第58步 深度学习图像识别:Transformer可视化(Pytorch)
一、写在前面
(1)pytorch_grad_cam库
这一期补上基于基于Transformer框架可视化的教程和代码,使用的是pytorch_grad_cam库,以Bottleneck Transformer模型为例。
(2)算法分类
pytorch_grad_cam库中包含的主要方法有以下几种:
GradCAM: 这是最基本的方法。GradCAM(Gradient-weighted Class Activation Mapping)通过取网络最后一个卷积层的特征图,然后对这些特征图进行加权求和,得到类别激活图。加权的系数是网络最后一个卷积层特征图对应类别的梯度的全局平均池化值。
GradCAMPlusPlus: 这是在GradCAM的基础上的改进。GradCAM++不仅计算了类别相对于特征图的梯度,还计算了二阶和三阶导数。这使得GradCAM++在某些情况下可以获得更细粒度的解释。
ScoreCAM: ScoreCAM采用了不同的策略。它对于每个特征图都生成一个类似的激活图,并将所有这些激活图加权求和。权重是每个特征图对应的类别分数。
AblationCAM: AblationCAM是基于Ablation-based的方法。它首先对每个特征图进行遮挡(或移除),然后看类别得分如何改变。这些改变被用来生成类别激活图。
XGradCAM: 这是GradCAM的另一个扩展。XGradCAM考虑了激活和梯度之间的空间关系,以生成更详细的类别激活图。
EigenCAM: 它基于主成分分析 (PCA) 的方法,利用协方差矩阵的特征向量和特征值来表示激活图。
FullGrad: FullGrad是一个对输入,权重和偏差的特征重要性进行全局分解的方法。
以上方法都在解释深度学习模型的决策,可以帮助理解模型关注的区域和特征。在选择使用哪种方法时,可以根据需求和实验效果进行选择。
二、Transformer可视化实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)Bottleneck Transformer建模
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as np
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
import os
# 数据集路径
data_dir = "./MTB"
# 图像的大小
img_height = 256
img_width = 256
# 数据预处理
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(img_height),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize((img_height, img_width)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)
# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占80%
val_size = full_size - train_size # 验证集的大小
# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])
# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']
# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes
###############################定义模型################################
# 导入必要的库
import torch.nn as nn
import timm
# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']
# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))
# 将模型移至指定设备
model = model.to(device)
# 打印模型摘要
print(model)
#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters())
# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 开始训练模型
num_epochs = 2
# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每个epoch都有一个训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 零参数梯度
optimizer.zero_grad()
# 前向
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 只在训练模式下进行反向和优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()
# 记录每个epoch的loss和accuracy
if phase == 'train':
train_loss_history.append(epoch_loss)
train_acc_history.append(epoch_acc)
else:
val_loss_history.append(epoch_loss)
val_acc_history.append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
print()
# 保存模型
torch.save(model.state_dict(), 'botnet_dit_model.pth')(b)使用GradCAM可视化
在跑之前,得先安装git;然后用git安装pytorch_grad_cam:
安装git容易,无脑输入:
conda install git安装pytorch_grad_cam也不难:
git clone https://github.com/jacobgil/pytorch-grad-cam.git
cd pytorch-grad-cam
pip install .然后码代码:
import numpy as np
from PIL import Image
from matplotlib import pyplot as plt
from pytorch_grad_cam import GradCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM, EigenCAM, FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
import timm
# 代码1中的函数
def myimshows(imgs, titles=False, fname="test.jpg", size=6):
lens = len(imgs)
fig = plt.figure(figsize=(size * lens,size))
if titles == False:
titles="0123456789"
for i in range(1, lens + 1):
cols = 100 + lens * 10 + i
plt.xticks(())
plt.yticks(())
plt.subplot(cols)
if len(imgs[i - 1].shape) == 2:
plt.imshow(imgs[i - 1], cmap='Reds')
else:
plt.imshow(imgs[i - 1])
plt.title(titles[i - 1])
plt.xticks(())
plt.yticks(())
plt.savefig(fname, bbox_inches='tight')
plt.show()
def tensor2img(tensor,heatmap=False,shape=(256,256)):
np_arr=tensor.detach().numpy()#[0]
#对数据进行归一化
if np_arr.max()>1 or np_arr.min()<0:
np_arr=np_arr-np_arr.min()
np_arr=np_arr/np_arr.max()
#np_arr=(np_arr*255).astype(np.uint8)
if np_arr.shape[0]==1:
# 如果是灰度图像,复制三个通道以创建一个RGB图像
np_arr=np.concatenate([np_arr,np_arr,np_arr],axis=0)
np_arr=np_arr.transpose((1,2,0))
return np_arr
# 加载模型
model = timm.create_model('botnet26t_256', pretrained=False)
# 更改全连接层以匹配你的类别数
num_ftrs = model.head.fc.in_features
model.head.fc = nn.Linear(num_ftrs, 2) # 假设你的类别数为2
model.load_state_dict(torch.load('botnet_dit_model.pth', map_location=device))
# 模型转移到相应设备
model = model.to(device)
# 你的图像路径
image_path = './MTB/Tuberculosis/Tuberculosis-203.png'
# 加载图像
image = Image.open(image_path).convert("RGB")
# 使用代码1中定义的图像转换
input_image = data_transforms['val'](image).unsqueeze(0).to(device)
# 使用GradCAM
target_layer = model.stages[2][0].conv3_1x1.bn.drop
with GradCAM(model=model, target_layers=[target_layer], use_cuda=torch.cuda.is_available()) as cam:
target = [ClassifierOutputTarget(1)] # 修改为你的目标类别
grayscale_cam = cam(input_tensor=input_image, targets=target)
#将热力图结果与原图进行融合
rgb_img=tensor2img(input_image.cpu().squeeze())
visualization = show_cam_on_image(rgb_img, grayscale_cam[0], use_rgb=True)
myimshows([rgb_img, grayscale_cam[0], visualization],["image","cam","image + cam"])结果输出如下:
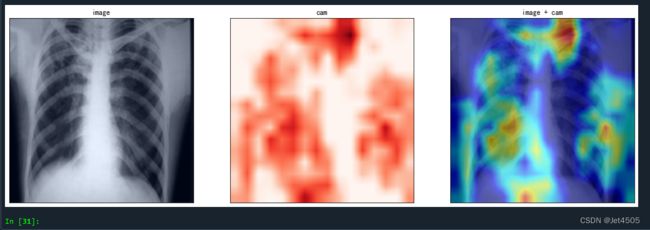
红色区域就是模型认为的“可疑区域”,也就是说模型根据这些区域判断它是Tuberculosis的主要依据。
几个注意事项:
(a)问:代码:‘target = [ClassifierOutputTarget(0)] # 修改为你的目标类别’,这个怎么解释?此外,0和1分别代表什么呢?
答:第一小问:一般来说,ClassifierOutputTarget(0)中的0代表的是你希望将注意力图(CAM)生成针对的类别标签。例如,如果你的两个类别是猫和狗,且在训练数据集中猫的标签是0,狗的标签是1,那么ClassifierOutputTarget(0)将生成猫的注意力图,而ClassifierOutputTarget(1)将生成狗的注意力图。
第二小问:在 PyTorch 中,使用 ImageFolder 函数或类似的数据加载器加载数据时,类别名称列表(class_names)的顺序将决定了类别标签的分配。这意味着类别名称列表的索引将作为类别的标签。在我们的例子中,class_names = ['Normal', 'Tuberculosis'],"Normal" 的索引是 0,所以它的标签是 0;"Tuberculosis" 的索引是 1,所以它的标签是 1。所以ClassifierOutputTarget(0) 将生成"Normal"类别的注意力图,ClassifierOutputTarget(1) 将生成"Tuberculosis"类别的注意力图。
(b)问:代码:‘target_layer = model.stages[2][0].conv3_1x1.conv’,如何选择输出的层?怎么知道模型中有哪些层?
答:第一小问:一般来说,卷积层或者重复结构的最后一层(如 ResNet 中的每个残差块的最后一层)是可行的目标层,因为这些层能保留空间信息,而全连接层则不行,因为它们不再保留空间信息。
第二小问:通过下面代码打印出模型中所有层次的名称:
#打印出模型中所有层次的名称
for name, module in model.named_modules():
print(name)输出如下:

或者打印出模型的顶层子模块:
#打印模型的顶层子模块
for name, module in model.named_children():
print(name)输出就四个:
stem
stages
final_conv
head接下来,展示几个层的写法,大家自行体会:
stem.conv2.conv :target_layer = model.stem.conv2.conv
stages.3.1.conv1_1x1:target_layer = model.stages[3][1].conv1_1x1
final_conv:target_layer = model.final_conv应该找到规律了吧,不详细解释了。每一层输出是不一样的,例如上面三层输出依次如下:

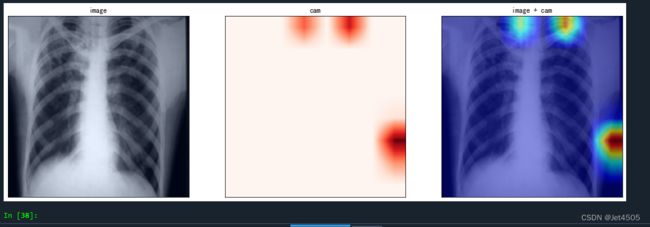

(c)问:如何改用其他7种方法来替代GradCAM?
答:很简单,来到这个代码段:
with GradCAM(model=model, target_layers=[target_layer], use_cuda=torch.cuda.is_available()) as cam:
target = [ClassifierOutputTarget(0)] # 修改为你的目标类别
grayscale_cam = cam(input_tensor=input_image, targets=target)
#将热力图结果与原图进行融合
rgb_img=tensor2img(input_image.cpu().squeeze())
visualization = show_cam_on_image(rgb_img, grayscale_cam[0], use_rgb=True)
myimshows([rgb_img, grayscale_cam[0], visualization],["image","cam","image + cam"])只需要把GradCAM分别换成GradCAMPlusPlus、ScoreCAM、AblationCAM、XGradCAM、EigenCAM以及FullGrad即可,简单粗暴。
三、写在后面
除了Transformer,pytorch_grad_cam库也可以用在之前提到的CNN的模型上,大家可自行探索哈。
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf