知识点21--springboot 文件切片上传
前面有一篇简单版的文件上传,是为了让大家知道文件上传是在干什么,但是在正式的开发中文件上传是一个稍微有些麻烦的东西,需要从页面层开发到数据层,如果你常常听人说文件上传会知道有一些相关的名词,比如切片、秒传、断点续传、md5、合并等名词。但其实一个完整的文件上传开发起来核心点永远只有那么几个。因此,本篇知识点给大家写了一个完整的文件上传流程,本身是用于大文件上传,不过当你看明白了代码,知晓了文件上传的核心要点,你就会发现,大、小文件的上传区别就两点,一是是否分片,二是是否并发,其他的都差不多。
当然考虑到适用性和大家的理解能力,本篇写的上传流程并没有偏业务代码,比如检查文件大小、图片像素等等这种偏业务的代码通通没有,只写了上传文件的主体核心流程,同时代码也上传到了github----》https://github.com/wangyang159/boot-jsp
看本例代码的时候有个容易产生误区的点要注意,本例代码只针对单个文件,如果你是多文件,则遍历文件调用上传就行,千万不要在单文件并发的基础上,再套一层多文件并发,先不说性能和开发难度的问题,浏览器就撑不住,浏览器对于请求的个数都是有一个上限的,而且一般不高,你可以去查一查,最高的应该是谷歌派系,也只是最高支持6个。所以我的代码中并发度是两个,给其他请求留了4个,同理你要是在单文件并发上在套一层多文件同时并发,那你的代码就成垃圾了,能不能用都成问题。不过一般在正式开发中涉及到文件上传,小文件一般传递很快,只需要把大文件的一个md5对应多个切片的js数据集合,换成小文件场景下一对一的数据集,就是说把小文件当成大文件的切片,再对应的改一下发送请求的代码,从而就可以实现小文件的并发发送,而大文件肯定会有个数和大小的限制的,不会让你很多个大文件一起上传,比如腾讯旗下的产品大多就限制单个大文件最大4G,多个挨个上传,所以遍历大文件单个并发上传就够了。
由于整个流程细节很多就不给大家分解了,完整的代码如果看不明白可以留言给我。为了方便大家理解,最好是先看一下流程图。
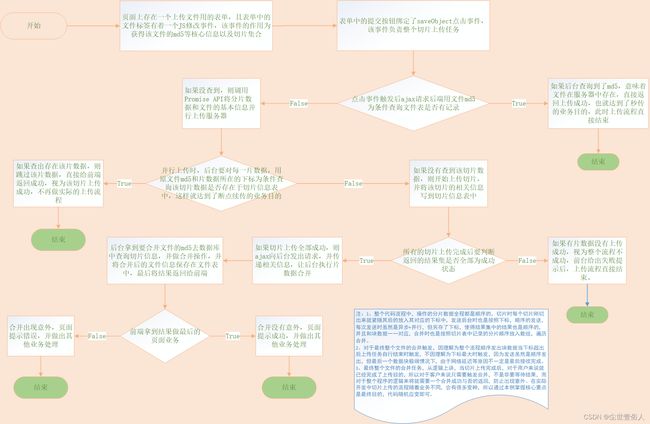
看完流程图对整个流程有个影响,就可以看代码了。
1、首先是前端的表单页面
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>切片上传title>
head>
<body>
<form id="addFrm" enctype="multipart/form-data" method="post">
文件上传:<input type="file" name="file" id="file"><br/>
<input type="button" onclick="saveObject()" value="文件上传"/>
form>
<script type="text/javascript" src="/sy.js">script>
<script type="text/javascript" src="spark-md5.min.js">script>
<script type="text/javascript" src="jquery-3.2.1.js">script>
<script type="text/javascript">
/**
* 1、分片获取文件的md5 并 顺序保存分片fileblock
* 给单文件标签添加一个修改事件,修改时将文件分为sliceLength个片
* 文件总大小除以sliceLength获得每个块的大小chunkSize
* FileReader每读取一块文件的字节数组就追加到SparkMD5中
* onload回调函数递归闭包的读取方法直到读取结束
* file_index是原文件的字节数组指针,fileblock_index是保存块文件的数组指针
* 最终将结果封装在一个总的结果集readyfilemeg中
*
* 注意结果中块数一定是sliceLength块,不要担心除法有可能除不尽文件的总大小
* 递归读取的条件是file_index小于文件总字节当运行到最后一块不够的的时候任然会切片
*/
var readyfilemeg = []
document.querySelector('#file').addEventListener('change', e => {
//准备需要的变量
const fileblock = [];
let fileblock_index = 0;
//document获取文件
const file = e.target.files[0];
const sliceLength = 5;
const chunkSize = Math.ceil(file.size / sliceLength);
const fileReader = new FileReader();
const md5 = new SparkMD5();
let file_index = 0;
//运行方法
const loadFile = () => {
//slice是一个左闭右开的方法
const slice = file.slice(file_index, file_index + chunkSize);
fileblock[fileblock_index]=slice;
fileblock_index++;
file_index += chunkSize;
fileReader.readAsBinaryString(slice);
}
//第一次需要手动调一下,才能触发onload
loadFile();
fileReader.onload = e1 => {
md5.appendBinary(e1.target.result);
if ( file_index < file.size ) {
loadFile();
} else {
//封装结果:文件的md5、文件块集合、文件块总数、文件的名称、文件总大小
readyfilemeg["filemd5"]=md5.end();
readyfilemeg["fileblocks"]=fileblock;
readyfilemeg["fileblocksize"]=fileblock_index;
readyfilemeg["filename"]=file.name;
readyfilemeg["filesize"]=file.size;
console.log(readyfilemeg)
}
};
});
/**
* 2、当要点击上传的时候,使用并发API-Promise将切片信息并发传递给后台
*/
function saveObject() {
//秒传
$.ajax({
method:"post",
dataType:"json",
url:"/minupload",
data:{"fileMd5":readyfilemeg["filemd5"]},
success:function (result) {
if(result){
alert("上传成功")
}else {
concurRequst(readyfilemeg,2).then(resps=>{
let reduce = 0;
for (let i = 0; i < resps.length; i++) {
reduce+=parseInt(resps[i]);
}
/**
* 3、根据后台传递回来的信息全部为上传成功,那么就要触发后台合并
*/
if(reduce != 0){
alert("上传失败请重新上传文件")
}else{
$.ajax({
method:"post",
dataType:"json",
url:"/allhb",
data:{"fileMd5":readyfilemeg["filemd5"],"fileSize":readyfilemeg["filesize"],"fileName":readyfilemeg["filename"]},
success:function (result) {
if(result){
alert("上传成功")
}else{
alert("上传失败")
}
}
})
}
});
}
}
})
}
script>
body>
html>
2、页面上发送单独写了一个js,用来写上传时的方法
/**
* 用并发请求的方式发出所有文件,本质上是Promise提供的异步且并发发送请求功能,运行上就是用n个并发,将请求体数组中的请求分摊开来发送
* @param readyfilemeg 请求体数组
* @param maxNum 最大并发数
* @returns
*/
function concurRequst(datas,maxNum) {
//并发发送请求,resolve是Promise用来回调的结果集
return new Promise(resolve => {
//文件数据不能为空
if(datas == null){
//Promise类的方法,调用时表示Resolved已完成,又称Fulfilled,参数是结束后可供回调的数据
resolve([])
return
}
//定义一个保存结果的临时数组、一个取文件信息时的临时下标、并且将文件块信息取出来
const result = [];
let index = 0;
let fileblocks = datas["fileblocks"];
//并发发出请求的方法
async function request() {
//当文件块数组中的内容全部发完,结束任务,返回回调结果
if(index === fileblocks.length){
resolve(result);
return;
}
//每次取出一个文件块,index后移,并另存一份下标后面要按下标保存结果
const fileblock = fileblocks[index];
const i = index;
index++;
//封装该文件块的信息
let f = new FormData();
f.append("fileBlock",fileblock);//文件块本身
f.append("fileMd5",datas["filemd5"]);//总文件的md5
f.append("fileBlockSize",fileblocks.length);//总文件一共被分了几块
f.append("blockIndex",i+1);//该快文件的序号
f.append("fileName",datas["filename"]);//文件的名称
try {
//把文件块的信息发到后台并保存返回结果
const resp = await fetch("http://localhost:91/upload",{
method : "post",
body : f
})
//后台将结果信息保存在响应头中,拿出来按顺序放到临时的结果集中
result[i]=resp.headers.get("meg")
}catch (err){
//出现意外 也要把错误信息加入进去
result[i] = err
}finally {
//递归发送下一个请求
request()
}
}
//用并发数和请求体数组元素个数取最小值控制发送数量
const t = Math.min(maxNum,fileblocks.length)
for (let i = 0 ; i < t ; i++){
request()
}
})
}
3、前端用了两个框架,第一个是jquery,大家应该都有,第二个是spark-md5,是一个计算文件md5的js框架,它可以在git上下载到https://github.com/satazor/js-spark-md5

代码中用它配合文件切分,提高转换大文件md5效率的同时,也完成了切片的需求,如果大家自己写代码的时候如果上传的是一般大小的文件,不需要切片的话,可以直接整个文件读取md5,就像下面这样
document.querySelector('#file').addEventListener('change', e => {
const file = e.target.files[0];
const fileReader = new FileReader()
fileReader.readAsBinaryString(file);
fileReader.onload = e => {
const md5 = SparkMD5.hashBinary(e.target.result);
console.log(md5);
}
});
4、前端就上面这些了,下面就是后端,首先是后端的数据Bean,需要对应数据库中的切片信息表和文件信息表
package com.wy.bootjsp.bean;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
/**
* 作者: wangyang
* 创建时间: 2022/12/20
* 描述:
* FileBlock 文件块数据的信息类
*/
public class FileBlock {
/**
* 数据id
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 总文件的md5信息
*/
private String fileMd5;
/**
* 总文件一共被分了几块
*/
private Integer fileBlockSize;
/**
* 该块文件的顺序号
*/
private Integer blockIndex;
/**
* 总文件的名字
*/
private String fileName;
/**
* 该文件块的全路径名
*/
private String blockPathName;
public FileBlock() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getFileMd5() {
return fileMd5;
}
public void setFileMd5(String fileMd5) {
this.fileMd5 = fileMd5;
}
public Integer getFileBlockSize() {
return fileBlockSize;
}
public void setFileBlockSize(Integer fileBlockSize) {
this.fileBlockSize = fileBlockSize;
}
public Integer getBlockIndex() {
return blockIndex;
}
public void setBlockIndex(Integer blockIndex) {
this.blockIndex = blockIndex;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String getBlockPathName() {
return blockPathName;
}
public void setBlockPathName(String blockPathName) {
this.blockPathName = blockPathName;
}
@Override
public String toString() {
return "FileBlock{" +
"id=" + id +
", fileMd5='" + fileMd5 + '\'' +
", fileBlockSize=" + fileBlockSize +
", blockIndex=" + blockIndex +
", fileName='" + fileName + '\'' +
", blockPathName='" + blockPathName + '\'' +
'}';
}
}
package com.wy.bootjsp.bean;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
/**
* 作者: wangyang
* 创建时间: 2022/12/20
* 描述:
* FileMeg 结果文件信息
*/
public class FileMeg {
/**
* 数据id
*/
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
/**
* 文件的md5信息
*/
private String fileMd5;
/**
* 总文件一共被分了几块
*/
private Integer fileBlockSize;
/**
* 总文件的名字
*/
private String fileName;
/**
* 文件的全路径名
*/
private String pathName;
/**
* 文件总大小
*/
private Long fileSize;
public FileMeg() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getFileMd5() {
return fileMd5;
}
public void setFileMd5(String fileMd5) {
this.fileMd5 = fileMd5;
}
public Integer getFileBlockSize() {
return fileBlockSize;
}
public void setFileBlockSize(Integer fileBlockSize) {
this.fileBlockSize = fileBlockSize;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public Long getFileSize() {
return fileSize;
}
public void setFileSize(Long fileSize) {
this.fileSize = fileSize;
}
public String getPathName() {
return pathName;
}
public void setPathName(String pathName) {
this.pathName = pathName;
}
@Override
public String toString() {
return "FileMeg{" +
"id=" + id +
", fileMd5='" + fileMd5 + '\'' +
", fileBlockSize=" + fileBlockSize +
", fileName='" + fileName + '\'' +
", pathName='" + pathName + '\'' +
", fileSize=" + fileSize +
'}';
}
}
并且你要准备一个数据库建表
/*
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50725
Source Host : localhost:3306
Source Schema : test
Target Server Type : MySQL
Target Server Version : 50725
File Encoding : 65001
Date: 20/12/2022 20:48:14
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for blockmeg
-- ----------------------------
DROP TABLE IF EXISTS `blockmeg`;
CREATE TABLE `blockmeg` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`filemd5` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '原文件的md5',
`fileblocksize` int(11) NULL DEFAULT NULL COMMENT '原文件被切分的总块数',
`blockindex` int(11) NULL DEFAULT NULL COMMENT '该块数对比原文件分块的顺序',
`filename` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '原文件姓名',
`blockpathname` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '块数据保存路径',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 79 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '切片信息表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for filemeg
-- ----------------------------
DROP TABLE IF EXISTS `filemeg`;
CREATE TABLE `filemeg` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`filemd5` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '文件的md5',
`fileblocksize` int(11) NULL DEFAULT NULL COMMENT '文件被切分的总块数',
`filename` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '文件名',
`pathname` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '文件存储路径',
`filesize` bigint(20) NULL DEFAULT NULL COMMENT '文件总大小',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '切片信息表对应的原文件信息表' ROW_FORMAT = Dynamic;
5、随后是控制器层
package com.wy.bootjsp.controller;
import com.wy.bootjsp.bean.FileBlock;
import com.wy.bootjsp.bean.FileMeg;
import com.wy.bootjsp.service.FileBlockService;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.IOException;
import java.util.List;
/**
* 作者: wangyang
* 创建时间: 2022/12/18
* 描述:
* 处理文件上传的控制器
*/
@Controller
public class FileUploadContrller {
@Resource
private FileBlockService fileBlockService;
/**
* 接收数据块的控制器,并支持断点续传
* @param response
* @param fileBlock
* @param fileBlockMeg
*/
@RequestMapping("/upload")
@ResponseBody
public void test(HttpServletResponse response, @RequestParam("fileBlock") MultipartFile fileBlock, FileBlock fileBlockMeg){
//断点续传:用总文件的md5和文件块序号去数据库中查,如果有则跳过存储该数据块
Integer blockId = fileBlockService.getFileBlockByMd5AndIndex(fileBlockMeg);
if(blockId != null){
response.addHeader("meg","0");
return;
}
//如果秒传没有发现已有数据块就保存
String path = null;
try {
path = fileBlockService.saveFile(fileBlock, fileBlockMeg);
} catch (IOException e) {
response.addHeader("meg","1");
e.printStackTrace();
return;
}
fileBlockMeg.setBlockPathName(path);
//把块文件信息写在数据库里面
fileBlockService.insertFileBlockMeg(fileBlockMeg);
response.addHeader("meg","0");
}
/**
* 通过文件的md5查询文件信息表是否有记录,如果有则视为本次上传为秒传
* @param fileMd5
* @return
*/
@RequestMapping("/minupload")
@ResponseBody
public Boolean minonload(String fileMd5){
Integer id = fileBlockService.getFileMegByMd5(fileMd5);
if(id != null){
return true;
}else{
return false;
}
}
/**
* 文件合并,并把结果文件的信息保存在数据库中
* @param fileMd5
* @param fileSize
* @param fileName
* @return
*/
@RequestMapping("/allhb")
@ResponseBody
public Boolean allhb(String fileMd5,long fileSize,String fileName) throws InterruptedException {
/*
等待一秒防止前面切面并行上传的结果没有完全落库完成
如果不等,则由于前面的上传是promise异步+并行,虽然使用了await,但仍然很可能少查询到n条数据,往往是最后一条
*/
Thread.sleep(1000);
//先查出所有文件片路径信息
List<FileBlock> fileBlocksPath = fileBlockService.getFileBlocksPath(fileMd5);
//获取到这些片文件,按顺序放到数组中
File[] fileBlocks = new File[fileBlocksPath.size()];
for (int i = 0 ; i < fileBlocksPath.size() ; i++){
FileBlock f = fileBlocksPath.get(i);
//下标要减一,因为片文件保存的时候是从1开始的
fileBlocks[f.getBlockIndex()-1] = new File(f.getBlockPathName());
}
//合并这些文件,注意保存文件的时候文件名主体使用md5
String savePath = fileBlockService.allhb(fileBlocks, fileMd5 + "." + fileName.split("\\.")[1]);
//如果合并成功返回的应该是结果文件的路径,需要和其他关键信息一起保存到数据库中
if(!savePath.equals("error")){
FileMeg fileMeg = new FileMeg();
fileMeg.setFileMd5(fileMd5);
fileMeg.setFileName(fileName);//保存文件信息时保存的是文件的本来名字
fileMeg.setFileSize(fileSize);
fileMeg.setFileBlockSize(fileBlocks.length);
fileMeg.setPathName(savePath);
fileBlockService.insertFileMeg(fileMeg);
return true;
}else{
return false;
}
}
}
6、随后是service业务层
package com.wy.bootjsp.service;
import com.wy.bootjsp.bean.FileBlock;
import com.wy.bootjsp.bean.FileMeg;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.util.List;
/**
* 作者: wangyang
* 创建时间: 2022/12/20
* 描述:
* FileBlockService
*/
public interface FileBlockService {
/**
* 通过md5和文件序号查询一条分片信息
* @param fileBlock
* @return
*/
Integer getFileBlockByMd5AndIndex(FileBlock fileBlock);
/**
* 文件存储
* @param file
* @param fileBlock
* @return
*/
String saveFile (MultipartFile file,FileBlock fileBlock) throws IOException;
/**
* 通过md5获得一个文件信息
* @param fileMd5
* @return
*/
Integer getFileMegByMd5(String fileMd5);
/**
* 保存文件块信息
* @param fileBlock
* @return
*/
void insertFileBlockMeg(FileBlock fileBlock);
/**
* 获取所有文件的路径信息
* @param fileMd5
* @return
*/
List<FileBlock> getFileBlocksPath(String fileMd5);
/**
* 合并所有文件的方法
* @param files
* @param savaFileName 合并结果的文件名
* @return
*/
String allhb(File[] files,String savaFileName);
/**
* 保存完整文件信息
* @param fileMeg
* @return
*/
void insertFileMeg(FileMeg fileMeg);
}
package com.wy.bootjsp.service.impl;
import com.wy.bootjsp.bean.FileBlock;
import com.wy.bootjsp.bean.FileMeg;
import com.wy.bootjsp.mapper.FileBlockMapper;
import com.wy.bootjsp.service.FileBlockService;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
import java.io.*;
import java.util.List;
/**
* 作者: wangyang
* 创建时间: 2022/12/20
* 描述:
* FileBlockSerivceImpl
*/
@Service
public class FileBlockSerivceImpl implements FileBlockService {
@Resource
private FileBlockMapper fileBlockMapper;
@Override
public Integer getFileBlockByMd5AndIndex(FileBlock fileBlock) {
return fileBlockMapper.getFileBlockByMd5AndIndex(fileBlock);
}
@Override
public String saveFile(MultipartFile file,FileBlock fileBlock) throws IOException {
//结果文件名称
String fileName = fileBlock.getFileMd5() + fileBlock.getBlockIndex() + ".ext";
//创建新文件对象
File destFile = new File("D:\\pic", fileName);
//确保目标的父文件目录存在
if (!destFile.getParentFile().exists()) {
destFile.mkdirs();
}
//执行拷贝过程
file.transferTo(destFile);
//返回文件的全路径名
return destFile.getPath();
}
@Override
public Integer getFileMegByMd5(String fileMd5) {
return fileBlockMapper.getFileMegByMd5(fileMd5);
}
@Override
public void insertFileBlockMeg(FileBlock fileBlock) {
fileBlockMapper.insertFileBlockMeg(fileBlock);
}
@Override
public List<FileBlock> getFileBlocksPath(String fileMd5) {
return fileBlockMapper.getFileBlocksPath(fileMd5);
}
@Override
public String allhb(File[] files,String savaFileName) {
String resultPath = "D:\\pic\\"+savaFileName;
FileInputStream in = null;
FileOutputStream out = null;
try {
//新建一个目标文件对象
File target = new File(resultPath);
//打开文件流输出对象
out = new FileOutputStream(target);
//循环读取要合并的文件集合
for(File f : files) {
byte[] buf = new byte[1024];
int len = 0;
in = new FileInputStream(f);
while ((len = in.read(buf)) != -1) {
//写出数据
out.write(buf,0,len);
}
//写完之后把片文件的输入流关掉
if (in != null) {
in.close();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
return "error";
} catch (IOException e) {
e.printStackTrace();
return "error";
}finally {
//把结果文件的输出流关掉
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return resultPath;
}
@Override
public void insertFileMeg(FileMeg fileMeg) {
fileBlockMapper.insertFileMeg(fileMeg);
}
}
7、最后是数据层
package com.wy.bootjsp.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.wy.bootjsp.bean.FileBlock;
import com.wy.bootjsp.bean.FileMeg;
import java.util.List;
/**
* 作者: wangyang
* 创建时间: 2022/12/20
* 描述:
* FileBlockDao
*/
public interface FileBlockMapper extends BaseMapper<FileBlock> {
/**
* 通过md5和文件序号查询一条分片信息
* @param fileBlock
* @return
*/
Integer getFileBlockByMd5AndIndex(FileBlock fileBlock);
/**
* 通过md5获得一个文件信息
* @param fileMd5
* @return
*/
Integer getFileMegByMd5(String fileMd5);
/**
* 保存文件块信息
* @param fileBlock
* @return
*/
void insertFileBlockMeg(FileBlock fileBlock);
/**
* 获取所有文件的路径信息
* @param fileMd5
* @return
*/
List<FileBlock> getFileBlocksPath(String fileMd5);
/**
* 保存完整文件信息
* @param fileMeg
* @return
*/
void insertFileMeg(FileMeg fileMeg);
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.wy.bootjsp.mapper.FileBlockMapper">
<select id="getFileBlockByMd5AndIndex" resultType="Integer">
select id from blockmeg where filemd5=#{fileMd5} and blockindex=#{blockIndex}
</select>
<insert id="insertFileBlockMeg">
insert into blockmeg(filemd5,fileblocksize,blockindex,filename,blockpathname) values(
#{fileMd5},#{fileBlockSize},#{blockIndex},#{fileName},#{blockPathName}
)
</insert>
<select id="getFileMegByMd5" resultType="Integer">
select id from filemeg where filemd5=#{fileMd5}
</select>
<resultMap id="fileBlockMap" type="com.wy.bootjsp.bean.FileBlock">
<id column="id" property="id"></id>
<result column="blockpathname" property="blockPathName" />
<result column="blockindex" property="blockIndex" />
</resultMap>
<select id="getFileBlocksPath" resultMap="fileBlockMap">
select id,blockpathname,blockindex from blockmeg where filemd5=#{fileMd5}
</select>
<insert id="insertFileMeg">
insert into filemeg(id,filemd5,fileblocksize,filename,pathname,filesize) values(
#{id},#{fileMd5},#{fileBlockSize},#{fileName},#{pathName},#{fileSize}
)
</insert>
</mapper>
其他pom、springboot配置文件那些,大家自己把代码拉下来自己看就行。
最后说一下合并文件时等待时间的问题,本质上是为了解决数据库的 “幻读” 问题,不知道什么叫幻读的自己去查一下,这里要说的是,为了省事我在代码里面使用了添加等待时间的解决方法,但是这个方法并不保险,它的解决概率不是100%,虽然代码逻辑上讲合并是在所有的Promise异步执行结束才触发的,但是等多久是一个很容易受影响的事情,最保险的方法是前端使用Promise.all()方法配合发送文件的Promise,尽量不要后端去解决,那很麻烦的,因为要使用悲观锁或者乐观锁,再麻烦点就是分布式锁,头发掉光光哦,0v0~~