【Java】常见面试题:HTTP/HTTPS、Servlet、Cookie、Linux和JVM
文章目录
-
- 1. 抓包工具(了解)
- 2. 【经典面试题】GET和POST的区别:
- 3. URL中不是也有这个服务器主机的IP和端口吗,为啥还要搞个Host?
- 4. 补充
- 5. HTTP响应状态码
- 6. 总结HTTPS工作过程(经典面试题)
- 7. HttpServlet的核心方法
- 8. 【面试题】谈谈Servlet的生命周期?
- 9. Cookie
- 10. Linux中常用指令
- 11. JVM内存划分
- 12. JVM类加载
- 13. JVM垃圾回收机制GC
- 14. 怎么找垃圾(判定某个对象是否是垃圾)
- 15. 回收垃圾的策略
努力经营当下 直至未来明朗!
1. 抓包工具(了解)
- “抓包工具”:是个特殊的软件,相当于一个“代理程序”,浏览器给服务器的请求就会经过这个代理程序(响应也是经过该代理程序的),进一步的就能分析出请求和响应的结果如何。
- fiddler可以抓取http请求,也可以开启抓取https请求。
- HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议。
- 在浏览器中写一个URL也不一定要写端口号,如果不写就相当于默认访问http80端口,https是443端口。
2. 【经典面试题】GET和POST的区别:
1)先盖棺定论:GET和POST没有本质区别(即:GET和POST使用的场景基本可以相互代替)
2)细节上谈区别:
① 语义上:GET的语义是“从服务器获取数据”,POST的语义的“往服务器提交数据”
② 使用习惯上:给服务器传递的数据,GET通常是放在url的query string中的,POST通常是放在body中的。
③ **GET请求建议实现成“幂等”**的,POST一般不要求实现“幂等”。
(幂等:简单来说大概就是输入是确定的,输出结果也就是确定的,即输入一样时输出也是一致的)
【设计服务器的时候,就需要提供一些“接口/API”:API传入的参数就视为输入,API返回的结果就视为输出。
基于GET的API一般会建议设计成幂等的,基于POST的API则无要求(建议不要求一定要遵守)】
④ 在幂等的基础上,GET的请求结果是可以缓存的(浏览器默认行为);POST则一般不会缓存。
如果当前GET确实是幂等的,就不必处理,直接让浏览器缓存没问题;
但是如果当前的GET不是幂等的,就需要通过特殊技巧避免浏览器产生缓存(典型的技巧就是让每次GET请求的URL都不相同,通过特殊的query string来保证url不同)
3. URL中不是也有这个服务器主机的IP和端口吗,为啥还要搞个Host?
① 事实上,URL中的IP和端口 与 Host中的IP和端口不一定完全一样(当请求是经过代理来访问的时候可能不一样的,当然这一点在fiddler上没有体现出来)。
② 请求中的URL地址是经过的代理地址,而Host的地址是目标服务器的地址。
4. 补充
- HTTP协议在传输层是基于TCP的(至少在HTTP3.0之前是这样的,3.0就变成UDP了)
- UA主要包含的信息就是操作系统信息和浏览器信息,描述了用户在使用啥样的设备上网。
- Referer指的是当前页面是从哪个页面跳转过来的,也就是上级页面是啥。
- cookie:是浏览器在本地存储数据(存到硬盘上)的一种机制。
- Cookie是存在浏览器中的,但是来源是服务器,还要再回到服务器。
①当我们的浏览器访问了服务器之后,在服务器返回的响应报文中,可以在响应header中包含一个/多个Set-Cookie这样的资源,浏览器看到Set-Cookie就会把这些数据保存在浏览器本地(Set-Cookie是程序员在服务器代码中构造出来的)
②当浏览器保存了Cookie之后,下次浏览器访问同一个网站时,就会把之前本地存储的Cookie再通过http请求header中的Cookie给带过去。
③ 为啥要转一圈呢?因为服务器要服务的客户端是很多的,这些不同的客户端应该要有不同的数据。
(Cookie会占硬盘,但是空间不大,而且会有到期时间)
- 服务器生成一对非对称的密钥,客户端可以先从服务器拿到服务器的公钥,然后使用公钥对自己生成的对称密钥进行加密,此时由于外界只有公钥,私钥只是服务器自己所有的(黑客拿不到),所以只有服务器可以使用私钥对上述的请求进行解密。
- Tomcat是http服务器,本质上是一个TCP服务器,只不过是在基础上加上了一些按照http协议格式进行解析/构造 这样子的代码。
- web程序一旦出现问题,起手式就是“抓包”,通过抓包确定是前端问题还是后端问题。
5. HTTP响应状态码
- 404 Not Found
这是后端开发过程中常见的错误。
问题的原因有且只有一个,就是请求路径写错了。
请求里是有一个url的,url就表示你要访问的服务器上的资源的路径。如果你想要访问的资源在服务器上没有就会返回404。 - 403 Forbidden
访问被拒绝(就是没有权限访问) - 500 Internal Server Error
服务器内部错误,也就是服务器代码执行过程中出异常,即代码bug。 - 504 Gateway Timeout
访问超时,一般就是服务器请求量很大的时候,对于服务器的负荷就比较重了。 - 302 重定向
即:访问一个旧的URL就会自动跳转到新的URL上。 - 4xx:一般是客户端问题; 5xx:一般是服务器端。

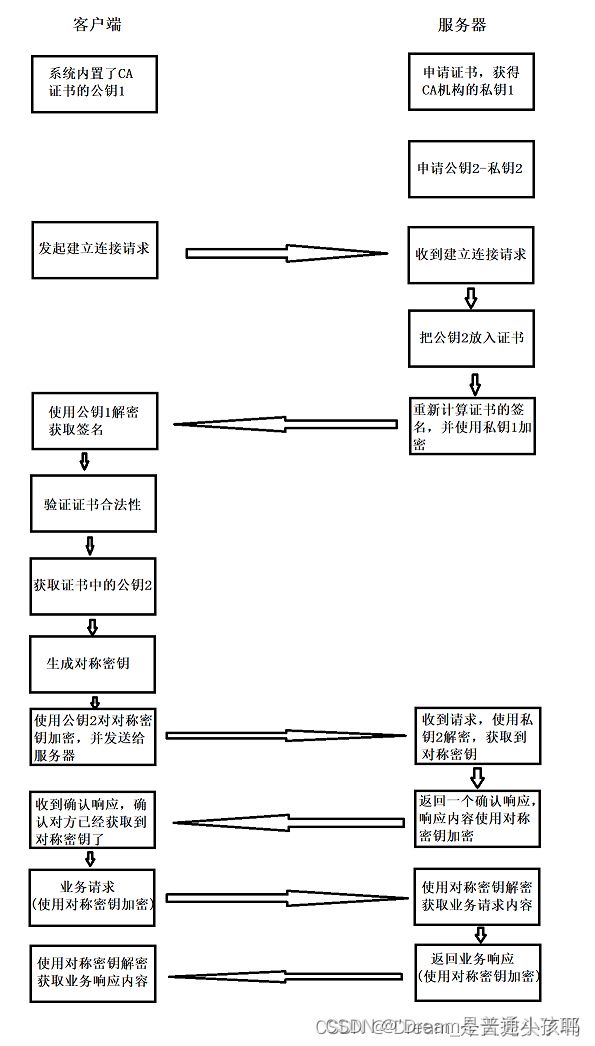
6. 总结HTTPS工作过程(经典面试题)
(https/http是一个应用层协议)
(CA是证书颁发机构)
可以参考:HTTPS工作过程
7. HttpServlet的核心方法

1)init:创建出HttpServlet实例会调用一次,其作用其实就是用来初始化。一般就是首次访问的时候会被实例化。
2)destroy:不一定能够调用到。因为HttpServlet不再调用其实就是在tomcat关闭时,关闭tomcat有两种方法:
① 直接杀进程:如点击idea中的红色方框、cmd直接点击x、通过任务管理器结束进程等,此时destroy无法被调用。
② 8005端口是用来控制tomcat的,通过该端口给tomcat发送一个关闭操作,此时tomcat就可以正常关闭,也就能够调用destroy了。
(工作中最常用的其实就是直接杀进程方式关闭,所以不太会调用到destroy方法)
3) service:tomcat收到请求之后实际上是先调用service方法,在service中根据方法来调用不同的doXXX方法。(实际开发中其实很少会重写service,重写doXXX方法就够了)
8. 【面试题】谈谈Servlet的生命周期?
- 生命周期:其实就是正确的时间干正确的事儿。
- 也就是回答:Servlet中有三个主要的方法:init、destroy、service,以及何时被调用:init在servlet被实例化的时候调用一次,destroy是在servlet销毁之前调用一次,service是每次收到请求调用(两次)。
9. Cookie
-
Cookie是浏览器在本地持久化保存数据的一种方案。
-
cookie是在浏览器这儿工作,session是在服务器那儿工作

-
Cookie 和 Session 的区别:
① Cookie 是客户端的机制,Session 是服务器端的机制.。
② Cookie 和 Session 经常会在一起配合使用,但是不是必须配合。
- 完全可以用 Cookie 来保存一些数据在客户端,这些数据不一定是用户身份信息,也不一定是token / sessionId
- Session 中的 token / sessionId 也不需要非得通过 Cookie / Set-Cookie 传递.
10. Linux中常用指令
- ls:即list,列出当前目录下都有啥
① ls 直接敲可以查看当前目录中的内容
② ls后面跟上具体的路径可以查看指定目录的内容
③ ls -l 可以以列表形式查看,可以缩写为ll
-
pwd 查看当前路径对应的绝对路径
-
cd 切换当前的工作目录
补充:
1) ctrl+l 就可以实现清屏
2)tab键补全:输入一个命令 or 输入一个目录,不必敲完整,只需要敲前几个部分,然后按tab键就可以触发补全。如果匹配结果只有一个就会立即补全,如果匹配结果有多个,按两下tab就会把可能的结果都列出来。
3)ctrl+c 重新输入: 如果命令或者目录敲错了, 可以 ctrl + c 取消当前的命令。
-
touch:创建一个空文件
如果是touch一个已经存在的文件,对文件的内容不会有任何的影响。(即:不会清空文件的内容) -
cat: 显示文件内容到控制台上
-
echo: 借助echo可以把想要的内容写到文件中
1)echo本来是一个回显/打印 操作
2)可以借助 > 这个重定向操作把显示到控制台的内容写到文件中
- echo 相当于把文件清空后重新写入
-
mkdir:创建目录
1)可以同时创建多个目录,使用空格进行分割
2)如果目录创建层次比较多,tree 命令就可以树形的展示当前目录结构(tree 后面加路径,如 tree . 就是针对当前目录展示树形结构) -
rm:删除文件 or 目录
1)删除文件:rm [文件名] -f// -f:不提示强制删除
2)删除目录: 需要指定-r选项(r 表示递归)rm -r [目录名]
3)可以通过history命令查看命令的历史记录
4)rm -rf / 这个操作是非常危险的,递归且不提示的进行删除 -
mv:move移动
mv [想要移动的文件] [目标文件/新的名字]
1)mv 还可以只改名不移动
2)mv可以移动整个目录 -
cp:copy复制
1)cp如果操作目录,此时就需要加上-r递归
cp [源目录] [目的目录] -r
2)cp 目的那儿文件名更改不更改都OK -
vim文本编辑器
在vim中按ctrl+z并不是退出!!按 ctr+z 其实vim并没有退出,只是放到后台了而已,随时按fg就能切换回来!! -
grep 文本查询
1)grep [字符串] [文件],字符串那儿可以不加引号
2)或者:| grep [字符串] -
ps 显示进程
ps 其实就相当于任务管理器
① 直接输入ps,显示的只是和当前终端相关的进程
② 需要使用 ps aux 就可以看到更完整的进程列表了,可以查看某个服务器的进程是否存在
③ 如果只想查看某些进程,也就是进行筛选操作:ps aux | grep xx -
netstat: 查看网络状态
尤其是可以用来查看某个进程绑定的端口如何,或者是查看某个端口是否被某个进程绑定.
①netstat -anp:查看网络连接状态
② 只想关注某个具体程序 or 端口 :就进行筛选,如netstat -anp | grep tcp -
用户操作
1)创建用户:useradd [用户名]
2)配置密码:passwd [用户名]
3)切换用户:su [用户名]
4)切换到超级用户:sudo su - -
修改文件权限
chmod [参数] 权限 文件名
11. JVM内存划分
- JVM也就是运行起来的java进程
- 区域划分:(java1.7之前)
① 堆:放的new的对象
② 方法区:放的是类对象(加载好的类)
③ 栈:放的是方法之间的调用关系
④ 程序计数器:放的是下一个要执行的指令的地址 - 区域划分实例
① 代码中的局部变量:栈
② 代码中的成员变量:堆
③ 代码中的静态变量:方法区 - 一个JVM进程中:堆和方法区只有一份,栈和程序计数器每个线程都有自己的一份。
- 区域划分(java1.8之后):
① 堆:放的new的对象
② 栈:放的是方法之间的调用关系
③ 程序计数器:放的是下一个要执行的指令的地址
④ 元数据区:用的是本地内存(JVM内部C++代码中搞的内存)
12. JVM类加载
-
类加载是干啥的?
① Java程序在运行之前需要先进行编译,也就是.java 文件编译为 .class文件(.class文件是二进制字节码文件);
② 运行的时候,java进程(JVM)就会读取对应的.class文件并且解析内容,在内存中构造出类对象并进行初始化。
③ 类加载其实就是把类从文件加载到内存中。 -
类加载的大体过程(谈谈 类加载 大概有哪几个环节,都是干啥的)
加载、连接(验证、准备、解析)、初始化
1)加载:
找到.class文件,读取文件的内容,并且按照.class规范的格式来解析
2)验证:
检查当前的.class里的内容格式是否符合要求
3)准备:给类里的静态变量分配内存空间。
如:static int a = 123; 准备阶段就是给a分配内存空间(int类型是4个字节),同时这些空间的初始情况全是0!
4)解析:初始化字符串常量,把符号引用(类似于占位符)替换成直接引用(类似于内存地址)。
① .class文件中会包含字符串常量(代码里很多地方也会使用到字符串常量)。
② 比如代码里有一行 String s = “hello”; 在类加载之前,“hello”这个字符串常量是没有分配内存空间的(得类加载完成之后才有内存空间);没有内存空间,s里也就无法保存字符串常量的真实地址,只能先使用一个占位符标记一下(这块是“hello”这个常量的地址),等真正给“hello”分配内存之后就可以使用这个真正的地址替代之前的占位符了。
5)初始化:针对类进行初始化,初始化静态成员,执行静态代码块,并且加载父类…
- 重点考察部分:双亲委派模型
1)双亲委派模型 只是决定了按照啥样的规则来在哪些目录里去找.class文件
2)类加载器:
1)JVM加载类是由类加载器(class loader)这样的模块来负责的。
2)JVM自带的类加载器主要有三个:
① Bootstrap ClassLoader:负责加载标准库中的类
② Extension ClassLoader:负责加载JVM扩展的库的类(语言规范里没有写,但是JVM给实现出来了)
③ Application ClassLoader:负责加载咱们自己的项目里的自定义的类
各自负责一个各自的片区(负责各自的一组目录),但是互相配合。
3)描述上述类加载器相互配合的工作过程就是双亲委派模型。
① 以上三种类加载器是存在父子关系的:

② 进行类加载的时候,输入的内容是 全限定类名,形如java.lang.Thread(也就是带有包名的类)
③ 加载的时候是从Application ClassLoader开始的
④ 某个类加载器开始加载的时候并不会立即扫描自己负责的路径,而是先把任务委派给 父 “类加载器” 来进行处理
⑤ 找到最上面的Bootstrap ClassLoader再往上就没有 父 类加载器了,此时就只能自己动手加载了,也就是开始扫描自己负责的路径
⑥ 如果父亲没有找到类,就交给自己的儿子继续加载
⑦ 如果一直找到最下面的Application ClassLoader也没有找到类,就会抛出一个“类没找到”异常,类加载就失败了。
按照这个顺序加载,最大的好处就在于如果程序员写的类,正好全限定类名和标准库中的类冲突了【比如自己写的类也叫做java.lang.Thread]】此时仍然可以保证类加载到标准库的类,防止代码加载错了带来问题。
13. JVM垃圾回收机制GC
- GC:程序员只需要申请内存,释放内存的工作就交给JVM来完成。JVM会自动判定当前的内存是啥时候需要释放的,认为内存不再使用了就会进行自动释放。
- 用GC最大的问题就在于引入额外的开销:时间(程序跑的慢)[GC中最大的问题就是STW问题[Stop The World],反应在用户这里就是明显卡顿] + 空间[消耗额外的CPU/内存资源]
(补:衡量GC好坏的重要指标之一就是STW问题) - GC主要就是针对堆来回收的。
- 一定要保证:彻底不使用的内存才能回收!宁可放过,不能错杀!
GC中回收内存不是以“字节”为单位,而是以“对象”为单位。

14. 怎么找垃圾(判定某个对象是否是垃圾)
- 在Java中,对象的使用需要 凭借引用。假如有一个对象,已经没有任何引用能够指向它了,这个对象自然就无法使用了。
- 判断某个对象是否为垃圾最关键的要点:通过引用来判定当前对象是否还能被使用,没有引用指向就视为是无法被使用了。
- 两种典型的判定对象是否存在引用的方法:
1)引用计数:[不是JVM采取的方法] (Python、PHP用这个)
① 给每个对象都加上一个计数器,这个计数器就表示“当前的对象有几个引用”。
② 每次多一个引用指向该对象,该对象的计数器就+1;
每次少一个引用指向该对象,该对象的计数器就-1。
③ 当引用计数器数值为0的时候,就说明当前这个对象已经无人能够使用了,此时就可以进行释放了。
④ 引用计数器的优点:简单,容易实现,执行效率也比较高。
⑤ 引用计数器的缺点:
-空间利用率比较低,尤其是小对象。比如计数器是个int,而你的对象本身里面只有一个int成员。
-可能会出现循环引用的情况。
2)可达性分析:[是JVM采取的方法](Java回收机制)
约定一些特定的变量,称为“GC roots”。每隔一段时间就从GC roots 出发进行遍历,看看当前哪些变量是能够被访问到的,能被访问到的变量就称为“可达”,否则就是“不可达”。
GC roots:
① 栈上的all变量
② 常量池引用的对象
③ 方法区中引用类型的静态变量
15. 回收垃圾的策略
① 标记清除
② 复制算法
③ 标记整理
④ 分代回收
-
标记清除
1)标记出垃圾之后,直接把对象对应的内存空间进行释放。
2)这种方式最大的问题:内存碎片!
也就是说:会导致整个内存“支离破碎”,如果想要申请一块连续的内存空间就申请不了,导致内存空间的浪费。
(申请的时候都是连续的内存空间)

-
复制算法
1)复制算法是针对“内存碎片”来提出的
2)复制算法不是原地释放,而是将“非垃圾”(可以继续使用的对象)拷贝到另一侧;然后将该侧的空间完全释放。
3)复制算法的缺点:
① 空间利用率更低了(用一半丢一半)
② 如果一轮GC下来,大部分对象要保留,只有少数对象要回收,此时复制开销就很大了

-
标记整理
1)类似于顺序表删除元素(搬运操作)。
即:将不是垃圾的对象往前搬运,可以直接占据垃圾的位置,最后就会形成一段连续使用的空间。
2)标记整理的方式相对于赋值算法来说:空间利用率提高了,也解决了空间碎片问题,但是搬运操作是比较耗时的!

-
分代回收
1)分代回收是根据对象的不同特点来进行回收的,特点是根据对象的年龄,即对象被GC扫描的轮次来计算的。
2)新生代中生存区之间是通过复制算法来实现的,老年代中的GC是通过标记整理来实现的。
