备注: 图片实在是上传不上去,都是外链图片,我暂时放弃了,需要的小伙伴转CSDN吧 -> https://blog.csdn.net/weixin_43917143/article/details/120436445。
SpringBoot 整合 Sharding-JDBC(mysql-8.0)
感谢
我也是从网上的资源查找后进行学习的,所以该项目仅适用与个人学习,不建议使用于生产项目。
这里感谢如下:
B站、CSDN、、GitHub、Gitee等......
ShardingShpere数据库中间件- 专栏 -KuangStudy
数据分片 :: ShardingSphere
等......
非常感谢狂神及狂神飞哥的教学视频及网站文档、感谢其他开发者提供的解决问题的博客、感谢ShardingSphere团队提供的开源技术等!
需要进行视频学习的小伙伴可以去B站搜索狂神说Java或狂神自己的网站学习
我很多都是基于ShardingShpere数据库中间件- 专栏 -KuangStudy去进行实现的!
文档迭代
| version | 功能 | 详细描述 |
|---|---|---|
| 0.0.1 | 读写分离与数据分片(分库分表) | 通过整合Sharding-JDBC实现主从数据库读写分离和分库分表进行数据分片。 |
项目技术版本(技术选型)
| 技术 | version | 描述 |
|---|---|---|
| jdk | 8 | 符合你当前选择的springboot版本就可以 |
| maven | 3.8.1 | 符合你当前选择的springboot版本就可以 |
| springboot | 2.2.2.RELEASE | |
| Sharding-JDBC | 4.0.0-RC1 | |
| mysql | 8.0 | |
| 其他 | 参考maven,pom配置 |
Sharding-JDBC学习
基础知识
基础知识了解可以自己去阅读下[文档](https://shardingsphere.apache.org/document/legacy/4.x/document/cn/overview/#sharding-jdbc),我搬运过来也没有什么意义!
概念&功能
下图是我从官网截取来的!
[图片上传失败...(image-37b32b-1632386680386)]
读写分离
读写分离内容
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/read-write-split/concept/
mysql-主从复制
要玩读写分离,那么你一定要有已经配置好主从复制的库,如果没有,那么我想你需要下面这个来进行配置!
基于Docker 配置主从服务器实现 mysql主从复制(8.0版本)_meng前行的博客-CSDN博客
基于Docker 配置主从服务器实现 mysql主从复制(8.0) -
这是我自己根据ShardingShpere数据库中间件- 专栏 -KuangStudy写的博客。
读写分离yml配置文件
[图片上传失败...(image-333dca-1632386680386)]
官网中的读写分离配置 -> https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/#%E8%AF%BB%E5%86%99%E5%88%86%E7%A6%BB
注意:
[图片上传失败...(image-63f11a-1632386680386)]
ds1和下面的dataSourc配置其实是Map的(k,v),所以在这里idea并不会进行代码提示,需要自己检查是否输入错误!
为什么是Map?
进入SpringBootConfiguration类可以看到如下:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.apache.shardingsphere.shardingjdbc.spring.boot;
......
@Configuration
@EnableConfigurationProperties({SpringBootShardingRuleConfigurationProperties.class, SpringBootMasterSlaveRuleConfigurationProperties.class, SpringBootEncryptRuleConfigurationProperties.class, SpringBootPropertiesConfigurationProperties.class})
@ConditionalOnProperty(
prefix = "spring.shardingsphere",
name = {"enabled"},
havingValue = "true",
matchIfMissing = true
)
public class SpringBootConfiguration implements EnvironmentAware {
private final SpringBootShardingRuleConfigurationProperties shardingProperties;
private final SpringBootMasterSlaveRuleConfigurationProperties masterSlaveProperties;
private final SpringBootEncryptRuleConfigurationProperties encryptProperties;
private final SpringBootPropertiesConfigurationProperties propMapProperties;
private final Map dataSourceMap = new LinkedHashMap();
private final ShardingRuleConfigurationYamlSwapper shardingSwapper = new ShardingRuleConfigurationYamlSwapper();
private final MasterSlaveRuleConfigurationYamlSwapper masterSlaveSwapper = new MasterSlaveRuleConfigurationYamlSwapper();
private final EncryptRuleConfigurationYamlSwapper encryptSwapper = new EncryptRuleConfigurationYamlSwapper();
......
// 它通过实现EnvironmentAware接口来获取配置文件中的配置属性,这里就获取了
// spring.shardingsphere.datasource.下的属性
public final void setEnvironment(Environment environment) {
String prefix = "spring.shardingsphere.datasource.";
// 拿到我这里的 ds1,ds2
Iterator var3 = this.getDataSourceNames(environment, prefix).iterator();
// 通过while 遍历获得每个具体的数据源配置,将数据源配置根据k,v存入 dataSourceMap
while(var3.hasNext()) {
String each = (String)var3.next();
try {
// DataSource属性获得,put进入 dataSourceMap,说明
// private final Map dataSourceMap = new LinkedHashMap();
// 就是存放数据源配置的属性
this. dataSourceMap.put(each, this.getDataSource(environment, prefix, each));
} catch (ReflectiveOperationException var6) {
throw new ShardingException("Can't find datasource type!", var6);
}
}
}
// 获取数据源名称集合(例如我这里的 ds1,ds2)
private List getDataSourceNames(Environment environment, String prefix) {
StandardEnvironment standardEnv = (StandardEnvironment)environment;
standardEnv.setIgnoreUnresolvableNestedPlaceholders(true);
return null == standardEnv.getProperty(prefix + "name") ? (new InlineExpressionParser(standardEnv.getProperty(prefix + "names"))).splitAndEvaluate() : Collections.singletonList(standardEnv.getProperty(prefix + "name"));
}
// 获取对应数据源名称的数据源配置
private DataSource getDataSource(Environment environment, String prefix, String dataSourceName) throws ReflectiveOperationException {
Map dataSourceProps = (Map)PropertyUtil.handle(environment, prefix + dataSourceName.trim(), Map.class);
Preconditions.checkState(!dataSourceProps.isEmpty(), "Wrong datasource properties!");
return DataSourceUtil.getDataSource(dataSourceProps.get("type").toString(), dataSourceProps);
}
......
}
你如果好奇我是怎么找到的SpringBootConfiguration?
请你先进入配置文件,例如我这里的 application-readwrite.yml,
按住ctrl + 选择spring.shardingsphere.datasource.names,然后点击鼠标左键就可以进入类了。
通过寻找 sharding-jdbc-spring-boot-starter-4.0.0-RC1.jar 配置中的自动配置类[图片上传失败...(image-40db26-1632386680386)]
我个人是建议你一定要会第二种,虽然第一种很方便,这就像那啥,你可以不用但不能不会!
是Map的话,那我这个数据源该怎么配置,和单个数据源有什么不同?
-
那我这个数据源该怎么配置?
按照官网说的支持如下图:
[图片上传失败...(image-762c34-1632386680386)]
你只要选择它支持的数据库连接池的配置就可以了。
-
单个数据源有什么不同?
几乎没什么不同,除了从原来的单个类,变成Map
测试
好了,到了这里了我们就假设你已经配置好了mysql-主从复制和yml配置了,没有配置好的请配置完成再看!
现在的数据如下:
[图片上传失败...(image-bc8533-1632386680386)]
左主右从
接下来我们先查询以下,是不是从从库 查询,然后 新增、修改、删除 都在主库完成。
查询 - 从库
我在 test包下写了个 {@link com.blacktea.shardingjdbc.ShardingJdbcReadWriteTests},
执行方法list(),结果如下图:
[图片上传失败...(image-aacc16-1632386680386)]
ds2 根据yml配置可以得知,确实是从库的配置。
那么**ShardingJdbc**读写分离也确实是从 *从库*中查询数据。
增加、删除、修改 - 主库
[图片上传失败...(image-28a314-1632386680386)]
注意: 我在测试增加的时候发现了一个问题,*Committed transaction for test*,他会自动进行回滚,导致数据库中并没有插入数据,但是该结果返回的是true,
后来我查询资料后发现 因为JUnit使用 @Transactional会自动开启事务,即没有报错也会执行事务,所以需要 @Rollback(false)关闭事务了。
资料如下:
https://blog.csdn.net/jinbaizhe/article/details/81055495
https://blog.csdn.net/u013107634/article/details/108888818
插入成功
[图片上传失败...(image-463ccf-1632386680386)]
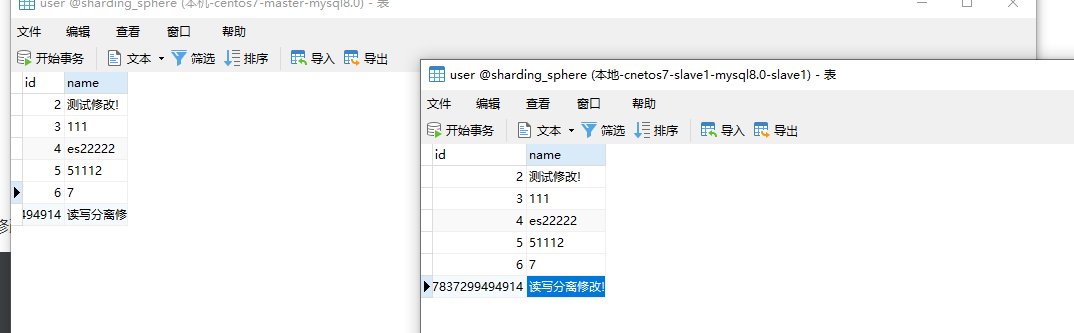
修改成功
[图片上传失败...(image-f526e9-1632386680386)]
删除成功
[图片上传失败...(image-99fd68-1632386680386)]
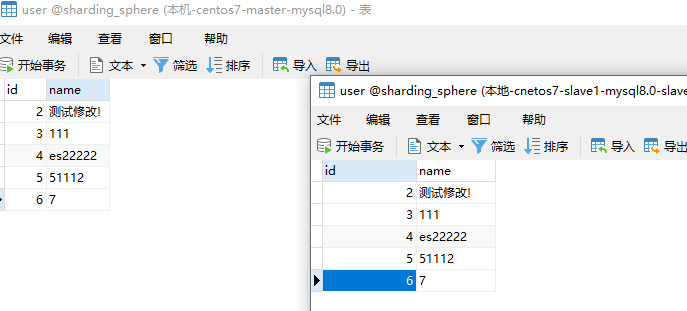
OK,那么读写分离入门那就结束了!
数据分片
数据分片内容
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/sharding/
分片配置
[图片上传失败...(image-3d1cc2-1632386680386)]
官网中的读写分离配置 -> https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/#%E6%95%B0%E6%8D%AE%E5%88%86%E7%89%87
注意:
sub1表示分库又分表;
sub2表示->(分库而固定表)或(固定库而分表);
yml配置说明
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的ds1,ds2任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.168.101:3306/sharding_sphere?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: mysql8.0
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_sphere?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: mysql8.0
maxPoolSize: 100
minPoolSize: 5
sharding:
# 配置分表的规则
tables:
# user 逻辑表名
sys_user:
key-generator:
# 主键的列明,
column: id
type: SNOWFLAKE
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.sys_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: ds$->{sex % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
# 按出生日期中的年份进行分表
# standard:
# shardingColumn: date_birth # 字段名不存在默认 sys_user全匹配 添加
# preciseAlgorithmClassName: com.blacktea.shardingjdbc.config.BirthdayAlgorithm
# 按年龄进行分表
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: sys_user$->{age % 2} # 分片算法表达式
spring.shardingsphere.sharding.tables : 表示对表进行分片(含分库和同库分表)
具体配置可以参考 SpringBootShardingRuleConfigurationProperties类与文档
SpringBootShardingRuleConfigurationProperties 解析如下:
package org.apache.shardingsphere.shardingjdbc.spring.boot.sharding;
import org.apache.shardingsphere.core.yaml.config.sharding.YamlShardingRuleConfiguration;
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(
prefix = "spring.shardingsphere.sharding"
)
public class SpringBootShardingRuleConfigurationProperties extends YamlShardingRuleConfiguration {
public SpringBootShardingRuleConfigurationProperties() {
}
}
其实值都在父类 YamlShardingRuleConfiguration里 如下:
package org.apache.shardingsphere.core.yaml.config.sharding;
......
public class YamlShardingRuleConfiguration implements YamlConfiguration {
// tables 逻辑表名 - k 对应 sys_user, v对应其他
private Map tables = new LinkedHashMap();
private Collection bindingTables = new ArrayList();
private Collection broadcastTables = new ArrayList();
private String defaultDataSourceName;
private YamlShardingStrategyConfiguration defaultDatabaseStrategy;
private YamlShardingStrategyConfiguration defaultTableStrategy;
private YamlKeyGeneratorConfiguration defaultKeyGenerator;
private Map masterSlaveRules = new LinkedHashMap();
private YamlEncryptRuleConfiguration encryptRule;
......
}
YamlTableRuleConfiguration又包含了对应的表策略、库策略、表主键生成等等......
package org.apache.shardingsphere.core.yaml.config.sharding;
......
public class YamlTableRuleConfiguration implements YamlConfiguration {
private String logicTable;
private String actualDataNodes;
// 分表策略
private YamlShardingStrategyConfiguration databaseStrategy;
// 分库策略
private YamlShardingStrategyConfiguration tableStrategy;
// 表主键生成
private YamlKeyGeneratorConfiguration keyGenerator;
private String logicIndex;
......
}
策略对象都是同一个类 YamlShardingStrategyConfiguration,里面包含了5个ShardingStrategy配置
package org.apache.shardingsphere.core.yaml.config.sharding;
......
public class YamlShardingStrategyConfiguration implements YamlConfiguration {
private YamlStandardShardingStrategyConfiguration standard;
private YamlComplexShardingStrategyConfiguration complex;
private YamlHintShardingStrategyConfiguration hint;
private YamlInlineShardingStrategyConfiguration inline;
private YamlNoneShardingStrategyConfiguration none;
......
}
对应文档中的3.1数据分片下的分片中的分片策略 5 种
[图片上传失败...(image-9d2f60-1632386680386)]
对应yml中的
spring.shardingsphere.sharding.tables.sys_user.database-strategy**
与
spring.shardingsphere.sharding.tables.sys_user.table-strategy**
这里的策略有5种,我在配置中只实现了两种,因为我是根据飞哥的文档进行学习的,其他几种就没尝试,以后有机会在补吧。
我这里常用的就是inline和standard。
inline 使用参考官网 3.1.4. 其他功能
strategy 使用参考 application-sub1.yml中的strategy
使用的策略类是 {@link com.blacktea.shardingjdbc.config.BirthdayAlgorithm},该类通过实现{@link org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm}接口实现,doSharding()方法的返回值就是你配置的库或表的实际sql名称。
strategy 其他实现方式,可以通过源码看到如下图(接口关系)
[图片上传失败...(image-bc0c48-1632386680386)]
都是通过顶层接口 ShardingAlgorithm实现的!
其实你从官网文档的 3.1.1. 核心概念 的 分片也可以找到,如下图:
[图片上传失败...(image-61e3ae-1632386680386)]
分片算法有四种!
具体想要用那个根据自己的业务去决定吧!
测试
数据库准备
1.准备两个及以上的数据库,我这里准备的是虚拟机-mysql和本地-mysql,你可以按自己的准备,只要存在两个库就行;
-
数据库中需要存有相同且与yml中配置的满足库与表策略的表,
例如我这里的,如下:
[图片上传失败...(image-8794c4-1632386680386)]
# 创建语句,其他表就是名字不一样而已
CREATE TABLE `sys_user0` (
`id` bigint NOT NULL,
`user_name` varchar(255) NOT NULL COMMENT '账号名称',
`password` varchar(255) NOT NULL COMMENT '密码',
`age` int DEFAULT NULL COMMENT '年龄',
`date_birth` datetime DEFAULT NULL COMMENT '出生日期',
`sex` int DEFAULT NULL COMMENT '1:男,2:女',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
新增
我写了个用例,{@link com.blacktea.shardingjdbc.ShardingJdbcSub1Tests}
执行createDs0_sysUser0(),正常效果是在ds0的sys_user表生成一条数据,
[图片上传失败...(image-925110-1632386680386)]
然后我又运行了 createDs0_sysUser1()和createDs1_sysUser0(),我就不放用例执行图了,直接放结果吧,如下图:
[图片上传失败...(image-9ce29f-1632386680386)]
修改
那新增是按照策略不同进行分库分表的,那么修改、删除呢?
来,上用例!
[图片上传失败...(image-5c872-1632386680386)]
从sql日志中可以发现在两个库的四个表都执行了修改语句,当前修改根据 user_name,该值是没有配置在yml的库表策略里的;
那么我们换一下,换成有配置的 age进行测试,
[图片上传失败...(image-ee3f30-1632386680386)]
你会发现它就执行了age%2对应的表,这里也就是sys_user0,没有执行sys_user1,直接出现脏数据!
删除
[图片上传失败...(image-dd2d5e-1632386680386)]
与修改一样存在相同问题!!!
查询
[图片上传失败...(image-7cb1e1-1632386680386)]
与修改一样存在相同问题!!!
修改、删除、查询需注意
通修改(包括删除、查询)的测试发现,好家伙,这不是完犊子了么,如果我不小心使用未配置的字段进行所有表的修改,然后就会漏改一些配置不到的库表,额......,所以进行更新的时候一定要注意是否是策略字段! 如果是策略字段,在修改策略字段对应值(表值)的时候,不要修改成非该表配置策略对应的值,这样会导致该条记录失去以该策略字段修改的功能!!!(因为匹配不到该表)!
怎么解决?
备注: 其实通过Sharding-JDBC查询是不会查出那些脏数据的,但是你自己在数据库中可以看到,这就很难受,不是吗!!!
其实这也是你自己操作的不规范,因为你自己配置了库表策略了,还这样进行修改、删除和查询!!!
-
再修改完事根据策略进行移库移表等操作!
简单点,就是删除该数据,再插入该数据,会自动根据策略存储库表的。
-
不要进行存有策略的字段的修改,就算修改也尽量修改为同样策略运算结果后同库同表的值!
简单点,就是 age%2 原本等于几现在就要等于几
待大佬补充......