SpringCloud(9)— Elasticsearch聚合和自动补全
SpringCloud(9)— Elasticsearch聚合和自动补全
一 数据聚合
1.聚合的分类
聚合(aggregations)可以实现对文档数据的统计,分析,运算。常见的聚合有三种:
1.桶聚合(Bucket)
text 不支持 桶聚合
桶聚合(Bucket)用来对文档做分组,其中比较常见的有:
- TermAggregation:按照文档的字段值进行分组,类似 MySql 中的 group by
- Date Histogram:按照日期阶梯分组,例如 一周或者一月 为一组
2.度量聚合(Metric)
text 和 keyword 不支持 度量聚合
度量聚合用于计算一些值,比如最大值,最小值,平均值等。常见的有:
- Avg:平均值
- Max:最大值
- Min:最小值
- Sum:求和
- Stats:同时求 Avg, Max, Min, Sum 等
3.管道聚合(pipeline)
管道聚合以其他聚合的结果为基础做聚合
参与聚合的字段类型,不能是 text 类型
一般为 keyword,date,bool,integer 等
2.DSL实现Bucket聚合
以下是语法示例:
GET /【indexName】/_search
{
"size":"分页值,默认为10,只做聚合不做数据分页时设置为0,则只会返回聚合结果而不会返回文档",
"aggs": {
"聚合名称,可自定义": {
"聚合类型,一般为 terms": {
"field": "字段名",
"size": 返回的数据量
}
}
}
}
默认情况下,Bucket 聚合会统计文档数量记为 _count,且按照 _count 进行倒序排序。
如果需要修改的话,则只需要增加 order 属性,并设置排序规则即可
以下是以 brand 为例的聚合示例:
GET /hotel/_search
{
"size":0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order":{
"_count":"asc"
}
}
}
}
}
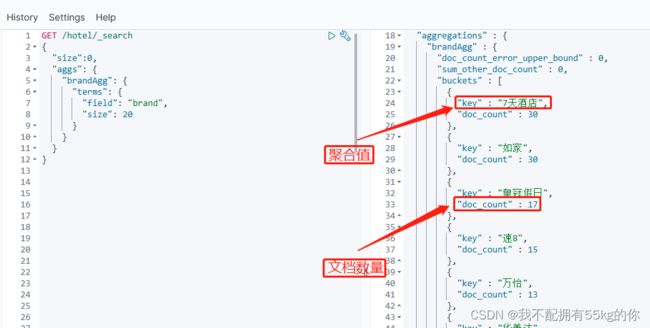
默认情况下,Bucket 聚合是对索引库的所有文档做聚合,对内存的消耗非常大。
我们可以通过增加 query 限定聚合的文档范围。
例如,只对 价格(price) 在 200-300 范围内的数据做聚合:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 200,
"lte": 300
}
}
},
"size":0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order":{
"_count":"asc"
}
}
}
}
}
3.DSL实现 Metrics 聚合
利用 Stats 聚合,获取指定字段的各项度量值
GET /hotel/_search
{
"size":0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs":{ //是 brandAgg 聚合后的子聚合,也就是分组后对每组分别计算
"score_stats":{ //聚合名称
"stats": { //聚合类型,此处可以是 min,max,avg等
"field": "score" //聚合的字段值,只能是数值类型,因为只有数组可以进行加减乘除
}
}
}
}
}
}
DSL 示例:
GET /hotel/_search
{
"size":0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs":{
"score_stats":{
"stats": {
"field": "score"
}
}
}
}
}
}
运行 DSL 代码,得到下图右侧的结果,利用 stats 同时计算出了最大值,最小值,和值,平均值以及数量。
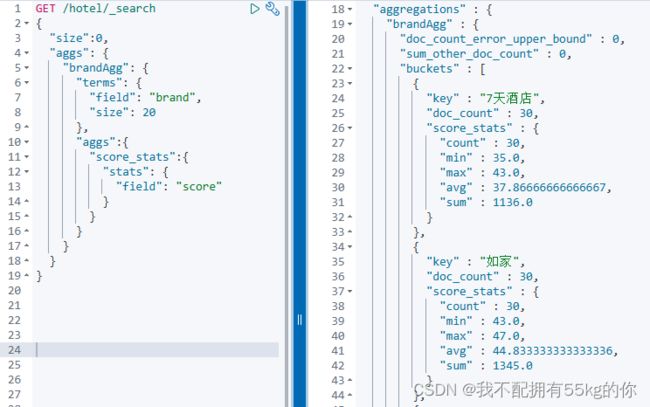
此时如果想要对按照聚合之后的值排序,则应当使用 score_stats 中的属性来定义。
例如,按照 score 的最大值进行排序
GET /hotel/_search
{
"size":0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"score_stats.max": "desc"
}
},
"aggs":{
"score_stats":{
"stats": {
"field": "score"
}
}
}
}
}
}
4.RestClient实现聚合
先参考以下对照图
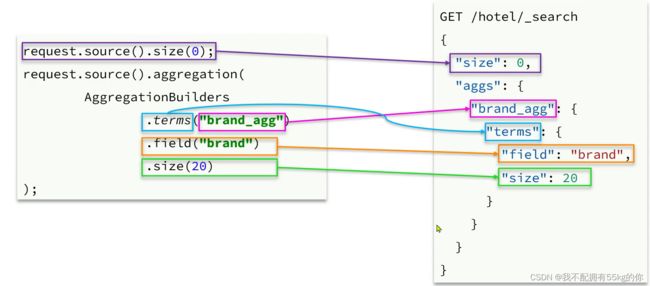
以下是测试示例:
@Test
public void testAggregationBrand() throws IOException {
//1.创建 SearchRequest 对象,指定索引库名称
SearchRequest request = new SearchRequest("hotel");
//2.去掉文档数据
request.source().size(0);
request.source().aggregation(
AggregationBuilders
//设置聚合类型为 term,且为聚合起名
.terms("brandAgg")
//设置需要聚合的字段
.field("brand")
//设置返回的数据量
.size(20)
//设置排序,
.order(BucketOrder.aggregation("_count",true))
);
//3.发送请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//获取全部聚合结果
Aggregations aggregations = response.getAggregations();
//根据 聚合名称 获取聚合结果
Terms brandTerms = aggregations.get("brandAgg");
//获取桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//遍历数据
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
Long docCount = bucket.getDocCount();
System.out.println(brandName+","+docCount);
}
}
需要注意:使用 AggregationBuilders 来构建一个 aggregation 对象
二 自动补全
1.拼音分词器的使用
GitHub地址:elasticsearch-analysis-pinyin
安装步骤:
- 下载指定版本(与 es 版本保持一致,文档使用 v7.12.1)的 elasticsearch-analysis-pinyin
- 解压并上传至 es 容器挂载插件的目录(与 ik分词器 同一个目录)
- 重启 es 容器
- 测试
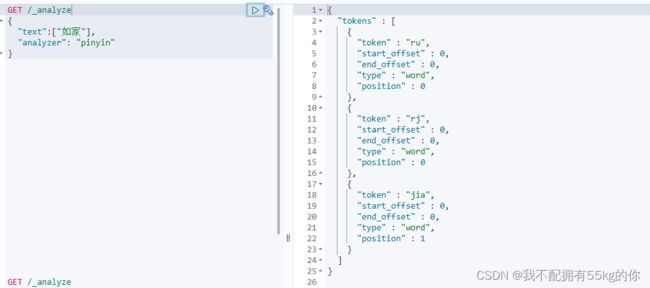
GET /_analyze
{
"text":["如家"],
"analyzer": "pinyin"
}
返回一下结果说明分词器安装成功,且成功分词
2.自定义分词器
1.分词器的构成
- character filters:在 tokenizer 之前对文本进行处理,例如 删除字符,替换字符等
- tokenizer:将文本按照一定的规则切割成词条(term),例如 keyword。
- tokenizer filter:将 tokenizer 输出的词条做进一步的处理,例如大小写转换,同义词处理,拼音处理等

自定义分词器时不一定三部分都需要。根据实际业务需求即可。例如以下示例,只有 tokenizer 和 filter两部分,并没有 character
2.自定义分词器的实现
在创建索引库时,通过 settings 来配置自定义的 analyzer(分词器)
因为自定义分词器是在创建索引库时指定,所以自定义分词器只针对当前的索引库生效
以下是语法示例:
PUT /【indexName】
{
"settings": {
"analysis": {
"analyzer": {
"自定义分词器的名称":{
"tokenizer":"分词器名称",
"filter":"分词器名称"
}
}
}
}
}
实现示例:
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"pinyin"
}
}
}
}
}
以上这种默认实现会将汉字分为一个一个的拼音,这并非我们想要的。参考文档,设置其他相关参数。
以下是实现示例:
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter": {
"py":{
"type":"pinyin", // 使用拼音分词器,以下为拼音分词器的部分参数设置
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
}
}
- my_analyzer:自定义的分词器名称
- py:自定义的分词器名称
3.拼音分词器注意事项
拼音分词器是和在创建倒排索引时使用,但不能在搜索时使用(会搜到同音词),因此字段在创建索引时应该使用创建的分词器,字段在搜索时应该使用 ik_smart 分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter": {
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
3.自动补全查询
1.Completion Suggester
elasticsearch 提供了 Completion Suggester 查询来实现自动补全,这个查询会匹配以用户输入的内容开头的词条并返回。
为了提高查询提高效率,需要堆文档中的字段做一些约束:
- 要求查询字段必须为 completion 类型
- 字段的内容一般是用来补全的多个词条形成的数据

2.语法示例
GET /test/_search
{
"suggest": {
"自定义suggest名称": {
"text": "YOUR TEXT",
"completion":{
"field":"字段名", // 补全查询的字段
"skip_duplicates":true, //跳过重复的
"size":10 // 获取前10条结果
}
}
}
}
三 实现搜索的自动补全
1.修改原有的数据结构
使用自定义分词器,并且增加 suggestion 字段,用于实现自动补全
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
},
"completion_analyzer":{
"tokenizer":"keyword",
"filter":"py"
}
},
"filter": {
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
},
"all":{
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart"
},
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"copy_to": "all",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "double"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword",
"copy_to": "all"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"isAD":{
"type": "boolean"
}
}
}
}
2.重新导入数据
修改实体类与文档的对应关系,重新导入数据
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
/**
* 新增自动补全字段
*/
private List<String> suggestion;
/**
* 广告
*/
public Boolean isAD;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + "," + hotel.getLongitude();
this.pic = hotel.getPic();
//处理广告字段(isAD)格式
if (hotel.getIsAD() == 1) {
this.isAD = true;
} else {
this.isAD = false;
}
//处理自动补全信息
List<String> list =new ArrayList<>();
list.add(hotel.getName());
list.add(hotel.getBrand());
//商圈信息含有"/"时视为多个,做切割处理
String business = hotel.getBusiness();
if (business.contains("/")) {
String[] businessArr = business.split("/");
Collections.addAll(list,businessArr);
}
this.setSuggestion(list);
}
}
导入数据完成,使用 DSL 语句进行测试
GET /hotel/_search
{
"suggest": {
"textSuggestion": {
"text": "s",
"completion": {
"field": "suggestion",
"skip_duplicates":true,
"size":10
}
}
}
}
3.RestClient实现自动补全
先看格式对照
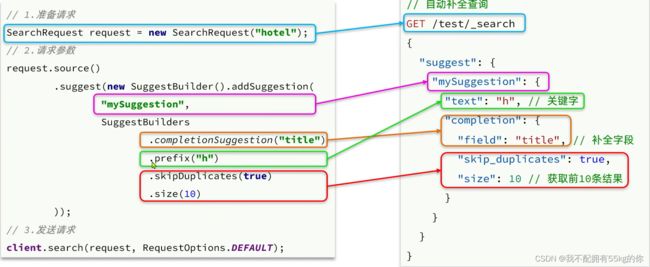
编写测试代码,实现自动补全
@Test
void testSuggestion() throws IOException {
//1.创建 SearchRequest 对象
SearchRequest searchRequest=new SearchRequest("hotel");
//2.构造 DSL 语句
searchRequest.source().suggest(
new SuggestBuilder().addSuggestion("textSuggestion",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("bj")
.skipDuplicates(true)
.size(10)
));
//3.发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//4.处理数据
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion= suggest.getSuggestion("textSuggestion");
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
String text = option.getText().toString();
System.out.println(text);
}
}
解析结果实际按照Json格式去逐层解析:

四 数据同步
- elasticsearch中的数据来源于数据库,因此数据库发生改变时, es 中的数据必须也跟着变。这就是 es 和数据库之间的同步问题
- 在微服务项目中,不同的业务一般运行在不同的服务器上,该如何解决?
1.同步调用
优缺点:
实现简单,粗暴。但是业务耦合度高

2.异步调用
优缺点:
低耦合,实现难度一般。但是过于依赖MQ的可靠性

3.监听binlog
优缺点:
耦合度完全解除。但是开启之后mysql的负担增加,且实现复杂度高

2022-12-28,增加 第四节 数据同步
完结撒花!!!