论文《DeepHawkes: Bridging the Gap between Prediction and Understanding of Information Cascades》阅读
论文《DeepHawkes: Bridging the Gap between Prediction and Understanding of Information Cascades》阅读
- 论文概况
- Introduction
- Preliminaries
-
- 霍克斯过程
- Model
-
- User Embedding
- Path Encoding and Sum Pooling
- Non-parametric Time Decay Effect
- 一些讨论
- 关于这篇论文,我的一些疑惑
论文概况
本文是沈华伟老师团队发表在CIKM 2017 (CCF B类会议)上的一篇关于热度预测方向的论文,提出了模型DeepHawkes,模型结合了RNN和Hawkes模型,能够解释性地使用生成式方法(霍克斯模型),并利用神经网络的计算优势,完成对社交网络中热度的预测。
Introduction
这里作者重点指出,对于热度预测,现有方法基本上是两类:1. 基于特征的方法; 2. 基于生成式的方法。
对于基于特征的方法,需要特征工程,虽然表现好,但是费时费力,而且对于不同人物不以拓展。
对于基于生成是的方法,就是利用信息传播领域的专家前辈提出的相关公式和模型,通过深度学习或者其他神经网络模型,进行模拟和丰富,而完成的热度预测模型。这类模型能够较好地解释热度预测的理论基础,具有可解释性。
Preliminaries
霍克斯过程
ρ t i = ∑ j : t j i ≤ t μ j i ϕ ( t − t j i ) (1) \rho_{t}^{i} = \sum_{j:t_{j}^{i} \leq t }\mu_{j}^{i}\phi(t-t_{j}^{i}) \tag{1} ρti=j:tji≤t∑μjiϕ(t−tji)(1)
上式表示霍克斯过程中,在时间 t t t 针对 原文 i i i 的预测转发到达率(arrival rate)的计算,一方面取决于时间 t t t ,时间越晚,则衰减越大,函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 表示一个时间衰减函数,不同场景函数形式不同。 μ j i \mu_{j}^{i} μji 表示针对原文 i i i 的转发用户 j j j 的影响人数。
通过上式,我们可以看到,霍克斯过程针对时间点 t t t 的到达率预测,其实就是把时间 t t t 之前的所有转发用户的影响大小与其转发时间的衰减系数乘积的算数加和。
Model
先上图:

针对上图,逐层介绍。
User Embedding
embedding层就是对用户的one-hot向量进行线性变换到K维,完成用户 ID 的embedding过程。
Path Encoding and Sum Pooling
这里的路径,我们通过举例说明。
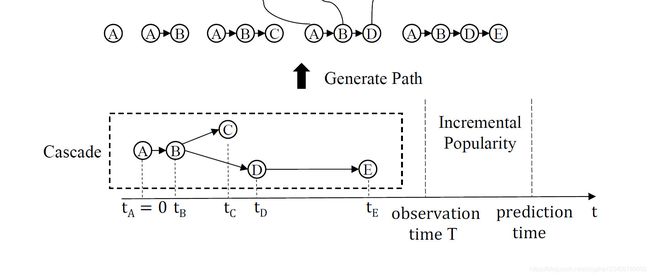
这里,作者是把级联中的每个箭头,从根节点出发,一直到目标结点,完成路径的分割。实际上,有N个结点,就有N-1个箭头(不包含根节点自己的自环),代表 N 条路径(包含根节点作为唯一结点的那条路径,见上图左上)。针对上面的每一条路径,输入GRU(RNN的一种),完成路径的编码。
沿着每条路径,将结点的embedding输入GRU,将路径输入完成最后一个隐藏状态向量作为这条路径最终的向量表示,向量维度为 H H H 。
一个级联(cascade)如果包含 m m m 条路径,如果不添加时间衰减因子,则级联的 c i c^i ci 用数学求和进行表示如下:
c i = ∑ j = 1 R T i h j i (7) c^i = \sum\limits_{j=1}^{R_T^i}{h_j^i} \tag{7} ci=j=1∑RTihji(7)
在式(7)中,路径条数 m m m 就等于 R T i {R_T^i} RTi 。表示原文 i i i 截止到计时时间 T T T 为止,共包含的路径条数。 对所有 R T i {R_T^i} RTi 条路径的隐含向量进行加和,可得到最终级联的向量表示 c i c^i ci 。
Non-parametric Time Decay Effect
如果按照上面的方式计算级联的向量表示 c i c^i ci ,则存在一个问题,就是不管是原文 i i i 刚发布就进行转发,还是过了好久才进行转发的行为,两者的重要程度都是一样的,这与霍克斯过程不符,与我们的认知也不相符合。
因此,需要在每条路径前面加一个系数 λ \lambda λ 。 作者是这样做的,首先将时间窗口 [ 0 , T ] [0, T] [0,T],分为 L 个同样大小的小范围。每个小范围对应一个 λ \lambda λ ,为 λ f ( T − t j i ) \lambda_{f(T-t_j^i)} λf(T−tji) 。这里的 f ( T − t j i ) f(T-t_j^i) f(T−tji) 就是一个将连续值转换为离散值的阶跃函数,对应到 0 , 1 , 2 , ⋯ , L − 1 0, 1, 2, \cdots, L-1 0,1,2,⋯,L−1。
文中没有指明的是,这些 { λ i ∣ i = 0 , 1 , ⋯ , L − 1 } \{\lambda_i | i=0, 1, \cdots, L-1\} {λi∣i=0,1,⋯,L−1} ,都是需要学习的参数,是模型的一部分。
最终的级联的向量表示 c i c^i ci 为时间衰减因子加权的路径向量之和,如下:
c i = ∑ j = 1 R T i λ f ( T − t j i ) h j i (9) c^i = \sum\limits_{j=1}^{R_T^i}{\lambda_{f(T-t_j^i)}h_j^i} \tag{9} ci=j=1∑RTiλf(T−tji)hji(9)
一些讨论
对于这篇文章,我有一些不太明白的地方,在最后一节《关于这篇论文,我的一些疑惑》中进行了整理,这里详细叙述一下。
文中写到batch size是32,但是我不明白的是如何进行批处理的。首先每个级联中包含的路径大小是不一样的;其次,对于路径而言,路径的长度也是不同的。
如果要进行批处理,需要保证路径数量和路径长度都是相同的,这个是怎么处理的,文中没有交代清楚,是做padding和截断吗,如何操作的???
另外,时间衰减因子 λ \lambda λ 是如何保证在 0 到 1 的范围内的,怎么做的归一化,文中也么有交代清楚,这个时间衰减因子的细节是什么呢???
关于这篇论文,我的一些疑惑
对于这篇论文,我存在以下一些疑惑,希望大家能够在评论区交流。特别是看过本文源代码的同学,能够解答我的疑惑。
- 文中使用GRU来计算同一cascade中不同路径的影响力向量。 但是每条路径的长度是不同的,这里是如何处理的?
- 每个cascade中包含的路径条数也是不同的,文中是如何处理的?
- 文中提到了batch size是32,这个32是指什么?
- 文中使用 λ f ( T − t j i ) \lambda_{f(T-t_j^i)} λf(T−tji) 来计算时间衰减因子,如何做归一化以保证 λ f ( T − t j i ) \lambda_{f(T-t_j^i)} λf(T−tji) 在 ( 0 , 1 ) (0, 1) (0,1) 范围中的?
这几个问题,作者都没有很清楚地交代,诚挚地希望大家能够在评论区解答我的疑惑。