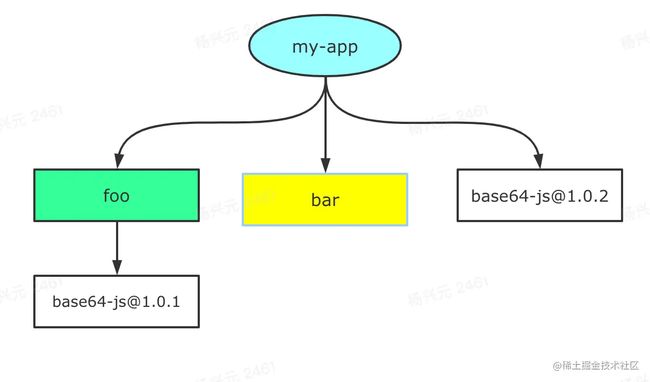
答案是: 都有可能。取决于 foo 和 bar 在 package.json中的位置,如果 foo 声明在前面,那么就是前面的结构,否则是后面的结构。
这就是为什么会产生依赖结构的不确定问题,也是 lock 文件诞生的原因,无论是package-lock.json(npm 5.x才出现)还是yarn.lock,都是为了保证 install 之后都产生确定的node_modules结构。
Phantom dependencies幽灵依赖
Phantom dependencies 被称之为幽灵依赖或幻影依赖,解释起来很简单,即某个包没有在package.json 被依赖,但是用户却能够引用到这个包。
比如yarn打包:
A依赖B, B依赖C,,那么 A 就算没有声明 C 的依赖,由于有依赖提升的存在,C 被装到了 A 的node_modules里面,在A里面引入C,没什么问题的。
但是,
第一, B 的版本是可能随时变化的,假如之前依赖的是[email protected],现在发了新版,新版本的 B 依赖 [email protected],那么在项目 A 当中 npm/yarn install 之后,装上的是 2.0.1 版本的 C,而 A 当中用的还是 C 当中旧版的 API,可能就直接报错了。
第二,如果 B 更新之后,可能不需要 C 了,那么安装依赖的时候,C 都不会装到node_modules里面,A 当中引用 C 的代码直接报错。
还有一种情况,在 monorepo 项目中,如果 A 依赖 X,B 依赖 X,还有一个 C,它不依赖 X,但它代码里面用到了 X。由于依赖提升的存在,npm/yarn 会把 X 放到根目录的 node_modules 中,这样 C 在本地是能够跑起来的,因为根据 node 的包加载机制,它能够加载到 monorepo 项目根目录下的 node_modules 中的 X。但试想一下,一旦 C 单独发包出去,用户单独安装 C,那么就找不到 X 了,执行到引用 X 的代码时就直接报错了。
npm 也有想过去解决这个问题,指定**–global-style**参数即可禁止变量提升,但这样做相当于回到了当年嵌套依赖的时代,一夜回到解放前,前面提到的嵌套依赖的缺点仍然暴露无遗。
pnpm
回想下,npm3+和yarn为什么要做node_modules 扁平划处理,不就是因为同样的依赖会复制多次,并且路径过长在 windows 下有问题么?
那如果不复制文件,比如通过link。
打开node_modules如下:
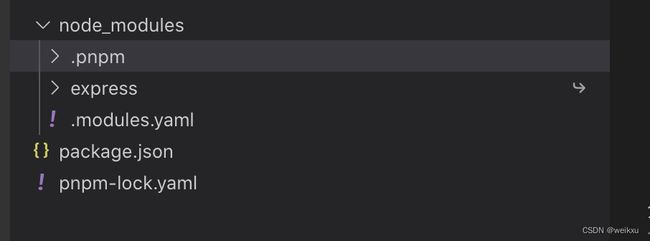
可以看到,该目录结构比较清晰,只有一个我们直接依赖的包express,并没有把express需要引用的包平铺开,并且也不在express包下面嵌套。
同时还有个 .pnpm 目录,目录结构如下:
.pnpm
├── lock.yaml
├── node_modules
│ ├── .bin
│ ├── accepts
│ ├── array-flatten
│ ├── body-parser
│ ├── bytes
│ ├── call-bind
│
│
├── [email protected]
│ └── node_modules
├── [email protected]
│ └── node_modules
├── [email protected]
│ └── node_modules
├── [email protected]
│ └── node_modules
├── [email protected]
│ └── node_modules
.pnpm 以平铺的形式储存着所有的包,正常的包都可以在这种命名模式的文件夹中被找到:
.pnpm/+@/node_modules/
// 组织名(若无会省略)+包名@版本号/node_modules/名称(项目名称)
我们称.pnmp为虚拟存储目录,该目录通过
那么它如何跟文件资源进行关联的呢?又如何被项目中使用呢?
答案是Store + Links!
Store
pnpm 资源在磁盘上的存储位置。
由于每个磁盘有自己的存储方式,所以Store会根据磁盘来划分。 如果磁盘上存在主目录,存储则会被创建在 /.pnpm-store;如果磁盘上没有主目录,那么将在文件系统的根目录中创建该存储。 例如,如果安装发生在挂载在 /mnt 的文件系统上,那么存储将在 /mnt/.pnpm-store 处创建。 Windows系统上也是如此。
可以在不同的磁盘上设置同一个存储,但在这种情况下,pnpm 将 复制包 而不是 硬链接 它们,因为硬链接只能发生在同一文件系统同一分区上。
如果是 npm 或 yarn,那么这个依赖在多个项目中使用,在每次安装的时候都会被重新下载一次。
如果某个依赖在 sotre 目录中存在了话,那么就会直接从 store 目录里面去 hard-link,避免了二次安装带来的时间消耗,如果依赖在 store 目录里面不存在的话,就会去下载一次。
Links(hard link & symbolic link)
pnpm 是怎么做到如此大的性能提升的呢?一部分原因是使用了计算机当中的 Hard link ,它减少了文件下载的数量,从而提升了下载和响应速度。
hard link
通过hard link, 用户可以通过不同的路径引用方式去找到某个文件,需要注意的是一般用户权限下只能硬链接到文件,不能用于目录。
pnpm 会在Store(上面的Store) 目录里存储项目 node_modules 文件的 hard links ,通过访问这些link直接访问文件资源。
举个例子,例如项目里面有个 2MB 的依赖 react,在 pnpm 中,看上去这个 react依赖同时占用了 2MB 的 node_modules 目录以及全局 store 目录 2MB 的空间(加起来是 4MB),但因为 hard link 的机制使得两个目录下相同的 2MB 空间能从两个不同位置进行 CAS寻址 直接引用到文件,因此实际上这个react依赖只用占用2MB 的空间,而不是4MB。
如何判断是否是hard link?
- mac和linux中,hard link的文件和普通文件无异,node甚至无法区分hard link文件;
- 可以通过
ls -i列出文件信息,第一个参数就是文件的inode值,其中,具有相同inode节点的多个文件互为hard link文件;- 这样 就可以通过不同项目观察同一个依赖文件是不是一样的 inode 就能确定是不是同为 hard link了。
symbolic link
由于hark link只能用于文件不能用于目录,但是pnpm的node_modules是树形目录结构,那么如何链接到文件? 通过symbolic link(也可称之为软链或者符号链接)来实现!
pnpm在全局通过Store来存储所有的node_modules依赖,并且在.pnpm/node_modules中存储项目的hard links,通过hard link来链接真实的文件资源,项目中则通过symbolic link链接到.pnpm/node_modules目录中,依赖放置在同一级别避免了循环的软链。
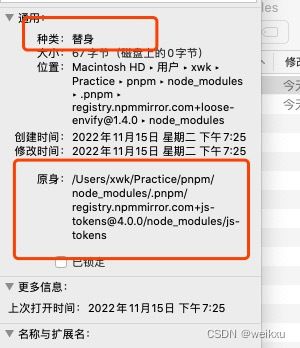
如何判断是否是symbolic link?
打开文件夹,显示简介,mac会有展示,如下图:
pnpm中是如何结合hard link和symbolic link的
官方给了一张原理图,
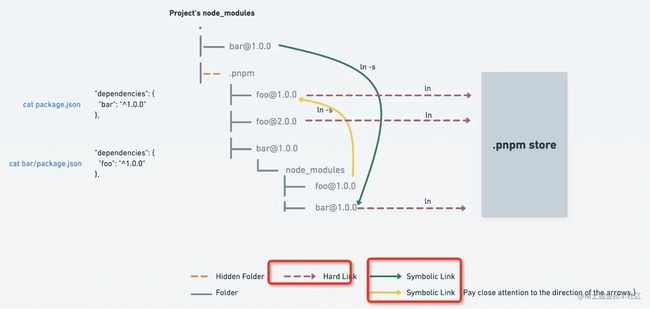
从上图可以看出,项目直接依赖 bar, bar又依赖 foo包。
pnpm下载依赖时,首先在node_modules下创建一个[email protected]的symbolic link,链向图示位置,然后在.pnpm中平铺所有依赖,观察[email protected]/node_modules/,里面的bar文件hard link真实文件,foo又是symbolic link到上层[email protected],这样bar就能够根据路径找到foo了。
pnpm prune
根据计数引用原理删除不需要的依赖包
npx 、 nvm
npx
首先 npx 是一个工具,旨在帮助完善使用npm注册表中的软件包的体验-npm使得超级容易安装和管理注册表中托管的依赖项,npx使得使用CLI工具和托管在该注册表中的其他可执行文件变得容易 注册表。 到目前为止,它大大简化了许多需要使用纯npm进行一些程序化的事情:
-
直接调用项目安装的模块
npm install -D mocha // 项目中安装mocha测试模块 // 一般来说,调用 Mocha ,只能在项目脚本和 package.json 的scripts字段里面, // 如果想在命令行下调用,必须像下面这样。 // 项目的根目录下执行 node-modules/.bin/mocha --version // 如果使用npx npx mocha --version // npx运行的时候,会到node_modules/.bin路径和环境变量$PATH里面,检查命令是否存在。 -
控制调用本地/远程模块
- 强制使用本地模块,不下载远程模块
npx --no-install http-server - 忽略本地同名模块,强制安装并使用远程模块
npx --ignore-existing create-react-app my-react-app
- 强制使用本地模块,不下载远程模块
-
执行一次性命令,避免全局安装
$ npx create-react-app my-app 安装一个临时的 create-react-app 并且调用它,不会污染全局安装
场景:
比如尝试一个cli工具,可能这辈子只能用到这一次,不想这次使用完后还一直存在电脑硬盘里占用内存。
步骤:- 当不在$PATH中时调用npx将自动从npm注册表安装一个具有该名称的包,并调用它。
- npx 将create-react-app下载到一个临时目录,使用以后再删除。
- 完成后,安装的软件包将会删除,而不会出现在globals中,不必担心全局污染。
-
使用不同版本的Node(同样适用于其他库的指定版本)
npx -p node@ node -v 可以用于一次性运行node版本
-
执行Github源码
# 执行 Gist 代码 $ npx https://gist.github.com/zkat/4bc19503fe9e9309e2bfaa2c58074d32 # 执行仓库代码 $ npx github:piuccio/cowsay hello
nvm
这是一个切换node版本的一个工具。和 n 命令类似。
- n 是一个需要全局安装的 npm package。所以在使用n时,必须得有一个版本的node环境。
- 在安装的时候,n 会先将指定版本的 node 存储下来,然后将其复制到/usr/local/bin。
- nvm 是一个独立软件包,需要单独使用它的安装逻辑。
- 在使用 nvm 安装 node 的时候,nvm 将不同的 node 版本存储到 ~/.nvm// 下,然后修改 $PATH,将指定版本的 node 路径加入,这样我们调用的 node 命令即是使用指定版本的 node。
- nvm 的全局模块存在于各自版本的沙箱中,切换版本后需要重新安装,不同版本间也不存在任何冲突。