Day67_Spark(二)Spark RDD操作
| 课程大纲 |
课程内容 |
学习效果 |
掌握目标 |
| Spark执行流程 |
Wordcount执行流程 |
掌握 |
|
| Spark作业提交流程 |
掌握 |
||
| RDD操作 |
RDD初始化 |
掌握 |
|
| RDD操作 |
掌握 |
||
| 变量 |
掌握 |
||
| 排序 |
高级排序 |
掌握 |
一、Spark执行流程
在上一讲中,我们知道了什么是Spark,什么是RDD、Spark的核心构成组件,以及Spark案例程序。在这一讲中,我们将继续需要Spark作业的执行过程,以及编程模型RDD的各种花式操作,首先来学习Spark作业执行流程。
(一)、WordCount执行流程
1、WordCount执行流程图
Wordcount执行流程入图2-1所示。
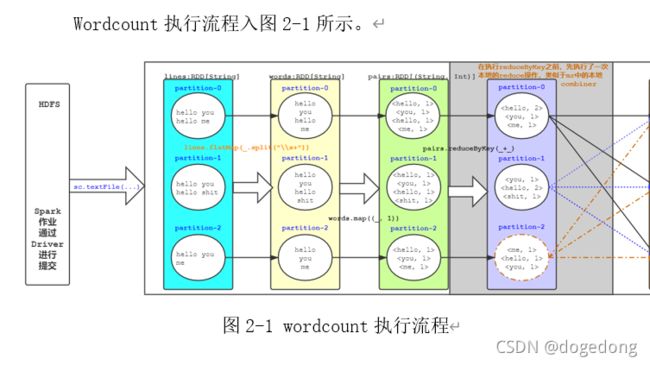
2、归纳总结
在上图中我们可以看到rdd(partition)和rdd之间是有依赖关系的,大致分为两种:窄依赖(Narrow Dependency)和宽依赖(Wide/Shuffle Dependency)。
- 窄依赖:rdd中partition中的数据,只依赖于父rdd中的一个分区,把这种依赖关系,称之为窄依赖,常见的窄依赖操作有:flatMap、map、filter、union、coalesce等等。
- 宽依赖:与窄依赖对应的,partition中的数据,依赖于父rdd中所有的partition,把这种依赖关系称之为宽依赖,常见的宽依赖操作:distinct、reduceByKey、groupByKey、repartition等等。
总而言之,rdd和rdd是有依赖关系的,我们把rdd和rdd之间关系构成的一个图或者依赖的链条,称之为为rdd的lineage(血统),是保障spark容错的一个重要支撑。
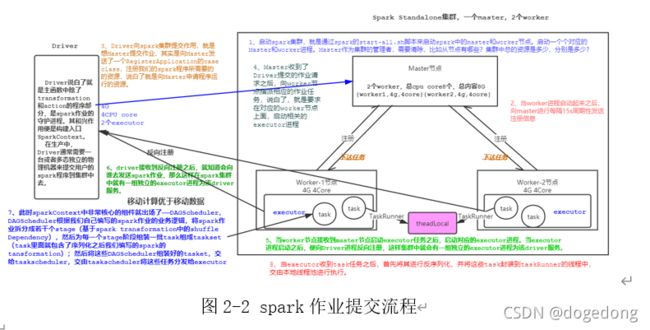
(二)、Spark作业提交流程
下面我们一同来看spark作业提交流程,流程如图2-2所示。
二、RDD的基本操作
(一)、RDD概述
在较高的层次上,每个Spark应用程序都由一个驱动程序组成,该驱动程序运行用户的主功能并在集群上执行各种并行操作。Spark提供的主要抽象是一个弹性分布式数据集(RDD),它是一个跨集群节点划分的元素集合,可以并行操作。RDD是从Hadoop文件系统(或任何其他支持Hadoop的文件系统)中的一个文件或驱动程序中现有的Scala集合开始创建的,并对其进行转换。用户还可以要求Spark将RDD持久化在内存中,这样就可以跨并行操作高效地重用RDD。最后,RDD会自动从节点故障中恢复。
1、RDD操作算子分类
需要知道RDD操作算子的分类,基本上分为两类:transformation和action,当然更加细致的分,可以分为输入算子,转换算子,缓存算子,行动算子,整个RDD原生数据空间如下图2-3所示。
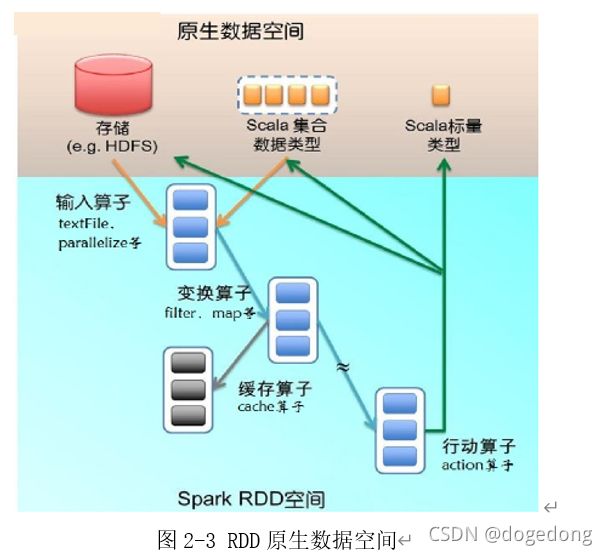
- 输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
- 运行:在Spark数据输入形成RDD后便可以通过转换算子,如filter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。 如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
- 输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
2、RDD初始化
RDD的初始化,原生api提供的2中创建方式,一种就是读取文件textFile,还有一种就是加载一个scala集合parallelize。当然,也可以通过transformation算子来创建的RDD。
(二)、RDD操作
(1)map算子:
说明
rdd.map(p: A => B):RDD,对rdd集合中的每一个元素,都作用一次该func函数,之后返回值为生成元素构成的一个新的RDD。
总结:map操作是一个one-2-one的操作。
编码
对rdd中的每一个元素×7
val sc = new SparkContext(conf)
//map 原集合*7
val list = 1 to 7
//构建一个rdd
val listRDD:RDD[Int] = sc.parallelize(list)
// listRDD.map((num:Int) => num * 7)
// listRDD.map(num => num * 7)
val ret = listRDD.map(_ * 7)
ret.foreach(println)
(2)flatMap算子:
a. 说明
rdd.flatMap(p: A => 集合):RDD ==>rdd集合中的每一个元素,都要作用func函数,返回0到多个新的元素,这些新的元素共同构成一个新的RDD。所以和上述map算子进行总结:
flatMap操作是一个one-2-many的操作
b. 编码
案例:将每行字符串,拆分成一个个的单词
def flatMapOps(sc:SparkContext): Unit = {
val list = List(
"jia jing kan kan kan",
"gao di di di di",
"zhan yuan qi qi"
)
val listRDD = sc.parallelize(list)
listRDD.flatMap(line => line.split("\\s+"))
.foreach(println)
}
(3)mapPartitions算子:
a.说明
mapPartitions(p: Iterator[A] => Iterator[B]),上面的map操作,一次处理一条记录;而mapPartitions一次性处理一个partition分区中的数据。
注意:虽说mapPartitions的执行性能要高于map,但是其一次性将一个分区的数据加载到执行内存空间,如果该分区数据集比较大,存在OOM的风险
b. 编码
//创建RDD并指定分区数
val rdd: RDD[Int] = sc.parallelize(Array(1,2,3,4),2)
//通过-将分区之间的数据连接
val result: RDD[String] = rdd.mapPartitions(x=>Iterator(x.mkString("-")))
//打印输出
println(result.collect().toBuffer)
(4)mapPartitionsWithIndex算子:
a.说明
mapPartitionsWithIndex((index, p: Iterator[A] => Iterator[B])),该操作比mapPartitions多了一个index,代表就是后面p所对应的分区编号。
rdd的分区编号,命名规范,如果有N个分区,分区编号就从0,...,N-1。
b. 编码
val rdd: RDD[Int] = sc.parallelize(1 to 16,4)
//查看每个分区当中都保存了哪些数据
val result: RDD[String] = rdd.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(",")))
//打印输出
result.foreach(println)
(5)sample算子:
a.说明
sample(withReplacement, fraction, seed):随机抽样算子,sample主要工作就是为了来研究数据本身,去代替全量研究会出现类似数据倾斜(dataSkew)等问题,无法进行全量研究,只能用样本去评估整体。
withReplacement:Boolean :有放回的抽样和无放回的抽样
fraction:Double:样本空间占整体数据量的比例,大小在[0, 1],比如0.2, 0.65
seed:Long:是一个随机数的种子,有默认值,通常不需要传参
需要说明一点的是,这个抽样是一个不准确的抽样,抽取的结果数可能在准确的结果上下浮动。
b. 编码
def sampleOps(sc: SparkContext): Unit = {
val list = sc.parallelize(1 to 100000)
val sampled1 = list.sample(true, 0.01)
println("sampled1 count: " + sampled1.count())
val sampled2 = list.sample(false, 0.01)
println("sampled2 count: " + sampled2.count())
}
takeSample
(6)union算子:
a.说明
rdd1.union(rdd2)
相当于sql中的union all,进行两个rdd数据间的联合,需要说明一点是,该union是一个窄依赖操作,rdd1如果有N个分区,rdd2有M个分区,那么union之后的分区个数就为N+M。
b. 编码
val value = sc.parallelize(List(1, 2, 3), 3)
val value1 = sc.parallelize(List(4, 5, 6), 3)
println(value.getNumPartitions)
println(value1.getNumPartitions)
val value2 = value.union(value1)
value2.mapPartitionsWithIndex((y,x)=>Iterator(y+" "+x.mkString("-"))).foreach(println)
println(value2.collect().toBuffer)
println(value2.getNumPartitions)(7)join算子:
a.说明
rdd1.join(rdd2) 相当于sql中的join连接操作
A(id) a, B(aid) b
select * from A a join B b on a.id = b.aid
交叉连接: across join
select * from A a across join B ====>这回产生笛卡尔积
内连接: inner join,提取左右两张表中的交集
select * from A a inner join B on a.id = b.aid 或者
select * from A a, B b where a.id = b.aid
外连接:outer join
左外连接 left outer join 返回左表所有,右表匹配返回,匹配不上返回null
select * from A a left outer join B on a.id = b.aid
右外连接 right outer join 刚好是左外连接的相反
select * from A a left outer join B on a.id = b.aid
全连接 full join
全外连接 full outer join = left outer join + right outer join
前提:要先进行join,rdd的类型必须是K-V
对join操作可以归纳为如下图2-4所示。

b. 编码
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd1: RDD[(Int, String)] = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
val rdd2: RDD[(Int, Int)] = sc.parallelize(Array((1,4),(2,5),(5,6)))
//join操作
val result: RDD[(Int, (String, Int))] = rdd1.join(rdd2)
//打印输出
println(result.collect().toBuffer)
//leftOutJoin操作
val result1: RDD[(Int, (String, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
//打印输出
println(result1.collect().toBuffer)
//rightOuterJoin
val result2: RDD[(Int, (Option[String], Int))] = rdd1.rightOuterJoin(rdd2)
//打印输出
println(result2.collect().toBuffer)
//fullOuterJoin
val result3: RDD[(Int, (Option[String], Option[Int]))] = rdd1.fullOuterJoin(rdd2)
//打印输出
println(result3.collect().toBuffer)
}(8)coalesce算子:
- 说明
coalesce(numPartition, shuffle=false): 分区合并的意思
numPartition:分区后的分区个数
shuffle:此次重分区是否开启shuffle,决定当前的操作是宽(true)依赖还是窄(false)依赖
原先有100个分区,合并成10分区,或者原先有2个分区,重分区之后变成了4个。
coalesce默认是一个窄依赖算子,如果压缩到1个分区的时候,就要开启shuffle=true,此时coalesce是一个宽依赖算子
如果增大分区,shuffle=false,不会改变分区的个数,可以通过将shuffle=true来进行增大分区
可以用repartition(numPartition)来进行代替= coalesce(numPartitions, shuffle = true)
编码
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val rdd = sc.parallelize(1 to 16,4)
//获取分区数
println(rdd.getNumPartitions)
//查看每个分区当中保存了哪些数据
rdd.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
//缩减分区
val rdd1: RDD[Int] = rdd.coalesce(3)
//获取分区数
println(rdd1.getNumPartitions)
//查看每个分区当中保存的数据变化
rdd1.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
//释放资源
sc.stop()
}
println(rdd.getNumPartitions)
val value = rdd.mapPartitionsWithIndex((index, item) => Iterator(index + " " + item.mkString("-")))
value.foreach(println)
println(value.collect().toBuffer)
// val value1 = rdd.coalesce(3,true)
// val value1 = rdd.repartition(3)
val value1 = rdd.repartition(5)
println(value1.getNumPartitions)
value1.mapPartitionsWithIndex((index, item) => Iterator(index + " " + item.mkString("-"))).foreach(println)
(9)repartition(numPartitions)
a.说明
根据分区数,重新通过网络随机洗牌所有数据。
编码
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
//设置控制台日志级别
sc.setLogLevel("WARN")
val rdd = sc.parallelize(1 to 16,4)
//获取分区数
println(rdd.getNumPartitions)
//查看每个分区当中保存了哪些数据
rdd.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
//缩减分区
val rdd1: RDD[Int] = rdd.repartition(3)
//获取分区数
println(rdd1.getNumPartitions)
//查看每个分区当中保存的数据变化
rdd1.mapPartitionsWithIndex((index,item)=>Iterator(index+":"+item.mkString(","))).foreach(println)
//释放资源
sc.stop()
}
(10)sortBy(func,[ascending], [numTasks])
说明
用func先对数据进行处理,按照处理后的数据比较结果排序
编码
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo").setMaster("local[*]")
val sc = new SparkContext(conf)
//设置控制台日志输出级别
sc.setLogLevel("WARN")
//加载数据
val rdd= sc.parallelize(List(("a",4),("c",2),("b",1)))
//默认是升序排序,指定false,转为倒叙输出
val rdd1: RDD[(String, Int)] = rdd.sortBy(_._2,false)
//收集结果,返回数组输出
println(rdd1.collect().toBuffer)
}
val rdd = sc.parallelize(List(("a", 4), ("c", 5), ("b", 1)))
println(rdd.getNumPartitions)
rdd.mapPartitionsWithIndex((index, item) => Iterator(index + " " + item.mkString("-"))).foreach(println)
val value = rdd.sortBy(x => x._1,false,3)
println(value.collect().toBuffer)
(11)sortByKey([ascending], [numTasks])
说明
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("demo").setMaster("local[*]")
val sc = new SparkContext(conf)
//设置控制台日志输出级别
sc.setLogLevel("WARN")
//加载数据
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//默认按照key进行升序输出,加false,转为倒叙输出
val result: RDD[(Int, String)] = rdd.sortByKey(false)
//收集结果,返回数组输出
println(result.collect().toBuffer)
}
(12)groupByKey算子:
a.说明
groupByKey(numPartition):[K, Iterable[V]]
按照key来进行分组,numPartition指的是分组之后的分区个数。
这是一个宽依赖操作,但是需要注意一点的是,groupByKey相比较reduceByKey而言,没有本地预聚合操作,
显然其效率并没有reduceByKey效率高,在使用的时候如果可以,尽量使用reduceByKey等去代替groupByKey。
groupBy其实就是对不是k-v键值对的数据提供的,其本质仍然是groupByKey
groupBy => data.map(data => (k, v)).groupByKey
用户表信息:
按照省份来进行分组
b.编码
case class Student(id: Int, name:String, province: String)
val stuRDD = sc.parallelize(List(
Student(1, "张三", "安徽"),
Student(2, "李梦", "山东"),
Student(3, "王五", "甘肃"),
Student(4, "周七", "甘肃"),
Student(5, "Lucy", "黑吉辽"),
Student(10086, "魏八", "黑吉辽")
))
val result1 = stuRDD.groupBy(stu => stu.province)
println(result1.collect().toBuffer)
println(result1.getNumPartitions)
println(stuRDD.map(x => (x.province, x)).groupByKey().collect().toBuffer)(13)reduceByKey算子:
说明
reduceByKey((A1, A2) => A3)
前提不是对全量的数据集进行reduce操作,而是对每一个key所对应的所有的value进行reduce操作,相当于:
rdd: RDD[K, V]
val k2vs:RDD{(K, Iterable[V])] = rdd.groupByKey()
k2vs.map{case (k, vs) => {
(k, vs.reduce((A1, A2) => A3))
}}
b.编码
case class Student(id: Int, name:String, province: String)
val stuRDD = sc.parallelize(List(
Student(1, "张三", "安徽"),
Student(2, "李梦", "山东"),
Student(3, "王五", "甘肃"),
Student(4, "周七", "甘肃"),
Student(5, "Lucy", "黑吉辽"),
Student(10086, "魏八", "黑吉辽")
))
val result1 = stuRDD.groupBy(stu => stu.province)
println(result1.collect().toBuffer)
println(result1.getNumPartitions)
println(stuRDD.map(x => (x.province, x)).groupByKey().collect().toBuffer)
stuRDD.map(x=>(x.province,1)).reduceByKey(_+_).foreach(println)(14)foldByKey算子:
说明
foldByKey(zeroValue)((A1, A2) => A3),其作用和reduceByKey一样,唯一的区别就是zeroValue初始化值不一样,相当于在scala集合操作中的reduce和fold的区别
code
def foldByKeyOps(sc: SparkContext): Unit = {
case class Student(id: Int, name:String, province: String)
val stuRDD = sc.parallelize(List(
Student(1, "张三", "安徽"),
Student(3, "王五", "甘肃"),
Student(5, "Lucy", "黑吉辽"),
Student(2, "李梦", "山东"),
Student(4, "周七", "甘肃"),
Student(10086, "魏八", "黑吉辽")
), 2).mapPartitionsWithIndex((index, partition) => {
val list = partition.toList
println(s"-->stuRDD的分区编号为<${index}>中的数据为:${list.mkString("[", ", ", "]")}")
list.toIterator
})
val ret = stuRDD.map(stu => (stu.province, 1)).foldByKey(0)((v1, v2) => v1 + v2)
ret.foreach{case (province, count) => {
println(s"province: ${province}, count: ${count}")
}}
}
(15)combineByKey算子:
说明
combineByKey,也是按照key进行聚合,那么他和groupByKey还有reduceByKey之间有什么区别:
reduceByKey和groupByKey底层都是通过combineByKeyWithClassTag来实现的,而combineByKey是combineByKeyWithClassTag的一个简化的版本。
ClassTag作用用来存储在运行时一个类被擦除的泛型,以便于在运行时来访问这个类型的字段泛型信息。比如对于一个编译器不知道类型的数组,在运行时就非常有用。
编码
模拟reduceByKey
/**
* 模拟reduceByKey
* createCombiner:初始化
* mergeValue : (分区内)局部聚合
* mergeCombiner:(分区间)全局聚合
*/
def cbk2rbk(sc: SparkContext): Unit = {
val array = sc.parallelize(Array(
"hello you",
"hello me",
"hello you",
"hello you",
"hello me",
"hello you"
), 2)
val pairs = array.flatMap(_.split("\\s+")).map((_, 1))
val ret = pairs.combineByKey(createCombiner, mergeValue, mergeCombiners)
ret.foreach{case (key, count) => {
println(s"key: ${key}, count: ${count}")
}}
}
//该参数num,就是这个key在该分区内出现的第一个元素,用来进行初始化 i= 21
def createCombiner(num: Int): Int = {
num
}
//在每一个分区内,完成局部sumi和新遍历到的元素进行聚合 sumi = sumi + i
def mergeValue(sumI: Int, num: Int): Int = {
sumI + num
}
//分区间在分区内局部聚合的基础之上进行全局聚合 相当于 sum = sum + sumI
def mergeCombiners(sum: Int, sumI: Int) = {
sum + sumI
}
(16)aggregateByKey算子:
说明
combineByKey和aggregateByKey的区别就相当于reduceByKey和foldByKey。
b. 编码
def abk2rbk(sc: SparkContext): Unit = {
val array = sc.parallelize(Array(
"hello you",
"hello me",
"hello you",
"hello you",
"hello me",
"hello you"
), 2)
val pairs = array.flatMap(_.split("\\s+")).map((_, 1))
val ret = pairs.aggregateByKey(0)(_+_, _+_)
ret.foreach{case (key, count) => {
println(s"key: ${key}, count: ${count}")
}}
}
2、action行动算子操作
(1)foreach算子:
foreach主要功能,就是用来遍历RDD中的每一条纪录,其实现就是将map或者flatMap中的返回值变为Unit即可,即foreach(A => Unit)。
在上述transformation操作学习过程中,多次使用到了foreach算子,所以这里就跳过学习了。
(2)count算子:
统计该rdd中元素的个数。
|
val count = rdd.count() println("rdd的count个数为:" + count) |
(3)collect算子:
字面意思就是收集,拉取的意思,该算子的含义就是将分布在集群中的各个
partition中的数据拉回到driver中,进行统一的处理;但是这个算子有很大的风险存在,第一,driver内存压力很大,第二数据在网络中大规模的传输,效率很低;所以一般不建议使用,如果非要用,请先执行filter。
|
val arr = rdd.filter(_._2 > 2).collect() arr.foreach(println) |
(4)take&first算子:
返回该rdd中的前N个元素,如果该rdd的数据是有序的,那么take(n)就是TopN;而first是take(n)中比较特殊的一个take(1)(0)。
|
val arr:Array[(String, Int)] = rdd.take(2) arr.foreach(println) val ret:(String, Int) = rdd.first() println(ret) |
(5)takeOrdered(n)
返回前几个的排序
val arr:Array[(String, Int)] = rdd.takeOrdered(2)
arr.foreach(println)
(6)reduce算子:
需要清楚的是,reduce是一个action操作,reduceByKey是一个transformation。reduce对一个rdd执行聚合操作,并返回结果,结果是一个值。
//例子1
val rdd: RDD[Int] = sc.parallelize(1 to 5,2)
//聚合
val result: Int = rdd.reduce(_+_)
//打印输出
println(result)
//例子2
val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
//聚合
val result1= rdd2.reduce((x,y)=>(x._1 + y._1,x._2 + y._2))
//打印输出
println(result1)
countByKey算子:
统计key出现的次数。
val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
//统计相同key出现的次数
val result: collection.Map[Int, Long] = rdd.countByKey()
//打印输出
println(result)
(10)saveAsXxx算子:
saveAsTextFile本质上是saveAsHadoopFile[TextOutputFormat[NullWritable, Text]]
saveAsObjectFile本质上是saveAsSequenceFile
saveAsHadoopFile和saveAsNewAPIHadoopFile,二者的主要区别就是OutputFormat的区别。
接口org.apache.hadoop.mapred.OutputFormat
抽象类org.apache.hadoop.mapreduce.OutputFormat
saveAshadoopFile使用的是接口OutputFormat,saveAsNewAPIHadoopFile使用的抽象类OutputFormat。
//saveAsTextFile
rdd.saveAsTextFile("file:/E:/data/out/")
//saveAsNewAPIHadoopFile
val path = "file:/E:/data/out1"
rr.saveAsNewAPIHadoopFile(path,
classOf[Text],
classOf[IntWritable],
classOf[TextOutputFormat[Text, IntWritable]])
(10)foreachPartition算子:
MySql 8.0以后写入数据库url必须加时间同步: "jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8&useSSL=false"
foreach写入
|
//终于写入数据库,但是极其不友好 def saveInfoMySQL2(rdd: RDD[(String, Int)]): Unit = { rdd.foreach{case (word, count) => { Class.forName("com.mysql.jdbc.Driver") val url = "jdbc:mysql://localhost:3306/test" val connection = DriverManager.getConnection(url, "mark", "sorry") val sql = """ |insert into wordcounts(word, `count`) Values(?, ?) |""".stripMargin val ps = connection.prepareStatement(sql) ps.setString(1, word) ps.setInt(2, count) ps.execute() ps.close() connection.close() }} } val rdd: RDD[(String, Int)] = sc.parallelize(List(("hadoop",2))) |
b.高效写入数据库
def saveInfoMySQLByForeachPartition(rdd: RDD[(String, Int)]): Unit = {
rdd.foreachPartition(partition => {
//这是在partition内部,属于该partition的本地
Class.forName("com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/test"
val connection = DriverManager.getConnection(url, "mark", "sorry")
val sql =
"""
|insert into wordcounts(word, `count`) Values(?, ?)
|""".stripMargin
val ps = connection.prepareStatement(sql)
partition.foreach{case (word, count) => {
ps.setString(1, word)
ps.setInt(2, count)
ps.execute()
}}
ps.close()
connection.close()
})
}
c.批量写入数据库
def saveInfoMySQLByForeachPartitionBatch(rdd: RDD[(String, Int)]): Unit = {
rdd.foreachPartition(partition => {
//这是在partition内部,属于该partition的本地
Class.forName("com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/test"
val connection = DriverManager.getConnection(url, "mark", "sorry")
val sql =
"""
|insert into wordcounts(word, `count`) Values(?, ?)
|""".stripMargin
val ps = connection.prepareStatement(sql)
partition.foreach{case (word, count) => {
ps.setString(1, word)
ps.setInt(2, count)
ps.addBatch() //批量操作
}}
ps.executeBatch() //批量操作
ps.close()
connection.close()
})
3.持久化操作
(1)什么是持久化,为什么要持久化
Spark中最重要的功能之一是跨操作在内存中持久化(或缓存)数据集。当您持久化RDD时,每个节点将其计算的任何分区存储在内存中,并在该数据集(或从该数据集派生的数据集)上的其他操作中重用这些分区。这使得未来的行动更快(通常超过10倍)。缓存是迭代算法和快速交互使用的关键工具。
(2)如何进行持久化
可以使用persist()或cache()方法将RDD标记为持久化。第一次在动作中计算时,它将保存在节点的内存中。Spark的缓存是容错的——如果RDD的任何分区丢失,它将使用最初创建它的转换自动重新计算。
持久化的方法就是rdd.persist()或者rdd.cache()
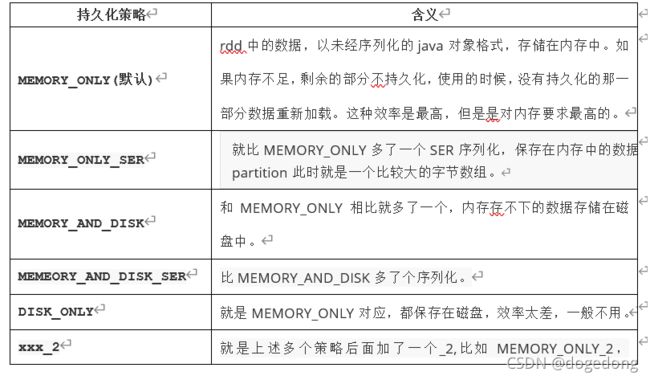
(3)持久化策略
可以通过persist(StoreageLevle的对象)来指定持久化策略,eg:StorageLevel.MEMORY_ONLY。

(4)如何选择一款合适的持久化策略
第一就选择默认MEMORY_ONLY,因为性能最高嘛,但是对空间要求最高;如果空间满足不了,退而求其次,选择MEMORY_ONLY_SER,此时性能还是蛮高的,相比较于MEMORY_ONLY的主要性能开销就是序列化和反序列化;如果内存满足不了,直接跨越MEMORY_AND_DISK,选择MEMEORY_AND_DISK_SER,因为到这一步,说明数据蛮大的,要想提高性能,关键就是基于内存的计算,所以应该尽可能的在内存中存储对象;DISK_ONLY不用,xx_2的使用如果说要求数据具备高可用,同时容错的时间花费比从新计算花费时间少,此时便可以使用,否则一般不用。
(5) 持久化和非持久化性能比较
object _05SparkPersistOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_05SparkPersistOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
//读取外部数据(文件125M大小)
var start = System.currentTimeMillis()
val lines = sc.textFile("file:///E:/data/spark/core/sequences.txt")
var count = lines.count()
println("没有持久化:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.persist(StorageLevel.MEMORY_AND_DISK) //lines.cache()
start = System.currentTimeMillis()
count = lines.count()
println("持久化之后:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.unpersist()//卸载持久化数据
sc.stop()
}
}4.RDD检查点机制
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志),也不能丢掉, 当某个节点某个 executor 宕机了,上面cache 的RDD就会丢掉, 需要通过依赖链重放计算出来,不同的是checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
如果存在以下场景,则比较适合使用检查点机制:
1)DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
2)在宽依赖上做Checkpoint获得的收益更大。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wc").setMaster("spark://CentOS1:7077")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().config(conf).getOrCreate()
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8),("a",33),("c",6)),3)
sc.setCheckpointDir("hdfs://CentOS1:9000/checkpoint")
rdd.checkpoint()
rdd.collect
println(rdd.collect.toBuffer)
}
}
三、共享变量
(一)概述
通常,当传递给Spark操作(如map或reduce)的函数在远程集群节点上执行时,它将在函数中使用的所有变量的单独副本上工作。这些变量被复制到每台机器上,对远程机器上变量的更新不会传播回驱动程序。跨任务支持通用的读写共享变量将是低效的(低效). 然而,Spark确实为两种常见的使用模式提供了两种有限类型的共享变量:广播变量和累加器。
就是说,为了能够更加高效的在driver和算子之间共享数据,spark提供了两种有限的共享变量,一者广播变量,一者累加器。
(二)broadcast广播变量
1、说明
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么只是每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。

如何使用广播变量呢?
对普通遍历进行包装即可,
val num:Any = xxx
val numBC:Broadcast[Any] = sc.broadcast(num)
调用
val n = numBC.value
需要注意一点的是,显然该num需要进行序列化。
2、编码操作
val conf = new SparkConf()
conf.setMaster("local[*]").setAppName("brocast")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val list = List("hello hadoop")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("E:\\word.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach(println)
sc.stop()3、定义广播变量注意点
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
4、注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
(三)accumulator累加器
1、说明
accumulator累加器的概念和mr中出现的counter计数器的概念有异曲同工之妙,对某些具备某些特征的数据进行累加。累加器的一个好处是,不需要修改程序的业务逻辑来完成数据累加,同时也不需要额外的触发一个action job来完成累加,反之必须要添加新的业务逻辑,必须要触发一个新的action job来完成,显然这个accumulator的操作性能更佳!
累加的使用:
构建一个累加器
val accu = sc.longAccumuator()
累加的操作
accu.add(参数)
获取累加器的结果,累加器的获取,必须需要action的触发
val ret = accu.value
编码操作
使用非累加器完成某些特征数据的累加求解
|
val sc = new SparkContext(conf) val lines = sc.textFile("file:/E:/work/data/accu.txt") val words = lines.flatMap(_.split("\\s+")) //统计每个单词出现的次数 val rbk = words.map((_, 1)).reduceByKey(_+_) rbk.foreach(println) println("=============额外的统计=================") //统计其中的is出现的次数 rbk.filter{case (word, count) => word == "is"}.foreach(println) Thread.sleep(10000000) sc.stop() |

(2)使用累加器完成上述案例
val conf = new SparkConf()
.setAppName(s"${AccumulatorOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/work/data/accu.txt")
val words = lines.flatMap(_.split("\\s+"))
//统计每个单词出现的次数
val accumulator = sc.longAccumulator
val rbk = words.map(word => {
if(word == "is")
accumulator.add(1)
(word, 1)
}).reduceByKey(_+_)
rbk.foreach(println)
println("================使用累加器===================")
println("is: " + accumulator.value)
Thread.sleep(10000000)
sc.stop()
(3)总结
使用累加器也能够完成上述的操作,而且只使用了一个action操作。
3.注意
- 累加器的调用,也就是accumulator.value必须要在action之后被调用,也就是说累加器必须在action触发之后。
- 多次使用同一个累加器,应该尽量做到用完即重置。
accumulator.reset
- 尽量给累加器指定name,方便我们在web-ui上面进行查看,如图2-8所示。

4.自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。实现自定义类型累加器需要继承AccumulatorV2并至少覆写下例中出现的方法,
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
class CustomerAcc extends AccumulatorV2[String, mutable.HashMap[String, Int]] {
private val _hashAcc = new mutable.HashMap[String, Int]()
// 检测是否为空
override def isZero: Boolean = {
_hashAcc.isEmpty
}
// 拷贝一个新的累加器,
//有可能多个task同时往初始值里写值,有可能出现线程安全问题,此时最好加锁
override def copy(): AccumulatorV2[String, mutable.HashMap[String, Int]] = {
val newAcc = new CustomerAcc()
_hashAcc.synchronized {
newAcc._hashAcc ++= (_hashAcc)
}
newAcc
}
// 重置一个累加器
override def reset(): Unit = {
_hashAcc.clear()
}
// 每一个分区中用于添加数据的方法 小SUM
override def add(v: String): Unit = {
_hashAcc.get(v) match {
case None => _hashAcc += ((v, 1))
case Some(a) => _hashAcc += ((v, a + 1))
}
}
// 合并每一个分区的输出 总sum
override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Int]]): Unit = {
other match {
case o: AccumulatorV2[String, mutable.HashMap[String, Int]] => {
for ((k, v) <- o.value) {
_hashAcc.get(k) match {
case None => _hashAcc += ((k, v))
case Some(a) => _hashAcc += ((k, a + v))
}
}
}
}
}
// 输出值
override def value: mutable.HashMap[String, Int] = {
_hashAcc
}
- 注册使用
object CustomerAcc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("partittoner").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val abc = "HIII"
val hashAcc = new CustomerAcc()
sc.register(hashAcc, "abc")
val rdd = sc.makeRDD(Array("a", "b", "c", "a", "b", "c", "d"))
rdd.foreach(hashAcc.add(_))
for ((k, v) <- hashAcc.value) {
println("【" + k + ":" + v + "】")
}
sc.stop()
}
}