小红书信息流推荐多样性解决方案
文末有彩蛋,不要错过~
摘要:
来自小红书的研究者在多样化推荐中,从用户体验和系统应用的视角出发,提出了一种滑动频谱分解(SSD)的方法,该方法可以捕捉用户在浏览长序列时对多样性的感知。通过理论分析、离线实验和在线 A/B 测试,验证了该方法的有效性。
背景:
多样化的推荐(diversified recommendation)是推荐系统中一个重要的课题。从用户视角看,多样性(diversity)可以帮助他们扩展和发现新的兴趣,扎堆的内容则会令他们厌倦。从平台视角看,多样性可以帮助系统探索用户的喜好,防止越推越窄的情况,同时也可以让小众和长尾的内容得到曝光,促进发布生态。
小红书是一个拥有2亿月活用户的社区产品,在APP首页,我们以“发现Explore”来定义信息流推荐的场景,希望这个场景能够帮助用户发现感兴趣的内容,抑或是找到新的兴趣。在“发现”这一目标的驱动下,多样化的推荐(diversified recommendation)显得尤为重要。从算法角度来看,我们认为它由以下三个要素组成:质量(Quality)、多样性(Diversity)和公平性(Fairness)。
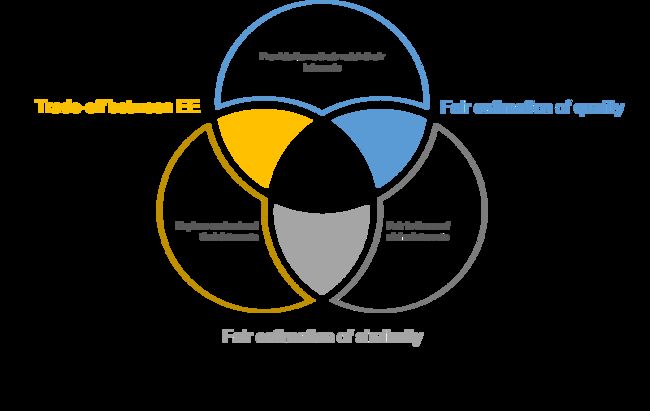
本文介绍的工作,也是小红书发表于KDD21的Sliding Spectrum Decomposition for Diversified Recommendation [1]一文,试图在信息流场景下研究多样性及其关联的问题。在信息流场景下,用户可以在Feed中进行持续的浏览,这会形成一个很长的浏览序列,另外受限于手机屏幕的大小以及短时记忆的影响,“窗口大小”也关乎浏览体验。

从第一性原理出发,我们试图从用户视角来理解这个问题。想象自己作为一台浏览机器,刷信息流就像是在观测一个一维的时间序列,每个时刻对应一篇Item。那如何描述序列中蕴含的多样性呢?不妨以经典时间序列分析中的价格波动为例,若定价由经营成本、季节因素和噪声三个独立的部分组成,如下图所示,那么分解的过程就是研究价格变化的关键。类比到推荐场景,如果我们能将Item序列分解成几个独立的部分,或许就能得到较好的多样性衡量。

Sliding Spectrum Decomposition (SSD):
出于上面的启发,我们将用户观测到的Feed序列,转换为下图所示的Tensor  :
:
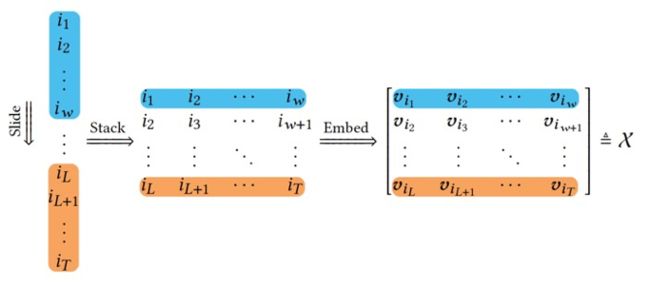
其中序列总长度为  ,用户浏览窗口大小为
,用户浏览窗口大小为 ,推荐的item序列为
,推荐的item序列为![]() ,滑动步长为1,
,滑动步长为1,![]() 为Item在向量空间中的表示。是一个三维的张量,直接研究它有些困难。我们不妨先考虑最为简单的情况:w = T = 2,即两个item向量如何分解成独立部分的问题。直观上,我们可以以空间上的正交方向来定义独立,如下图所示
为Item在向量空间中的表示。是一个三维的张量,直接研究它有些困难。我们不妨先考虑最为简单的情况:w = T = 2,即两个item向量如何分解成独立部分的问题。直观上,我们可以以空间上的正交方向来定义独立,如下图所示

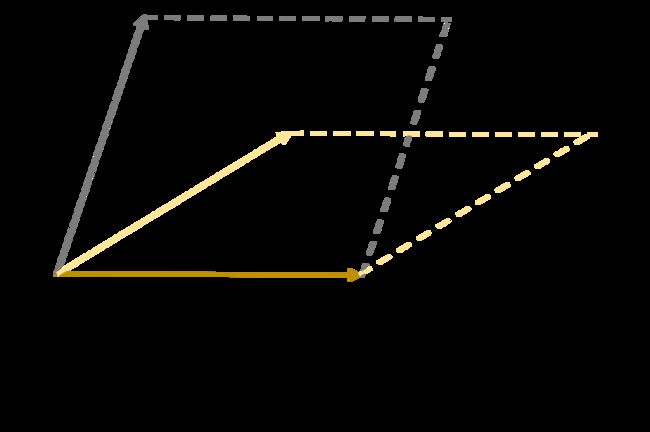
以 为底,我们可以计算
为底,我们可以计算![]() 与之重叠的部分以及正交的部分,正交的部分越大,意味着二者越独立,也就是多样性更好。只考虑2个Item,也就是在二维平面中,面积是一个很好的度量,如下图所示,与
与之重叠的部分以及正交的部分,正交的部分越大,意味着二者越独立,也就是多样性更好。只考虑2个Item,也就是在二维平面中,面积是一个很好的度量,如下图所示,与![]() 围成的平行四边形面积更大,于是他们组合的多样性也就更好。扩展到更一般的情况,我们可以用体积来计算一个窗口内Item的多样性。
围成的平行四边形面积更大,于是他们组合的多样性也就更好。扩展到更一般的情况,我们可以用体积来计算一个窗口内Item的多样性。
至此我们用体积定义了单一窗口的多样性,但多个窗口联合的体积是没有一个直观定义的,我们需要推广“体积”的概念。具体而言,一个窗口是Tensor退化至二维矩阵Matrix的情况,其体积的原始定义是行列式的值,然而一般Tensor的行列式没有一个统一的定义。考虑Matrix行列式的等价计算方式,奇异值的乘积,这一概念是可以作为代理扩展到Tensor的,类似的分解方式也常见于时间序列分析中 [4]。于是我们对Tensor做奇异值分解,将奇异值![]() 的乘积,作为了Tensor的体积,即多个窗口联合的多样性。与每篇Item的质量结合,我们即得到了如下的trade-off目标,其中
的乘积,作为了Tensor的体积,即多个窗口联合的多样性。与每篇Item的质量结合,我们即得到了如下的trade-off目标,其中 是候选集合,
是候选集合, 是一个平衡系数。
是一个平衡系数。

在这里我们以EE的方式来组合Quality和Diversity,在实际应用中,Quality更多的是以精排模型打分为基础,是以过去经验来判断的Exploitation,多样性则是基于内容相似度的分数,在不考虑个性化的情况下,多样性可以理解为是一种Exploration。
与SSD最相近的工作是DPP。DPP本是物理中用于描述粒子随机过程的概率框架,全程determinantal point process,基于体积来描述粒子的扩散程度(多样性)。回忆体积的物理意义,体积这一概念其实是无关乎顺序的。在基于DPP的多样化推荐中,是贪心求解过程赋予了顺序 [3],而SSD在Tensor构造中就引入了顺序这一概念,当Tensor退化成Matrix时即可得到DPP的结果,因此SSD可以看做是DPP在序列推荐上的一种推广。另一方面,在Diversity与Quality的组合上,SSD和DPP也有明显的不同,DPP延续了体积的概念,将Quality作为向量的boost系数,即体积中的因子来融合,而SSD更推荐用EE的组合方式,我们认为EE更符合用户的浏览诉求。除此之外,在窗口的处理上,DPP本身定义上不存在窗口的概念,因此在求解过程中会完全忽略掉窗口外的内容,这在长序列中是很不符合用户感知的,SSD通过Tensor的构造引入了体积的概念,虽然在原始定义上需要求解NP-hard的Tensor SVD,但我们在[1]中给出了一种近似的贪心求解,最终的复杂度会优于基于DPP的工作。

Content-based to Collaborative Filter:
在多样性定义中,我们依赖于Item的向量表示来计算体积,向量之间两两之间的相似性需要能够符合用户对于多样性的感知,也需要考虑最开始我们提到的公平性。有两种直观的思路来得到这些向量。一是content-based方法,即我们构造一个基于图片和文字内容的监督任务,将监督模型的中间层结果作为向量表示。二是基于协同过滤方法,即我们通过全体用户的交互历史,构造CF向量。

然而在实际应用中,单纯使用这两种方法都有一定的缺陷。Content-based的方法依赖于大量的先验知识,效果往往不如CF,而基于协同过滤的方法对于长尾兴趣和新内容却非常不友好,在计算相似度上可能没那么公平。于是我们设计了上图所示的Content-based to Collaborative Filter(CB2CF)方法,通过content信息预估协同过滤的结果。在输入上仅使用内容,这样即使对于新内容也能依赖模型的泛化能力得到较好的结果。在输出上依赖全体用户的协同标注,使得我们能够在统计上学习用户感知的信号。
这里我们也与过去工作做一个简单的对比,CB2CF的思想源于微软19年发表在RecSys上的工作 [2]。[2]中推荐的训练方式是以CB向量直接预测CF向量,最终以两个CF向量的差异作为loss。我们则更推荐以距离的方式先度量CB向量转换后的结果,最终以likelihood的方式构造loss。
实验效果:
在离线实验中,我们对比了CF和CB2CF在长尾上的表现。在四个高区分度的类目下,我们可以看到CB2CF有着较好的区分能力。
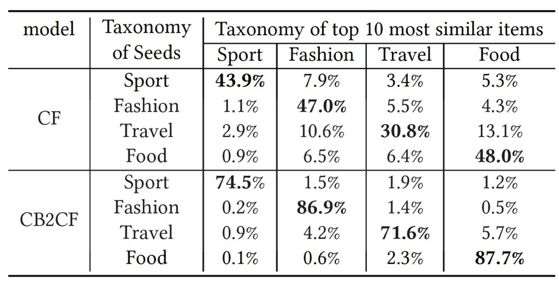
在线上实验中,我们用SSD与SOTA的DPP模型做了A/B实验,在时长(Time)、互动(Engage)、ILAD(用户浏览Item之间的平均距离,即曝光多样性)、MRT(用户平均阅读类目数,即消费多样性)上都取得了一定的收益。

论文链接:https://arxiv.org/abs/2107.05204
参考文献:
-
Huang, Yanhua, et al. "Sliding Spectrum Decomposition for Diversified Recommendation." Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021.
-
Barkan, Oren, et al. "CB2CF: a neural multiview content-to-collaborative filtering model for completely cold item recommendations." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
-
Chen, Laming, Guoxin Zhang, and Eric Zhou. "Fast greedy map inference for determinantal point process to improve recommendation diversity." Advances in Neural Information Processing Systems 31 (2018).
-
Broomhead, David S., and Gregory P. King. "Extracting qualitative dynamics from experimental data." Physica D: Nonlinear Phenomena 20.2-3 (1986): 217-236.
招聘信息
小红书目前在算法和工程上都有着很多有趣并富有挑战的问题。除了推荐多样性外,我们还在召回、排序、强化学习、图神经网络、CV、NLP等多个方向进行着持续探索和落地。
岗位职级、薪水open,base上海/北京。
欢迎感兴趣的朋友发送简历至:[email protected],
并抄送至:[email protected]、[email protected]。
惊喜彩蛋
论文太艰深读不透怎么办?专家带你一起看。
关注小红书技术团队公众号,回复关键词『KDD21论文』,即可获得由【小红书基础模型团队负责人王树森】批注的论文全文,围观技术专家如何阅读与解读论文~