好用的小技能(Python库:pytest-assume、itertools、faker等)
pytest不间断继续断言:pytest-assume插件
pytest-assume 插件,上一个断言失败,可继续执行后续的断言
-
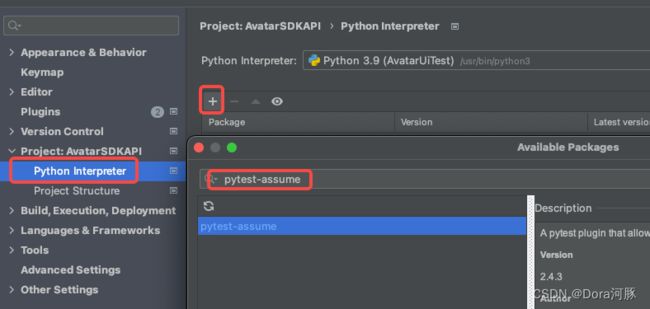
安装说明:在 Python Interpreter点击“+”,搜索“pytest-assume”,点击安装
-
使用示例
#!/usr/bin/env python3
#!coding:utf-8
import pytest
@pytest.mark.parametrize(('x', 'y'), [(1, 1), (1, 0), (0, 1)])
def test_simple_assume(x, y):
assert x == y #如果这个断言失败,则后续都不会执行
assert True
assert False
@pytest.mark.parametrize(('x', 'y'), [(1, 1), (1, 0), (0, 1)])
def test_pytest_assume(x, y):
pytest.assume(x == y) #即使这个断言失败,后续仍旧执行
pytest.assume(True)
pytest.assume(False)
intertools:
— 为高效循环而创建迭代器的函数
itertools.product()笛卡尔积,相当于嵌套的for循环,提高for循环效率,优化性能
更多用法,可以看官网文档itertools,和python itertools.product的用法
使用示例:
# for循环要在list1,list2取数据
list1 = ['a', 'b']
list2 = ['c', 'd']
# 用itertools.product()求笛卡尔积
for i in itertools.product(list1,list2):
print i
# 结果为:
('a', 'c')
('a', 'd')
('b', 'c')
('b', 'd')
Python库:faker
—用于伪造数据:伪造姓名、出生年月日、性别、地址、手机号等
github地址:faker
可用于给数据库伪造数据
#! /usr/bin/env python3
# _*_ coding:utf-8 _*_
import random,pymysql
import time
from faker import Faker
import random
from time import sleep
# 伪造数据
def create_data():
for i in range(100):
pseudo = Faker("zh_CN") # 伪造姓名和地址
# 随机年月日
a1 = (1990, 1, 1, 0, 0, 0, 0, 0, 0) # 设置开始日期时间元组(1990-01-01 00:00:00)
a2 = (2023, 12, 31, 23, 59, 59, 0, 0, 0) # 设置结束日期时间元组(2024-01-01 00:00:00)
start = time.mktime(a1) # 生成开始时间戳
end = time.mktime(a2) # 生成结束时间戳
t = random.randint(start, end)
date_touple = time.localtime(t)
date = time.strftime("%Y-%m-%d", date_touple)
a = """INSERT INTO PRACTICE.TbStudent values ({id},'{name}',{sex},'{birthday}','{hotel}','{address}',null);""" \
.format(id=str(1001 + i + 1), name=pseudo.name(), sex=random.choice([1, 0]), birthday=date,
hotel=random.choice(["如家", "七天", "度假酒店", "七里香酒店", "窗前明月光"]), address=pseudo.address())
print(a)
with open('data.txt', 'a+') as f:
f.write(a + '\n')
# 计算文件行数
def iter_count(file_name):
from itertools import (takewhile, repeat)
buffer = 1024 * 1024
with open(file_name) as f:
buf_gen = takewhile(lambda x: x, (f.read(buffer) for _ in repeat(None)))
return sum(buf.count('\n') for buf in buf_gen)
# 读取文件
def read_data(file_name):
with open(file_name, 'r') as f:
count = 0
for i in f.readlines():
count = count + 1
print("line_data:", i)
# 批量新增数据
def insert_data():
# 连接数据库
db_connect = pymysql.connect(
user='root',
password='xxxx',
host='127.0.0.1',
db='PRACTICE')
# 使用cursor()方法创建游标对象cursor
cursor = db_connect.cursor()
sql_word = """SELECT * FROM TbStudent;"""
cursor.execute(sql_word) # 执行SQL语句
with open('/Users/XX/Code/pythonProject/XX/data_mysql/data.txt','r') as f:
for i in f.readlines():
print(i)
cursor.execute(i)
db_connect.commit()
sleep(0.5)
data = cursor.fetchone() # 返回执行结果
print(data)
if __name__ == '__main__':
create_data()
lines = iter_count('data.txt')
print("lines:", lines)
read_data('data.txt')
insert_data()