AI工程师招募;60+开发者AI工具清单;如何用AI工具读懂插件源码;开发者出海解读;斯坦福LLM课程 | ShowMeAI日报

日报&周刊合集 | 生产力工具与行业应用大全 | 点赞关注评论拜托啦!

一则AI工程师招募信息:新领域需要新技能
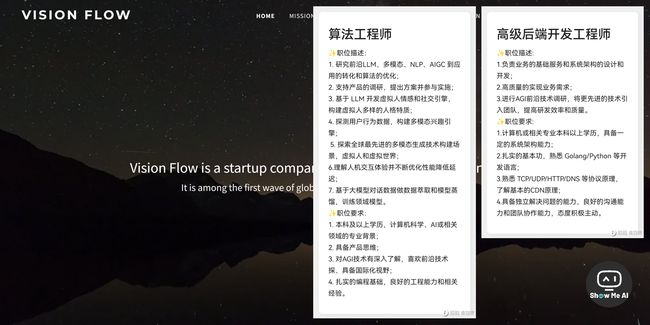
Vision Flow (目的涌现) 是一家基于 AGI 原生技术的创业公司,是全球探索AGI原生应用的第一波船队。创立初期获得李想、曾鸣、Yeahmobi等知名机构投资。最近,其创始人 @刘夜 在社交媒体中发布了一则招聘信息,不管是否应聘都可以看一下JD,了解新岗位的技能需求。
岗位:算法工程师、高级后端开发工程师
工作地点:北京朝阳区望京
薪资:面谈
发送简历至:[email protected]
邮件主题格式为:即刻+应聘岗位+姓名 ⋙ 即刻@刘夜 | Vision Flow 官网

雷军:小米大模型技术主力突破方向是「轻量化,本地部署」

8月14日晚,小米创始人、董事长雷军的第四次年度演讲「> 成长> 」在国家会议中心举行。在3小时的演讲和年度新品发布中,雷军分享了过去30多年经历的几次关键成长和感悟,并宣布小米科技战略升级:深耕底层技术、长期持续投入,软硬深度融合,AI全面赋能。
同时,小米积极布局人工智能,全面推进大模型研发和落地,选择「轻量化,本地部署」作为小米大模型技术主力突破方向,并在现场正式宣布手机端侧大模型初步跑通,部分场景效果媲美云端。此外,小爱同学也升级AI大模型,并开启邀请测试 ⋙ 阅读全文
科大讯飞发布「讯飞星火认知大模型V2.0」
https://xinghuo.xfyun.cn/
8月15日,科大讯飞举办了主题为「解放生产力,释放想象力」的发布会,宣布星火认知大模型升级为 V2.0 版本,重磅发布了代码能力、多模态能力,分享了其在教育、办公等领域商业落地进展,并将同步发布星火语伴2.0、星火教师助手、AI学习机的「AI创意画板」/「AI编程」等新功能。
根据发布会的介绍和实时演示,讯飞星火V2.0已具备代码生成、代码补齐、代码纠错、代码解释、单元测试生成等能力,多模态能力已实现图像描述、图像理解、图像推理、识图创作、文图生成、虚拟人合成等功能,并在生态内聚集4109支开发者团队,创建了7862款星火助手 ⋙ 了解详情
首个生成式AI监管文件,今天(8月15日)起施行
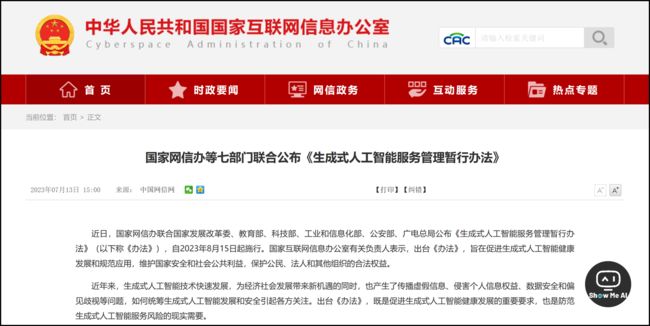
8月15日起,《生成式人工智能服务管理暂行办法》(以下称《办法》) 开始施行,这也是我国首个针对生成式人工智能产业的规范性政策。
《办法》界定了生成式人工智能技术的基本概念,规定了生成式人工智能服务提供者的制度要求,为生成式人工智能的健康发展指明了方向:
坚持发展和安全并重,对生成式人工智能服务实行包容审慎和分类分级监管
明确适用对象和范围:适用于向境内公众提供AIGC服务,对大量垂直领域如科研、工业应用等场景排除适用范围
以鼓励产业创新和发展为重,明确生成式人工智能技术发展路径和重点方向
搭建人工智能全生命周期监管体系,对数据、算法等业务适度“松绑” ⋙ 微信阅读全文 | 专家解读

一份AI开发者的工具清单,60+工具帮你效率UPUP!

最近逛 GitHub 发现了一份非常棒的工具清单,汇总了面向开发人员的 60+ AI工具。将工具的名称、链接和简介等信息分类如下,非常值得收藏~
集成开发环境 IDEs
Cursor(https://www.cursor.so/): 具有聊天、编辑、生成和调试功能的IDE。从VSCodium分叉,因此界面类似于VS Code。使用OpenAI。
Mutable(https://mutable.ai/): 基于Web的IDE,与聊天机器人和GitHub集成。
助手 Assistants
Replit Ghostwriter Chat(https://replit.com/site/ghostwriter): 内置于 Replit 的助手,具有聊天、主动调试和自动补全功能。使用 OpenAI 进行聊天,并使用 replit-code-v1-3b(OS)进行自动补全。
GitHub Copilot X(https://github.com/features/preview/copilot-x): 带有聊天、拉取请求文本生成和单元测试生成功能的 VS Code 扩展。
Refact AI(https://refact.ai/): 开源助手,具有聊天、补全、重构和针对代码库的细调功能。适用于 VS Code 和 JetBrains 的扩展。
Codeium(https://codeium.com/): 带有自动补全、自然语言搜索和聊天功能的助手。适用于包括 VS Code、JetBrains、Neovim、Vim、Emacs、Eclipse、PyCharm 和 Xcode 在内的 21 个编辑器。企业版包括针对代码库的细调功能。
Continue(https://continue.dev/): 带有聊天、重构和代码生成功能的 VS Code 扩展。可编辑多个文件并代表您运行命令。
Blackbox(https://www.useblackbox.io/): 带有自动补全和聊天功能的 VS Code 扩展,包括指向在线编码参考的链接。
Source Graph Cody(https://about.sourcegraph.com/cody): 带有聊天、重构和单元测试生成功能的助手。适用于 VS Code 和 IntelliJ 的扩展。
Quack AI(https://www.quack-ai.com/): 用于遵循项目编码规范的 VS Code 扩展。等候列表。
talk-codebase(https://github.com/rsaryev/talk-codebase): 具有仓库上下文的命令行聊天机器人。支持 OpenAI,以及通过 GPT4All 本地运行的LLM。
Magnet(https://www.magnet.run/): 基于 Web 的聊天机器人,以仓库和问题为上下文。
Adrenaline(https://useadrenaline.com/): 使用人工智能和 AST 来回答关于代码库的问题的基于 Web 的聊天机器人。
Tabby(https://tabbyml.github.io/tabby/): 开源的、自托管的代码补全助手。适用于 VS Code 和 Vim 的扩展。
Tabnine(https://www.tabnine.com/): 开源的、自托管的代码补全助手。适用于包括 VS Code、IntelliJ、Neovim、Eclipse 和 PyCharm 在内的 15 个编辑器。
CodeSquire(https://codesquire.ai/): 为 Google Colab、BigQuery 和 JupyterLab 添加自动补全功能的 Chrome 扩展。
CodeMate(https://www.codemate.ai/): 用于调试和优化代码的 VS Code 扩展。
Shell助手 Shell assistants
AskCommand(https://www.askcommand.cppexpert.online/): 使用人工智能自动从文本生成 Unix 命令的基于 Web 的工具。
Butterfish(https://butterfi.sh/): 在您的 shell 中嵌入 ChatGPT 以提供方便访问的命令行工具。包括简单的自主能力。
智能体 Agents
Smol Developer(https://github.com/smol-ai/developer): 通过CLI代理根据提示生成存储库。使用OpenAI和Anthropic。
Aider(https://github.com/paul-gauthier/aider): 通过CLI助手和代理生成更改和提交到存储库。使用OpenAI。
Mentat(https://www.mentat.codes/): 通过CLI助手和代理对存储库进行更改。
GPT Engineer(https://github.com/AntonOsika/gpt-engineer): 通过CLI代理根据提示生成存储库,并提问澄清问题。
GPT Migrate(https://github.com/0xpayne/gpt-migrate): 通过CLI代理将全栈应用程序从一种语言或框架转换为另一种。使用GPT-4 32k上下文。
GitWit(https://gitwit.dev/): 用于向Git存储库的全栈应用程序添加功能的基于Web的代理。
DemoGPT(https://github.com/melih-unsal/DemoGPT): 具有Llama 2的强大力量的自动生成AI应用程序生成器
DevOpsGPT(https://github.com/kuafuai/DevOpsGPT): DevOpsGPT基于AI的软件开发自动化解决方案
Second.dev(https://www.second.dev/): 用于向全栈应用程序添加功能的平台。
Factory(https://www.factory.ai/): 用于代码生成的代理。等待中。
应用生成器 App generators
Pico(https://picoapps.xyz/): 具有即时部署的端到端微应用生成器
Literally anything(https://literallyanything.io/ ) : HTML和JavaScript Web应用生成器。
代码片段生成器 Snippet generators
CodePal(https://codepal.ai/ ) : 一个用于快速生成或重构代码的Web工具。
AI Code Convert(https://aicodeconvert.com/ ) : 一个用于在编程语言之间转换代码的Web工具。
AI Code Playground(https://aicodeplayground.com/ ) : 用于重构和改进代码的Web工具。
文档 Documentation
Trelent(https://trelent.net/): 一个用于生成文档字符串的VS Code扩展。使用专有模型。
Docify(https://docify.ai4code.io/): 一个用于生成文档字符串的VS Code扩展。
Mintlify Writer(https://writer.mintlify.com/): 一个用于生成文档字符串的VS Code扩展。
持续集成机器人 Continuous integration bots
BitBuilder(https://www.bitbuilder.ai/): 一个用于从问题生成拉取请求的GitHub集成。
Sweep(https://sweep.dev/): 另一个用于从问题生成拉取请求的GitHub集成。
Code Review GPT(https://github.com/mattzcarey/code-review-gpt): 用于审查PR的开源工具。可以作为GitHub动作、Gitlab CLI或本地工具使用。
Nova(https://www.trynova.ai/): 一个用于为新的PR添加摘要和测试等操作的CI机器人。
CodeRabbit(https://coderabbit.ai/): 可定制的CI工具,用于为PR添加摘要和代码建议。
Code generation: 代码生成
- Magic(https://magic.dev/): 该公司承诺推出两款产品,一个助手和一个基于代码训练的底层基础模型LTM-1。等候名单。
智能体平台 Agent platforms
E2B(https://www.e2b.dev/): 用于托管基于LLM的代理的开源云平台。支持Smol Developer。
Morph Rift(https://github.com/morph-labs/rift): 开源的VS Code扩展,允许合并代码生成代理的输出。
SuperAGI(https://superagi.com/): 用于托管基于LLM的代理的开源平台,包括SuperCoder。
OpenAI插件 OpenAI plugins
ChatWithGit(https://gitsearch.sdan.io/): 允许ChatGPT搜索GitHub并返回相关存储库的链接。
Code ChatGPT Plugin(https://github.com/kesor/chatgpt-code-plugin): ChatGPT插件的开源示例,从文件目录中提取上下文。
搜索 Search
Bloop(https://bloop.ai/): 用于存储库的自然语言搜索。
Buildt(https://www.buildt.ai/): 用于存储库的自然语言搜索。
测试 Testing
OctoMind(https://octomind.dev/): 自动维护和生成的基于浏览器的端到端测试,集成到Github Actions,Azure DevOps等。
Traceloop(https://traceloop.com/): 利用开放遥测跟踪数据和生成的人工智能来提高系统可靠性。
Carbonate(https://carbonate.dev/): 使用自然语言进行端到端测试。与现有的测试套件集成(目前支持Jest,PHPUnit和Python的unittest)。
Meticulous.ai(https://www.meticulous.ai/): 自动生成、自动维护的端到端测试: 随着应用程序的发展,测试套件也随之演变。
DiffBlue(https://www.diffblue.com/): 为Java自动生成单元测试 ⋙ GitHub

使用AI工具「bloop」读懂「Webpilot」插件源码,再高效教会我
Webpilot 是一个浏览器插件,允许用户对网页内容进行自然语言提问,并自动生成回答。
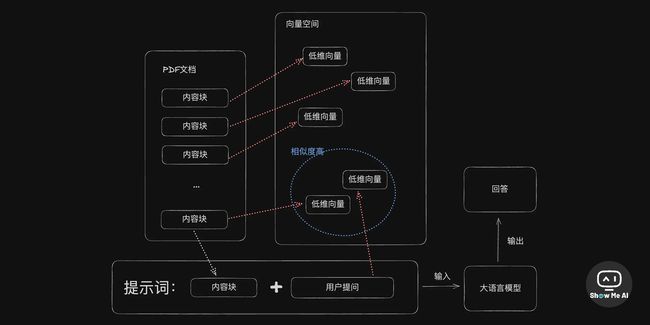
bloop是一个面向软件开发者的AIGC工具,可以回答关于代码库的问题,核心技术是 embeddings——将代码块映射为向量,然后检索向量之间关联度最强的内容来回答问题。但是 bloop 不了解代码之间的依赖关系,在提问时需要提供足够上下文,才能得到准确回答。
作者在这篇文章中展示了如何使用 bloop 工具来分析 Webpilot 的源码:通过逐步深入的技术思路,先用 bloop 对项目做整体的概述,然后再针对关键功能细节继续提问,逐步让 bloop 解释代码的具体逻辑。核心流程如下:
首先需要在 bloop 中绑定 Webpilot 的代码仓库,让 bloop 对代码进行向量化表示
然后可以就项目整体提出一个概述性问题,如"简单介绍下这个项目";这可以让 bloop 对项目有一个大致的了解
在得到项目简介后,可以询问一些关键功能的实现,如"与网页进行自由形式对话"是如何实现的;bloop会指出相关的代码位置
根据 bloop 提供的代码位置,可以继续询问该代码的详细作用和逻辑;bloop 会尝试解释代码含义
在理解了一个功能点后,可以继续问其他功能的实现代码在哪,并重复上述过程逐步深入
当对全部关键逻辑都进行了解析后,就可以比较系统地理解该项目的代码实现了
在提问时,需要提供足够具体的上下文信息,而不要只问一些过于概括的问题
如果bloop的回答不对或不全,需要修正提问方式提供更多上下文线索 ⋙ 思否@卡颂

为什么开发者应该多关注海外市场?
最近AI社区里「独立开发者」「大模型开发者」话题的关注度很高,也频频提到「出海」这个话题。这篇文章可以算是「开发者出海」相关内容的科普文,读完就大概能了解为什么大家都在关注这个方向。
不存在足够的空间给个人/小团队做独立产品存活。分析了Slack在美国成功上市,但在国内却难以存活。原因是BAT等巨头互相竞争,都想占领流量入口,不愿意有其它独立产品出现。国内生态封闭制约,不利于小团队参与竞争。
需求验证或者叫「试错」成本高。分析了国内要上线产品需要经过繁琐的审批、备案等程序,验证需求的门槛很高。而海外上线产品门槛低,可以快速试错验证需求。国内完成公司注册等流程也耗费大量精力和时间。
推广渠道少 && 门槛高。分析了国外有更多免费推广渠道如 ProductHunt 等,用户反馈真诚;国内推广渠道少,用户不友好。付费推广国内门槛高,但海外可以低成本推广。
商业化选择少。分析了国内用户习惯免费产品,不愿付费,盈利难。海外用户付费意愿强,小产品解决痛点也能获支付。付费用户更看重产品,免费用户难以满足 ⋙ 掘金@强生

斯坦福CS324「大语言模型 (LLM)」,好品质专题好课
语言模型的规模在快速增长,这不仅带来了全新的模型能力,对社会发展也产生了重大影响,而且也带来了可靠性不高、社会偏见、产生语气攻击、生成虚假信息等诸多风险。
CS324 - Large Language Models 是斯坦福 Winter 2022 的新课程,系统讲解了大语言模型的原理和开发,并深入探讨了上方的话题。通过这门课程的学习,学生可以对大型语言模型有全面的了解,掌握技术细节,并能对语言模型进行批判性思考。
Introduction
AI定义:让机器具有与人类相似的智能功能
语言具有创造力、组合性和交流性等特点
NLP发展历程:规则方法、统计方法、神经方法
神经网络崛起:计算能力提升,大规模标注数据
词向量捕获语义信息,seq2seq模型实现端到端学习
基础模型:可微、可优化的大规模预训练模型,适用于下游任务
GPT-3示范基础模型的潜力:通过提示完成各种下游任务
Capabilities
语言模型任务:预测文本的联合概率或下一个词
GPT-3在Penn Treebank语言建模任务上优于SOTA
GPT-3在LAMBADA长距离依赖语言建模任务上也优于SOTA
GPT-3在HellaSwag常识推理任务上接近SOTA
在问答任务上,GPT-3零样本表现不佳,少样本效果更好
GPT-3零样本机器翻译质量不高,少样本可达到SOTA
GPT-3可用于简单算术问题,但不“理解”数学
GPT-3可生成几乎无法区分的新闻文章
GPT-3可适应新词使用和纠正语法错误等新任务
Harms I
定义AI:智能因子、代理的集合
AI安全关键问题:价值观对齐、 interruptibility、透明度
价值观对齐:使AI行为符合人类价值观
可中断性:人类可随时停止/修改AI系统
透明度:人类可理解AI决策过程
狭义AI:专注特定任务,更易控制
强AI目标:具有人类水平跨领域智能
具体做法:强化学习、规范、监督
Harms II
性能差异:不同人群的准确率存在差异
社会偏见:生成文本带有刻板成见
引起伤害:生成攻击性内容
造假信息:生成误导性内容
内容审核:平衡言论自由和安全
缓解危害:数据处理、模型设计、部署监管
Data
数据获取:Common Crawl、社交媒体
数据处理:去重、分词、清洗
数据标注:Mechanical Turk、竞赛
弱监督:无标注数据的监督信号
自监督:从数据中自动构建监督信号
数据质量:覆盖范围、样本大小、注释质量
数据偏差:历史数据中的社会偏见
隐私:个人敏感信息泄露
版权:未经授权使用受版权保护数据
Security
模型逆向:从模型输出推断训练数据
成员推断:判断样本是否在训练数据中
数据提取:从模型内提取训练数据
毒化攻击:注入对模型产生不利影响的数据
欺骗攻击:对测试样本做微小变化来欺骗模型
后门攻击:使模型对特定触发输入产生错误输出
对抗防御:鲁棒性训练、差分隐私等方法
Legality
版权法:规定数据使用权利义务
合理使用:允许未经授权有限使用版权作品
隐私法:规定个人信息使用权利义务
其他法律:规范AI系统应用和部署
伦理规范:行业和组织自律守则
Modeling
分词:将文本切分为词单元
编码器:生成文本表示,适用于分类
解码器:顺序生成文本,适用于生成
编解码器:编码输入并解码输出
注意力:软查询表,实现全局依赖
Transformer:编码器解码器统一架构
位置编码:表示词在序列中的位置
Training
语言模型损失:最大化联合概率或交叉熵
预训练目标:遮蔽语言模型、下一句预测等
优化算法:SGD、Adam、mixed precision
学习率:warmup和降低学习率
正则化:dropout、weight decay
初始化:控制参数尺度,增加模型可训练性
Parallelism
数据并行:数据划分到不同计算节点
模型并行:模型划分到不同计算节点
流水线并行:不同模块串行计算
参数服务器:跨节点共享参数
分布式训练:协同高效地完成预训练
Scaling laws
模型规模:随着参数量增加,性能提升
数据规模:随着训练数据增多,性能提升
计算规模:随着FLOPs增加,性能提升
递减收益:扩展规模带来的收益递减
外推预测:预估未来性能提升趋势
建模规模法则:数学公式描述规模与性能关系
Selective architectures
混合专家:根据输入激活部分专家
稀疏混合专家:每个样本只使用少量专家
Switch Transformer:每个样本只使用一个专家 ⋙ 学习课程
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!