视觉大模型综述
万字长文带你全面解读视觉大模型细数近期涌现的优秀视觉大模型工作 https://mp.weixin.qq.com/s/jLQaguLejx9zXjZjaJWx-Q深入了解视觉语言模型 - 知乎人类学习本质上是多模态 (multi-modal) 的,因为联合利用多种感官有助于我们更好地理解和分析新信息。理所当然地,多模态学习的最新进展即是从这一人类学习过程的有效性中汲取灵感,创建可以利用图像、视频、文本…
https://mp.weixin.qq.com/s/jLQaguLejx9zXjZjaJWx-Q深入了解视觉语言模型 - 知乎人类学习本质上是多模态 (multi-modal) 的,因为联合利用多种感官有助于我们更好地理解和分析新信息。理所当然地,多模态学习的最新进展即是从这一人类学习过程的有效性中汲取灵感,创建可以利用图像、视频、文本… https://zhuanlan.zhihu.com/p/609886192我之前已知觉得多模态模型应该完全将图像对齐到llm中,但是我现在越来越觉得在具体的生产任务中,先通过语音和图像将模态转成文本,再送入到llm中,也许更好,llm不一定要和其他模态产生直接的关联。
https://zhuanlan.zhihu.com/p/609886192我之前已知觉得多模态模型应该完全将图像对齐到llm中,但是我现在越来越觉得在具体的生产任务中,先通过语音和图像将模态转成文本,再送入到llm中,也许更好,llm不一定要和其他模态产生直接的关联。
基础视觉模型:


1.基础架构

-
双编码器架构:其中,独立的编码器用于处理视觉和文本模态,这些编码器的输出随后通过目标函数进行优化。
-
融合架构:包括一个额外的融合编码器,它获取由视觉和文本编码器生成的表示,并学习融合表示。
-
编码器-解码器架构:由基于编码器-解码器的语言模型和视觉编码器共同组成。
-
自适应 LLM 架构:利用大型语言模型(LLM)作为其核心组件,并采用视觉编码器将图像转换为与 LLM 兼容的格式(模态对齐)。
2.目标函数
2.1 对比学习
从无标签的图像文本中学习,clip使用了ITC(图像文本对比)损失,此外还有ITM(图像文本匹配),SimCLR以及各种ITC的变体FILIP Loss,TPC Loss,RWA,MITC,UniCL,RWC
2.2 生成式学习
条件概率模型,已知上一个token或图像预测下一个token。MLM、LM、Cap,主要是和语言模型相关联。
3.预训练
3.1 预训练数据集
视觉-语言模型的核心是大规模数据,可分为:
-
图像-文本数据:例如
CLIP使用的WebImageText等,这些数据通常从网络抓取,并经过过滤过程删除噪声、无用或有害的数据点。 -
部分伪标签数据:由于大规模训练数据在网络上不可用,收集这些数据也很昂贵,因此可以使用一个好的教师将图像-文本数据集转换为掩码-描述数据集,如
GLIP和SA-1B等。 -
数据集组合:有些工作直接将基准视觉数据集组合使用,这些作品组合了具有图像-文本对的数据集,如字幕和视觉问题回答等。一些工作还使用了非图像-文本数据集,并使用基于模板的提示工程将标签转换为描述。
3.2 微调
微调主要用于三个方面:
-
提高模型在特定任务上的性能(例如开放世界物体检测,
Grounding-DINO); -
提高模型在某一特定能力上的性能(例如视觉定位);
-
指导调整模型以解决不同的下游视觉任务(例如
InstructBLIP)。

上面是instructBLIP, 其实就是将image转成llm更好理解的query。
3.3 提示工程
大多数视觉数据集由图像和相应文本标签组成,为了利用视觉语言模型处理视觉数据集,一些工作已经利用了基于模版的提示工程,
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda() 4.基于文本提示的基础模型
4.1 基于对比学习的方法

clip产生N个图像-文本对的多模态嵌入空间。通过对称交叉熵损失来训练,以最小化N个正确图像-文本对的嵌入的余弦相似度,并最大化N²-N个不正确对的余弦相似度。
4.1.1 基于通用模型的对比方法

ALIGN,利用了一个超过10亿图像-文本对的噪声数据集,无需过滤,一个简单的双编码器架构学习使用对比性损失来对齐图像和文本的视觉和语言表示,效果也不错,只要数据措大,简单方法,效果sota。

Florence,从clip样式的预训练开始,扩展为具有3个不同适配头的模式,能够处理不同空间、时间和模式。

FILIP, 提出了一种交叉模态的后期交互方法,以捕捉细粒度语义对齐。FILIP 损失最大化了视觉和文本嵌入之间逐标记的相似性,有助于在不牺牲 CLIP 的推理效率的情况下,模拟两种模态之间的细粒度交互。
4.1.1.2 基于掩码对比学习

FLIP, FLIP 是一种简单和更有效的训练 CLIP 的方法,其思想很简单,如图所示,就是将 MAE 的 Mask 操作引入到 CLIP 上,随机地 mask 掉具有高 mask 率的图像碎片,只对可见的碎片进行编码。不同之处在于,这里不会对被 masked 的图像内容进行重建。此外,对于文本也做同样处理,有点类似于 BERT 但又不一样,BERT 是用学习过的 mask token 来代替它们,这种稀疏的计算可以显著减少文本编码的成本。
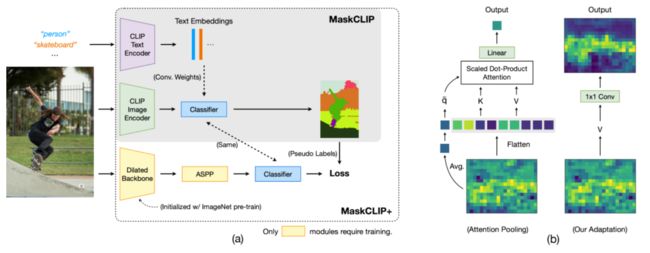
MaskCLIP 强调了图像是一个连续且细粒度的信号,而语言描述可能无法完全表达这一点。因此,MaskCLIP 通过随机遮挡图像并利用基于 Mean Teacher 的自蒸馏来学习局部语义特征。
4.1.2 基于视觉定位基础模型的方法

上图表明原始clip是擅长视觉定位任务的,特别是针对语义分割这种像素级定位任务来说。
RegionCLIP 显着扩展了 CLIP 以学习区域级视觉表示,其支持图像区域和文本概念之间的细粒度对齐,从而支持基于区域的推理任务,包括零样本目标检测和开放词汇目标检测。

CRIS则通过引入视觉-语言解码器和文本到像素对比损失,使CLIP学习像素级信息。
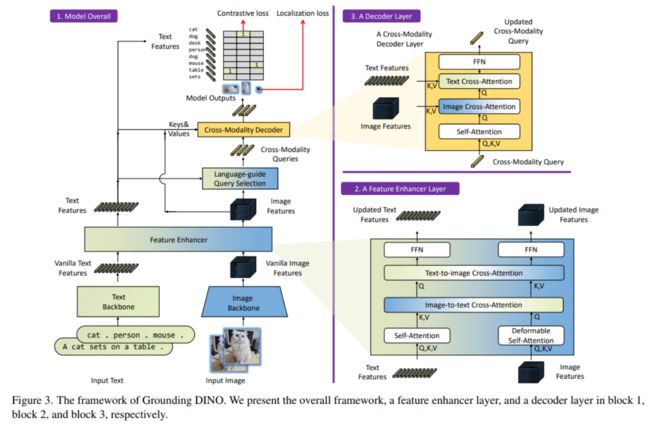
Grounding DINO,利用强大的预训练模型,并通过对比学习进行修改,以增强语言的对齐。
总体而言,上面一系列的基础视觉研究,这些方法试图通过对比学习、掩码学习等技术来改进clip。
4.2 基于生成式的方法
结合大语言模型的多模态范式:
-
结合上下文的多模态输入学习:例如
Frozen方法将图像编码器与LLM结合,无需更新LLM的权重,而是在带有图像标注的数据集上训练视觉编码器。类似地,Flamingo模型采用了固定的预训练视觉和语言模型,并通过Perceiver Resampler进行连接。 -
使用
LLM作为其它模态的通用接口:如MetaLM模型采用半因果结构,将双向编码器通过连接层连接到解码器上,可实现多任务微调和指令调整零样本学习。此外,KOSMOS系列也在LLM上整合了多模态学习的能力。 -
开源版本的模型:如
OpenFlamingo,是Flamingo模型的开源版本,训练于新的多模态数据集
通用目标下训练:
-
简化视觉语言建模:如
SimVLM使用前缀语言建模(PrefixLM)目标进行训练,不需要任务特定的架构或训练,可在多个视觉语言任务上实现优秀的性能。 -
掩码重构与对齐:如
MaskVLM,采用联合掩码重构语言建模,其中一个输入的掩码部分由另一个未掩码输入重构,有效对齐两个模态。 -
模块化视觉语言模型:如
mPLUG-OWL,由图像编码器、图像抽象器和冻结LLM组成,通过两阶段的训练实现多模态对话和理解。
上述方法之所以叫生成式,是因为其通过在视觉条件下训练语言生成任务,为llm增加视觉能力。
4.3 基于对比学习和生成式的混合方法
4.3.1 通用视觉-语言学习的基础模型
-
UNITER:结合了生成(例如掩码语言建模和掩码区域建模)和对比(例如图像文本匹配和单词区域对齐)目标的方法,适用于异构的视觉-语言任务。 -
Pixel2Seqv2:将四个核心视觉任务统一为像素到序列的接口,使用编码器-解码器架构进行训练。 -
Vision-Language:使用像 BART 或 T5 等预训练的编码器-解码器语言模型来学习不同的计算机视觉任务。
4.3.2 通用架构

-
Contrastive Captioner (CoCa):结合了对比损失和生成式的字幕损失,可以在多样的视觉数据集上表现良好。 -
FLAVA:适用于单模态和多模态任务,通过一系列损失函数进行训练,以便在视觉、语言和视觉-语言任务上表现良好。 -
BridgeTower:结合了不同层次的单模态解码器的信息,不影响执行单模态任务的能力。 -
PaLI:一种共同扩展的多语言模块化语言-视觉模型,适用于单模态和多模态任务。 -
X-FM:包括语言、视觉和融合编码器的新基础模型,通过组合目标和新技术进行训练。
4.3.3 BLIP框架范式
-
BLIP:利用生成和理解能力有效利用图像文本数据集,采用Multimodal mixture of Encoder-Decoder (MED)架构。 -
BLIP-2:通过查询转换器来实现计算效率高的模态间对齐。
4.3.4 指令感知特征提取和多模态任务解决方案
-
InstructBLIP:利用视觉编码器、Q-Former和LLM,通过指令感知的视觉特征提取来进行训练。对预训练模型的高效利用: -
VPGTrans:提供了一种高效的方法来跨 LLM 传输视觉编码器。 -
TaCA:提到了一种叫做TaCA的适配器,但没有进一步详细描述。
4.3.4 基于Visual Grounding的方法
-
ViLD:这一方法使用了一个两阶段的开放词汇对象检测系统,从预训练的单词汇分类模型中提取知识。它包括一个RPN和一个类似于CLIP的视觉语言模型,使用Mask-RCNN创建对象提案,然后将知识提取到对象检测器中。 -
UniDetector: 此方法旨在进行通用对象检测,以在开放世界中检测新的类别。它采用了三阶段训练方法,包括类似于上面我们提到的RegionCLIP的预训练、异构数据集训练以及用于新类别检测的概率校准。UniDetector 为大词汇和封闭词汇对象检测设立了新的标准。 -
X-Decoder: 在三个粒度层次(图像级别、对象级别和像素级别)上运作,以利用任务协同作用。它基于Mask2Former,采用多尺度图像特征和两组查询来解码分割掩码,从而促进各种任务。它在广泛的分割和视觉语言任务中展现出强大的可转移性。
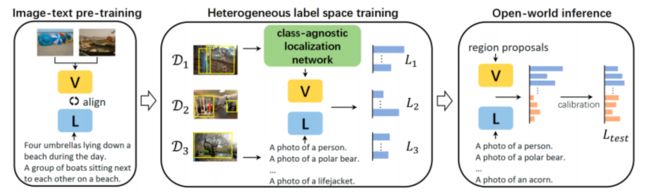
UniDetecor
4.4 基于对话式的视觉语言模型
GPT4
miniGPT4,由预训练大语言模型Vicuna和视觉组件Vit-G和Qformer组成。模型先在多模态示例上训练,然后在高质量的图像和文本对上微调。
XrayGPT:基于visualglm的
LLaVA
LLaMA-Adapter v2
5.基于视觉提示的基础模型
5.1 视觉基础模型
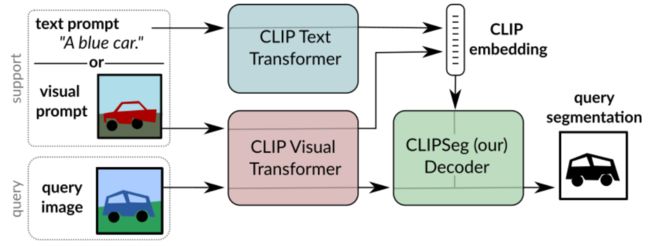
CLIPSeg:视觉和文本查询通用相应的clip编码器获取嵌入,然后归入clipseg解码器中。
SegGPT

SAM

SEEM
5.2 SAM的改进与应用

FastSAM、MobileSAM、RefSAM、HQSAM
5.3 通才模型
如何使用上下文学习快速适应具有不同提示和示例的各种任务,给定示例prompt,就能完成相应的任务。

Painter, 在训练后,painter可以根据与输入条件相同的任务的输入/输出配对图像来确定在推理过程中执行哪个任务。

VisionLLM可以对齐视觉和语言模态已解决开放式任务,利用视觉模型学习图像特征,这些图像特征与描述图像的语言指令一起传递给语言引导的图像分词器,图像分词器的输出连同语言指令被提供给一个开放式的llm为基础的任务解码器。
6.综合性基础模型
6.1 基于异构架构的基础视觉模型
对齐图像-文本,视频-音频,图像-深度等成对模态
6.1.1 CLIP与异构模态对齐

CLIP2Video:将图像-文本的clip模型的空间语义转移到视频-文本检索问题中。

AudioCLIP:处理音频。
6.1.2 学习共享表示的多模态模型
ImageBind:
MACAW-LLM
6.1.3 视频和长篇幅文本的处理
COSA
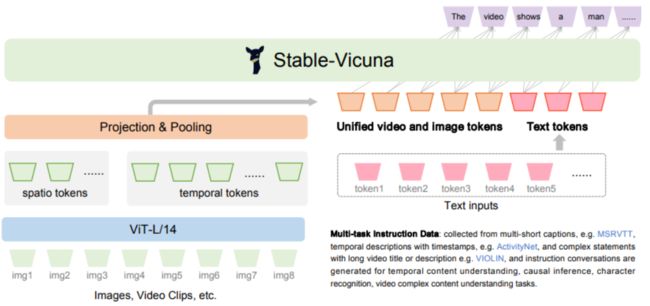
Valley
6.2 基于代理的基础视觉模型
基于代理的基础视觉模型将llm与现实视觉的视觉和物理传感器模式详结合,不仅涉及文字的理解,还涉及与现实视觉的互动和操作,特别是在机器人操作和导航方面。