使用Scikit-Learn实现多标签分类,助力机器学习
大家好,在机器学习任务中,分类是一种监督学习方法,用于根据输入数据预测标签。例如,我们想要根据历史特征预测某人是否对销售优惠感兴趣,通过使用可用的训练数据训练机器学习模型,可以对输入数据执行分类任务。
平常会遇到一些经典分类任务,例如二元分类(两个标签)和多类分类(两个以上标签)。在这种情况下,我们会训练分类器,模型会尝试从所有可用标签中预测一个标签。用于分类的数据集类似于下面的图像:

上面的图像显示目标(销售优惠)在二元分类中包含两个标签,在多类分类中包含三个标签,模型会从可用特征中进行训练,然后仅输出一个标签。
多标签分类与二元或多类分类不同,在多标签分类中,我们不仅尝试预测一个输出标签,相反,多标签分类会尝试预测尽可能多的适用于输入数据的标签,输出可以是从没有标签到最大数量的可用标签。
多标签分类通常用于文本数据分类任务,下面是一个多标签分类的示例数据集。
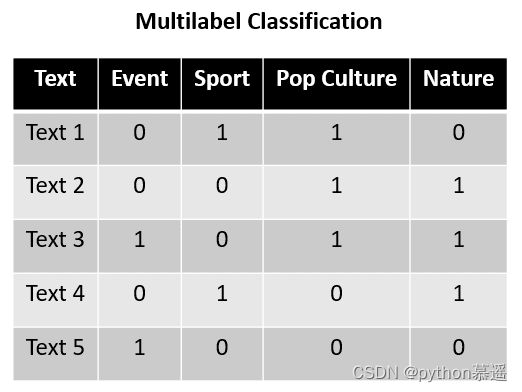
在上面的示例中,假设文本1到文本5是可以归类为四个类别的句子:事件、体育、流行文化和自然。通过上述训练数据,多标签分类任务可以预测哪个标签适用于给定的句子。每个类别之间并不相互对立,因为它们不是互斥的;每个标签可以被视为独立的。
更详细地说,我们可以看到文本1标记为体育和流行文化,而文本2标记为流行文化和自然。这表明每个标签是互斥的,多标签分类的预测输出可以是没有标签或同时包含所有标签。
有了上述介绍,接下来尝试使用Scikit-Learn搭建多标签分类器。
使用Scikit-Learn进行多标签分类
本文将使用Kaggle上公开可用的生物医学PubMed多标签分类数据集,该数据集包含各种特征,但本文只使用abstractText特征和它们的MeSH分类(A:解剖学,B:有机体,C:疾病等)。示例数据如下图所示:
【生物医学PubMed多标签分类数据集】:https://www.kaggle.com/datasets/owaiskhan9654/pubmed-multilabel-text-classification
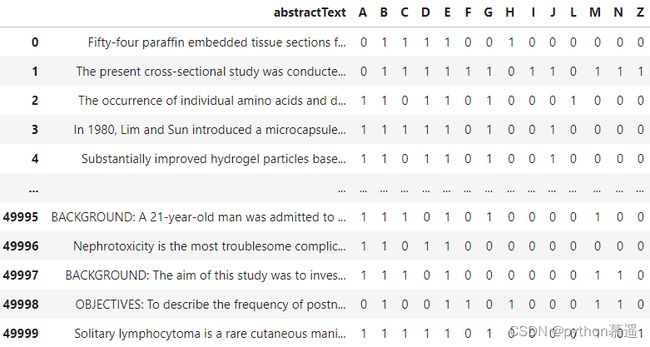
上述数据集表明,每篇论文都可以被分为多个类别,这就是多标签分类的案例。有了这个数据集,那么就可以使用Scikit-Learn建立多标签分类器,在训练模型之前,首先准备好数据集。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Text Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.fit(X)
在上面的代码中,将文本数据转换为TF-IDF表示,以便Scikit-Learn模型能够接受训练数据。此外,为了简化教程,本文跳过了预处理数据的步骤,例如删除停顿词。
数据转换完成后,我们将数据集分割为训练集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
完成所有准备工作后,我们将开始训练多标签分类器。在Scikit-Learn中,我们将使用MultiOutputClassifier对象来训练多标签分类器模型。该模型背后的策略是为每个标签训练一个分类器,每个标签都有自己的分类器。
在这个示例中,我们将使用逻辑回归,并使用MultiOutputClassifier将其扩展到所有标签。
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).fit(X_train_tfidf, y_train)
我们可以更改模型并调整传递给MultiOutputClasiffier的模型参数,因此请根据自己的要求进行管理。训练完成后,使用模型预测测试数据。
prediction = clf.predict(X_test_tfidf)
prediction

预测结果是每个MeSH类别的标签数组,每一行代表一个句子,每一列代表一个标签。
最后,我们需要对多标签分类器进行评估,可以使用准确率指标来评估模型。
from sklearn.metrics import accuracy_score
print('Accuracy Score: ', accuracy_score(y_test, prediction))****
准确率得分为0.145。
准确度得分结果为0.145,这表明该模型只能在不到14.5%的情况下能预测出准确的标签组合。然而,对于多标签预测评估来说,准确率得分存在不足。准确率得分需要每个句子的所有标签都出现在准确的位置上,否则就会被认为是错误的。
例如,第一行预测与测试数据之间仅有一个标签的差异。

对于准确率得分来说,这将被认为是错误的预测,因为标签组合不同,这就是模型具有较低度量分数的原因。
为了解决这个问题,我们必须评估标签的预测而不是它们的组合。在这种情况下,我们可以使用Hamming Loss评估指标。汉明损失通过将错误预测与总标签数的比例来计算,因为汉明损失是一种损失函数,得分越低越好(0表示没有错误预测,1表示所有预测都错误)。
from sklearn.metrics import hamming_loss
print('Hamming Loss: ', round(hamming_loss(y_test, prediction),2))
汉明损失为0.13。
我们的多标签分类器Hamming Loss模型为0.13,这意味着我们的模型在独立情况下约有13%的错误预测,也就是说每个标签的预测可能有13%的错误。
总结
多标签分类是一种机器学习任务,其输出可以是没有标签或给定输入数据的所有可能标签。这与二元或多类分类不同,其中标签输出是相互排斥的。
使用Scikit-Learn的MultiOutputClassifier,我们可以开发多标签分类器,为每个标签训练一个分类器。在模型评估方面,最好使用Hamming Loss指标,因为准确率得分可能无法正确反映整体情况。