【python实现网络爬虫20】知乎热榜爬取
知乎热榜爬取
- 1. 目标网址
- 2. 实战解析
-
- 2.1 标题信息爬取
- 2.2 热度信息爬取
- 2.3 图片爬取
- 2.4 新闻介绍爬取
- 3 全部代码
手动反爬虫: 原博地址
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
如若转载,请标明出处,谢谢!
1. 目标网址
要爬取的网址如下:知乎热榜

爬取的内容:标题、热度、新闻介绍和图片,重点在于异常处理,有些热搜并不是全部内容都有的
2. 实战解析
首先导入常用的爬虫模块,并设置headers,进行目标网址的请求,代码如下
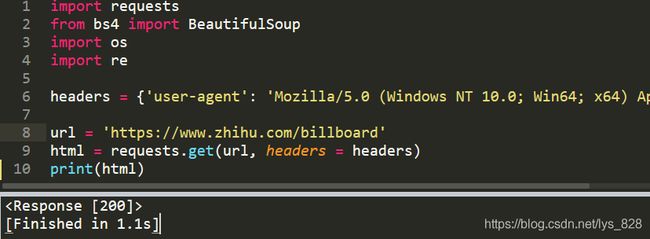
import requests
from bs4 import BeautifulSoup
import os
import re
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'https://www.zhihu.com/billboard'
html = requests.get(url, headers = headers)
print(html)
输出结果为:(可以正常请求网页的信息,因此可以进行下一步)
然后在热搜的空白界面鼠标右键点击弹出的选项查看源代码,可以发现标题,热度和图片的链接都在网页的标签中,而具体的新闻介绍是在script中。因此为了爬取方便可以针对标签的爬取使用bs库解析,后面的新闻介绍使用正则表达式提取

2.1 标题信息爬取
可以发现对于出现在热搜上的信息是必然有标题的,因此只需要查看标签进行相应内容的获取即可,回到热搜界面,鼠标右键进入检查界面,定位标题标签,共50条信息,进行匹配验证如下
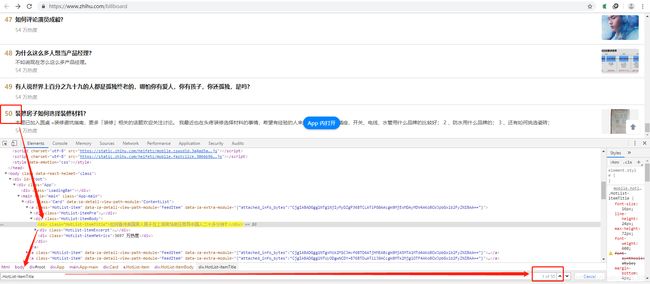
这部分代码如下
soup = BeautifulSoup(html.text, 'lxml')
titles = soup.select('.HotList-itemTitle')
for title in titles:
print('title:', title.text)
输出结果为:(截取部分输出结果)

2.2 热度信息爬取
和上面标题信息获取类似,定位标题标签,共50条信息,进行匹配验证如下
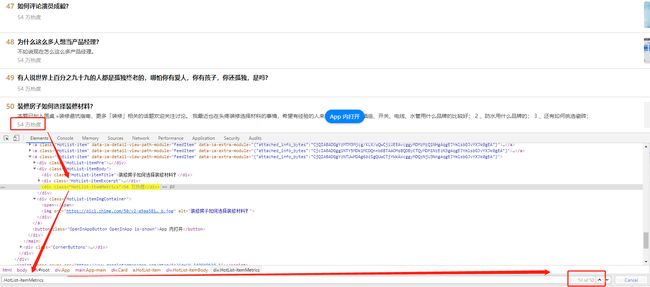
这部分代码如下:
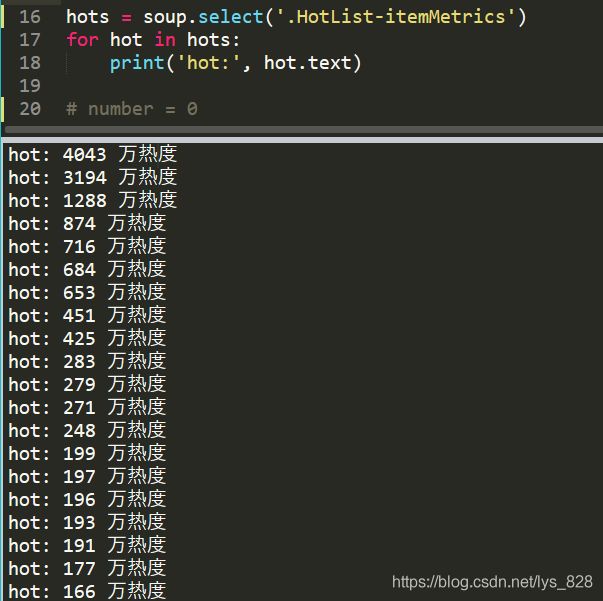
hots = soup.select('.HotList-itemMetrics')
for hot in hots:
print('hot:', hot.text)
输出结果为:(截取部分输出结果)
2.3 图片爬取
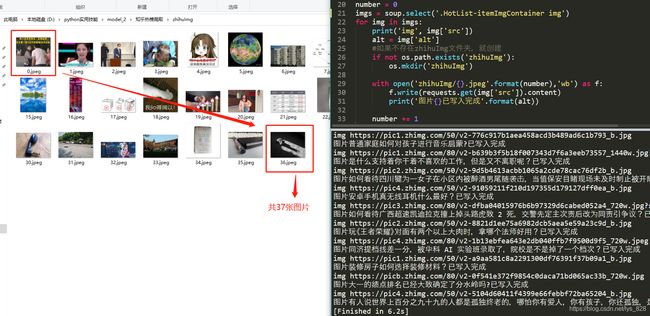
图片的标签定位也类似,如下,但是存在有些热搜不存在图片的情况,比如这里只有37张图片

代码如下,基本代码都在之前的内容中讲过,这里就直接给出
number = 0
imgs = soup.select('.HotList-itemImgContainer img')
for img in imgs:
print('img', img['src'])
alt = img['alt']
#如果不存在zhihuImg文件夹,就创建
if not os.path.exists('zhihuImg'):
os.mkdir('zhihuImg')
with open('zhihuImg/{}.jpeg'.format(number),'wb') as f:
f.write(requests.get(img['src']).content)
print('图片{}已写入完成'.format(alt))
number += 1
输出结果为:(截取部分输出结果)
2.4 新闻介绍爬取
这部分的信息是在script里,因此使用正则表达式进行匹配较为方便,只需要把目标内容使用 .*? 代替即可,页面解析如下(注意这里是在网页的源代码处,前面的三个信息的获取是在检查界面,其实也可以直接在源代码界面直接匹配前面三个信息)

这部分代码如下,注意缺失的数据处理:
int_re = re.compile('"excerptArea":{"text":"(.*?)"}',re.S|re.I)
int_results = int_re.findall(html.text)
for int_r in int_results:
if int_r is None or int_r == '':
continue
print(int_r)
print('-'*20)
输出结果为:(截取部分结果)

3 全部代码
至此四个字段的内容获取完毕,全部的代码如下
import requests
from bs4 import BeautifulSoup
import os
import re
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'https://www.zhihu.com/billboard'
html = requests.get(url, headers = headers)
# print(html)
soup = BeautifulSoup(html.text, 'lxml')
titles = soup.select('.HotList-itemTitle')
for title in titles:
print('title:', title.text)
hots = soup.select('.HotList-itemMetrics')
for hot in hots:
print('hot:', hot.text)
number = 0
imgs = soup.select('.HotList-itemImgContainer img')
for img in imgs:
print('img', img['src'])
alt = img['alt']
#如果不存在zhihuImg文件夹,就创建
if not os.path.exists('zhihuImg'):
os.mkdir('zhihuImg')
with open('zhihuImg/{}.jpeg'.format(number),'wb') as f:
f.write(requests.get(img['src']).content)
print('图片{}已写入完成'.format(alt))
number += 1
int_re = re.compile('"excerptArea":{"text":"(.*?)"}',re.S|re.I)
int_results = int_re.findall(html.text)
for int_r in int_results:
if int_r is None or int_r == '':
continue
print(int_r)
print('-'*20)