python爬虫从0到1(第五天)——Xpath与Jsonpath
数据解析之Xpath与Jsonpath
取其精华去其糟粕
通过前面几篇文章的学习,我们已经能够处理简单的需要登录的网站并且能够去分析我们需要的目标数据所在的url了,但可以发现获取到的响应不是一段html文本就是很长的一串json串,也就是说目标数据中掺杂了很多的无用信息。不管是html也好还是json也好,我们都可以很明显的看到它们的结构就像是一个大盒子,大盒子里面又有小盒子这样的结构,而这个入口呢我们可以称其为节点(要深入了解的朋友请自行学习前端三剑,对爬虫来说还是比较重要的)。那么对于节点对应的数据我们又要如何去进行提取呢?其实刚刚已经说过啦,它就像是大盒子里面包含了小盒子,例如html中包含了body和head,body中有有div、table等,所以也能知道其具有的层次关系,所以要去提取出其中的节点的话我们只要去一层一层地剥开它的“皮”就好了。在python中的话是有很多方法能够实现我们的需求的库,在这些库的帮助下我们就能够高效准确得提取出我们需要的目标数据了。
一、Xpath的使用
xpath全称为XML Path Language,即XML路径语言,用以在XML文档中查找信息,同时也是适用于HTML文档的搜索。因此我们完全可以在爬虫中使用xpath来进行信息提取。
1.1 xpath节点关系
在XML或者HTML中的标签就是我们所说的节点,其中最外层的称为根节点。如下方代码的节点分析。
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italiantitle>
<author>Giada De Laurentiisauthor>
<year>2005year>
<price>30.00price>
book>
<book category="CHILDREN">
<title lang="en">Harry Pottertitle>
<author>J K. Rowlingauthor>
<year>2005year>
<price>29.99price>
book>
<book category="WEB">
<title lang="en">Learning XMLtitle>
<author>Erik T. Rayauthor>
<year>2003year>
<price>39.95price>
book>
bookstore>
其转换为树结构如下图所示
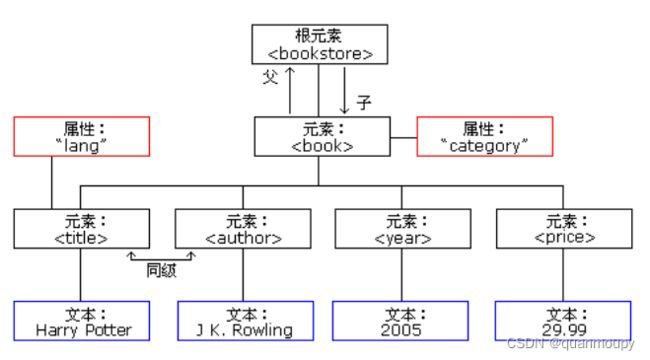
其中我们就可以看到
bookstore就是根节点,然后其包含了三个book标签,称其为bookstore的子节点,反之称bookstore为book的父节点,book节点下又有title、author、year、price四个子节点,这四个子节点位于同一父节点下互为兄弟节点。代入代码分析是同样的道理,如下图。


1.2 lxml的使用
lxml是HTML和XML的解析器,其主要功能就是能够从XML和HTML中解析和提取数据。
安装方式:通过包管理工具pip进行安装
pip install lxml
安装完成后代码中导包进行使用即可,导包方式
from lxml import etree
导包后要将字符串实例化为Element对象,该对象具有xpath的方法,返回的结果为列表类型。
html = etree.XML(text) # 或html = etree.HTML(text) # 当为XML时表示处理XML文档,为HTML时表示处理HTML文档 result_list = html.xpath('写入xpath路径表达式')
1.3 Xpath表达式
定位语法主要依赖以下符号
表达式 说明 举例 /从根节点开始选取(绝对路径) /html/div/span //从任意节点开始选取(相对路径) //input .选取当前节点 ..选取当前节点的父节点 //input/… 会选取 input 的父节点 @选取属性,或者根据属性选取 //input[@data] 选取具备 data 属性的 input 元素 //@data 选取所有 data 属性 *通配符,表示任意节点或任意属性 //*
接下来以1.1中的XML文本为例学习xpath表达式
from lxml import etree xml_local = etree.XML(xml) # 选取根节点bookstore。 假如路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径 xpath_bookstore = xml_local.xpath('/bookstore') print(xpath_bookstore) print(type(xpath_bookstore[0])) # 选取根节点bookstore的子节点book xpath_book = xml_local.xpath('/bookstore/book') print(xpath_book) print(type(xpath_book[0])) # 跨节点进行解析book的结果 xpath_book = xml_local.xpath('//book') print(xpath_book) # 选择bookstore节点的所有book节点 xpath_book = xml_local.xpath('/bookstore//book') print(xpath_book) # 提取对应位置的标签,注意:xpath中下标是从1开始 xpath_book1 = xml_local.xpath('//book[1]') print(xpath_book1) # 文本提取 xpath_text_book = xml_local.xpath('//book[1]//text()') print(xpath_text_book) # 根据属性值来提取标签 xpath_book = xml_local.xpath('//book/title[@lang="eng"]//text()') print(xpath_book) # 获取标签中的属性值 xpath_elements = xml_local.xpath('//book/title/@lang') print(xpath_elements) # 选取bookstore子节点中最后一个book节点中的元素 last_book = xml_local.xpath('//book[last()]/title/text()') print(last_book) # 选取bookstore子节点book中title文本,从第二个开始选取 xpath_large1 = xml_local.xpath('//book[position()>1]/title/text()') print(xpath_large1) # 仅选择文本为Harry Potter的title的文本 xpath_book_harry = xml_local.xpath('//book/title[text()="Harry Potter"]/text()') print(xpath_book_harry) # 选取 bookstore 元素中的 book 元素的所有 title 文本,且其中的 price 元素的值须大于 35.00 xpath_price_l35 = xml_local.xpath('book[price>35]/title/text()') print(xpath_price_l35) # *选取所有节点 xpath_all = xml_local.xpath('//book/*') print(xpath_all) # 选取所有带有属性的title节点 xpath_all_title = xml_local.xpath('//book/title[@*]') print(xpath_all_title) # 使用"|"两个表达式分别提取title和price的结果 xpath_both_pt = xml_local.xpath('//book/title | //book/price') print(xpath_both_pt) # 通过在路径表达式中使用“|”运算符,可以选取若干个路径。 # 选取 book 元素的所有 title 和 price 元素。 xml = etree.XML(str) xpath_data = xml.xpath("//book/title | //book/price") print(xpath_data) # 选取文档中的所有 title 和 price 元素。 xml = etree.XML(str) xpath_data = xml.xpath("//title | //price") print(xpath_data) # 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 xml = etree.XML(str) xpath_data = xml.xpath("/bookstore/book/title | //price") print(xpath_data)
上方代码请逐个运行测试。
二、json的数据提取
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前端与后端之间的数据交互。

1.1 json.dumps()和json.loads()是json格式处理函数
可以这么理解,json是字符串
(1)json.dumps()函数是将一个Python数据类型字典转换为json格式
json.dumps()函数是将字典转化为字符串
json.dumps(python数据类型字典, indent=空格数, ensure_ascii=False)
indent:参数根据数据格式缩进显示,读起来更加清晰
ensure_ascii=True:默认输出ASCLL码,如果把这个该成False,就可以输出中文
(2)json.loads()函数是将json格式数据转换为字典
json.loads()函数是将字符串转化为字典
json.loads(json字符串)
import json
# json.dumps 实现python类型转化为json字符串
# json.dumps(dict_data, indent=2, ensure_ascii=False)
# dict_data 要转换的数据
# indent实现换行和空格
# ensure_ascii=False实现让中文写入的时候保持为中文
import json
dict_data = {
'name': '靓女',
'age': 18
}
# json.dumps() 将python数据类型(字典)转换为json(字符串)
json_str = json.dumps(dict_data,indent =2, ensure_ascii=False)
print(json_str) # 发现引号变成了双引号,因为json格式的引号为双引号
print(type(json_str)) # 字符串类型
# json.loads()实现json(字符串)转化为python的数据类型(字典)
python_dict = json.loads(json_str)
print(python_dict) # 发现双引号又变为单引号了
print(type(python_dict)) # 字典类型
2.2 json.dump()和json.load()主要用来读写json文件的函数
(1) json.dump()函数是将一个Python数据类型字典写入到json文件里面
json.dump(python数据类型字典, 文件变量,indent=空格数, ensure_ascii=False)
文件变量:open返回的变量
indent:参数根据数据格式缩进显示,读起来更加清晰
ensure_ascii=True:默认输出ASCLL码,如果把这个该成False,就可以输出中文
(2)json.load()函数是将json文件的字符串转化为python数据类型的列表
# json.dump 实现把python类型写入json类文件对象
# json.dump(dict_data, 文件变量,indent=空格数, ensure_ascii=False)
# dict_data 要转换的数据
# indent实现换行和空格
# ensure_ascii=False实现让中文写入的时候保持为中文
# json.dump()函数将一个python数据类型列表(字典)写入到json文件
with open("dict_data.json", "w", encoding="utf-8") as f:
json.dump(dict_data, f, ensure_ascii=False) # 查看写入的文件发现转换为json类型了
# json.load()函数 将json文件的数据转换为python数据类型
with open("dict_data.json", "r", encoding="utf-8") as f:
python_dict = json.load(f)
print(python_dict) # 引号又变为单引号了
print(type(python_dict)) # 发现又变为字典类型了
总结:
json.dumps()函数是将一个Python数据类型(字典)转换为json类型(字符串) json.dump()函数是将一个Python数据类型(字典)写入到json文件里面并且转换为json类型(字符串) json.loads()函数是将json格式(字符串)转换为python数据类型(字典) json.load()函数是将json文件的json数据类型(字符串)转换为python数据类型(字典)
三、jsonpath
3.1 jsonpath介绍
用来解析多层嵌套的json数据;JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
4.2 JsonPath 对于 JSON 来说,相当于 XPath 对于 XML。
安装方法:pip install jsonpath
语法: jsonpath.jsonpath(json数据,筛选条件)
没筛选到则返回False
官方文档:http://goessner.net/articles/JsonPath
4.3 JsonPath语法
| JsonPath | 根节点 |
|---|---|
| $ | 根节点(就相当于windows电脑的此电脑) |
| @ | 当前选中得节点 |
| . | 选取子节点 |
| … | 跨节点 |
| * | 匹配所有元素节点 |
| [] | 迭代器标示(可以在这里面做简单的迭代操作,如列表下标,根据内容选值等) |
| [,] | 支持迭代器中做多选 |
| ?() | 通过条件过滤数据 |
| () | 支持表达式计算 |
4.4代码示例
dict_data = {"store": {
"book": [
{"category": "reference",
"author": "吴承恩",
"title": "西游记",
"price": 8.95
},
{"category": "fiction",
"author": "曹雪芹",
"title": "红楼梦",
"price": 12.99
},
{"category": "fiction",
"author": "罗贯中",
"title": "三国演义",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "fiction",
"author": "施耐庵",
"title": "水浒传",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
import jsonpath
import json
dict_data = {"store": {
"book": [
{"category": "reference",
"author": "吴承恩",
"title": "西游记",
"price": 8.95
},
{"category": "fiction",
"author": "曹雪芹",
"title": "红楼梦",
"price": 12.99
},
{"category": "fiction",
"author": "罗贯中",
"title": "三国演义",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "fiction",
"author": "施耐庵",
"title": "水浒传",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
# $ 根节点 .选取子节点
# 获取store的值
citylist = jsonpath.jsonpath(dict_data, '$.store')
# 获取book的值
citylist = jsonpath.jsonpath(dict_data, '$.store.book')
print(citylist)
# * 匹配所有元素节点
# 获取book所有值
citylist = jsonpath.jsonpath(dict_data, '$.store.book.*')
print(citylist)
# .. 跨节点 $..元素 跨过根节点到元素之间的节点直接找到元素
# 使用..获取book的值
citylist = jsonpath.jsonpath(dict_data, '$..book')
print(citylist)
# * 匹配所有元素节点
#使用..获取book所有值
citylist = jsonpath.jsonpath(dict_data, '$..book.*')
print(citylist)
# 获取根节点下面的所有值
citylist = jsonpath.jsonpath(dict_data, '$..*')
print(citylist)
# 总结: . 和..
# 使用.选取子节点必须要一个节点一个节点的取,直到定位到对应的节点元素为止
# 使用.. 可以直接定位到要取的值,不用考虑中间有多少节点
# 获取第三本书
# 这里的第几本书是不是列表里面的元素,同学们还记不记得我们列表里面怎么取列表里面某个值的
# # $ 根节点 .选取子节点 [] 迭代器标示(下标取值) * 匹配所有元素节点
citylist = jsonpath.jsonpath(dict_data, '$.store.book[2]')
print(citylist)
# 获取前两本书
# [,] 多个下标
citylist = jsonpath.jsonpath(dict_data, '$.store.book[0,1]') # 注意下标也是从0开始,0代表第一个,1代表第二个,取第一个和第二个
print(citylist)
citylist = jsonpath.jsonpath(dict_data, '$.store.book[:1]')
print(citylist)
# 总结 :这里获取列表里面的某个元素跟我们python基础里面一样的通过下标获取
# () 支持表达式计算 @.length-1 取最后一个值
# $..book[(@.length-1)] | $..book[-1:]
# 最后一本书
citylist = jsonpath.jsonpath(dict_data, '$..book[(@.length-1)]')
print(citylist)
citylist = jsonpath.jsonpath(dict_data, '$..book[-1:]')
print(citylist)
citylist = jsonpath.jsonpath(dict_data, '$..book.*')
print(len(citylist)-1)
# 总结: @.length 就相当len()函数
# 获取有author的所有值
# [] 根据内容选值 ?()根据条件过滤 @ 当前选中的节点
"""
分析:
1. 根据json数据可以看出,author是在book的列表里的列表
2. 所以我们要有 $.store.book[] ,book里面的值
3.接下来我就要筛选出book里面的有author的值了
4.筛选的话就要使用 ?()根据条件过滤
5.里面的值就是author ,我们要选择author这个节点 就可以使用 @
"""
citylist = jsonpath.jsonpath(dict_data, '$.store.book[*].author')
print(citylist)
citylist = jsonpath.jsonpath(dict_data, '$.store.book[?(@.author)]')
print(citylist)
# 获取有isbn的所有值
citylist = jsonpath.jsonpath(dict_data, '$.store.book[?(@.isbn)]')
print(citylist)
# 获取价格小于10的所有书
citylist = jsonpath.jsonpath(dict_data, '$.store.book[?(@.price<10)]')
print(citylist)