论文《Cross-Session Aware Temporal Convolututional Network for Session-based Recommendation》阅读
论文《Cross-Session Aware Temporal Convolututional Network for Session-based Recommendation》阅读
- 论文概况
- Introduction
- Method
-
- A. Cross-Session Item Graph
- B.Temporal Convolutional Neural Network
- C. Session-Context Graph
- D. Recommendation Decoder
- 总结一下
- 一点不成熟的意见
论文概况
本文是美团发表在ICDM(CCF B会)的一个wrokshop上的一篇论文,聚焦于序列化推荐(sequential recommendation,或session-based recommendation(SBR))问题,提出了模型CA-TCN,如果没有问题的话,应该是最早使用全局图解决序列化推荐的模型。
Introduction
作者提出了几个问题:
- 现有模型没有考虑使用其他session信息来加强session内表示,造成了性能缺失
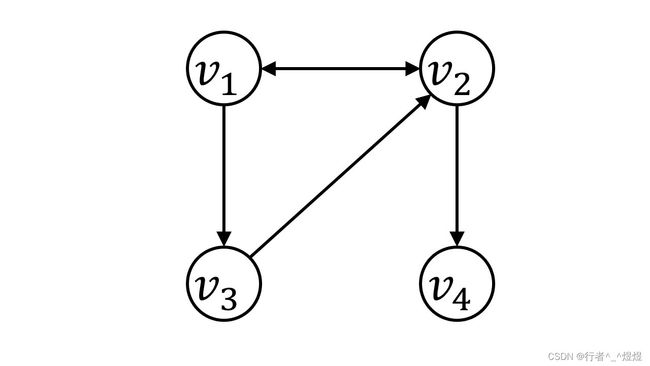
- 当前SBR流行的GNN方法存在缺陷,即GNN缺少了序列的位置信息,不同的序列构造完很可能是一幅图,例如 v 1 → v 2 → v 1 → v 3 → v 2 → v 4 v_1 \rightarrow v_2 \rightarrow v_1 \rightarrow v_3 \rightarrow v_2 \rightarrow v_4 v1→v2→v1→v3→v2→v4序列和 v 1 → v 3 → v 2 → v 1 → v 2 → v 4 v_1 \rightarrow v_3 \rightarrow v_2 \rightarrow v_1 \rightarrow v_2 \rightarrow v_4 v1→v3→v2→v1→v2→v4 两个序列,都可以构造成如图1所示的图
- GNN存在过度平滑问题,众所周知,GNN最深一般3、 4层,即最多能够描述长度为3到4的序列,这与我们的主观认识是不相符的。我们平常购物中,经常有之前买了一件衣服,过很长时间需要搭配一条裤子,这之间可能有过数十次购买经历,但是这两者却是紧密相关的。
对于上述几点,作者通过 1)使用时间卷积网络(Temporal Convolutional Network,TCN)完成序列学习,这可以保证长序列的因果关系;2)使用item-level来表征全局物品属性,即显示同一个物品在不同session中对不同用户的吸引(如一个人买苹果耳机可能是因为喜欢苹果这个品牌,也可能是单纯喜欢各种耳机);3)使用session-level来表征行为模式,即通过一个session来比较当前用户的一种行为模式,从而可以推测出不同模式之间的相似或不同。
Method
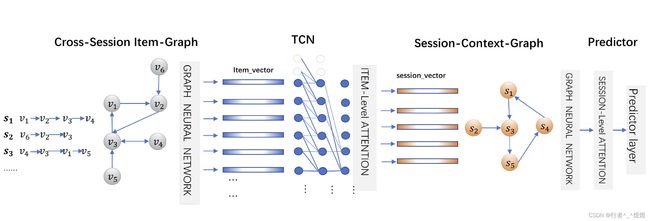
A. Cross-Session Item Graph
构造全局的cross-session图 G i t e m G_{item} Gitem,这里作者使用所有的session中的临边加入到一个总图中(即凡是有邻接的都接一遍)形成一个有向图,权重使用连接次数进行归一化。从而可以形成 A i n A_{in} Ain和 A o u t A_{out} Aout用来表示入度、出度,并对应两个可训练矩阵 W i n W_{in} Win和 W o u t W_{out} Wout。最终形成所有物品的矩阵表示 V ∈ R ∣ V ∣ × d i m V \in \mathbb{R}^{|V| \times dim} V∈R∣V∣×dim,GNN迭代过程如下:
V l + 1 = σ ( D − 1 ( W i n V l + W o u t V l + V l ) W l ) (1) V^{l+1} = \sigma(D^{-1}(W_{in}V^l + W_{out}V^l + V^l)W^l) \tag{1} Vl+1=σ(D−1(WinVl+WoutVl+Vl)Wl)(1)
上式中, D D D表示 A i n A_{in} Ain和 A o u t A_{out} Aout得出的度对角矩阵, W l W^l Wl表示可训练矩阵, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 表示激活函数。
这里,使用两个矩阵 W i n W_{in} Win和 W o u t W_{out} Wout显得有点多余,用一个矩阵就可以了
另外,这里对公式进行了一定修改,矩阵 W i n W_{in} Win和 W o u t W_{out} Wout 分别表示两个可训练矩阵, V ∈ R ∣ V ∣ × d i m V \in \mathbb{R}^{|V| \times dim} V∈R∣V∣×dim使用 ∣ V ∣ |V| ∣V∣来表示维度,与前文保持一致,原文使用 m m m与后文产生了冲突。
B.Temporal Convolutional Neural Network
这一部分使用前面GNN得出的物品embedding,传入TCN进行卷积。具体的,针对序列 s = { v s , 1 , v s , 2 , ⋯ , v s , n } s=\{v_{s, 1}, v_{s, 2}, \cdots, v_{s, n} \} s={vs,1,vs,2,⋯,vs,n},每个物品的向量使用GNN从 G i t e m G_{item} Gitem得到的全局embedding,即 [ v s , 1 , v s , 2 , ⋯ , v s , n ] [\mathbf{v}_{s, 1}, \mathbf{v}_{s, 2}, \cdots, \mathbf{v}_{s, n}] [vs,1,vs,2,⋯,vs,n],传入TCN,对会话 s s s中的每个物品向量 v s , i \mathbf{v}_{s, i} vs,i进行卷积操作 F F F:
F ( v s , i ) = ( v s , i ∗ d f ) = ∑ j = 0 k − 1 f ( j ) ⋅ v s , i − d ⋅ j (2) F(\mathbf{v}_{s, i})=(\mathbf{v}_{s, i}\ {*_{d}f} )=\sum_{j=0}^{k-1}{f(j)\cdot \mathbf{v}_{s,i-d\cdot j}} \tag{2} F(vs,i)=(vs,i ∗df)=j=0∑k−1f(j)⋅vs,i−d⋅j(2)
这里,对TCN具体内部操作没有过多了解,作者表示TCN感受野与神经网络层数呈指数关系,感受野内的节点等同于直接相连。
作者使用session序列最后一个TCN输出 s l o c a l s^{local} slocal作为local表示,即
s l o c a l = F ( v s , n ) (3) s^{local}=F(\mathbf{v}_{s, n}) \tag{3} slocal=F(vs,n)(3)
使用session内所有向量加权表示 s g l o b a l s^{global} sglobal得到global表示,即
s g l o b a l = ∑ i = 1 n α s , i ⋅ F ( v s , i ) (4) s^{global}=\sum_{i=1}^{n}{\alpha_{s,i}\cdot F(\mathbf{v}_{s, i})} \tag{4} sglobal=i=1∑nαs,i⋅F(vs,i)(4)
其中,注意力权重 α s , i \alpha_{s,i} αs,i通过当前物品 v s , i \mathbf{v}_{s, i} vs,i与session最后一个物品 v s , n \mathbf{v}_{s, n} vs,n计算得到,这里应该是为了计算不同位置物品针对session(如 s l o c a l s^{local} slocal所示,最后一个物品表示session)的影响力,具体如下:
α s , i = s o f t m a x ( σ ( W 1 F ( v s , n ) + W 2 F ( v s , i ) ) ) (5) \alpha_{s,i}=softmax(\sigma(\mathbf W_1F(\mathbf{v}_{s, n}) +\mathbf W_2F(\mathbf{v}_{s, i}))) \tag{5} αs,i=softmax(σ(W1F(vs,n)+W2F(vs,i)))(5)
C. Session-Context Graph
作者在这里构造了一个图 G s e s s i o n G_{session} Gsession,使用时间顺序上每个session前的 m m m个session作为候选,对 m m m个session的global向量进行KNN计算得到相似度的前 K K K个进行连接,得到所有session连接图,使用GAT计算不同session之间的权重系数,得到最终session的全局session表示如下所示:
s c r o s s = ∑ t ∈ N s β s , t t g l o b a l \mathbf s^{cross}=\sum_{t \in N_s}{\beta_{s,t}\mathbf t^{global}} scross=t∈Ns∑βs,ttglobal
这里对公式进行了一定修改,以方便理解,这里的下标 i i i 表示session编号, N s N_s Ns表示 G s e s s i o n G_{session} Gsession中当前session节点 s s s的邻居节点, β s , t \beta_{s,t} βs,t表示注意力系数,如原文公式(6)所示,这里从略。
D. Recommendation Decoder
session表示使用前面得到的所有向量加和,即
f = σ ( W l s l o c a l + W g s g l o b a l + W s s c r o s s ) f = \sigma(\mathbf W_l \mathbf s^{local} + \mathbf W_g \mathbf s^{global} + \mathbf W_s \mathbf s^{cross}) f=σ(Wlslocal+Wgsglobal+Wsscross)
s f i n a l = f ⋅ [ s l o c a l ∥ s g l o b a l ] + ( 1 − f ) s c r o s s (10) \mathbf s_{final} = f\cdot[\mathbf s^{local}\| \mathbf s^{global}] + (1-f)\mathbf s^{cross} \tag{10} sfinal=f⋅[slocal∥sglobal]+(1−f)scross(10)
-
这里, W l \mathbf W_l Wl、 W s \mathbf W_s Ws、 W g \mathbf W_g Wg是三个变维矩阵,得到的不应该是一个向量吗?怎么变成实数了???数学表达有问题啊这里
-
另外得到实数 f f f对 [ s l o c a l ∥ s g l o b a l ] [\mathbf s^{local}\| \mathbf s^{global}] [slocal∥sglobal]和 s c r o s s \mathbf s^{cross} scross进行相加,俩向量维度应该是一样的啊,此处明显不对
-
f f f应该是为了对两者进行平均,为什么这么操作作者也没有进行说明
得到最终的 s f i n a l \mathbf s_{final} sfinal,与每个物品 i i i的embedding进行内积并使用softmax进行归一化得到结果,使用交叉熵作为损失函数进行训练。如下所示:
y ^ i = s o f t m a x ( s f i n a l T v i ) \hat{y}_i=softmax(\mathbf s_{final}^\mathsf{T}\mathbf{v}_i) y^i=softmax(sfinalTvi)
总结一下
- 这篇文章使用TCN达到了长期依赖的描述
- 应该是第一个考虑不同session之间相互作用的作品
一点不成熟的意见
- 文中数学表达较为混乱,需要仔细对比和推敲
- 文中cross session概念较为浅显,一方面构造了一个会话图 G s e s s i o n G_{session} Gsession 作为session之间互相影响的证明,但是构造方面有点过于简单;另一方面构造了一个物品图 G i t e m G_{item} Gitem 用于描述物品在不同session之间的综合属性。但是从直觉上,本人认为使用TCN和GNN得到的embedding应该彼此分离,并在最终预测阶段进行拼接,效果应该会更好。理由如下:通过 G i t e m G_{item} Gitem 得到的物品embedding追求不同session之间物品的公有属性;而通过TCN得到的内部物品embedding则应该追求session自己的独特属性。