1. 驱动开发--基础知识
文章目录
- 1 驱动的概念
- 2 linux体系架构
- 3 模块化设计
-
- 3.1 微内核和宏内核
- 4 linux设备驱动分类
-
- 4.1 驱动分类
- 4.2 三类驱动程序详细对比分析
- 4.3 为什么字符设备驱动最重要
- 5 驱动程序的安全性要求
-
- 5.1 驱动是内核的一部分
- 5.2 驱动对内核的影响
- 5.3 常见驱动安全性问题
- 6 驱动应该这么学
-
- 6.1 先学好C语言
- 6.2 掌握相关预备知识
- 6.3 驱动学习阶段
- 6.4 驱动开发的准备工作
-
- 6.4.1 驱动开发的步骤
- 6.4.2 实践
- 6.5 最简单的模块源码分析
-
- 6.5.1 常用的模块操作命令
- 6.5.2 模块的安装
- 6.5.3 模块的版本信息
- 6.5.4 模块卸载
- 6.5.5 模块中常用宏
- 6.5.6 函数修饰符
- 6.5.7 printk函数详解
- 6.5.8 关于驱动模块中的头文件
- 6.5.9 驱动编译的Makefile分析
- 参考资料
该文内容源于朱有鹏老师的课程,按照自己的理解进行汇总,方便查阅。如有侵权,请告知删除。
1 驱动的概念
- 驱动一词的字面意思
- 物理上的驱动
- 硬件中的驱动
- linux内核驱动
软件层面的驱动广义上就是指:这一段代码操作硬件去动,所以这一段代码就叫硬件的驱动程序。(本质上是电力提供了动力,而驱动程序提供了操作逻辑方法)。
狭义上驱动程序就是专指操作系统中用来操控硬件的逻辑方法部分代码。
2 linux体系架构

(1)分层思想
(2)驱动的上面是系统调用API
(3)驱动的下面是硬件
(4)驱动自己本身也是分层的
3 模块化设计
3.1 微内核和宏内核
(1)宏内核(又称为单内核):将内核从整体上作为一个大过程实现,并同时运行在一个单独的地址空间。所有的内核服务都在一个地址空间运行,相互之间直接调用函数,简单高效。(紧耦合)
(2)微内核:功能被划分成独立的过程,过程间通过IPC进行通信。模块化程度高,一个服务失效不会影响另外一个服务。典型如windows。(松耦合)
(3)linux:本质上是宏内核,但是又吸收了微内核的模块化特性,体现在以下2个层面:
静态模块化 : 在编译时实现可裁剪,特征是想要功能裁剪改变必须重新编译。
动态模块化 : zImage可以不重新编译烧录,甚至可以不关机重启就实现模块的安装和卸载。
4 linux设备驱动分类
4.1 驱动分类
(1)分3类:字符设备驱动、块设备驱动、网络设备驱动
(2)分类原则:设备本身读写操作的特征差异
4.2 三类驱动程序详细对比分析
(1)字符设备,准确的说应该叫“字节设备”,软件操作设备时是以字节为单位进行的。典型的如LCD、串口、LED、蜂鸣器、触摸屏······
(2)块设备,块设备是相对于字符设备定义的,块设备被软件操作时是以块(多个字节构成的一个单位)为单位的。设备的块大小是设备本身设计时定义好的,软件是不能去更改的,不同设备的块大小可以不一样。常见的块设备都是存储类设备,如:硬盘、NandFlash、iNand、SD····
(3)网络设备,网络设备是专为网卡设计的驱动模型,linux中网络设备驱动主要目的是为了支持API中socket相关的那些函数工作。
4.3 为什么字符设备驱动最重要
(1)常见大量设备都属于字符设备
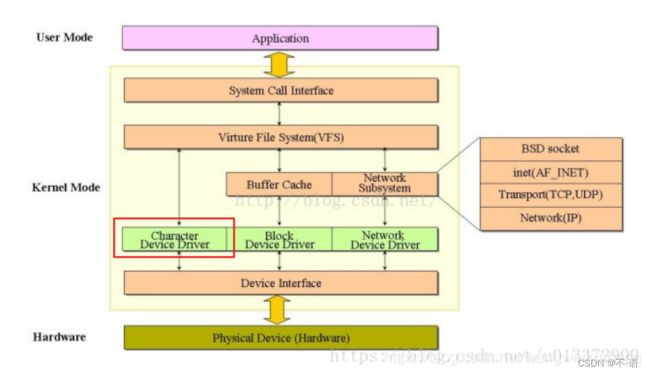
linux一切皆文件,则linux下的字符设备驱动也是以文件的形式呈现。既然是文件,那无外乎文件的一系列操作,其实我们之所以可以对文件进行一系列操作最为本质的原因就是文件系统的实现。在linux内核中(中间抽象一层,这就好比阿里当年想把快递拿下,搞出了菜鸟驿站,管你什么快递,都放到我这里,我来为用户服务!),在各种类型的文件系统上在加一层,抽象出了VFS,也正是VFS的实现对于我们来说管你底层是什么类型的文件系统对上完全没有影响。
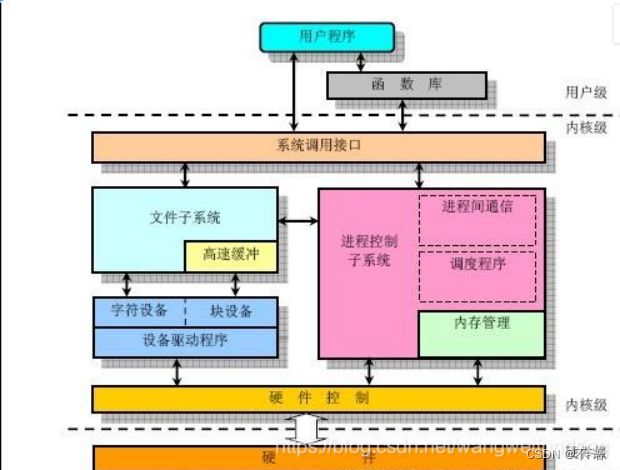
从架构图上可以清晰的发现,字符设备驱动的架构是如此简单,当应用层操作的时候通过系统调用转到内核层,内核中实现文件操作的时候就是驱动代码实现,并没有调用任何文件系统, 相当于我们直接和vfs对接就ok!
(2)举例说明非标准类型字符设备驱动
基于ZYNQ平台开发的字符驱动,属于非标准类型字符设备驱动。
5 驱动程序的安全性要求
5.1 驱动是内核的一部分
- 驱动已经成为内核中最庞大的组成部分
- 内核会直接以函数调用的方式调用驱动代码
- 驱动的动态安装和卸载都会“更改”内核
5.2 驱动对内核的影响
- 驱动程序崩溃甚至会导致内核崩溃
- 驱动的效率会影响内核的整体效率
- 驱动的漏洞会造成内核安全漏洞
5.3 常见驱动安全性问题
- 未初始化指针
- 恶意用户程序
- 缓冲区溢出
- 竞争状态
6 驱动应该这么学
6.1 先学好C语言
6.2 掌握相关预备知识
- 硬件操作方面
- 应用层API
6.3 驱动学习阶段
- 注重实践,一步一步写驱动
- 框架思维,多考虑整体和上下层
- 先通过简单设备学linux驱动框架
- 学会总结、记录,这会有助于理解
6.4 驱动开发的准备工作
(1)正常运行linux系统的开发板。要求开发板中的linux的zImage必须是自己编译的,不能是别人编译的。
(2)内核源码树,其实就是一个经过了配置编译之后的内核源码。
(3)nfs挂载的rootfs,主机ubuntu中必须搭建一个nfs服务器。
6.4.1 驱动开发的步骤
- 驱动源码编写、Makefile编写、编译
- insmod装载模块、测试、rmmod卸载模块
6.4.2 实践
1)copy原来提供的x210kernel.tar.bz2,找一个干净的目录(我的目录/x210_driver/kernel),解压之,并且配置编译。编译完成后得到了:1. 内核源码树。2.编译ok的zImage
2)fastboot将第1步中得到的zImage烧录到开发板中去启动(或者将zImage丢到tftp的共享目录,uboot启动时tftp下载启动),将来驱动编译好后,就可以在这个内核中去测试。因为这个zImage和内核源码树是一伙的,所以驱动安装时版本校验不会出错。
6.5 最简单的模块源码分析
最简单的驱动模块源码:
#include // module_init module_exit
#include // __init __exit
// 模块安装函数
static int __init chrdev_init(void)
{
printk(KERN_INFO "chrdev_init helloworld init\n");
return 0;
}
// 模块卸载函数
static void __exit chrdev_exit(void)
{
printk(KERN_INFO "chrdev_exit helloworld exit\n");
}
module_init(chrdev_init); //执行这个宏就相当于进到模块安装函数里面执行函数
module_exit(chrdev_exit); //执行这个宏就相当于进到模块卸载函数里面执行函数
// MODULE_xxx这种宏作用是用来添加模块描述信息
MODULE_LICENSE("GPL"); // 描述模块的许可证
MODULE_AUTHOR("aston"); // 描述模块的作者
MODULE_DESCRIPTION("module test"); // 描述模块的介绍信息
MODULE_ALIAS("alias xxx"); // 描述模块的别名信息
6.5.1 常用的模块操作命令
模块命令功能
lsmod (list module, 将模块列表显示) 功能是打印出当前内核中已经安装过的模块列表
insmod(install module,安装模块) 功能是向当前内核中去安装一个模块,用法是insmod xxx.ko
modinfo(module information,模块信息) 功能是打印出一个内核模块的自带信息,用法是modinfo xxx.ko
rmmod(remove module,卸载模块) 功能是从当前内核中卸载一个已经安装了的模块,用法是rmmod xxx(注意卸载模块时只需要输入模块名即可,不能加.ko后缀)
modprobe、depmod 暂时用不到,后面再说
6.5.2 模块的安装
(1) 先lsmod再insmod看安装前后系统内模块记录。实践测试标明内核会将最新安装的模块放在lsmod显示的最前面。
(2) insmod与module_init宏。模块源代码中用module_init宏声明了一个函数(在我们这个例子里是chrdev_init函数),作用就是指定chrdev_init这个函数和insmod命令绑定起来,也就是说当我们insmod module_test.ko时,insmod命令内部实际执行的操作就是帮我们调用chrdev_init函数。照此分析,那insmod时就应该能看到chrdev_init中使用printk打印出来的一个chrdev_init字符串,但是实际没看到。原因是ubuntu中拦截了,要怎么才能看到呢?在ubuntu中使用dmesg命令就可以看到了。
(3) 模块安装时insmod内部除了调用module_init宏所声明的函数外,实际还做了一些别的事(譬如lsmod能看到多了一个模块也是insmod在内部做了记录),但是我们就不用管了。
6.5.3 模块的版本信息
- 使用modinfo查看模块的版本信息
- 内核zImage中也有一个确定的版本信息
- insmod时模块的vermagic必须和内核的相同,否则不能安装,报错信息为:insmod: ERROR: could not insert module module_test.ko: Invalid module format
- 模块的版本信息是为了保证模块和内核的兼容性,是一种安全措施
- 如何保证模块的vermagic和内核的vermagic一致?编译模块的内核源码树就是编译正在运行的这个内核的那个内核源码树即可。说白了就是模块和内核要同出一门。
6.5.4 模块卸载
- module_exit和rmmod的对应关系
- lsmod查看rmmod前后系统的模块记录变化
6.5.5 模块中常用宏
| 宏名 | 作用 |
|---|---|
| MODULE_LICENSE(“GPL”) | 描述模块的许可证 |
| MODULE_AUTHOR(“aston”) | 描述模块的作者 |
| MODULE_DESCRIPTION(“module test”) | 描述模块的介绍信息 |
| MODULE_ALIAS(“alias xxx”) | 描述模块的别名信息 |
注:模块的许可证,一般声明为GPL许可证,而且最好不要少,否则可能会出现莫名其妙的错误(譬如一些明显存在的函数提升找不到)。
6.5.6 函数修饰符
- __init,本质上是个宏定义,在内核源代码中就有#define __init xxxx。这个__init的作用就是将被他修饰的函数放入.init.text段中去(本来默认情况下函数是被放入.text段中)。整个内核中的所有的这类函数都会被链接器链接放入.init.text段中,所以所有的内核模块的__init修饰的函数其实是被统一放在一起的。内核启动时统一会加载.init.text段中的这些模块安装函数,加载完后就会把这个段给释放掉以节省内存。2)
- __exit原理也一样。
6.5.7 printk函数详解
printk是内核态信息打印函数,功能和比标准C库的printf类似。
函数原型:int printk(const char *fmt, …)
消息打印级别:fmt----消息级别:不同级别使用不同字符串表示,数字越小,级别越高
#define KERN_EMERG “<0>” 用于紧急消息, 常常是那些崩溃前的消息.
#define KERN_ALERT “<1>” 需要立刻动作的情形.
#define KERN_CRIT “<2>” 严重情况, 常常与严重的硬件或者软件失效有关.
#define KERN_ERR “<3>” 用来报告错误情况; 设备驱动常常使用 KERN_ERR 来报告硬件故障.
#define KERN_WARNING “<4>” 有问题的情况的警告, 这些情况自己不会引起系统的严重问题.
#define KERN_NOTICE “<5>” 正常情况, 但是仍然值得注意. 在这个级别一些安全相关的情况会报告.
#define KERN_INFO “<6>” 信息型消息. 在这个级别, 很多驱动在启动时打印它们发现的硬件的信息.
#define KERN_DEBUG “<7>” 用作调试消息.
(1)printk在内核源码中用来打印信息的函数,用法和printf非常相似。
(2)printk和printf最大的差别:printf是C库函数,是在应用层编程中使用的,不能在linux内核源代码中使用;printk是linux内核源代码中自己封装出来的一个打印函数,是内核源码中的一个普通函数,只能在内核源码范围内使用,不能在应用编程中使用。
(3)printk相比printf来说还多了个:打印级别的设置。printk的打印级别是用来控制printk打印的这条信息是否在终端上显示的。应用程序中的调试信息要么全部打开要么全部关闭,一般用条件编译来实现(DEBUG宏),但是在内核中,因为内核非常庞大,打印信息非常多,有时候整体调试内核时打印信息要么太多找不到想要的要么一个没有没法调试。所以才有了打印级别这个概念。
(4)操作系统的命令行中也有一个打印信息级别属性,值为0-7。当前操作系统中执行printk的时候会去对比printk中的打印级别和我的命令行中设置的打印级别,小于我的命令行设置级别的信息会被放行打印出来,大于的就被拦截的。
可以用cat /proc/sys/kernel/printk查看打印级别;
可以用echo 4 /proc/sys/kernel/printk来设置打印级别为4
譬如我的ubuntu中的打印级别默认是4,那么printk中设置的级别比4小的就能打印出来,比4大的就不能打印出来。
(5)ubuntu中这个printk的打印级别控制没法实践,ubuntu中不管你把级别怎么设置都不能直接打印出来,必须dmesg命令去查看。
6.5.8 关于驱动模块中的头文件
驱动源代码中包含的头文件和原来应用编程程序中包含的头文件不是一回事。应用编程中包含的头文件是应用层的头文件,是应用程序的编译器带来的(譬如gcc的头文件路径在 /usr/include下,这些东西是和操作系统无关的)。驱动源码属于内核源码的一部分,驱动源码中的头文件其实就是内核源代码目录下的include目录下的头文件。所以包含头文件时要像#include
6.5.9 驱动编译的Makefile分析
makefile源码
#ubuntu的内核源码树,如果要编译在ubuntu中安装的模块就打开这2个
#KERN_VER = $(shell uname -r)
#KERN_DIR = /lib/modules/$(KERN_VER)/build
#开发板的linux内核的源码树目录
KERN_DIR = /root/driver/kernel
obj-m += module_test.o
all:
make -C $(KERN_DIR) M=`pwd` modules
cp:
cp *.ko /root/porting_x210/rootfs/rootfs/driver_test
.PHONY: clean
clean:
make -C $(KERN_DIR) M=`pwd` modules clean
(1)KERN_DIR,变量的值就是用来编译这个模块的内核源码树的目录,分为在Ubuntu中和开发板中两种
(2)obj-m += module_test.o,表示我们要将module_test.c文件编译成一个模块
(3)make -C $(KERN_DIR) M=pwd modules 这个命令用来实际编译模块,工作原理就是:利用make -C进入到我们指定的内核源码树目录下,然后在源码目录树下借用内核源码中定义的模块编译规则去编译这个模块,编译完成后把生成的文件还拷贝到当前目录下,完成编译。
(4)make clean ,用来清除编译痕迹
总结:模块的makefile非常简单,本身并不能完成模块的编译,而是通过make -C进入到内核源码树下,借用内核源码的体系来完成模块的编译链接的。这个Makefile本身是非常模式化的,3和4部分是永远不用动的,只有1和2需要动。内核源码树的目录,必须根据自己的编译环境确定的。
参考资料
Makefile
注:
- module_param(参考文末链接) // 即使文件已经定义参数值,参数传递会覆盖已经定义的。
- 模块化设计,自己写好的代码按功能单独封装在一个KO里面,EXPORT_SYMBOL之后就将函数放到了全局符号表(一个链式结构),内核可以找到相应的函数。其他模块可以调用它实现代码的共用。有点类似于动态库。